


Comunicação Entre Microsserviços: Estilos e Estratégias
A promessa dos microserviços é permitir atualizações e manutenção de partes individuais do sistema sem impactar negativamente o todo, mas isso exige uma boa estratégia de comunicação.

No livro "Building Microservices: Designing Fine-Grained Systems", Sam Newman aponta para tipos de estilos de comunicação que um ecossistema distribuído pode adotar. Neste artigo, comentaremos sobre cada um desses estilos, utilizando diagramas e exemplos para facilitar a compreensão. Além disso, discutiremos os impactos, vantagens e desvantagens de cada estilo.
Então, sem mais delongas, vamos direto ao primeiro estilo.
Comunicação Síncrona Bloqueante
Vamos imaginar que você está em um restaurante fazendo um pedido. Você diz ao garçom o que deseja, e ele vai até a cozinha para entregar seu pedido ao chef que irá preparar sua comida. Enquanto isso, você está esperando na mesa, sem fazer mais nada, até que o garçom volte com seu prato. Nesse cenário, você está bloqueado, aguardando a resposta (seu prato de comida) antes de poder continuar a refeição.

Este é um exemplo de comunicação síncrona bloqueante na vida real: você (o cliente) faz uma solicitação (pedido de comida), e seu processo (esperar na mesa) fica parado até que a solicitação seja atendida (o prato chegar).
No contexto de microsserviços, esse padrão funciona de forma semelhante. Quando um microsserviço faz uma chamada a outro serviço para realizar uma tarefa ou obter dados, ele fica parado, aguardando a resposta antes de continuar com seu próprio processamento. Tá vamos exemplificar isso.
A comunicação síncrona bloqueante, como a gente vê na vida real com o exemplo de pedir comida em um restaurante, tem suas vantagens e é bastante útil em várias situações. Imagine que o Serviço A precisa verificar os pontos de fidelidade de um cliente antes de processar um pedido. Ele faz uma chamada ao Serviço B (responsável pela fidelidade) e espera a resposta antes de continuar. Isso é uma comunicação síncrona bloqueante.
Agora, por que isso é bom? Bem, primeiro, é super simples de entender e implementar. O fluxo é bem claro: eu peço, você responde, e eu continuo. Nada de muito complicado. Além disso, garante que o Serviço A só vai continuar o processamento se tiver certeza de que os pontos de fidelidade foram corretamente verificados. Isso é crucial em operações onde você não pode ter margem para erro, como em transações financeiras ou quando você precisa de uma confirmação imediata para prosseguir.
Outro ponto positivo é a previsibilidade. Como tudo segue uma ordem sequencial, é fácil rastrear e debugar se algo der errado. Você sabe exatamente onde procurar, já que cada passo depende do anterior ter sido concluído com sucesso.
Claro, essa abordagem pode introduzir um pouco de latência, porque o Serviço A fica esperando a resposta do Serviço B. Mas em muitos casos, essa espera é aceitável e garante que tudo está funcionando como deveria. Então, embora tenha seus trade-offs, a comunicação síncrona bloqueante é uma ferramenta valiosa no kit de ferramentas de qualquer arquiteto de microsserviços.
A imagem abaixo retrata esse tipo de comunicação comum:

Mas nem tudo são flores… vamos conversar sobre alguns pontos de atenção.
Os cuidados que devemos ter com a comunicação bloqueante!
Embora a comunicação síncrona bloqueante seja bastante útil e simples, é importante estar ciente de algumas desvantagens associadas a ela, como destacou Sam Newman.
Um dos principais desafios com chamadas síncronas é o acoplamento temporário inerente. Pense nisso como uma dança em que um parceiro depende totalmente do outro para dar o próximo passo.
Visualize um e-commerce. Quando o Processador de Pedido faz uma chamada para o microsserviço Fidelidade, o microsserviço Fidelidade precisa estar disponível para que a chamada funcione. Se o microsserviço Fidelidade estiver indisponível, a chamada falha e o Processador de Pedido precisa decidir o que fazer. Isso pode significar tentar novamente imediatamente, guardar a chamada para mais tarde, ou talvez desistir completamente.
Esse acoplamento é bidirecional. A resposta geralmente é enviada pela mesma conexão de rede, o que significa que se o Serviço A precisa de uma resposta do Serviço B, mas se algo acontecer no meio do caminho, essa resposta pode ser perdida. O Processador de Pedido ficará esperando até que a resposta chegue, e se houver qualquer problema, ele simplesmente não vai conseguir continuar.

Agora, imagine que o Serviço A está esperando por uma resposta e o Serviço B está sob carga pesada, demorando para responder. O Serviço A fica parado, esperando, e isso pode causar problemas de latência. Se houver muitos serviços fazendo isso ao mesmo tempo, seu sistema pode começar a se comportar como um restaurante lotado onde todos os clientes estão esperando por comida que demora para sair da cozinha. Pode virar um caos.
Então, a grande sacada aqui é saber quando usar esse tipo de comunicação. Para arquiteturas de microsserviços, as chamadas síncronas bloqueantes podem funcionar bem. Muitos programadores já estão familiarizadas com elas e elas são fáceis de entender e implementar. Mas, conforme seu sistema cresce e você começa a ter mais cadeias de chamadas, esse tipo de comunicação pode se tornar um problema.
Por exemplo, se o Processador de Pedido chama o serviço Pagamento, que por sua vez chama o serviço de Detecção de Fraudes, que precisa consultar outro serviço para obter informações, você cria uma longa cadeia de dependências. Cada chamada síncrona adiciona um ponto de potencial falha e latência, isso se não causarem uma 1.
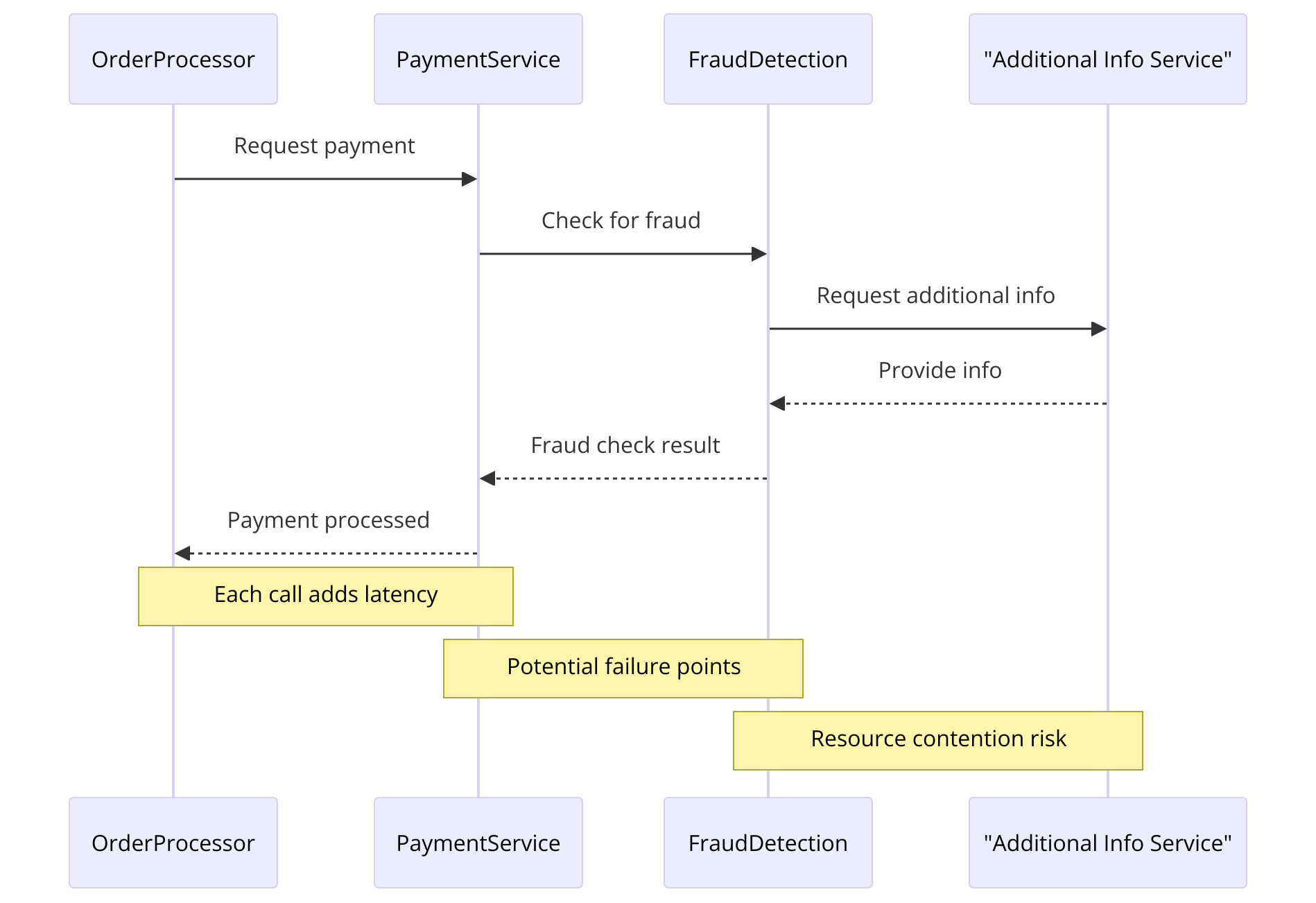
Estratégia para Diminuir Cadeias de Serviços Bloqueantes
Uma maneira inteligente de lidar com cadeias de serviços bloqueantes é mover algumas operações para segundo plano ou distribuí-las ao longo da jornada do usuário. Sam Newman destaca essa estratégia ao discutir a detecção de fraudes.
Imagine que você tem um sistema de e-commerce onde o serviço de Processamento de Pedidos precisa validar o pagamento. Naturalmente, você quer ter certeza de que o pagamento é legítimo e não uma tentativa de fraude. Em um cenário de comunicação síncrona bloqueante, o serviço de Processamento de Pedidos chamaria diretamente o serviço de Detecção de Fraudes, que então consultaria outros serviços como Histórico de Transações e Análise de Comportamento antes de retornar uma resposta. Cada um desses passos adiciona latência e cria uma cadeia de dependências.
Veja como isso pode ser feito:
1. Pré-Validação
Descrição: Antes do usuário completar a compra, você pode realizar algumas verificações preliminares.
Exemplo: Quando o usuário adiciona um item ao carrinho, você já pode iniciar uma verificação de comportamento suspeito. Isso não precisa ser bloqueante e pode ser feito de maneira assíncrona, com os resultados prontos quando o usuário estiver prestes a finalizar a compra.
2. Validação em Segundo Plano
Descrição: Algumas verificações de fraude podem ser feitas depois que o pedido foi realizado, mas antes do envio.
Exemplo: Após o pagamento ser processado, um serviço de verificação de fraude pode analisar a transação. Se algo suspeito for encontrado, o pedido pode ser colocado em espera para revisão manual, enquanto a maior parte do fluxo continua normalmente.
3. Notificações e Monitoramento
Descrição: Em vez de bloquear o processamento enquanto espera pela validação completa, você pode monitorar transações em segundo plano.
Exemplo: Podemos utilizar sistemas de monitoramento e alertas para notificar os administradores se uma transação suspeita for detectada após o pedido ter sido processado.
O diagrama a seguir tenta representar isso, obviamente existem detalhes que um ecossistema anti-fraude pode considerar, o diagrama serve apenas para um esclarecimento visual do que estamos conversando:
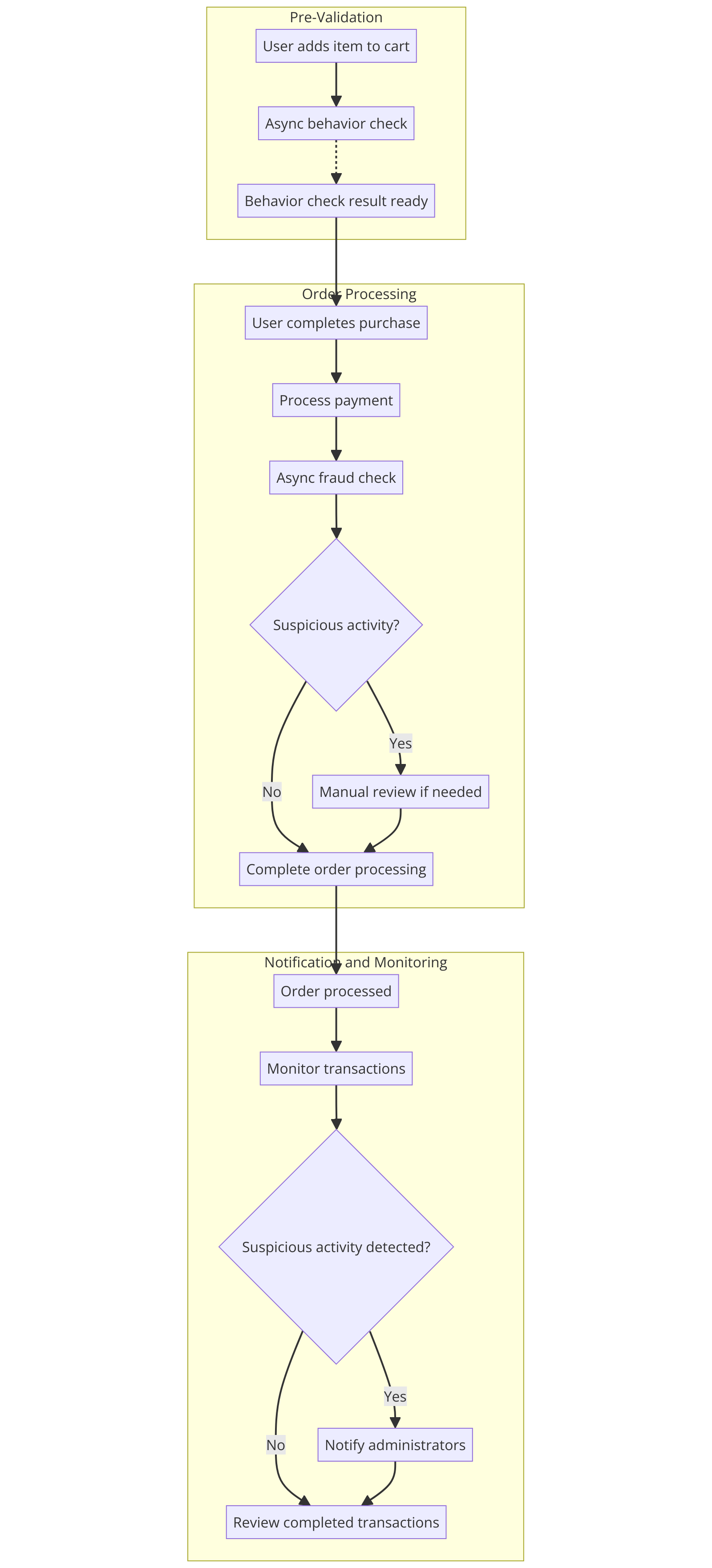
Aplicação na Detecção de Fraudes
Sam Newman sugere que essa abordagem é particularmente útil. Ao distribuir as verificações de fraude ao longo da jornada do usuário, você reduz a carga de dependências bloqueantes. Por exemplo:
Durante a Navegação: Coletar dados sobre o comportamento do usuário.
No Checkout: Realizar verificações iniciais rápidas e continuar com verificações mais detalhadas em segundo plano.
Pós-Compra: Analisar transações com maior profundidade após a compra, enquanto o pedido está em processamento ou antes do envio.
Benefícios
Redução de Latência: Ao mover operações intensivas para segundo plano, você reduz o tempo de resposta e melhora a experiência do usuário.
Aumento da Resiliência: Menos dependências diretas entre serviços significa que falhas em um serviço não paralisarão todo o sistema.
Escalabilidade: Operações assíncronas podem ser escaladas mais facilmente e processadas em lote, se necessário.
Para determinar se devemos utilizar comunicação síncrona bloqueante em operações de requisitos de negócio, Sam Newman sugere considerar alguns fatores-chave. Vamos reforçar cada um deles.
Analisando a Necessidade de Comunicação Síncrona Bloqueante
1. Criticidade da Operação
Pergunta-chave: A operação exige uma confirmação imediata para o fluxo do negócio?
Exemplo: Imagine um sistema de reserva de passagens aéreas. Quando um cliente clica para confirmar a reserva, o sistema precisa garantir que o assento está disponível e reservado para aquele cliente especificamente. Nesse caso, uma comunicação síncrona bloqueante faz sentido, pois o serviço de Reserva precisa uma resposta imediata do serviço de Disponibilidade de Assentos antes de continuar.
2. Impacto da Latência
Pergunta-chave: A latência na comunicação afetará significativamente a experiência do usuário ou a eficiência do sistema?
Exemplo: Pense em um serviço de recomendação de produtos. Se o sistema precisar buscar recomendações de vários serviços diferentes para mostrar produtos personalizados, a latência pode ser menos crítica. Aqui, usar comunicação assíncrona pode ser mais adequado, permitindo que o sistema agregue resultados de forma não bloqueante e melhore a escalabilidade.
3. Resiliência e Tolerância a Falhas
Pergunta-chave: O sistema precisa ser altamente resiliente e tolerante a falhas?
Exemplo: Considere um sistema de processamento de pedidos em uma loja online. Se o serviço de Pagamentos falhar, é crucial que o sistema possa lidar com essa falha sem impactar negativamente a experiência do cliente. Utilizar comunicação assíncrona com padrões de fallback e retries pode aumentar a resiliência do sistema, evitando que uma falha temporária cause problemas maiores.
4. Dependências e Cadeias de Chamada
Pergunta-chave: A operação envolve muitas dependências ou uma longa cadeia de chamadas?
Exemplo: Visualize um sistema de entrega onde o serviço de Rastreamento de Entregas precisa consultar o serviço de Inventário, que por sua vez consulta o serviço de Logística. Cada serviço depende de uma resposta do anterior. Se cada serviço na cadeia usar comunicação síncrona bloqueante, isso pode introduzir grandes latências e pontos de falha. Alternativamente, utilizando comunicação assíncrona, cada serviço pode continuar seu trabalho independentemente, melhorando a eficiência e a resiliência do sistema.
Ao avaliar se deve usar comunicação síncrona bloqueante, Sam Newman sugere que você deve pesar esses fatores:
Criticidade: Use comunicação síncrona bloqueante para operações que requerem confirmação imediata.
Latência: Se a latência for aceitável, considere comunicação assíncrona para melhorar a escalabilidade.
Resiliência: Para aumentar a resiliência, especialmente em sistemas complexos com muitas dependências, comunicação assíncrona pode ser mais vantajosa.
Cadeias de Chamada: Evite longas cadeias de chamadas síncronas, pois elas podem introduzir pontos de falha e latência acumulada.
Mas talvez você prefira algo não bloqueante em comunicações entre serviços distintos, por isso vamos conversar mais detalhadamente sobre essa estratégia.
Assíncrono Não-Bloqueante
Imagine que você está organizando uma festa e precisa encomendar uma pizza. Você liga para a pizzaria, faz o pedido e o atendente diz que a pizza será entregue em 30 minutos. Em vez de ficar esperando perto do telefone, você continua preparando a festa: coloca as bebidas na geladeira, arruma a decoração e conversa com os convidados. Depois de algum tempo, a campainha toca e a pizza chega. Você recebe a pizza e volta para a festa sem perder tempo esperando.
Esse é um exemplo de comunicação assíncrona não bloqueante: você fez a solicitação (pedido da pizza) e continuou com suas tarefas enquanto esperava a resposta (entrega da pizza).
Se analogia não deixou claro, vou simplificar mais. Comunicação Sincrona é você esperar no telefone um atendente confirmar seus dados. Comunicação Assíncrona Não Bloqueante é você enviar um e-mail e fazer outras tarefas sem se preocupar imediatamente por uma resposta, obviamente a pessoa que recebeu o e-mail não precisa responder imediatamente, ela pode estar ocupada tratando de outras atividades.

A Vantagem do Desacoplamento Temporal
Em uma comunicação assíncrona não bloqueante, o microsserviço que faz a chamada inicial e o microsserviço que recebe a chamada estão temporariamente desacoplados. Assim como na analogia do e-mail e da festa, os microsserviços que recebem a chamada não precisam estar acessíveis no mesmo instante em que a chamada é feita.
O grande benefício desse estilo de comunicação é o desacoplamento temporal. Os serviços não precisam estar "sincronizados" em tempo real, o que aumenta a resiliência e a eficiência do sistema. Isso é especialmente útil se a funcionalidade acionada por uma chamada demorar muito para ser processada. Em vez de tudo parar até que a tarefa seja concluída, cada parte do sistema pode continuar trabalhando de maneira independente.
Vamos voltar para o serviço de e-commerce que o serviço de Processamento de Pedidos precisa verificar a detecção de fraudes, mas isso pode levar algum tempo. Em vez de ficar bloqueado, o Processador de Pedidos pode enviar a solicitação de verificação de fraude e continuar com outras partes do processamento do pedido. Quando a verificação estiver concluída, ele será notificado com os resultados, permitindo que a operação prossiga de maneira fluida e eficiente.
Vamos conversar brevemente sobre as diversas estratégias de comunicação assíncrona.
Quais os Tipos de Comunicação Assíncrona Não Bloqueante?
Quando falamos de comunicação assíncrona não bloqueante, não estamos apenas falando de disparar eventos. Mas envolve qualquer forma de comunicação onde o serviço que faz a chamada continua com outras tarefas sem se preocupar com uma resposta imediata. Vamos ver algumas das maneiras mais comuns de implementar essa comunicação assíncrona.
Message Queues
Pense nas Message Queues como uma biblioteca com uma estante de devoluções. Quando você (produtor) devolve um livro, você o coloca na estante de devoluções específica, mas não espera saber quem está interessado em processar ou ler aquele livro no futuro. Os bibliotecários ou pessoas interessadas no livro (consumidores) sabem que precisam pegar os livros dessa estante para processá-los ou lê-los. Eles não precisam saber quem devolveu o livro, mas sabem exatamente onde encontrar os livros que precisam processar.

Neste caso, a estante de devoluções representa um serviço de mensageria, como RabbitMQ ou Kafka, que entrega a mensagem (evento) para os serviços interessados. Aqui, o principal ponto é que quem publica a mensagem na fila (quem devolve o livro na estante) não precisa saber quem vai recebê-la.
Exemplo: Você tem um serviço de Processamento de Pedidos que precisa verificar o estoque. Em vez de esperar uma resposta imediata do serviço de Inventário, ele coloca uma mensagem na fila. O serviço de Inventário pega a mensagem, processa a verificação e depois coloca a resposta de volta na fila. O Processador de Pedidos pega a resposta quando estiver pronto.
Publicação e Assinatura (Pub/Sub)
O padrão Pub/Sub é uma implementação da arquitetura orientada a eventos. Pense nisso como um sistema de anúncios por alto-falante. Um serviço (o publicador) envia uma mensagem para um tópico, e qualquer serviço interessado nesse tópico (os assinantes) recebe a mensagem. Isso é muito útil para sistemas onde várias partes podem estar interessadas na mesma informação.
Exemplo: Suponha que você tenha um serviço de Pedidos que publica um evento toda vez que um pedido é criado. Vários outros serviços, como o de Faturamento, Inventário e Notificações, podem se inscrever nesse evento e reagir de acordo. O serviço de Pedidos não precisa saber quem está ouvindo, ele apenas publica o evento.
Você pode usar sistemas como Apache Kafka, Google Pub/Sub ou Redis. A ideia é configurar tópicos para publicação, onde um serviço publica mensagens e qualquer outro serviço que esteja inscrito nesses tópicos recebe as mensagens. Isso permite que você envie notificações para múltiplos serviços de uma vez, sem precisar saber quem está ouvindo.
Webhooks
Imagine um webhook como assinar uma revista. Você pode assinar uma revista mensal e em vez de ir à loja todos os dias para ver se a nova edição chegou, a editora da revista envia a nova edição diretamente para sua casa assim que é lançada.
De maneira similar, um webhook é uma API leve que envia notificações para outros aplicativos quando ocorre um evento específico. Por exemplo, você pode criar um webhook que envie uma notificação para sua plataforma de marketing por e-mail sempre que um novo lead for captado em seu CRM.
Em suma, webhooks são como gatilhos orientados por eventos, frequentemente usados para integrações em tempo real. Eles enviam notificações assim que a atividade ocorre, mantendo seus sistemas atualizados com as informações mais recentes sem que você precise verificar constantemente por atualizações. Isso pode ser útil para tarefas como enviar confirmações de pedido, atualizar perfis de clientes ou acionar campanhas de marketing.
Streams de Dados
Streams de dados são fluxos contínuos de dados que podem ser processados em tempo real. Pense nisso como um rio de dados fluindo constantemente, onde vários serviços podem se conectar para consumir dados à medida que eles chegam.
Exemplo: Em uma plataforma de monitoramento de desempenho, os dados de uso e métricas são continuamente enviados para um stream. Serviços como Análise de Performance ou Alertas em Tempo Real podem consumir esses dados do stream e agir imediatamente com base nas informações recebidas.
Implementar webhooks envolve configurar endpoints HTTP nos serviços que desejam receber notificações. O serviço emissor envia requisições HTTP para esses endpoints quando eventos específicos ocorrem. Ferramentas como RestTemplate (no caso de Java) ou bibliotecas HTTP em outras linguagens são comumente usadas para essa comunicação.
Dados em Comum
Sam Newman destaca uma abordagem chamada "Dados em Comum", onde a colaboração assíncrona não bloqueante entre microsserviços ocorre por meio de uma fonte de dados compartilhada. Isso permite que os serviços leiam e escrevam dados conforme necessário, sem depender de uma resposta imediata de outro serviço.
Exemplo: Imagine um serviço de Inventário e um serviço de Encomendas que precisam acessar informações sobre produtos. Em vez de um serviço solicitar dados diretamente do outro, ambos acessam um banco de dados compartilhado onde essas informações são armazenadas. O serviço de Inventário atualiza os níveis de estoque, enquanto o serviço de Encomendas lê esses dados para processar novos pedidos.
Para trabalhar com streams de dados, plataformas como Apache Kafka Streams ou Apache Flink são escolhas válidas. Elas permitem que você configure produtores para enviar dados contínuos para um stream, e consumidores para processar esses dados em tempo real. Isso é especialmente útil para aplicações que exigem processamento de dados em tempo real, como análise de performance ou monitoramento.
Espero trazer em detalhes cada um desses tipos em outros posts, por enquanto vamos arranhar a superficie. Vamos entender melhor a diferença entre Message Queues e Pub/Sub.
Comparação Message Queues e Pub/Sub
Ambos os modelos oferecem dissociação, mas de maneiras ligeiramente diferentes:
Message Queues: O produtor e o consumidor são desacoplados através do uso de uma fila específica. O produtor coloca eventos na fila e o consumidor lê da fila, sem conhecer um ao outro.
Pub/Sub: O publicador e os assinantes são desacoplados através do uso de tópicos. O publicador envia mensagens para um tópico e os assinantes se inscrevem no tópico para receber as mensagens, sem precisar conhecer um ao outro.
Mas existe um ponto importante que diferencia esses dois tipos de comunicação assíncrona que pode não ser claramente vista ou entendida. Vamos discutir isso.
Comparação Técnica
Padrão de mensagens:
Sistema Pub/Sub: Em um sistema Pub/Sub, as mensagens são publicadas em um tópico, e vários assinantes podem recebê-las. Publicadores e assinantes são desacoplados, e os assinantes expressam interesse em tópicos específicos. Quando uma mensagem é publicada em um tópico, todos os assinantes interessados recebem uma cópia da mensagem.
Filas: Em um sistema baseado em fila, as mensagens são enviadas para uma fila e um ou mais consumidores (assinantes) processam mensagens da fila. As mensagens normalmente são consumidas na ordem FIFO (primeiro a entrar, primeiro a sair). Cada mensagem normalmente é processada por apenas um consumidor.
Dissociação:
Sistema Pub/Sub: Os sistemas Pub/Sub fornecem acoplamento flexível entre editores e assinantes. Os editores não precisam saber quem são os assinantes e vice-versa. Isso promove flexibilidade e escalabilidade.
Filas: Embora as filas também forneçam algum nível de desacoplamento, elas geralmente envolvem um relacionamento mais direto entre produtores (remetentes de mensagens) e consumidores (processadores de mensagens). Os produtores enviam mensagens para uma fila específica, e os consumidores pesquisam ou escutam essa fila.
São muitos assuntos para conversar e nem todos vou conseguir escrever neste post, mas caso tenha alguma dúvida, por favor, compartilhe nos comentários. Vou colocar na nota algumas conclusões sobre esse assunto Pub/Sub VS Message Queues.2
Processamento em Lote
Processamento em lote é outra maneira de lidar com comunicação assíncrona. Em vez de processar cada solicitação individualmente e imediatamente, você acumula várias solicitações e as processa todas de uma vez em um intervalo de tempo. Isso permite lidar com grandes volumes de dados de maneira eficiente.
Exemplo: Um serviço de Relatórios pode acumular dados durante o dia e processar tudo à noite, gerando relatórios em lote. Isso é eficiente e reduz a carga no sistema durante horários de pico.
Para processamento em lote, frameworks como Spring Batch ou ferramentas como Apache NiFi são bastante úteis. Você configura jobs que acumulam dados e os processam em intervalos regulares.
Processamento em Lote como Comunicação Assíncrona?
Processamento em lote é, de fato, uma forma de comunicação assíncrona. Veja por quê:
Desacoplamento Temporal: No processamento em lote, a coleta e o processamento de dados são temporariamente desacoplados. As solicitações de dados são acumuladas ao longo do tempo e processadas em um momento posterior, não imediatamente quando a solicitação é feita.
Execução Independente: O sistema que faz a coleta de dados (por exemplo, o serviço de Relatórios) não precisa esperar pelo processamento imediato dos dados. Ele pode continuar a coletar mais dados enquanto o processamento é realizado de forma independente em outro momento.
Redução de Carga em Tempo Real: Processamento em lote permite distribuir a carga de trabalho ao longo do tempo, evitando picos de uso que podem ocorrer com o processamento imediato de cada solicitação. Isso é especialmente útil para tarefas que não exigem processamento imediato, como geração de relatórios diários.
A essência da comunicação assíncrona é que o remetente de uma solicitação não precisa esperar pela conclusão da ação para continuar seu trabalho. Em processamento em lote, a coleta de dados e o processamento são duas fases distintas e independentes, conectadas por uma fila ou armazenamento intermediário de dados. Esta separação permite que o sistema continue funcionando sem bloqueios, exatamente como em outras formas de comunicação assíncrona.
Portanto, o processamento em lote compartilha os mesmos princípios de comunicação assíncrona, tornando-se uma prática válida e eficiente para lidar com grandes volumes de dados sem sobrecarregar o sistema em tempo real.
Desvantagens de Cada Estilo de Comunicação Assíncrona Não Bloqueante
Vários estilos e cada um tem seu ponto forte, mas também carregam pontos fracos. Por isso, um excelente arquiteto de software deve compreender bem não só as tecnologias e estilos, mas o core business para encaixar um estilo que seja uma solução adequada e viável para a organização. Vamos continuar conversando e destacar algumas desvantagens de cada estilo de comunicação assíncrona não bloqueante.
Comunicação Orientada a Eventos com Filas
Message Queuing
O enfileiramento de mensagens tem algumas limitações:
Complexidade: As filas de mensagens podem adicionar uma camada extra de complexidade com a ordem das mensagens, tratamento de prioridades e processamento de mensagens inativas.
Latência: aplicativos com tempo limitado podem enfrentar problemas, pois o enfileiramento e o desenfileiramento podem levar a problemas de latência.
Intensivo em recursos: eles tendem a ocupar uma quantidade significativa de recursos de memória. Isso pode causar problemas se você estiver operando em ambientes com restrição de memória.
Ao optar por um sistema de enfileiramento de mensagens, é importante avaliar esses pontos. A escolha de configurar uma fila de mensagens depende de suas necessidades específicas e dos recursos que você pode alocar. Apesar de algumas desvantagens, os benefícios que oferecem, como robustez, escalabilidade e resiliência, tornam-nos uma escolha popular entre os desenvolvedores.
Publicação e Assinatura (Pub/Sub)
Desvantagem: Complexidade de Monitoramento e Depuração
Embora o modelo Pub/Sub ofereça maior desacoplamento e flexibilidade, ele pode introduzir complexidade adicional na monitorização e depuração. Em um sistema onde múltiplos serviços podem se inscrever em vários tópicos e reagir a eventos, rastrear o fluxo de dados e identificar a origem de um problema pode ser desafiador.
Imagine um cenário onde um evento é publicado em um tópico e vários serviços diferentes reagem a esse evento de maneiras distintas. Se algo der errado, descobrir qual serviço causou o problema ou onde exatamente a falha ocorreu pode ser como encontrar uma agulha no palheiro. Isso exige ferramentas robustas de monitoramento e práticas de logging detalhadas para garantir que problemas possam ser identificados e resolvidos rapidamente.
Processamento em Lote
Desvantagem: Latência
O processamento em lote pode introduzir latência significativa no sistema. Em vez de processar cada mensagem imediatamente, as mensagens são acumuladas e processadas em intervalos regulares. Isso pode ser problemático para aplicações que exigem processamento em tempo real ou respostas rápidas.
Imagine um sistema de análise de dados que processa logs de usuário em lote uma vez por hora. Se você precisar de insights quase em tempo real, como detectar fraudes ou responder a eventos críticos de segurança, a latência introduzida pelo processamento em lote pode ser inaceitável.
Webhooks
Desvantagem: Segurança e Confiabilidade
Webhooks dependem de endpoints HTTP para enviar notificações de eventos. Isso pode introduzir desafios de segurança, como a exposição a ataques de negação de serviço (DDoS). Além disso, a confiabilidade pode ser um problema, pois se o endpoint do webhook estiver indisponível ou sobrecarregado, as notificações podem ser perdidas ou atrasadas.
Por exemplo, se você estiver usando webhooks para enviar notificações de pagamento a um serviço de faturamento, um ataque de DDoS ou uma falha temporária do serviço pode impedir que os pagamentos sejam processados corretamente, causando interrupções significativas no negócio.
Streams de Dados
Desvantagem: Consumo Contínuo de Recursos
Streams de dados exigem recursos contínuos para processamento em tempo real, o que pode ser oneroso em termos de uso de memória e CPU. Além disso, lidar com picos de dados e manter a performance consistente pode ser desafiador.
Imagine um sistema de monitoramento de performance que precisa processar um fluxo constante de métricas em tempo real. Durante picos de tráfego, o sistema pode ficar sobrecarregado, resultando em atrasos ou perda de dados. Manter a performance e a escalabilidade pode exigir uma infraestrutura robusta e complexa.
Dados em Comum
Desvantagem: Concorrência e Consistência
Usar uma fonte de dados compartilhada pode introduzir problemas de concorrência e consistência. Quando múltiplos serviços estão lendo e escrevendo nos mesmos dados, garantir que todos os serviços vejam uma visão consistente dos dados pode ser complicado.
Imagine um sistema de e-commerce onde o serviço de inventário e o serviço de pedidos precisam acessar e atualizar a quantidade de produtos em estoque. Se ambos tentarem atualizar o estoque ao mesmo tempo, pode ocorrer uma condição de corrida, resultando em inconsistências nos dados e possíveis problemas de overselling.3
Analisando a Necessidade de Comunicação Assíncrona Não Bloqueante
Criticidade da Operação
Pergunta-chave: A operação pode ser processada de forma assíncrona sem necessidade de resposta imediata?
Exemplo: Pense em um sistema de processamento de e-mails de marketing. Quando um usuário se inscreve para receber newsletters, o sistema pode processar essa inscrição e enviar um e-mail de confirmação de forma assíncrona. Não há necessidade de uma resposta imediata para o fluxo principal do negócio, tornando a comunicação assíncrona uma escolha ideal.
Tolerância à Latência
Pergunta-chave: A operação pode tolerar alguma latência sem impactar negativamente a experiência do usuário ou a eficiência do sistema?
Exemplo: Considere um sistema de análise de dados de comportamento do usuário. Os dados coletados de várias fontes podem ser processados e analisados de forma assíncrona, permitindo que o sistema funcione sem esperar pela conclusão de cada operação de análise. Isso melhora a escalabilidade e tolera a latência sem afetar a experiência do usuário.
Resiliência e Tolerância a Falhas
Pergunta-chave: O sistema se beneficiaria de maior resiliência e tolerância a falhas através da comunicação assíncrona?
Exemplo: Imagine um sistema de processamento de pedidos em uma loja online. Se o serviço de Inventário está temporariamente indisponível, o pedido pode ser colocado em uma fila e processado assim que o serviço estiver de volta, sem impactar a experiência do cliente. A comunicação assíncrona permite retries automáticos e fallback strategies, aumentando a resiliência do sistema.
Dependências e Cadeias de Chamada
Pergunta-chave: A operação envolve múltiplas dependências ou uma cadeia de chamadas que podem ser desacopladas?
Exemplo: Visualize um sistema de entrega onde o serviço de Rastreamento de Entregas precisa consultar o serviço de Inventário, que por sua vez consulta o serviço de Logística. Utilizando comunicação assíncrona, cada serviço pode enviar e receber mensagens independentemente, sem esperar pela resposta do serviço anterior. Isso reduz a latência acumulada e melhora a eficiência do sistema.
Ao avaliar se deve usar comunicação assíncrona não bloqueante, considere os seguintes fatores:
Criticidade: Utilize comunicação assíncrona para operações que não requerem confirmação imediata.
Latência: Se a operação puder tolerar alguma latência, comunicação assíncrona pode melhorar a escalabilidade.
Resiliência: Para aumentar a resiliência e tolerância a falhas, especialmente em sistemas complexos, comunicação assíncrona é vantajosa.
Dependências: Evite longas cadeias de chamadas síncronas, pois comunicação assíncrona pode desacoplar serviços e reduzir pontos de falha.
Seguindo esses princípios, é possível aproveitar ao máximo as vantagens da comunicação assíncrona não bloqueante, conforme discutido por Sam Newman em seu livro sobre microserviços.
O que podemos aprender?
Cada estilo de comunicação síncrona e assíncrona não bloqueante tem suas próprias vantagens e desvantagens, que devem ser cuidadosamente consideradas ao projetar um serviço. Compreender as desvantagens e como mitigá-las é crucial para criar uma arquitetura robusta e eficiente. Seja implementando ferramentas de monitoramento ou garantindo consistência de dados, um bom arquiteto de software deve estar preparado para enfrentar esses desafios.
Se gostar do conteúdo, por favor, compartilhe e deixe seu like no post! Isso me ajuda e incentiva a continuar a trazer conteúdos em forma de texto também!😄
Contenção de recursos ocorre quando vários processos ou threads competem pelo acesso a recursos limitados do sistema, como CPU, memória, disco ou conexões de rede. Essa competição pode levar a um desempenho degradado, aumento de latência e, em alguns casos, bloqueios ou deadlocks.
Vamos detalhar distinções importantes entre Message Queues e Pub/Sub e os cuidados necessários ao lidar com comunicação baseada em eventos.
Diferenças entre Filas de Mensagens e Pub/Sub
Modelo de Comunicação:
Filas de Mensagens: Funcionam em um modelo one-to-one, onde uma mensagem é consumida por um único consumidor.
Pub/Sub: Segue um modelo one-to-many, onde uma mensagem publicada em um tópico pode ser consumida por vários assinantes.
Persistência de Mensagens:
Filas de Mensagens: As mensagens são excluídas ou ficam invisíveis depois de consumidas.
Pub/Sub: As mensagens permanecem disponíveis para todos os assinantes até que sejam consumidas por cada um.
Modelo de Confirmação:
Filas de Mensagens: Geralmente utilizam um modelo de confirmação do receptor, garantindo que a mensagem foi processada antes de ser removida.
Pub/Sub: Frequentemente é do tipo "dispare e esqueça", onde o publicador não espera uma confirmação de que a mensagem foi recebida.
Casos de Uso Ideais para Cada Tecnologia
Message Queues:
Ideais para distribuir trabalho entre trabalhadores, lidar com picos de carga ou fornecer algum tipo de atraso no processamento. Exemplos incluem processamento de tarefas em segundo plano, gerenciamento de filas de trabalho e balanceamento de carga entre múltiplos consumidores.
Pub/Sub:
Brilha quando você deseja notificar vários serviços sobre um determinado evento, fornecer atualizações em tempo real ou propagar eventos em uma arquitetura orientada a eventos. Exemplos incluem sistemas de notificação, atualização de caches distribuídos e disseminação de eventos para múltiplos serviços.
Considerações Importantes ao Implementar Filas de Mensagens e Pub/Sub
A escolha entre Message Queues e Pub/Sub depende de vários fatores. Ao tomar a decisão, considere:
Estilo de Comunicação:
Se você precisa enviar mensagens de um remetente para um destinatário, uma fila de mensagens pode ser mais adequada.
Se você precisa transmitir mensagens para muitos destinatários, um sistema Pub/Sub pode ser mais apropriado.
Ordem de Processamento:
Se você precisa processar mensagens na ordem em que foram enviadas, uma fila de mensagens com entrega FIFO (First-In-First-Out) estrita seria mais adequada.
Carga do Sistema:
Se o seu sistema prevê tráfego intenso e de alto volume com comunicação um-para-um, uma fila de mensagens provavelmente será mais adequada.
Se o seu sistema exigir a transmissão de mensagens para um grande número de consumidores simultaneamente, considere um sistema Pub/Sub.
Overselling é a ação de prometer mais do que se pode entregar. Isso pode ocorrer em várias formas:
Vendas e Marketing:
Produtos e Serviços: Empresas podem exagerar as funcionalidades, benefícios ou resultados de um produto ou serviço para atrair clientes.
Promoções: Anúncios que sugerem que um produto ou serviço é mais eficaz ou valioso do que realmente é.
Tecnologia e Hospedagem:
Serviços de Hospedagem Web: Provedores de serviços de hospedagem podem vender mais recursos (como espaço em disco ou largura de banda) do que realmente possuem, assumindo que nem todos os clientes usarão a capacidade total ao mesmo tempo.
Soluções de Software: Desenvolvedores podem prometer funcionalidades futuras ou capacidades do software que não estão disponíveis ou que são difíceis de implementar.