
A Lei de Conway: Como afeta o design do código?
Desacoplar o código começa por desacoplar as mentalidades e abrir as portas da comunicação.

A Lei de Conway, formulada por Melvin Conway em 1967, é uma observação profunda e surpreendente sobre o desenvolvimento de sistemas. A lei afirma:
"Qualquer organização que projeta um sistema (definido amplamente) produzirá um projeto cuja estrutura é uma cópia da estrutura de comunicação da organização."
Esta afirmação pode parecer estranha à primeira vista, mas vamos mergulhar profundamente em suas implicações, explorando como ela se manifesta na realidade das organizações e como pode levar a códigos mais complexos ou menos complexos dependendo da estrutura organizacional dos times.
Ah, e se gostar do conteúdo, por favor, compartilhe nas redes com outros programadores. Isso me ajuda a continuar escrevendo sempre e motiva a não parar de criar e planejar esses artigos! 😄
Juntando as peças 🧩
Vamos desmembrar a frase de forma mais concisa:
"Qualquer organização que projeta um sistema (definido amplamente)":
Qualquer grupo de pessoas trabalhando juntas.
Criando algo, como um software.
O termo "sistema" é usado de forma ampla e pode se referir a muitas coisas.
"produzirá um projeto cuja estrutura":
O grupo criará algo.
Esse algo terá uma estrutura específica.
"é uma cópia da estrutura de comunicação da organização.":
A estrutura do que é criado reflete como as pessoas do grupo se comunicam.
Se a comunicação é desconexa, o projeto também será; se é coesa, o projeto também será.
Conway sugere que a maneira como uma empresa se comunica e interage irá refletir diretamente na estrutura do projeto ou produto que ela cria. Se a comunicação é fragmentada e desconectada, o produto final provavelmente será da mesma forma. Se a comunicação é coesa e bem organizada, o produto também será. É uma observação profunda sobre a interconexão entre pessoas e o trabalho que elas produzem.
Então se a comunicação entre todos for confusa e burocrática, a comunicação entre as camadas do software também vai refletir isso. Então fica claro que o software é uma cópia da estrutura da empresa que o projeta e codifica.
Podemos ir mais além, empresas mal estruturadas desenvolvem arquiteturas de software mal modularizados e estruturados. Mas o contrário, ou seja, o lado positivo também ocorre. Softwares bem modularizados e com um design de código coeso só podem ser escritos por empresas com uma boa estrutura de comunicação entre os times.
Vamos expandir um pouco mais, olhando para uma analogia.
O pintor e o espelho 🖌️🪞
Pense em uma organização como uma artista olhando para o espelho. O reflexo que ela vê é a estrutura de comunicação interna da organização. Agora, o artista tem uma tela em branco à sua frente, pronta para ser pintada. Esta tela em branco é o projeto de software que a organização está prestes a criar.
A cada pincelada na tela, o artista olha para o espelho, usando o reflexo como guia. O reflexo no espelho é a base para a pintura, a inspiração para cada decisão de design que o artista toma. Ao longo do processo de pintura, o que acaba aparecendo na tela é uma cópia fiel do reflexo no espelho.
Da mesma forma, à medida que a organização trabalha no projeto de software, cada decisão de design, cada linha de código escrita, é influenciada pela estrutura de comunicação da organização. O design do software se torna um reflexo da comunicação dentro da organização. Como em nossa analogia, a pintura na tela acaba se parecendo com o reflexo no espelho, a estrutura do software acaba imitando a estrutura de comunicação da organização.
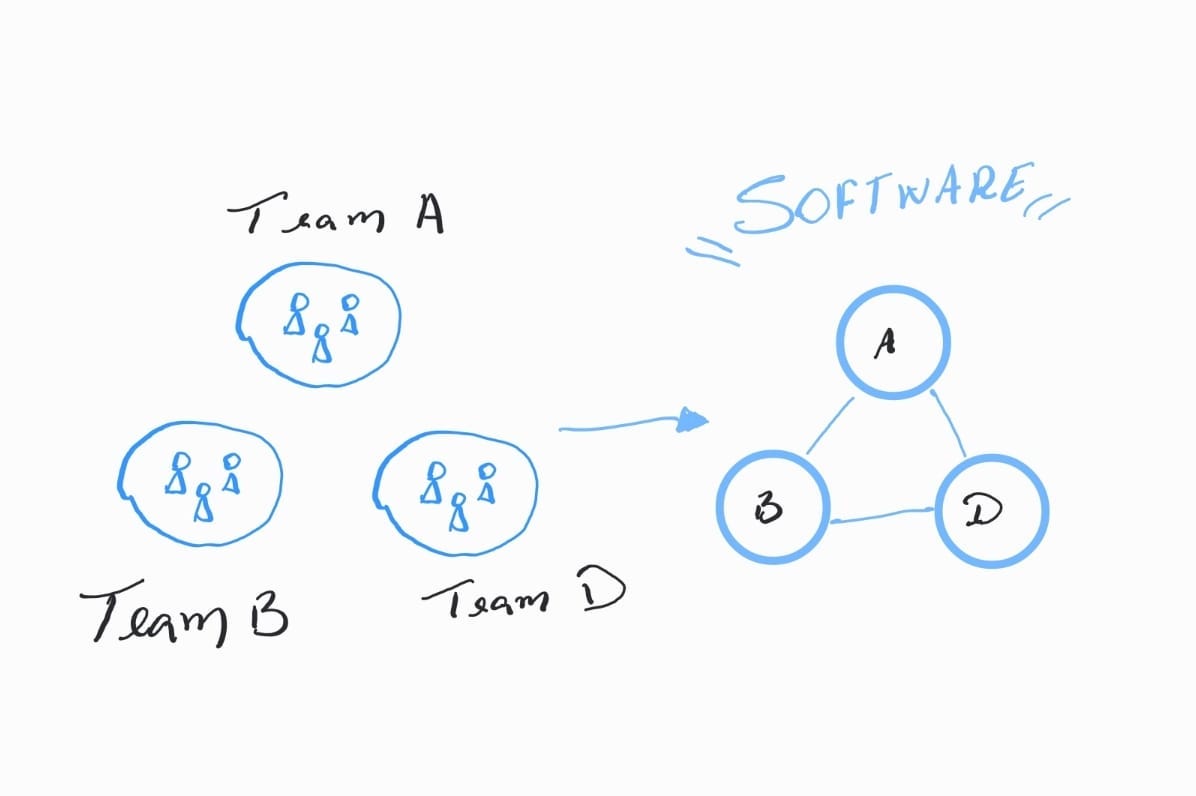
Além disso, é importante notar que, assim como um espelho reflete o que está na frente dele, sem adicionar ou remover nada, a estrutura do projeto de software reflete com precisão a estrutura de comunicação. Se há falhas na comunicação, elas se manifestarão no design do software. Se a comunicação é clara e eficiente, isso também será refletido no software.
Então, em essência, a Lei de Conway sugere que a melhor maneira de melhorar o design de seu software pode ser melhorar a maneira como sua organização se comunica.
Mas como isso realmente reflete no código que você lê e escreve? A Lei de Conway prova que a manutenção do código fica difícil?
Quero conversar com você sobre como isso afeta negativamente o código em termos de manutenção, legibilidade, testabilidade e coesão dos módulos e classes. Mas antes seria legal entender um conceito da lei de Conway, os famosos silos.
Silos corporativos 🏙️
A palavra silo, em sua origem, remonta às antigas linguagens indo-europeias, adaptada tanto ao latim como "sirus" quanto ao grego como "siros", ambos traduzidos como "poço para guardar grãos". No contexto agrícola, os silos são estruturas usadas para armazenar grãos ou forragem em grandes quantidades. Eles são projetados para isolar seu conteúdo do ambiente externo, protegendo-o contra a deterioração. Este conceito de isolamento e proteção foi emprestado para descrever um fenômeno organizacional e, por extensão, suas implicações no desenvolvimento de software.
No mundo do software, mais precisamente corporativo, assim como os grãos são mantidos isolados em silos agrícolas, encontramos "silos" dentro das organizações. Estes representam equipes, departamentos ou unidades de negócios que operam de forma isolada dos outros, cada um com sua própria abordagem, ferramentas, processos e prioridades. Embora, à primeira vista, tal separação possa parecer benigna ou até mesmo desejável em termos de especialização, muitas vezes leva a desafios substanciais, especialmente quando falamos em coesão e integridade do código de software.
Vamos considerar uma organização que possui múltiplos silos, com cada unidade de negócios responsável por um domínio específico do software. Se uma dessas unidades decide fazer alterações diretas no código gerenciado por outro silo, sem uma comunicação adequada ou sem seguir protocolos estabelecidos, as ramificações podem ser vastas e, muitas vezes, prejudiciais.
Primeiro, quando uma unidade de negócio altera o código de outro domínio sem o devido entendimento, há um risco significativo de que os requisitos originais, nuances ou considerações específicas sejam mal interpretados ou completamente ignorados. Isso pode resultar em funcionalidades comprometidas, desempenho reduzido ou, na pior das hipóteses, falhas catastróficas no sistema. Afinal, a equipe original pode ter projetado o código de uma maneira particular para atender a certos critérios ou comportamentos esperados.
Além disso, essas alterações não autorizadas ou não comunicadas criam um cenário de código "fantasma". Sem documentação adequada ou rastreabilidade, outros desenvolvedores podem se deparar com trechos de código que não reconhecem e, sem saber de sua origem ou propósito, podem gastar horas valiosas tentando entender, corrigir ou adaptar esses segmentos.
A questão da manutenção também se torna crítica. Se, no futuro, for necessário atualizar, refatorar ou expandir a funcionalidade, a falta de clareza sobre quem fez o quê e por quê torna o processo muito mais demorado, arriscado e caro. A responsabilidade torna-se difusa, e a falta de propriedade clara pode levar a um cenário onde ninguém se sente verdadeiramente responsável por corrigir ou melhorar o código em questão.
A integração é outra área onde os problemas se manifestam. Se diferentes silos estão desenvolvendo módulos ou componentes que precisam interagir entre si, mas cada um o faz isoladamente, sem uma visão ou entendimento comum, integrar essas partes pode se tornar uma tarefa conflitante e com alto custo de tempo. Incompatibilidades, redundâncias, dependências frágeis e outros problemas podem surgir, comprometendo a integridade e a funcionalidade do software como um todo.
Portanto a ideia de silos não traz grandes benefícios para grandes corporações ou unidades de negócios que têm o mesmo objetivo em comum. Em muitos casos ter silos representa dificuldades em comunicação e colaboração. Além do fato que cada departamento tem suas próprias prioridades que podem conflitar com outras unidades de negócios, dificultando a colaboração dos times.
O mundo ideal vs realidade
Em um mundo ideal, o código deve ser claro, conciso, e fácil de entender. No entanto, muitas organizações enfrentam um dilema único: a estrutura de comunicação complexa e fragmentada pode ser um reflexo direto no código produzido. A falta de clareza e comunicação entre os membros da equipe pode levar a uma abordagem ad hoc na codificação, resultando em uma estrutura de código enigmática e indisciplinada.
Se você já se deparou com um código que parece um labirinto impenetrável, pode reconhecer os sintomas desta situação. O que parece uma tarefa simples de manutenção ou atualização pode se transformar em uma odisseia exaustiva de descobertas, interpretações e, em última análise, frustração.
A Dor da Manutenção
Manter um código complexo e desorganizado não é apenas desafiador, mas pode ser uma fonte constante de desconforto e estresse para os desenvolvedores. Corrigir um bug ou adicionar uma nova funcionalidade pode se tornar uma tarefa hercúlea quando a estrutura do código é uma miríade confusa de dependências, loops e condições.
Falta de Coesão: A Ruptura Silenciosa
A coesão é uma qualidade que desejamos em nossos sistemas. Queremos que as partes relacionadas do código estejam agrupadas de maneira lógica e que as partes não relacionadas estejam separadas. No entanto, em uma organização onde a comunicação é fraturada e a visão unificada é ofuscada por barreiras organizacionais, a coesão pode se desintegrar rapidamente.
O resultado? Classes e módulos que tentam fazer demais, tornando-se monolitos ininteligíveis, ou aqueles que fazem muito pouco, tornando-se fragmentos inúteis. A falta de coesão não é apenas um problema técnico; é um sintoma de uma organização onde os membros da equipe estão trabalhando em silos, desconectados das necessidades e objetivos que deveriam alcançar juntos.
Reflexão sobre o Desconforto
As consequências negativas da aplicação da Lei de Conway na manutenção de software não são apenas teóricas. Elas são sentidas todos os dias pelos desenvolvedores que lutam para entender, manter e evoluir sistemas que se tornaram reflexos distorcidos da estrutura organizacional em que foram criados.
É como tentar ler um livro escrito em várias línguas diferentes, onde cada capítulo foi traduzido por uma pessoa diferente sem acesso ao contexto geral. O sentido se perde, e o leitor (ou o desenvolvedor) é deixado para juntar as peças, muitas vezes sem sucesso.
A falta de coesão, a complexidade desnecessária, e os desafios da manutenção são mais do que apenas inconvenientes técnicos. Eles são obstáculos que podem diminuir a moral da equipe, retardar o progresso e, em última análise, afetar a qualidade do produto final.
Vendo na prática os efeitos!
Considere essa situação. A empresa em que você trabalha tem um sistema de gestão de estoque. Este sistema foi desenvolvido por um time que, em sua época, possuía um conjunto de habilidades, experiências e conhecimentos específicos. Este time seguiu a arquitetura de microserviços, onde cada componente do sistema era responsável por uma parte específica do trabalho.
No entanto, devido à mudança na estrutura organizacional, a equipe atual responsável pela manutenção do sistema não pode alterar agora InventoryService. Os gestores decidem passar essa responsabilidade para outro time. Ela possui um conjunto diferente de habilidades e experiências, e infelizmente, tem pouca familiaridade com a lógica de negócios incorporada ao código do sistema de estoque.
Vamos pegar, por exemplo, um dos módulos desse sistema: o módulo responsável pela atualização do inventário após a venda de um produto.
public class InventoryService
{
public void UpdateInventoryAfterSale(int productId, int quantitySold)
{
Product product = Database.GetProductById(productId);
if (product == null)
{
throw new Exception("Produto não encontrado.");
}
if (product.StockQuantity < quantitySold)
{
throw new Exception("Estoque insuficiente.");
}
product.StockQuantity -= quantitySold;
Database.UpdateProduct(product);
}
}
O método UpdateInventoryAfterSale do InventoryService é responsável por buscar um produto específico no banco de dados, verificar se há estoque suficiente para a venda e então atualizar a quantidade de estoque do produto.
Agora, suponha que a empresa decida introduzir um novo recurso que envolve a verificação de múltiplos depósitos antes de confirmar a venda de um produto. Para a squad que não possui familiaridade com a lógica de negócios incorporada ao código, isto pode parecer uma tarefa complicada. Como resultado, eles podem decidir implementar essa nova funcionalidade de maneira mais direta, mas que mata o desacoplamento entre classes:
public class InventoryService
{
public void UpdateInventoryAfterSale(int productId, int quantitySold)
{
Product product = Database.GetProductById(productId);
if (product == null)
{
throw new Exception("Product not found.");
}
var warehouses = Database.GetWarehousesWithProductStock(productId);
int totalStock = warehouses.Sum(w => w.GetProductStock(productId));
if (totalStock < quantitySold)
{
throw new Exception("Insufficient stock.");
}
foreach (var warehouse in warehouses)
{
int warehouseStock = warehouse.GetProductStock(productId);
if (warehouseStock >= quantitySold)
{
warehouse.UpdateProductStock(productId, warehouseStock - quantitySold);
quantitySold = 0;
}
else
{
warehouse.UpdateProductStock(productId, 0);
quantitySold -= warehouseStock;
}
if (quantitySold == 0)
{
break;
}
}
product.StockQuantity = totalStock - quantitySold;
Database.UpdateProduct(product);
}
} Embora a solução possa parecer adequada à primeira vista, ela introduz uma série de problemas que podem levar a uma manutenção de código mais complexa no futuro.
Primeiramente, o método UpdateInventoryAfterSale agora tem muito mais responsabilidades, tornando-se mais complexo e difícil de entender. Ele está lidando diretamente com a lógica de atualização de estoque de vários depósitos, o que é uma violação do princípio da responsabilidade única.
Além disso, o método agora depende do método GetWarehousesWithProductStock, o que aumenta o acoplamento entre o InventoryService e o WarehouseService. Isto pode tornar o código mais difícil de modificar e testar.
Finalmente, a squad atual pode não estar ciente de todas as implicações desta alteração. Por exemplo, eles podem não saber que a atualização do estoque de um depósito pode disparar eventos que afetam outras partes do sistema.
Esta situação é um pequeno e simples exemplo de como a regra de Conway se aplica na prática. A estrutura do código reflete a estrutura da organização. Como o time atual não tem familiaridade com a lógica de negócios e a arquitetura do código, eles podem acabar implementando soluções que aumentam a complexidade do código e introduzem novos problemas.
De acordo com Conway, a solução para este problema não é simplesmente refatorar o código. O time precisa compreender melhor o sistema como um todo, as regras de negócio e a arquitetura. Por exemplo, deveriam ter consultado a equipe que realmente tem conhecimento profundo sobre esse serviço para buscar por explicações. Mas se dentro da organização não existe essa comunicação fácil, fica muito difícil que essas alterações sejam coerentes.
Além disso, precisam colaborar mais estreitamente com outros membros da organização que possam ter conhecimento ou experiência relevantes. Ao fazer isso, eles podem chegar a soluções que estão mais alinhadas com as necessidades do negócio e a arquitetura do sistema.
Unidades de Negócio Isoladas e Fragmentação no Código
Quero propor um segundo exemplo. Imagine uma organização com vários times trabalhando isoladamente em diferentes aspectos de um sistema. Um é responsável pelos clientes, outra squad pelos produtos, e uma terceira pelos pedidos. Eles não se comunicam bem, e isso se reflete no código. Como? Veja abaixo:
public class ClienteHandler
{
// Métodos e propriedades relacionadas ao cliente
}
public class ProdutoHandler
{
// Métodos e propriedades relacionados ao produto
}
public class PedidoHandler
{
// Métodos e propriedades relacionados ao pedido
}
Temos uma separação clara das responsabilidades em três classes: ClienteHandler, ProdutoHandler, e PedidoHandler. Cada classe parece ser responsável por lidar com um aspecto específico do sistema, seja ele clientes, produtos ou pedidos.
Mas isso parece ser bom, certo? Veja bem, isso depende muito. Mesmo com as classes separadas em diferentes responsabilidades, isso não necessariamente reflete organização e fácil leitura do código. Vamos explorar as razões:
Comunicação Insuficiente: Se as equipes que estão desenvolvendo essas classes não têm comunicação adequada, pode haver uma falta de entendimento comum sobre como essas classes devem interagir e colaborar. O resultado pode ser interfaces mal definidas e incoerentes.
Desalinhamento de Requisitos: As squads podem ter diferentes interpretações dos requisitos do sistema, o que pode levar a incompatibilidades nas implementações das classes. Isso pode causar problemas quando essas classes precisam trabalhar juntas.
Duplicação de Código: Sem uma coordenação clara, pode haver duplicação de lógica entre as classes. Por exemplo, se a validação de certos dados for necessária em várias partes do sistema, e não houver uma abordagem unificada, essa lógica pode ser repetida em várias classes.
Inconsistência de Design: Mesmo que as classes estejam separadas, se não houver padrões e práticas de design consistentes entre as equipes, o código pode se tornar desorganizado. Algumas classes podem ser desenvolvidas usando um conjunto de práticas, enquanto outras podem seguir abordagens diferentes, resultando em um código heterogêneo e difícil de manter.
Acoplamento Indesejado: A separação das classes não garante necessariamente um baixo acoplamento se não for bem pensada. Se as classes dependerem fortemente umas das outras, alterar uma pode ter efeitos colaterais inesperados em outras. Isso torna o sistema frágil e difícil de modificar.
Falta de Coesão: As classes podem ser divididas de forma que não reflitam uma divisão lógica das responsabilidades do sistema. Isso pode levar a classes que têm responsabilidades mistas e mal definidas, resultando em uma falta de coesão.
Testabilidade: A falta de coesão e a comunicação ineficaz podem tornar o código difícil de testar. Sem entender completamente como as classes devem interagir, escrever testes significativos que refletem o comportamento real do sistema pode ser um desafio.
Simplesmente dividir o código em classes separadas não é suficiente para garantir uma boa organização e coesão. A separação deve ser informada por uma compreensão clara das responsabilidades e colaborações entre as partes do sistema, e deve ser apoiada por uma comunicação eficaz e práticas de design consistentes entre as equipes. Caso contrário, o que pode parecer uma organização à primeira vista pode, na verdade, esconder uma complexidade e fragilidade consideráveis.
A complexidade desnecessaria nasce em nosso exemplo. Tal complexidade do software é inevitável até certo ponto, mas desnecessária e surge devido a problemas como falta de comunicação, coordenação insuficiente, acoplamento forte, coesão fraca e falta de testabilidade pode ser minimizada. O primeiro passo para fazer isso é estar ciente de como a estrutura organizacional pode influenciar o design do código. Pense nisso!
A Testabilidade e Sua Complexidade Escondida
Agora vamos direcionar nossa atenção para testes. A testabilidade do código não é algo que possa ser simplesmente isolado ou ignorado. É uma parte vital da engenharia de software e está profundamente entrelaçada com a forma como organizamos nossas equipes e nossa comunicação.
Imagine, por um momento, que você está diante de um código complexo, fortemente acoplado e fragmentado. Agora, sua tarefa é testá-lo. Como você se sente? Provavelmente, confuso, frustrado, talvez até um pouco assustado.
A testabilidade do código reflete a clareza de pensamento e organização por trás dele. Se o código é claro, se os módulos são coesos e bem definidos, testá-lo se torna uma tarefa compreensível e gerenciável. Mas se o código é o resultado de uma equipe fragmentada, com comunicação pobre e sem um direcionamento claro, então testar esse código se torna uma missão quase impossível.
Desvendando o Complexo Labirinto da Testabilidade
Para ilustrar ainda mais a complexidade e a profundidade dessa relação, vamos explorar mais profundamente:
A Coesão e a Testabilidade: Se os módulos e as classes do código não têm coesão, se tentam fazer muitas coisas ao mesmo tempo, testá-los se torna uma tarefa gigantesca. A falta de coesão faz com que os módulos se tornem mais dependentes uns dos outros, tornando os testes isolados quase impossíveis.
A Comunicação e a Testabilidade: Se os times não se comunicam efetivamente, o código resultante refletirá essa falta de comunicação. Interfaces mal definidas, falta de documentação, falta de entendimento claro dos requisitos - tudo isso torna o teste uma tarefa árdua.
A Estrutura Organizacional também influência: Como a unidade de negócio é estruturada? É uma equipe grande e monolítica? São várias squads pequenas trabalhando em partes diferentes do código? Essa estrutura vai se refletir no código, e, consequentemente, na maneira como o código pode ser testado.
O Lado Humano da Testabilidade: Por trás de todos esses aspectos técnicos e organizacionais, existe o lado humano. A testabilidade é uma questão de qualidade e garantias, mas também empatia, compreensão e respeito pelos colegas e pelos usuários.
Vamos mergulhar em um exemplo real e ilustrar como a Lei de Conway pode afetar a testabilidade do código.
A falta de clareza do que testar
Imagine que temos dois núcleos, A e B, estão trabalhando em partes distintas de um projeto que lida com vouchers. Núcleo A é responsável pelo gerenciamento dos vouchers, mas o núcleo B que não é especialista nesse dominio. Vamos supor que por alguma decisão interna o núcleo B recebe autorização/permissão para modificar e adicionar recursos na classe VoucherManager.
Se a comunicação entre os dois núcleos é limitada, e têm diferentes entendimentos de como a classe deve operar, pode ocorrer conflitos de como o código deve ser alterado. Vamos colocar algo simples aqui, mas quero que pense nisso em propoções maiores!
Código da Classe VoucherManager (Desenvolvimento feito pelo núcleo A)
public class VoucherManager
{
private IVoucherRepository _voucherRepository;
public VoucherManager(IVoucherRepository voucherRepository)
{
_voucherRepository = voucherRepository;
}
public bool ValidateVoucher(string voucherCode)
{
Voucher voucher = _voucherRepository.GetVoucherByCode(voucherCode);
if (voucher == null || voucher.IsExpired())
{
return false;
}
return true;
}
}
public class Voucher
{
public string Code { get; set; }
public DateTime ExpiryDate { get; set; }
public bool IsExpired()
{
return DateTime.Now > ExpiryDate; // Grave essa linha em sua mente.
}
}
public interface IVoucherRepository
{
Voucher GetVoucherByCode(string code);
}Código alterado por núcleo B (Terrível escolha para adicionar a nova regra 👇)
public class Voucher
{
public string Code { get; set; }
public DateTime ExpiryDate { get; set; }
public bool IsUsed { get; set; } // Adicionando um novo campo
public bool IsExpired()
{
return DateTime.Now > ExpiryDate || IsUsed; // Changing the logic to consider IsUsed
}
}
Exemplo de Teste Unitário (Desenvolvimento feito por núcleo A, Porém alterado por núcleo B)
[Fact]
public void ValidateVoucher_ReturnsFalse_WhenVoucherIsExpired()
{
// Arrange
var mockVoucherRepository = new Mock<IVoucherRepository>();
mockVoucherRepository.Setup(repo => repo.GetVoucherByCode(It.IsAny<string>()))
.Returns(new Voucher
{
Code = "TEST123",
ExpiryDate = DateTime.Now.AddDays(-1), // Voucher expired yesterday
IsUsed = false // Even though this is false, it should not influence the result
});
var voucherManager = new VoucherManager(mockVoucherRepository.Object);
// Act
bool result = voucherManager.ValidateVoucher("TEST123");
// Assert
Assert.False(result);
}
[Fact]
public void ValidateVoucher_ReturnsTrue_WhenVoucherIsNotExpired()
{
// Arrange
var mockVoucherRepository = new Mock<IVoucherRepository>();
mockVoucherRepository.Setup(repo => repo.GetVoucherByCode(It.IsAny<string>()))
.Returns(new Voucher
{
Code = "TEST123",
ExpiryDate = DateTime.Now.AddDays(1), // Voucher will expire tomorrow
IsUsed = false // This should not influence the result
});
var voucherManager = new VoucherManager(mockVoucherRepository.Object);
// Act
bool result = voucherManager.ValidateVoucher("TEST123");
// Assert
Assert.True(result);
}
}
O exemplo é simples. Sabemos muito bem que os sistemas do mundo real tem problemas bem maiores. Mas seria interessante analisar o que este exemplo revela:
Falta de Alinhamento: O teste não reflete completamente o comportamento do
VoucherManagerou as expectativas do núcleo A em termos de como a classe deve ser testada. O time B está realizando o teste de acordo com sua própria interpretação, que pode não estar alinhada com as intenções do time A.Introdução de Falhas Inesperadas e Regressões: Se o time B altera o código da squad A sem uma compreensão completa do contexto e não fornece cobertura de teste adequada, eles podem inadvertidamente introduzir bugs ou regressões. Estas falhas podem ser sutis e só se manifestar sob condições específicas que a equipe B pode não estar ciente. Quando esses problemas surgem, a equipe A pode ter que gastar um tempo significativo identificando, reproduzindo e corrigindo as falhas, afetando sua produtividade e os prazos do projeto.
Desalinhamento das Expectativas do Domínio: As alterações feitas pela equipe B podem não estar alinhadas com as expectativas ou requisitos do domínio da equipe A. Isso pode levar a um comportamento de software que diverge do que os stakeholders esperam ou do que foi acordado inicialmente. A equipe A, ao revisitar o código, pode enco ntrar-se em uma situação onde precisa reverter ou reescrever partes do código para realinhá-lo com as expectativas do domínio, causando retrabalho.
Deterioração da Confiança e Integridade do Código: A introdução de alterações sem cobertura de teste adequada pode minar a confiança na base de código. A equipe A pode começar a questionar a estabilidade e confiabilidade das partes do sistema que foram alteradas.
Como podemos ver, a equipe B alterou dois testes que ja tinham sido escritos pela equipe A: um para um voucher válido e outro para um voucher expirado. No entanto, eles não criaram um teste para verificar o cenário onde um voucher já foi utilizado (IsUsed = true).
Esse tipo de omissão pode levar a falsas garantias sobre a correção do código e potencialmente a erros não detectados no ambiente de produção.
Além disso notou esse trecho de código na classe Voucher?
// Péssima escolha ⚠️⚠️⚠️
return DateTime.Now > ExpiryDate || IsUsedVejamos os problemas potenciais que essa mudança pode gerar:
Violando o Princípio da Responsabilidade Única: O método
IsExpired()originalmente tinha uma única responsabilidade: determinar se um voucher estava ou não expirado com base na data. Com a adição da verificaçãoIsUsed, o método agora tem duas responsabilidades: verificar a data de validade e verificar se o voucher foi usado. Isso torna o método menos intuitivo e potencialmente confuso para futuros desenvolvedores que poderiam esperar queIsExpired()verificasse apenas a data de expiração.Possíveis Efeitos Colaterais Indesejados: Em lugares do código onde apenas a data de validade do voucher era relevante, o método
IsExpired()agora também considera o status de uso do voucher. Isso pode levar a comportamentos indesejados em certas situações. Por exemplo, imagine uma funcionalidade que deseja listar todos os vouchers que estão prestes a expirar em uma semana, mas que ainda não expiraram. Se um voucher foi usado, mas ainda não atingiu sua data de expiração, ele seria incorretamente filtrado por essa lógica.Dificuldade de Manutenção e Expansão: Ao combinar lógicas diferentes em um único método, você torna mais difícil isolar e modificar comportamentos individuais no futuro. Por exemplo, se a lógica de determinar se um voucher foi usado mudar, ou se houverem exceções adicionais a serem consideradas, isso pode exigir que você reescreva ou adicione condições adicionais ao método
IsExpired(), tornando-o ainda mais complexo.Testabilidade: Testar um método com múltiplas responsabilidades pode ser mais desafiador. Agora, em vez de simplesmente testar as datas de validade para verificar se um voucher expirou, os testes também precisariam considerar o estado
IsUseddo voucher. Isso significa mais cenários de teste e, potencialmente, maior complexidade em preparar e verificar os testes.
Embora pareça uma pequena mudança, combinar lógicas diferentes em um único método pode ter ramificações substanciais na clareza, manutenção e testabilidade do código.
O exemplo ilustra claramente como a falta de comunicação e entendimento mútuo entre as equipes pode levar a um teste unitário que não reflete adequadamente o comportamento da classe em teste.
Essa desconexão pode resultar em uma falsa sensação de segurança (os testes passam, então tudo deve estar bem), mas na verdade, o código pode ter problemas não detectados ou comportamentos indesejados que não foram testados.
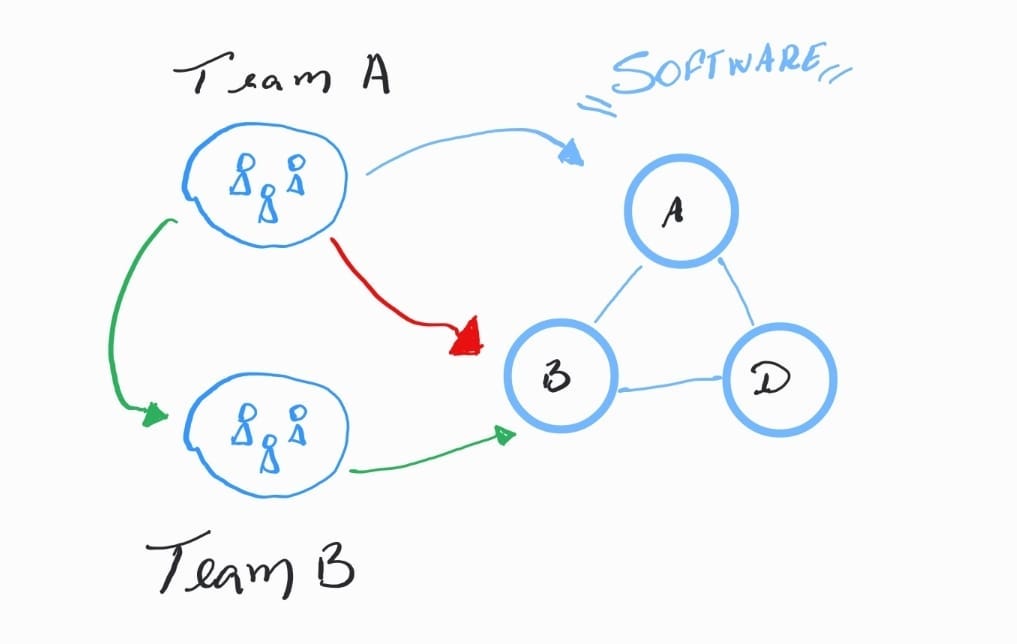
Na imagem acima, a seta vermelha indica a equipe A alterando ou criando funcionalidades que outra equipe é responsável. Isso não é nada benéfico para a qualidade do produto! A seta verde indica uma comunicação entre os dois times onde o time A solicita alteração para o time B.
A Lei de Conway, mais uma vez, mostra seu valor, destacando como a estrutura organizacional e a comunicação podem afetar diretamente o design do código e a qualidade dos testes. É um lembrete valioso de que o desenvolvimento de software é um esforço colaborativo e que a clareza e a comunicação são essenciais para o sucesso.
Falhas em Contratos
Imagine dois times: Time 2, que trabalha na API de Pagamentos, e Time 3, responsável pela API de Pedidos. A Time 2 cria um novo endpoint para processar pagamentos e define que um status code 422 (Unprocessable Entity) será retornado caso a validação falhe.
Squad 2 - API de Pagamentos:
[HttpPost]
public IActionResult ProcessPayment(PaymentModel payment)
{
var validationResult = ValidatePayment(payment);
if (!validationResult.IsValid)
{
return UnprocessableEntity(validationResult.Errors);
}
// Logic to process payment
return Ok();
}
A equipe 3, sem ter uma comunicação clara sobre o novo status code, cria a integração com a API de Pagamentos, mas espera apenas status code 400 (Bad Request) para erros de validação.
Squad 3 - API de Pedidos:
public async Task<bool> ProcessPaymentAsync(PaymentModel payment)
{
var response = await _httpClient.PostAsJsonAsync("/api/payments", payment);
if (response.StatusCode == HttpStatusCode.BadRequest)
{
// Handle bad request
throw new ValidationException("Payment validation failed.");
}
if (response.StatusCode != HttpStatusCode.OK)
{
// Unexpected status code
throw new Exception("Failed to process payment.");
}
return true;
}
Qual o problema com essa falta de comunicação e clareza do contrato?
Incompatibilidade de Expectativas: A diferença entre o que a squad 2 retornou (422) e o que a squad 3 esperava (400) ilustra como a falta de comunicação clara sobre contratos pode levar a mal-entendidos e erros de integração.
A Experiência do Usuário Final: A falta de tratamento específico para o status code 422 na API de Pedidos pode resultar em mensagens de erro genéricas ou ambíguas sendo retornadas ao usuário final. Isso pode deixar o usuário confuso e insatisfeito com a experiência.
Manutenção e Debugging: Essa incompatibilidade entre os códigos de status pode tornar a manutenção e a depuração mais difíceis. Se um erro de validação ocorrer, a exceção lançada será genérica, não revelando o motivo real do problema.
Este exemplo nos lembra da importância do entendimento claro e da comunicação efetiva entre as equipes. Em um mundo complexo, uma falha de comunicação pode se espalhar e afetar não apenas o código, mas também a experiência do usuário final.
A legibilidade do código pede socorro!
Quando falamos de legibilidade do código, estamos realmente falando sobre como um programador pode rapidamente entender e seguir o fluxo de um programa. Isso envolve identificar o que cada classe, método ou função faz e, igualmente crucial, o que ela deveria fazer. Mas quando as equipes não estão comunicando claramente entre si ou com outras partes da empresa, essa legibilidade é posta em risco.
Sem um canal de comunicação claro para obter esclarecimentos, um desenvolvedor pode interpretar a necessidade de uma maneira e acabar nomeando funções ou métodos de maneira menos intuitiva. Uma função destinada à autenticação do usuário pode receber um nome como "AuthProcess" ou "CheckLogin", em vez de algo mais descritivo e padrão, como "UserAuthentication".
Em um cenário onde as informações não são prontamente compartilhadas ou são compartilhadas de forma ineficaz, o risco de recriar funcionalidades já existentes aumenta. Desenvolvedores podem acabar escrevendo funções que replicam a lógica de outras, mas com nomes ligeiramente diferentes, criando redundância e potencialmente levando a discrepâncias no comportamento do sistema.
Esta inconsistência na nomeação e na abordagem não apenas torna o código menos legível, mas também significa que os desenvolvedores gastam mais tempo tentando entender o código do que realmente programando. Sem uma comunicação clara, a padronização fica comprometida.
A consequência é um código onde a intenção e a funcionalidade de classes, métodos ou funções são obscuras. Novos programadores, encontrarão desafios ao tentar discernir o propósito de cada componente. E cada hora gasta tentando decifrar o que uma parte do código faz é uma hora não gasta melhorando, otimizando ou expandindo o sistema.
O que podemos fazer?
A Lei de Conway é menos um conjunto de regras rígidas e mais uma observação perspicaz sobre a natureza humana e como ela se reflete na criação de sistemas. Aceitar essa lei e trabalhar com ela, em vez de contra ela, pode levar a uma integração de equipe mais suave e eficaz. Vamos considerar três abordagens estratégicas que podem ajudar a alcançar esse objetivo, e também refletir sobre o que não devemos fazer.
1. Comunicação Aberta e Eficiente:
O que fazer: Estabelecer canais claros e abertos de comunicação entre as equipes. Isso pode incluir reuniões regulares de alinhamento, documentação clara, e ferramentas colaborativas que facilitam a comunicação.
Por que funciona: Conway nos diz que a estrutura de nosso código refletirá nossa estrutura de comunicação. Se nossas equipes estão falando clara e abertamente, nosso código será mais claro e aberto.
Exemplo prático: Utilizar ferramentas como Slack (existem muitas no mercado) para criar canais específicos para cada projeto, onde as equipes podem discutir detalhes, compartilhar conhecimento e esclarecer dúvidas.
2. Coesão e Modularidade:
O que fazer: Organizar os times de acordo com os domínios do negócio e responsabilidades claras. Cada unidade deve ser responsável por um módulo ou parte do sistema que esteja alinhada com seus conhecimentos e habilidades.
Por que funciona: Ao dividir o sistema em módulos claros e alinhar as equipes a esses módulos, podemos minimizar o acoplamento desnecessário e aumentar a coesão. A estrutura do time e a estrutura do código se espelham, conforme a Lei de Conway.
Exemplo prático: Se uma unidade é responsável pela gestão de clientes e outra pela gestão de produtos, elas devem ser organizadas de modo a refletir essa separação no código, com interfaces claras entre os módulos.
3. Cultura de Aprendizagem e Colaboração:
O que fazer: Encorajar uma cultura onde as equipes aprendem umas com as outras e colaboram, compartilhando melhores práticas e conhecimentos.
Por que funciona: Ao incentivar essa cultura colaborativa, incentivamos uma estrutura organizacional que é flexível e adaptável, que se reflete em um código mais flexível e adaptável.
Exemplo prático: Workshops e sessões de treinamento, onde as squads/unidades podem aprender sobre os desafios e soluções uns dos outros, promovendo um entendimento mútuo. Além disso, as squads devem estar cientes de que cada Code Review é um momento de esclarecimento de dúvidas e direcionamento de aprendizado para todos, independente da senioridade dos envolvidos!
Agora vamos brevemente falar sobre Domain-Driven Design.
DDD pode ajudar sua organização!
O entendimento da relação entre Domain-Driven Design e a Lei de Conway é crucial para produzir software que não apenas funcione bem, mas também reflita fielmente o domínio do negócio subjacente. Essa relação é baseada principalmente na comunicação e na estrutura.
Dando uma olhada no DDD, vemos que ele é focado no domínio do negócio. Por exemplo, temos "Bounded Context" no DDD, que é basicamente um território bem definido onde um modelo de domínio faz sentido. Em termos leigos, é como se fosse uma parte específica do mundo dos negócios, com seu próprio jargão e regrinhas.
Pense no "Bounded Context" do DDD. Se uma organização estruturasse suas equipes em torno desses contexts, cada equipe teria uma compreensão clara do subdomínio com o qual está trabalhando. Teoricamente, isso levaria a um software mais coeso, com cada pedaço do software refletindo claramente o subdomínio correspondente.
Porém, problemas surgem quando a comunicação entre essas equipes falha. Imagine que duas equipes estejam trabalhando em subdomínios diferentes que precisam interagir entre si. Se essas equipes não se comunicam efetivamente, haverá um descompasso entre os Bounded Contexts.
Isso poderia se manifestar de várias maneiras: inconsistências de dados, lógica de negócios conflitante ou até mesmo falhas no sistema. Além disso, a linguagem usada dentro desses contextos, chamada Linguagem Ubíqua em DDD, precisa ser consistentemente compreendida e aplicada por todos os envolvidos. Se a Lei de Conway não for considerada, e a comunicação entre todos não for suficientemente clara, essa linguagem comum poderia se tornar fragmentada, levando a mais confusões e erros.
Para adicionar uma camada extra de complexidade, os domínios de negócios, assim como as organizações, evoluem. Se uma área do domínio de negócios está se expandindo rapidamente, isso poderia sugerir a necessidade de dividir uma equipe em duas, para lidar com a crescente complexidade. Mas, se essa divisão não é refletida na estrutura do software (ou vice-versa), complicações são inevitáveis.
Resumindo, a conjugação do DDD e da Lei de Conway ressalta a importância da estrutura e da comunicação no desenvolvimento de software. Negligenciar qualquer um desses aspectos pode comprometer a eficácia do produto final. É, portanto, imperativo para as organizações reconhecerem e navegarem por essa interseção para alcançar a excelência em suas soluções de software.
Benefícios do DDD na Estrutura Organizacional
Podemos trazer rapidamente os benefícios:
Comunicação Clara e Eficaz: A Linguagem Ubíqua promove a comunicação clara e eficaz entre as partes envolvidas no desenvolvimento. Ao estabelecer uma linguagem comum, reduz-se a ambiguidade e mal-entendidos. Isso facilita a colaboração entre as equipes, tornando a estrutura de comunicação mais eficiente, o que, por sua vez, reflete em um código mais coeso e compreensível.
Coesão e Modularidade: O DDD incentiva a divisão do sistema em contextos delimitados, cada um com sua própria Linguagem Ubíqua e modelo. Isso promove a coesão dentro dos módulos e minimiza o acoplamento entre eles. Essa coesão na arquitetura de software pode ser um reflexo direto da coesão entre as equipes de desenvolvimento, reforçando o espelho entre a organização e o código.
Flexibilidade e Agilidade: Ao permitir que as equipes compreendam melhor os domínios de negócios e colaborem mais efetivamente, o DDD aumenta a capacidade da organização de responder às mudanças. A estrutura modular do código facilita a manutenção e adaptação, refletindo a capacidade da organização de se adaptar às mudanças no ambiente de negócios.
Integração entre as Squads: A aplicação do DDD promove uma compreensão compartilhada dos objetivos de negócios e dos desafios técnicos. Essa compreensão comum, promovida através da Linguagem Ubíqua, facilita a integração e colaboração entre as equipes, resultando em uma arquitetura de software mais harmonizada.
Alinhamento com os Objetivos de Negócios: DDD coloca o domínio de negócios no centro do desenvolvimento. Isso garante que a estrutura do código esteja alinhada com os objetivos e necessidades de negócios da organização. Esse alinhamento pode se refletir em uma maior eficiência e eficácia na entrega de valor para o negócio.
Nunca tente Lutar contra a Lei de Conway.
Ao tentar impor uma estrutura organizacional que não reflete a forma natural como os times se comunicam e colaboram, estamos criando uma batalha constante entre a organização e o código. Isso pode levar a ineficiências, confusão, e código desajeitado.
Por exemplo, se tentarmos forçar uma estrutura altamente centralizada em uma organização que funciona melhor com equipes autônomas e independentes, poderíamos acabar com um sistema monolítico e inflexível que é difícil de manter e adaptar.
Não é algo que possa ser derrotado ou contornado. É uma observação sobre a natureza do desenvolvimento de software e deve ser respeitada e entendida. Ao alinhar a estrutura de nossas times com a estrutura de nossos sistemas, podemos criar um ambiente mais harmonioso, eficiente e produtivo.
Fico por aqui neste post! Obrigado por ler até o final, se este post foi útil, compartilhe! Até o próximo! 😄