
Anatomia do Kafka
Quando falamos de Kafka, não estamos apenas falando de mensageria, mas de uma infraestrutura robusta que possibilita que arquiteturas distribuídas prosperem com consistência e baixo acoplamento.

Se você clicou nesse artigo, é porque esse assunto desperta sua curiosidade — ou talvez você já tenha ouvido falar tanto de Kafka que decidiu entender melhor o que é e por que todo mundo fala sobre ele. E olha, você está no lugar certo. Vamos explorar o Kafka sem enrolação, de forma simples e acessível.
Ao longo desse artigo, vamos dar uma olhada mais profunda na "anatomia" desse broker de mensagens tão utilizado no mundo da tecnologia. Vamos entender com ilustrações como ele funciona e por que ele se tornou indispensável para tantas empresas.
O Que é Kafka?
Vale a pena conhecer um pouco da história do Kafka. Ele foi criado pelo LinkedIn, lá em 2010, quando a empresa enfrentava um desafio comum em muitas empresas de tecnologia: como lidar com a enorme quantidade de dados que diferentes sistemas geravam em tempo real. O Apache Kafka nasceu para resolver isso, permitindo que sistemas pudessem trocar informações de maneira rápida e confiável. Ele foi projetado para ser escalável, ou seja, crescer junto com o volume de dados e a demanda, sem perder performance. Mais tarde, o Kafka foi doado para a Apache Software Foundation, tornando-se open-source e ganhando ainda mais popularidade.

Agora, se você trabalha em um sistema distribuído, sabe como pode ser desafiador fazer diferentes partes da aplicação se comunicarem de maneira eficiente, sem que dados se percam ou as mensagens demorem demais para chegar. Isso é especialmente crítico quando estamos falando de processamento em tempo real. E é justamente nesse ponto que o Kafka faz toda a diferença.
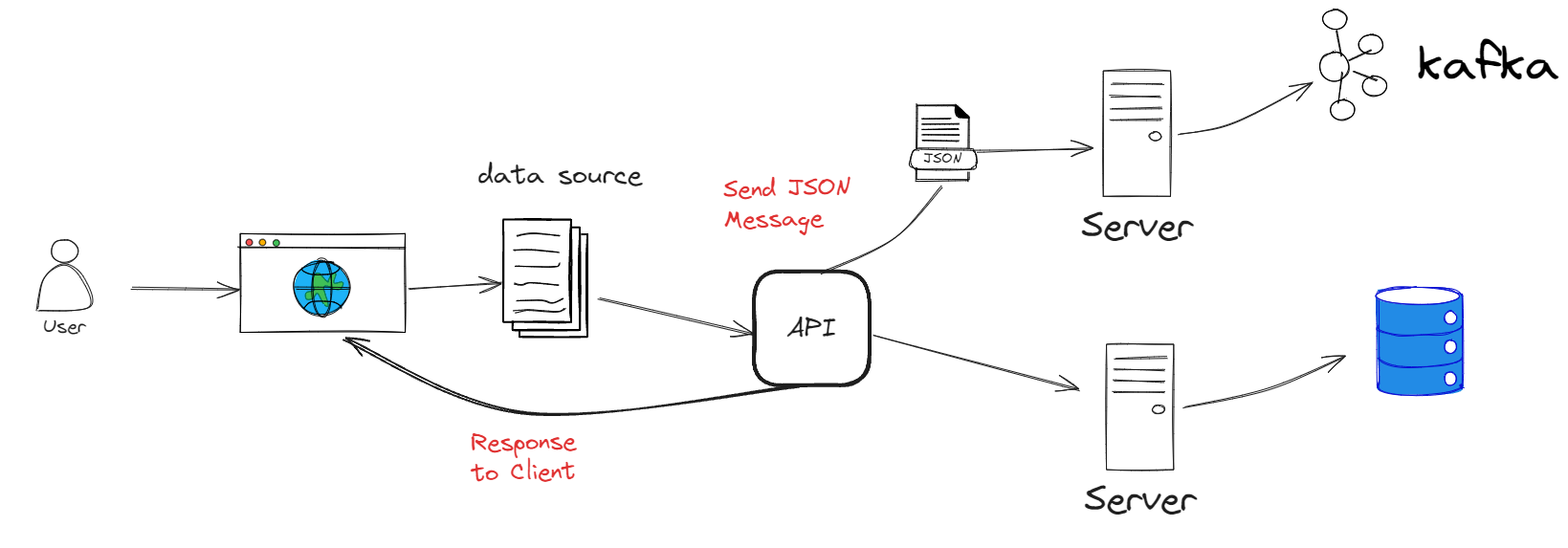
Imagine uma empresa de e-commerce, como falamos antes: cada pedido feito no site precisa ser comunicado ao sistema de estoque, ao sistema de pagamento, à equipe de entrega, e tudo isso tem que ser sincronizado, para que o processo funcione de forma integrada. Sem uma solução como o Kafka, essas mensagens podem se perder, ou pior, chegar com atraso, comprometendo a experiência do usuário. O Kafka resolve esse problema de comunicação entre sistemas de maneira rápida, escalável e confiável.

Agora, para entender melhor como o Kafka faz isso, podemos pensar nele como um sistema de correios. Ele recebe mensagens de produtores (os sistemas que enviam dados) e as entrega para os consumidores (os sistemas que precisam desses dados). O Kafka é a plataforma central que faz todo esse trânsito de mensagens acontecer de forma eficiente.
Produtores são como os remetentes, que enviam as mensagens.
Consumidores são como os destinatários, que recebem essas mensagens.
O Kafka é o correio que organiza, armazena e distribui essas mensagens de forma ordenada.
Agora, vamos falar sobre a estrutura básica da mensagem no Kafka!
Principais Elementos de uma Mensagem no Kafka
Quando você trabalha com Kafka, as mensagens (também conhecidas como eventos ou registros) são a essência de toda a comunicação entre os sistemas. Então, é importante entender como essas mensagens são compostas e o que elas contêm.
Normalmente, as mensagens que você envia ou recebe no Kafka são transmitidas no formato JSON, ou seja, um payload JSON com os dados que você quer compartilhar. Esse formato é bem comum, principalmente porque é leve e fácil de ler, tanto para humanos quanto para sistemas. Agora, vamos ver os principais componentes dessa mensagem:
Key (Chave): Essa parte é opcional, mas é muito útil quando você precisa garantir que mensagens relacionadas sejam enviadas para a mesma partição. Por exemplo, se você tem mensagens sobre pedidos de clientes, pode usar o ID do cliente como chave, para garantir que todos os pedidos de um cliente específico vão para a mesma partição e sejam processados na ordem correta.
Value (Valor): Aqui é onde mora a mensagem — o dado real que você está enviando. Esse valor pode ser praticamente qualquer coisa: um evento, um status, uma resposta de enquete, etc. No caso de um payload JSON, seria o conteúdo completo da mensagem que está sendo transmitida entre sistemas.
Timestamp (Carimbo de Tempo): Cada mensagem no Kafka tem um timestamp, que indica quando a mensagem foi criada ou registrada. Isso é essencial para monitorar a ordem dos eventos e para rastrear quando as mensagens foram geradas. O timestamp ajuda bastante em sistemas que dependem do tempo dos eventos para funcionar corretamente.
Compression Type (Tipo de Compressão): Dependendo do volume de dados que você está lidando, o Kafka permite que as mensagens sejam comprimidas com algoritmos como gzip ou snappy. Isso ajuda a reduzir o tamanho das mensagens e melhora a eficiência no envio de grandes quantidades de dados, sem perder a integridade.
Headers (Cabeçalhos, opcional): São pequenos metadados opcionais que você pode adicionar à mensagem para incluir informações extras, sem mexer no conteúdo principal. Eles são super úteis para transportar dados adicionais que os consumidores podem usar para decisões de processamento, sem alterar o valor da mensagem em si.
Partition e Offset ID: Depois que a mensagem é gravada no Kafka, ela é armazenada em uma partição e recebe um offset. Esses dois elementos são fundamentais para o Kafka garantir a entrega e a leitura correta das mensagens (vamos conversar muito sobre esses dois conceitos daqui a pouco).
E como isso chega no Kafka?
Como mencionei antes, a maioria das mensagens que trafegam no Kafka usa JSON como formato de payload, mas pode variar dependendo do caso. A estrutura seria algo assim:
{
"key": "survey_123",
"value": {
"surveyId": "survey_123",
"title": "Pesquisa de Preferências de Filmes",
"question": "Qual é o seu filme favorito?",
"answers": [
"A Origem",
"Interestelar",
"O Grande Truque",
"Dunkirk"
],
"responseCount": 457,
"createdAt": "2024-10-06T12:00:00Z",
"updatedAt": "2024-10-08T09:45:30Z",
"isActive": true,
"metadata": {
"surveyType": "multipleChoice",
"maxResponses": 1000
}
},
"timestamp": 1722873600000,
"headers": {
"source": "survey-platform",
"language": "pt-BR",
"content-type": "application/json",
"event-type": "surveyResponse",
"transaction-id": "f4d9a1b3-67d2-49b8-915b-df1dcee3bdf9"
}
}Tópicos
No Kafka, "tópicos" são como categorias ou temas que organizam as mensagens de forma eficiente. Cada tópico agrupa mensagens que tratam de um mesmo assunto, facilitando o acesso e o processamento das informações que você precisa.
Por exemplo, em um sistema de e-commerce, você pode ter um tópico para pedidos, outro para pagamentos e um para notificações. Dentro de cada tópico, as mensagens são organizadas em ordem cronológica, ou seja, da mais antiga para a mais recente.
Tecnicamente, um tópico é onde os produtores enviam (publicam) as mensagens sobre um assunto e os consumidores as leem. Assim, o Kafka garante que as informações estão sempre no lugar certo, para que os sistemas possam acessá-las de forma rápida e organizada.

Aqui está um detalhe importante: ao organizar as mensagens em tópicos, o Kafka permite que vários consumidores acessem as mensagens de forma simultânea e independente. Cada consumidor pode "se inscrever" em um tópico específico e pegar as mensagens que ele precisa, sem interferir nos outros.
Isso é especialmente importante quando falamos de escalabilidade. Imagine um site de compras com milhares de pedidos sendo feitos a cada segundo. Se todos os pedidos fossem jogados em um único espaço desorganizado, processar esses dados seria um caos. Mas com os tópicos, o Kafka permite que os dados sejam processados em lotes organizados, tornando a comunicação entre os sistemas rápida e eficiente.
Agora que entendemos isso, vamos ver como o Kafka divide essas mensagens em partições, permitindo que ele processe dados de forma ainda mais rápida e escalável.
Partições
Quando falamos sobre "partições" no Kafka, estamos nos referindo a uma forma inteligente de dividir o trabalho para tornar o sistema mais rápido e eficiente. Imagine que você tenha que processar milhões de mensagens que chegam o tempo todo. Se tudo for processado em uma única "linha de produção", pode demorar muito. É aí que as partições entram em cena.
Pense nas partições como pequenas seções dentro de um tópico. Um bom exemplo do cotidiano seria organizar documentos dentro de uma pasta. Imagine que você tem uma pasta chamada "Contas" (o tópico), e dentro dela você cria diferentes seções, como "Água", "Luz" e "Telefone" (as partições). Ao invés de deixar todos os documentos misturados, dividir em seções facilita a organização e permite que você encontre e processe os documentos muito mais rápido.
Da mesma forma, no Kafka, as partições ajudam a dividir as mensagens dentro de um tópico, o que facilita o acesso e o processamento dessas mensagens de forma mais eficiente.

Vamos pegar o exemplo da imagem acima: imagine que você tenha um sistema que coleta respostas de enquetes (surveys). Cada vez que um usuário responde a uma enquete, esse sistema envia uma mensagem para um tópico Kafka chamado survey-responses. Agora, se você tiver milhares de respostas chegando ao mesmo tempo, seria muito lento processar tudo em sequência, uma resposta após a outra. Então, o Kafka divide automaticamente essas respostas em partições.
Partição 0 pode receber algumas respostas de um grupo de usuários.
Partição 1 pode receber outras respostas, de maneira aleatória ou baseada em uma chave (como o ID da enquete).
Partição 2 pode receber mais respostas, garantindo que o trabalho seja distribuído entre diferentes partições de forma eficiente.

Essas partições ajudam a distribuir a carga de processamento entre diversos consumidores. Em vez de um único consumidor lidar com todas as respostas, você pode ter vários consumidores, cada um responsável por processar uma ou mais partições ao mesmo tempo. Isso garante que o sistema consiga lidar com grandes volumes de respostas de forma rápida e escalável.
O Que São Offsets?
Imagine que o Kafka é um grande armazém logístico onde pacotes (as mensagens) chegam de todos os lados. O armazém precisa organizar e enviar esses pacotes para os destinos corretos o mais rápido possível.
Se todos os pacotes fossem colocados em uma única pilha, o trabalho seria caótico e demorado. Em vez disso, o armazém divide os pacotes em diferentes corredores — e cada um desses corredores representa uma partição.
Agora, cada pacote recebe uma etiqueta de número de série — e essa etiqueta é o offset. Com esse sistema de offset, os trabalhadores (consumidores) sabem exatamente de onde pegar os pacotes, em que ordem e, se forem interrompidos, conseguem voltar ao ponto exato em que pararam.
Depois dessa pequena analogia, pense nos offsets como a numeração única que o Kafka dá para cada mensagem dentro de uma partição. Cada vez que uma nova mensagem é escrita em uma partição, ela recebe um número de offset, que começa em 0 e vai aumentando conforme novas mensagens são gravadas.

Como você pode ver na imagem, cada partição (0, 1 e 2) tem uma sequência de offsets, e o Kafka garante que a ordem seja mantida dentro de cada partição.
Partições e Offsets:
A imagem mostra três partições de um tópico Kafka (Partição 0, Partição 1, Partição 2). Dentro de cada partição, as mensagens são gravadas com offsets sequenciais. Por exemplo, na Partição 0, a mensagem mais recente está no offset 9.
Mensagens Escrevendo Continuamente:
O Kafka está constantemente escrevendo novas mensagens nas partições. As setas à direita mostram que, à medida que novas mensagens chegam, elas são gravadas no próximo offset disponível. Quando uma nova mensagem for recebida, ela será escrita com o próximo número de offset.
Offsets Únicos para Cada Partição:
Vale notar que os offsets são específicos para cada partição. Na Partição 1, por exemplo, a mensagem mais recente está no offset 8, mas na Partição 2, o offset mais recente é 9. Essas sequências podem ser diferentes entre as partições, mas dentro de cada uma, a ordem é sempre respeitada.
Os offsets são importantes porque garantem que os consumidores saibam exatamente onde parar e onde continuar lendo quando voltarem a consumir mensagens de um tópico. Se o consumidor já leu até o offset 5 na Partição 0, da próxima vez que ele fizer uma "poll", ele começará a partir do offset 6. Isso garante que nenhuma mensagem seja lida mais de uma vez (a menos que seja reprocessada intencionalmente) e que as mensagens não sejam ignoradas.
🚨 ATENÇÃO! 🚨 O offset não contém a mensagem em si. Ele serve como um "marcador" que indica a posição em que a mensagem está armazenada dentro da partição.
O Que Isso Significa Na Prática?
Imagine que você tenha uma API de enquetes (surveys) que coleta perguntas e respostas dos usuários. Cada vez que uma nova enquete é criada, a API publica uma mensagem no Kafka, enviando essa enquete para um tópico chamado survey-events. Nesse caso, o Kafka precisa gerenciar grandes volumes de dados, especialmente se essa API estiver constantemente recebendo e enviando novas enquetes.
Agora, vamos visualizar um cenário mais completo:
A API publica uma nova mensagem:
Quando uma nova enquete é criada, a API publica essa mensagem no tópico
survey-events. Essa mensagem pode conter informações como o título da enquete, as opções de resposta, e a data de criação.
Particionamento e Offsets:
No Kafka, o tópico
survey-eventsestá particionado, o que significa que as mensagens serão distribuídas entre diferentes partições. Cada mensagem de enquete recebe um offset dentro de sua partição.Por exemplo, uma nova mensagem pode ser enviada para a Partição 0 com o offset 10, enquanto outra mensagem vai para a Partição 1 com o offset 6. Essas mensagens ficam gravadas em suas respectivas partições, aguardando para serem lidas pelos consumidores.
Consumidores lendo as mensagens:
Agora imagine que você tem dois serviços consumidores distintos:
Um serviço de coleta de respostas que precisa monitorar cada nova enquete e preparar o sistema para receber as respostas.
Um serviço de análise de dados que coleta as informações da enquete para gerar relatórios e insights em tempo real.
Ambos os serviços estão lendo as mensagens do tópico
survey-events, mas o Kafka distribui as partições entre eles, e é aqui que os offsets brilham.Como os Offsets Garantem a Continuidade:
Vamos supor que o serviço de coleta de respostas esteja consumindo a Partição 0. Ele já processou todas as mensagens até o offset 9, e agora precisa processar a nova enquete que acabou de chegar no offset 10.
Enquanto isso, o serviço de análise de dados está consumindo a Partição 1 e já leu até o offset 5. Quando uma nova enquete é publicada na Partição 1 com o offset 6, ele sabe exatamente de onde continuar.
Agora, pense que um desses serviços caiu temporariamente (por manutenção, erro, etc.). Quando ele voltar a funcionar, ele não vai perder a sequência de mensagens, porque o Kafka armazena os offsets e sabe exatamente onde cada consumidor parou. O serviço de coleta de respostas continuará a partir do offset 10 na Partição 0, e o serviço de análise de dados começará de onde parou, no offset 6 da Partição 1.
Por que isso é tão útil?
Sem os offsets, os consumidores não teriam como garantir que as mensagens fossem processadas na ordem correta ou sem repetições. O Kafka, com sua lógica de partições e offsets, resolve esse problema de maneira elegante.
Isso significa que, não importa o quanto o sistema cresça ou quantas enquetes sejam publicadas a cada minuto, os consumidores conseguem lidar com essa carga de forma eficiente e sem perder dados ou processar mensagens fora de ordem.
Fluxo:
Nova enquete criada → API publica mensagem no Kafka.
Kafka distribui a mensagem → Mensagem vai para uma partição e recebe um offset.
Consumidores processam mensagens → Cada consumidor lê a partir do offset onde parou.
Falhas são recuperadas → Se um consumidor falhar, ele retoma do último offset lido, sem perder nada.
Os serviços consumidores saibam exatamente onde parar e retomar, mesmo em caso de falhas. Isso torna o Kafka uma ferramenta poderosa para lidar com sistemas distribuídos em tempo real.
Como As Partições e o Offset Ajudam?
As partições e os offsets desempenham papéis fundamentais no Kafka, cada um ajudando de maneiras distintas:
Escalabilidade: As partições são cruciais para permitir que o Kafka seja altamente escalável. Quando o volume de mensagens cresce, você pode adicionar mais consumidores, e cada consumidor pode ser responsável por uma ou mais partições. Isso ajuda na distribuição da carga de trabalho, facilitando o processamento de mensagens de forma rápida e eficiente, sem sobrecarregar um único ponto de processamento.
Processamento Paralelo: Ao dividir os tópicos em partições, o Kafka possibilita o processamento em paralelo. Isso significa que diferentes consumidores podem processar mensagens simultaneamente, acelerando o tempo de resposta e o throughput do sistema.

Manutenção da Ordem: O offset é um número único que identifica cada mensagem dentro de uma partição. Ele garante que as mensagens dentro de cada partição sejam processadas na ordem correta. Por exemplo, se você está processando um fluxo de pedidos, e a primeira mensagem é "Pedido 1" e a segunda é "Pedido 2", o offset preserva essa sequência dentro da partição, garantindo que as mensagens sejam lidas na ordem em que foram recebidas.

Continuidade e Resiliência: Além disso, o offset ajuda a garantir a continuidade do processamento. Se um consumidor falhar ou precisar reiniciar, ele pode recomeçar a partir do último offset processado. Isso garante que nenhuma mensagem seja perdida e que o processamento continue de onde parou, proporcionando resiliência ao sistema.


Revisando
Tópico = O "assunto" (ou categoria) das mensagens.
Partição = As "divisões" dentro do tópico, que permitem processar as mensagens de maneira eficiente e paralela.
Offset = O "marcador" de cada mensagem dentro de uma partição, permitindo que o processamento seja controlado com precisão.
Agora que entendemos essas diferenças, vamos falar de um componente muito importante dentro do kafka.
O Papel do Zookeeper no Kafka
Agora que já cobrimos bastante coisa, vamos falar sobre um personagem que trabalha nos bastidores para garantir que tudo no Kafka funcione direitinho: o Zookeeper. Pense nele como o maestro de uma orquestra. Só que, em vez de coordenar músicos, ele coordena brokers, partições, e em versões antigas offsets, e até mesmo os consumidores. Ele está sempre ali, mantendo tudo em sincronia para que o Kafka rode como uma máquina bem ajustada.
Mas o que o Zookeeper realmente faz? Como ele garante que, mesmo com falhas, o Kafka continue funcionando de forma eficiente? Vamos mergulhar nisso.
Gerenciamento de Brokers: Mantendo a Casa em Ordem
O Kafka é um sistema distribuído, o que significa que você pode ter múltiplos brokers (ou servidores) rodando ao mesmo tempo. Cada broker é responsável por armazenar e processar um conjunto de partições. Mas como o Kafka sabe quais brokers estão ativos e disponíveis para processar essas partições?
Essa é a primeira grande função do Zookeeper. Ele mantém uma lista atualizada de todos os brokers ativos no cluster Kafka. Pense nele como uma espécie de "gerente de sala", verificando quais servidores estão funcionando, quais estão inativos e redistribuindo as tarefas, caso necessário.

Se um broker cai, o Zookeeper age rápido. Ele realoca as partições que estavam sob responsabilidade desse broker para outro que ainda está funcionando. Isso é o que mantém o Kafka tão resiliente. Mesmo quando um pedaço do sistema falha, o Zookeeper faz com que o Kafka continue operando quase sem que você perceba.
Coordenação de Offsets: Antes e Agora
Lembra dos offsets que discutimos antes? São eles que indicam ao consumidor em qual mensagem o Kafka deve continuar lendo quando retoma o processamento. Mas como o Kafka sabe exatamente em qual offset cada consumidor parou, especialmente se algo der errado?
Antes da Versão 0.9 do Kafka:
Até a versão 0.9, o Zookeeper era diretamente responsável por armazenar os offsets. Isso significa que cada vez que um consumidor lia uma mensagem, o Zookeeper atualizava e guardava o último offset lido por aquele consumidor. Se algo desse errado, como uma falha no sistema ou reinicialização, o Zookeeper tinha o registro exato de onde cada consumidor parou, permitindo que o Kafka retomasse a leitura no ponto certo.
Essa abordagem funcionava bem para clusters menores, mas à medida que os sistemas cresciam e mais consumidores eram adicionados, isso começou a sobrecarregar o Zookeeper. Ele não foi projetado para armazenar dados de alta frequência como os offsets, o que limitava a escalabilidade do Kafka.

Atualmente (Versão 0.9 em diante):
Com a introdução da versão 0.9, o Kafka passou a armazenar os offsets internamente, em um tópico especial chamado __consumer_offsets. Agora, em vez de o Zookeeper armazenar diretamente os offsets, o próprio Kafka gerencia e armazena esses dados como mensagens dentro desse tópico. Isso permite que o Kafka manipule grandes volumes de consumidores e dados de forma muito mais eficiente, sem sobrecarregar o Zookeeper.
Embora o Zookeeper tenha deixado de armazenar diretamente os offsets, ele ainda desempenha um papel importante na coordenação geral do estado do cluster. Ele mantém o controle de quais brokers estão ativos, gerencia a eleição de líderes de partições e coordena os consumidores e seus grupos.
Eleições de Líderes de Partições
No Kafka, cada partição tem um líder, que é o broker responsável por gerenciar as leituras e escritas de mensagens daquela partição. O líder recebe as mensagens dos produtores e as distribui para os followers — que são réplicas dessa mesma partição em outros brokers.

Mas o que acontece se o líder falhar ou ficar inacessível? É aqui que entra o Zookeeper, coordenando o processo de eleição de um novo líder de forma rápida e automática. Na imagem, se o broker-1 falhar, o Zookeeper identifica essa falha e escolhe um novo líder entre os followers — neste exemplo, o broker-2 assumiria a liderança da partition-0 (e de outras se for necessário). Isso garante que os consumidores possam continuar lendo as mensagens daquela partição.

Esse mecanismo automático de failover é essencial para garantir a alta disponibilidade. Mesmo em cenários em que um broker ou partição fica indisponível, o sistema permanece resiliente e os dados continuam fluindo. O Zookeeper faz todo o gerenciamento nos bastidores, sem intervenção manual, permitindo que o Kafka seja escalável e robusto para lidar com falhas.
Portanto, com o Zookeeper coordenando as eleições de líderes, o Kafka garante que o processamento de mensagens continue fluindo, mesmo em situações adversas, como a falha de um broker.
Monitoração do Cluster
Em um sistema distribuído como o Kafka, com múltiplos brokers, consumidores e partições, manter tudo sincronizado é fundamental. É fácil imaginar como isso pode se tornar caótico se ninguém estiver no comando.
O Zookeeper é essa peça central de orquestração. Ele garante que cada broker saiba quais partições está gerenciando, que cada consumidor saiba onde parou e que todo o sistema esteja sempre alinhado. Ele atua como o gerente invisível, mantendo todas as engrenagens do Kafka rodando de forma suave.

Agora, pense em um cenário onde você está coletando respostas de milhares de surveys em tempo real, em um sistema Kafka com vários brokers e partições. O que aconteceria se um dos brokers falhasse? Sem o Zookeeper, você poderia perder dados importantes, ou o sistema poderia até parar de processar as mensagens. Isso seria um desastre em um sistema!
É nesse momento que o Zookeeper aparece. Ele detecta falhas, realoca o trabalho para outros brokers, coordena e faz tudo isso de forma tão eficiente que você raramente notará que algo deu errado. Isso mantém o Kafka altamente disponível, confiável e pronto para escalar conforme necessário.
O Zookeeper não recebe tanta atenção quanto os outros componentes do Kafka, mas ele é o verdadeiro herói nos bastidores. Sem ele, o Kafka perderia sua resiliência, sincronia, e habilidade de se auto-recuperar em caso de falhas. Ele é quem garante que todas as partes do Kafka — dos brokers aos consumidores — estejam sempre em harmonia, trabalhando juntas de forma eficiente e contínua.
Agora vamos focar um pouco mais em dois papéis fundamentais que estão um pouco fora do ecossistema do kafka.
Mantenha Esta Palavra em Mente: Assíncrono
Quando falamos de Kafka, uma palavra que você deve sempre ter em mente é assíncrono. No centro do sistema estão os produtores e consumidores, responsáveis por enviar e receber/manipular dados. No entanto, o grande segredo por trás da eficiência do Kafka é justamente a maneira assíncrona como essa comunicação acontece, permitindo que tudo funcione de maneira fluida, sem dependências rígidas entre as partes. Vamos entender melhor como isso funciona.
Produtores e Consumidores: Enviando e Recebendo Sem Pressa
No Kafka, os produtores são aqueles que geram os dados e enviam para o Broker, publicando suas mensagens em tópicos. Eles podem ser qualquer tipo de serviço: desde uma aplicação de e-commerce enviando informações de pedidos até um sistema de monitoramento enviando logs de erro. O mais importante aqui é que os produtores não se preocupam com quem vai consumir essas mensagens — eles apenas enviam os dados.
Por outro lado, os consumidores são os responsáveis por ler e processar essas mensagens. Eles se inscrevem nos tópicos que lhes interessam e, assim que estão prontos, consomem os dados. A grande sacada é que eles podem fazer isso no próprio tempo, sem estarem sincronizados com os produtores. Isso significa que, mesmo que um consumidor não esteja disponível no momento em que a mensagem é enviada, ele poderá acessá-la mais tarde, pois as mensagens são armazenadas pelo Kafka até serem consumidas.
A Comunicação Assíncrona
Agora, aqui entra o poder do assíncrono. Quando dizemos que a comunicação entre produtores e consumidores é assíncrona, queremos dizer que eles não precisam estar em sincronia para que o processo funcione. Os produtores não precisam esperar que os consumidores estejam prontos para receber as mensagens, e os consumidores podem pegar as mensagens quando lhes for conveniente.
Isso não apenas evita gargalos como também torna os serviços extremamente flexíveis. Cada componente trabalha no seu próprio ritmo, sem depender diretamente do outro. Se um consumidor demora para processar uma mensagem ou se há um volume muito alto de dados, nada se perde ou trava — o Kafka se adapta, armazenando os dados temporariamente até que o consumidor possa tratá-los.

A assíncronia é fundamental em sistemas distribuídos, especialmente quando há grandes volumes de dados e múltiplos serviços interagindo entre si. Sem essa característica, você acabaria com gargalos, travamentos, e sobrecarga em momentos de pico de tráfego de dados. Na imagem acima vemos isso, uma API consumidora está indisponível, mas o Kafka vai garantir que as mensagens que chegam sejam preservadas até que o consumidor se recupere para continuar a processar as mensagens.
Essa independência entre produtores e consumidores, facilitada pelo Kafka, torna o sistema robusto e eficiente, mesmo em ambientes altamente dinâmicos e de grande escala. Tudo isso, claro, graças à palavra que você deve manter em mente: assíncrono.
Legal estamos quase concluindo essa jornada e se tiver dúvidas pode deixar seu comentário!
O Coração Distribuído do Kafka
Agora que já cobrimos os logs, partições e consumidores, chegou a hora de falar sobre os brokers. São eles que fazem o Kafka funcionar de maneira distribuída e escalável. Mas o que exatamente são esses brokers, e por que eles são tão importantes? Vamos entender isso juntos!
Imagine os brokers do Kafka como centros de distribuição em uma grande rede de logística. Assim como em um sistema de entregas, onde centros de distribuição recebem, armazenam e enviam pacotes para diferentes destinos, os brokers do Kafka fazem o mesmo com as mensagens. Eles recebem as mensagens dos produtores, as armazenam temporariamente e as entregam aos consumidores de forma organizada e eficiente.
Um broker no Kafka é simplesmente um servidor que faz parte do cluster Kafka. Ele é responsável por receber os dados dos produtores, armazenar essas mensagens em partições (dentro dos tópicos), e então entregar as mensagens aos consumidores que se inscrevem para ler essas mensagens.

O Papel dos Brokers!
Escalabilidade horizontal: Capacidade de crescer conforme a demanda aumenta.
Resiliência: Capacidade de lidar com falhas sem interrupções no sistema.
Alta disponibilidade: Garantia de que o sistema sempre estará operacional, mesmo em casos de falha.
Em resumo, os brokers garantem que tudo continue fluindo, mesmo quando ocorrem falhas. Agora vamos conversar brevemente sobre algumas questões que podem ser levantadas. Essas dúvidas vou colocar em formato de tópico para organizarmos melhor o raciocinio.
Consumidores Se Inscrevem em Tópicos ou Partições?
Os consumidores no Kafka se inscrevem nos tópicos. Quando um consumidor se inscreve em um tópico, o Kafka distribui automaticamente as partições desse tópico entre os consumidores. Isso significa que cada consumidor será responsável por processar as mensagens de uma ou mais partições, e ele vai seguir lendo as mensagens na ordem indicada pelos offsets.
Se você tem um tópico com três partições e três consumidores inscritos nesse tópico, o Kafka vai garantir que cada consumidor processe as mensagens de uma partição diferente. Isso garante que as mensagens sejam processadas de forma paralela e distribuída. Isso torna o Kafka extremamente flexível, permitindo que o sistema escale conforme a demanda cresce.
E Se Só Houver Um Consumidor Por Tópico? O Kafka Ainda é a Melhor Escolha?
Talvez você esteja se perguntando: "E se eu só tiver um consumidor interessado no tópico? Será que o Kafka ainda é a solução ideal?". Essa é uma pergunta válida, afinal, o Kafka brilha em cenários com múltiplos consumidores processando dados em paralelo. Mas calma, vamos analisar essa situação juntos.
O Kafka foi projetado para lidar com grandes volumes de dados e processamento em escala. Então, se você está lidando com um cenário onde só um único serviço ou sistema está interessado nas mensagens de um tópico, o Kafka pode parecer um "canhão para matar uma mosca". Mas será que é mesmo?
Quando Kafka é Uma Boa Escolha Para Um Consumidor Único
Mesmo que haja apenas um consumidor processando as mensagens de um tópico, o Kafka ainda pode ser uma escolha sólida, dependendo do seu cenário. Vamos considerar algumas situações em que ele se destaca:
Volume de Dados: Se você estiver lidando com grandes volumes de dados (mesmo que só tenha um consumidor), o Kafka ainda pode ser ideal por sua capacidade de lidar com fluxos intensos e persistir mensagens de forma confiável. A performance e a capacidade de escalabilidade do Kafka continuam sendo um grande trunfo.
Garantia de Persistência: O Kafka mantém as mensagens armazenadas por um período configurável, o que significa que mesmo que seu único consumidor fique temporariamente fora do ar, ele pode voltar e "ler" as mensagens que perdeu sem nenhum problema.
Futuro Escalável: Hoje você pode ter apenas um consumidor, mas e amanhã? O Kafka permite que você adicione novos consumidores facilmente no futuro, caso outros sistemas ou serviços também precisem acessar os dados. Ele se adapta conforme suas necessidades evoluem.
Mas e Quando Kafka Não é Tão Ideal?
Agora, se o seu cenário envolve apenas um único consumidor e o volume de dados é relativamente pequeno, o Kafka pode ser uma solução robusta demais. Nesse caso, talvez uma fila de mensagens mais simples (como RabbitMQ ou SQS) possa atender melhor. Esses sistemas são mais leves, fáceis de configurar e funcionam bem em cenários onde o volume de dados é menor e a simplicidade é mais importante que a escalabilidade.
Então, Kafka ou Não?
A resposta depende das suas necessidades. Se você está lidando com grandes volumes de dados, quer garantir durabilidade das mensagens e está pensando em escalabilidade futura, o Kafka é uma ótima escolha, mesmo com apenas um consumidor. Mas se o seu cenário é mais leve e não envolve tanto processamento ou dados em escala, pode valer a pena considerar outras opções mais simples.
No fim das contas, o Kafka é como um cinto de utilidades: pode parecer demais para um problema pequeno, mas está sempre pronto para crescer junto com suas demandas. Neste artigo não vou ter tempo de mergulhar em outras questões importantes e dúvidas, mas se tiver alguma deixe um comentário!
Conclusão
Quanta coisa vimos! Ao explorar a anatomia do Kafka, entendemos como essa plataforma de mensageria distribuída opera de maneira eficiente e escalável. Começamos com a ideia de tópicos e partições, que ajudam a dividir e organizar grandes volumes de dados, permitindo que múltiplos consumidores processem mensagens em paralelo. Descobrimos também o papel crucial dos offsets, que garantem que cada mensagem seja lida na ordem correta dentro de uma partição, permitindo um controle preciso do processamento.
Além disso, vimos como o broker é o coração do Kafka, responsável por armazenar e distribuir as mensagens, e como o Zookeeper mantém tudo em sincronia, garantindo que os brokers estejam sempre coordenados e que os consumidores continuem a funcionar mesmo diante de falhas.
Por fim, entendemos que as mensagens no Kafka não são apenas pedaços de dados — elas têm chave, valor, timestamp e outros metadados que ajudam a manter a integridade e a rastreabilidade das informações. Com isso, vimos que o Kafka é mais do que uma simples ferramenta de mensageria; é uma plataforma robusta e flexível, fundamental para sistemas que precisam processar dados em tempo real de maneira distribuída e resiliente.
Se você gostou do artigo, deixe sua curtida no post e compartilhe!