
Can a human understand that?
Every decision we make while programming has the potential to cause a range of outcomes - some desirable, some not!

Martin Fowler once said:
Any fool can write code that a computer can understand. Good programmers write code that humans can understand.
This quote, taken from his influential book Refactoring: Improving the Design of Existing Code, is highly meaningful to all developers who care not just about the functionality of their software, but also its maintainability, testability, readability, and effectiveness.
Meanwhile, the legendary Kent Beck, one of the founders of extreme programming and an advocate for simplicity in software design, brings us a similar perspective:
The biggest limitation of software is the developer's ability to understand the system.
This quote, originating from his book "Extreme Programming Explained", reveals the inescapable truth that software is not just limited by technical constraints but also by human understanding.
Together, these two quotes emphasize a principle that should be the cornerstone of any software project: the clarity and simplicity of code are vital. It's not just about aesthetic or intellectual vanity. It's a pragmatic concern that affects the efficiency and effectiveness of the entire development team.
But before we go on, let me clarify one thing. When I refer to clarity and simplicity, I'm not suggesting that you sacrifice functionality or performance in favor of a more "beautiful" coding design. No, it's not that. We're talking about writing code that is easily understood by your fellow programmers, that can be maintained, extended, and improved without the need for a giant bottle of painkillers.
So, what does it mean to write code that humans can understand? And why is this so important? Let's dive into these questions and find out.
Intelligible Code: Why Does It Matter?
Software is understood, modified, and extended multiple times throughout its lifespan. This makes code readability an indispensable feature in any project. But what does that really mean?
In practice, an intelligible code is one that does not need a decoder or an interpreter to be understood. The code should not be a riddle, should not be a maze, and definitely should not be a black box. It should be an open book, ready to be read, understood, and expanded by any team member.
As Kent Beck highlights, the programmer's ability to understand the system is the greatest limitation of software. Therefore, if the development team cannot understand a system clearly, how will they be able to modify it, fix it, or improve it? How will they ensure they are not introducing new bugs every time they make a change? How will timely deliveries be possible? This is why we need to strive and struggle to write readable algorithms regardless of seniority level. It does not matter if you have been in the company for 5, 10, 15, or 20 years, everyone needs to cherish the quality and clarity of the code!
Moreover, this matters because a readable algorithm also reduces the time and effort needed to bring new team members up to speed on what is being done in a specific flow within the software. The easier it is for a new developer to understand each line, the quicker they can effectively contribute to the project.
In addition, a simple and easy-to-understand code can help reduce the incidence of errors. And the fact is, humans are much better at detecting errors in code that they can read and clearly understand.
So, what are the benefits? The list is extensive, but we can highlight some main advantages:
Development Efficiency: Clean and understandable code makes the development process more efficient. It allows the team to focus on adding new functionalities, instead of spending time deciphering obscure and complex code.
Ease of maintenance: Software maintenance is an inevitable part of its life cycle. An easy-to-understand and simple code makes maintenance a much easier task and less prone to errors.
Easier code to review: When we write a method or class that is simple it will be easier to review, which increases the chances of finding possible logic problems.
Improvement in team collaboration: Easy-to-read and understand code promotes collaboration within the team. It allows all team members to contribute to the project effectively, regardless of their level of experience.
The point is, software is less about machines and more about people. Machines just execute the commands that are written, provided by humans. It's the people who create, maintain and evolve the software. Therefore, a code that is easy for people to understand has great intrinsic value. It's like a well-paved road: it allows you to reach your destination faster, easier, and in a safer way.
Software development is not just an exercise in machine-to-machine communication, but even more, a matter of human-to-human communication.
But what exactly does "clean" and "simple" design mean? One way to think about this is through the lens of the KISS Principle (Keep It Simple, Stupid). The principle is straightforward, avoid unnecessary complexity, create the simplest thing possible that meets the customer's needs. And for this to be achieved, each method must have well-defined responsibilities. Classes should be small and cohesive. The code should be as self-explanatory as possible.
However, despite the obvious logic behind this, it's incredibly easy to fall into the trap of writing overly complex code. Maybe it's because of the pressure to deliver quickly, maybe it's because of the temptation to show how smart we are, or maybe it's just a lack of discipline and experience.
Whatever the reason, the result is code that looks more like a maze than a road. It is full of loops, unnecessary twists and turns that make it difficult to navigate. And so, what should be a straightforward task of reading and understanding code turns into a time and energy consuming challenge.
We need to avoid this! Why? Because we need to make it easier for our teammates, reviewers, or even ourselves, months later, when we've forgotten what our own devious logic was trying to accomplish. Therefore, good code must be transparent in its intent, logical in its flow and, above all, readable by a person with equivalent knowledge of the programming language.
Kent Beck's phrase quoted at the beginning of the article reminds us that, no matter how smart and capable we are, our cognitive abilities are limited. We can't keep an accurate representation of an incredibly complex system in our heads, and when we try, we inevitably lose track of the details. This results in bugs, regressions, and the famous expression "it works, but I don't know why".
So what can we do to fight complexity and ensure our systems are understandable to humans?
Go for simplicity!
The first encouragement is to embrace simplicity. This may seem like trivial advice, but in practice it can be incredibly challenging. Simplicity often requires us to be disciplined to resist the temptation to add "just one more feature", or utilize that shiny new design pattern we've just learned, when a simpler, more straightforward solution could serve just as well or better.
Simplicity also implies making our code as declarative as possible. Rather than focusing on how something should be done (which often leads to cryptic imperative algorithms), we should strive to describe what we want done, leaving the implementation details to the software libraries and programming language. that we are using. This makes our code easier to read and understand, and it also opens the door to optimizations that the machine can perform better than we can.
It is true that embracing simplicity is a challenging task. It is an exercise in restraint and discipline. Resisting the temptation to add "just one more feature", avoiding using complex design patterns when a simpler solution will do just as well, requires a degree of self-control that is often lacking in our rush to produce and deliver. And that is often a big obstacle!
Why is it so hard to keep things simple?
One reason could be that as developers we tend to fall in love with our own algorithms. We treat each line like an artist treats each brushstroke, each note like a composer treats his symphony. The problem is that, unlike art or music, code is not meant to be appreciated for its intrinsic beauty. Code is a tool for solving problems.
But we know that software engineers face a series of design decisions. Some of these choices can take the software out of the way of simplicity. We can comment on the main ones:
Premature optimization: It is common for developers to fall into the temptation of prematurely optimizing, trying to achieve incredible performance before they are even sure that the code is working correctly. This can lead to complex structures that are difficult to understand and maintain. As Donald Knuth said, "Premature optimization is the root of all evil."
Over-Engineered Architectures: We often design complex architectures with many interconnected components, anticipating possible future requirements. While it's important to consider software growth and evolution, creating over-engineered architectures can add unnecessary complexity and make code harder to understand and maintain.
Ignore Technical Debt: The much-talked-about technical debt refers to development decisions that may facilitate progress in the short term but are likely to cause problems in the long term. Ignoring it can result in more complex code that is difficult to maintain over time.
All of these examples serve as reminders that simplicity in software design is a goal that requires careful balance. Keeping simplicity in mind when making design decisions can help you avoid these pitfalls and create a more readable design that is easy to maintain and test.
Achieving simplicity may seem like a daunting task, but it can be best addressed by following a few steps:
Understand the Problem: Before writing a single line of code, it's critical to understand the problem you're trying to solve. The clearer the understanding of the problem, the easier it will be to identify the simplest and most straightforward solution. We'll talk more about that shortly.
Plan Before Programming: Think of the solution before you start programming. Sketch the program flow and major components. This can help you identify the simplest approach to implementing the solution.
KISS Principle (Keep It Simple, Stupid): This principle is a constant reminder to keep your code as simple as possible. Whenever you add unnecessary complexity, take a step back and think about how you can simplify.
Use Declarative Programming When Possible: As mentioned earlier, declarative programming, which describes what the program is supposed to do without spelling out how, can lead to simpler and easier to understand code.
Regular Refactoring: Refactoring is the process of changing the structure of code without changing its behavior to improve readability and reduce complexity. Doing this regularly can help keep your code simple.
Write Unit Tests: Unit tests not only help ensure that what you write works as expected, but also force you to write code that is testable. When we think about testability we tend to write in a more modular and simpler way.
Code Review and Feedback: Peer code review and feedback are great ways to ensure every line is understandable and simple. If other developers understand what's written, chances are you're on the right track.
Let's see a clear example that can help explain better what decisions are all about.
The simpler to read, the better!
When we think about writing or improving a certain piece of code, we must first simplify the reading. Probably already faced this problem. Let's use as an example the excessive use of logical operators in a single conditional structure. It is natural to use these language resources, as they are fundamental for controlling the software flow. However, overly complex conditions can make software difficult to understand and maintain. Look at the example below:

There are too many checks happening on a single line. A person reading this for the first time may find it difficult to understand the logic being applied. The conditions for approving the loan are all mixed up, and it takes some cognitive effort to discern what exactly is being checked. This can make code more error-prone as it is harder to read and therefore harder to review and debug.
It is important to highlight the lack of modularity, this is worrying and shows that something in the design and choices is giving off some bad smells. Loan approval logic is being carried out practically in a single method. This makes it difficult to maintain and add new validations or modify existing ones. It is difficult to write the unit tests as well, we may end up missing some important test scenario!
Let's imagine that in the future you need to change the credit rating logic, perhaps you need a minimum of 750 instead of 700. Now you would have to find that particular line of code and change it, risking in the process introducing a bug.
Last but not least, there is a clear lack of transparency about the business rules this code is trying to implement. The programmer reading this will have to interpret the logic behind the conditions to understand what is considered a loan-eligible customer. This can be a big problem, especially when new developers join the team or when business rules need to be revised.
These three facts highlight the importance of maintaining simplicity and clarity when writing code.

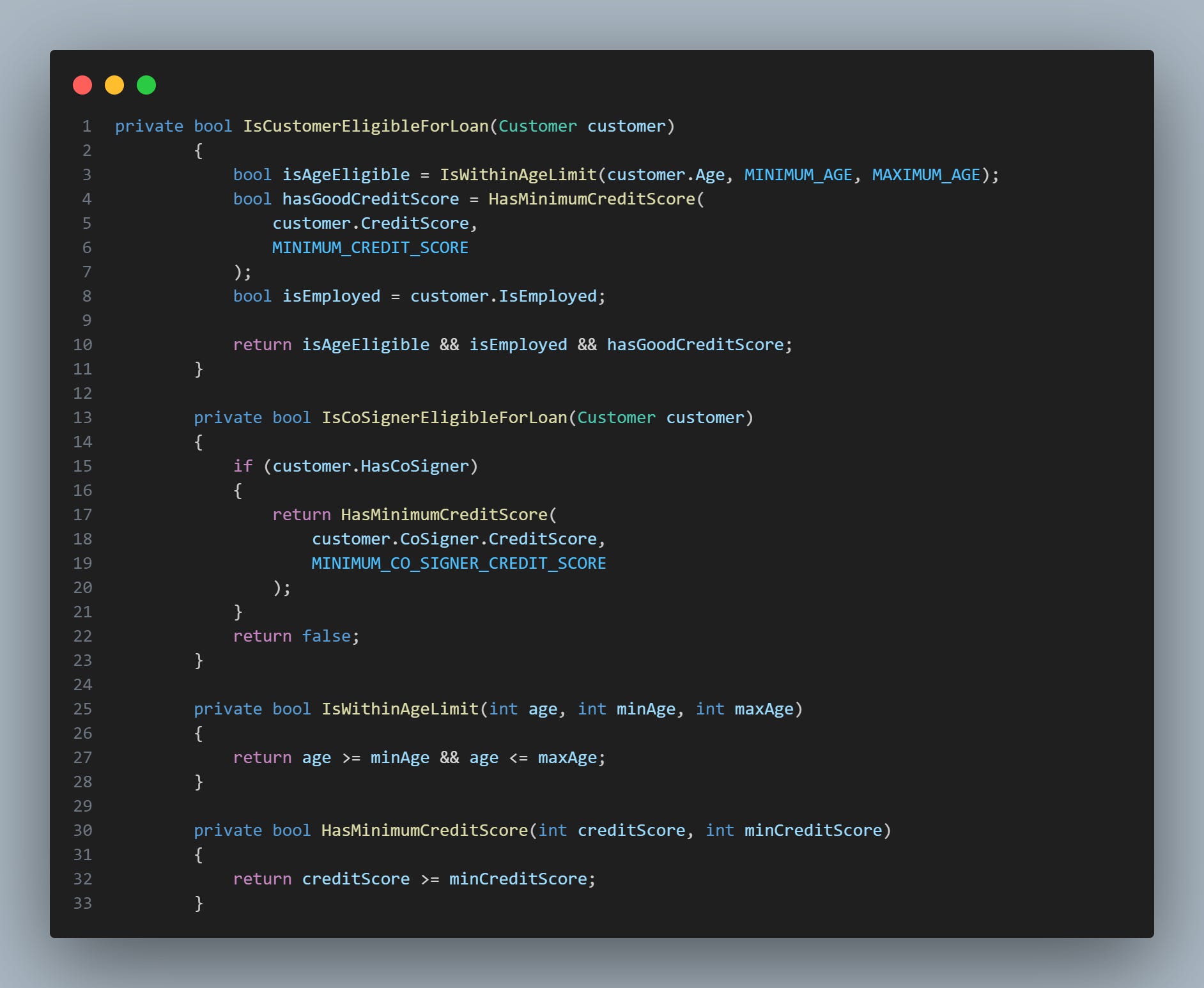
This refactoring makes things clearer. You might even ask yourself: “Why in the IsCustomerEligibleForLoan() method, was the return not passed directly?” As in the image below:

Well I think it's important to explain this. Defining the eligibility conditions as separate boolean variables, such as isAgeEligible, hasGoodCreditScore and isEmployed, has advantages and disadvantages that depend mainly on the context in which they are inserted.
One of the advantages of this approach is the ease of debugging. By defining complex conditions as separate variables, it's easier to track which specific condition failed during code execution. For example, if the IsCustomerEligibleForLoan method returns false, it would be easy to check which of the conditions returned false through debugging or even the log, depending on how the code was written.
Furthermore, this approach can also improve readability and maintainability. By assigning conditions to well-named variables, we are essentially documenting the code. A future developer (or even you in the future) will have a more immediate understanding of what each condition is checking for, without having to decipher a boolean expression.
But not everything is party, this approach also has its drawbacks. First, it can lead to more verbose code. In cases where the conditions are quite simple and readability is not seriously compromised, it may be more efficient to combine all the conditions into a single return expression.
Second, there may be a slight loss of efficiency as all conditions are evaluated, even if an early condition fails. This might not be noticeable in most cases, but in a high-performance environment, every little optimization counts. Take these points into consideration for your context!
A very essential point I would like to highlight is about avoiding magic numbers in our code, let's get straight to the benefits of avoiding them:
Clarity of meaning: When you see a number like 700 or 60, it can be difficult to understand what these numbers mean. By using a constant with a descriptive name, such as MINIMUM_CREDIT_SCORE or MAXIMUM_AGE, it is immediately clear to the code reader what these values mean.
Ease of maintenance: Suppose you need to change the value of MINIMUM_CREDIT_SCORE from 700 to 750. If this value is used in multiple places and you have used the number 700 directly, you would have to look for all instances of the number 700 and change each one to 750. This can be error prone as not all 700's in your code may refer to the MINIMUM_CREDIT_SCORE. However, if you used a constant, you only need to change the constant value in one place.
Error reduction: When you use numbers directly in code, you are more likely to make mistakes, such as typing 800 instead of 80. With constants, these errors are less likely because you only set the value of the constant once.
Consistency and reuse: If you have a value that is used in multiple places, setting that value to a constant ensures that the same value is used everywhere. This is especially useful if the value is somewhat complicated or if there is a chance that the value will change in the future.
The example that was presented clearly has its limitations for some contexts, but the essence of the message remains the same, write code for humans, to make everyone's work easier!
Question, question and question!
The first reflection we should make after finishing writing any line is: Could a human understand this? Then we can do others following this line of reasoning:
Is what was written structured so that a human can easily write tests?
Do variable and function names allow a human to easily understand what each component is doing?
Is the code structured in such a way as to minimize the amount of time a human would spend reading and understanding it?
Are there any pieces of code that seem unintelligible that could be rewritten to improve readability for a human?
Is the code written in such a way that a human can easily predict the outcome of any changes made to the code?
But it's important not to get lost! Focus on creating code that fulfills the expected objective, but at the same time evaluate how clear it is to understand the flow and each business rule that was written.
For simplicity understand the problem!
This is a big wake-up call! The more we understand about the problem we are trying to solve, the easier it will be to think and write code that humans can understand. Why is this true?
The programmer is, above all, a problem solver. Therefore, the fundamental task that all of us have is to understand the problem before starting to solve it. This deep understanding is, in itself, a powerful tool for creating readable, efficient, and maintainable code.
To better understand this statement, we must consider the coding process not only as a technical task, but also as an intellectual and creative activity. Writing code is, in essence, translating a real-world problem into a language the machine can understand, and thereby producing the desired solution.
Let's visualize this better. When a programmer does not clearly understand the problem, the ramifications can be quite negative.
Ramifications are the possible consequences and developments that arise from a particular choice. Every decision we make while programming has the potential to cause a range of outcomes - some desirable, some not. These developments, or ramifications, can affect the course of the project in both the short and long term.
Understanding the ramifications is crucial to making informed decisions. When you understand what might happen based on a specific choice, you are better equipped to make a decision that will benefit the project in the long run.
For example, if we decide to implement a feature in a quick and unstructured way, that is, we don't stop to analyze the problem and we don't plan, but we do it just to meet an immediate demand, the immediate branch can be the satisfaction of the urgent need. However, the long-term ramifications of this decision could include code that is difficult to maintain, with more chance of errors and more time spent on future changes to that functionality. As the drawing below tries to illustrate this:]
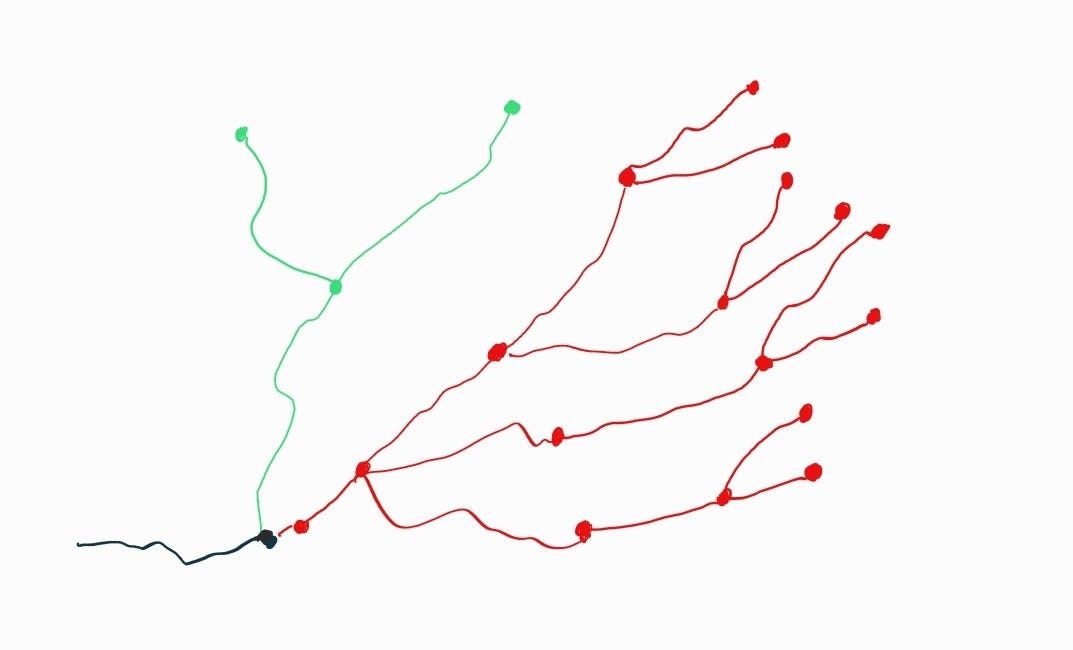
These decisions, and their consequent ramifications, can be visualized as a decision tree, where each node represents a choice and each branch represents a possible outcome. In this sense, it is possible to make a comparison with graph theory in mathematics, where the objective is to find the most efficient path between two points. With each decision made, the number of possible future paths (or branches) increases, and each of these paths has its own implications and possible outcomes.
Therefore, it is crucial that programmers have a clear understanding of not only the immediate problem they are trying to solve, but also how their decisions could impact the future of the project.
When we deeply understand the problem, we are able to visualize the best strategy to solve it. This understanding allows each of us to identify which parts of the problem are crucial, which are secondary, and which can be broken down into smaller sub-problems. With this panorama in mind, we can logically and coherently structure each line, making it easier for other developers to read and understand.
Another point I've come across in recent years is that a deep understanding of the problem allows writing code that really meets the user's needs. Many times, in the rush to produce a solution, we can end up writing something that, although correct, does not effectively address the problem the customer has. Understanding the problem in depth allows you to avoid this type of mismatch.
Conclusion
Finally, the question "Could a human understand this?" is fundamental in software development. It directly affects code readability, system maintainability and, ultimately, the quality of the software produced. Human understandability should be at the forefront of a programmer's considerations, not just for the immediate benefit of teammates or himself in the future, but also for the long-term sustainability of the project.
If code is written in a way that a human can easily understand, it is likely to be more efficient to test, debug, modify, and extend. Furthermore, this approach promotes better and cleaner coding practices, which leads to more robust and reliable systems.
Simplicity is therefore a deliberate choice that programmers must make in order to achieve clear and readable algorithms. Just as an author of a book strives to ensure that his message is understood by the reader, a programmer must strive to ensure that his code is easily understood by other programmers. This is the part that many programmers miss and the science of software development, an intersection of technology and humanity where every line of code is a decision made, every decision has ramifications, and every ramification has an impact on human understanding.
Thus, when faced with the question, "Could a human understand this?", a programmer must be aware that the answer to this question can be the divider between sustainable and efficient software and problematic and complex software. Ultimately, the goal is to create code that humans can not only understand, but that is inviting, easy to work with, and easy to maintain.
I'm here for this post. If you like it, please share it with other developers! Comment if you want. I am also available to answer questions through LinkedIn. Until the next post folks! 😉