
Hexagonal Architecture: What It Is, Why It Matters, and How It Can Save Your Code from Chaos
“I invented ‘Hexagonal Architecture’ because I was tired of firefighting…” - Alistair Cockburn 📚

In this article, we’ll explore Hexagonal Architecture and how it can transform the way we structure systems. We’ll see how separating the core application logic from the external world brings benefits like flexibility, robustness, and easier maintenance. ✨
We’ll discuss ports, which connect business logic to external interactions, and adapters, which bridge the core to the surrounding technologies. 🛠️ By the end, you’ll understand how this approach can prepare your system to evolve seamlessly, allowing external technologies to be swapped without touching the core logic. 🔄
Ready to make your code future-proof? Let’s dive in!
The Growth of Systems Over Time 🌱
Most projects start small, with a simple and clear architecture. Often, the system is divided into well-known layers:
Presentation Layer (UI): Responsible for the user interface, whether it’s web, desktop, or mobile, where the user interacts directly with the system. 🖥️📱
Application/Service Layer: This is where the business rules reside. It coordinates the system’s logic, processing operations, and connecting the interface with the data. ⚙️
Data Access Layer (DAO): Handles communication with the database, sending and retrieving the necessary information to make the business logic work. 📊
Database Layer: The layer where data is actually stored and retrieved. 💾
This division of responsibilities is quite common and works well for many projects, especially in the beginning, when everything is simple, and the number of features is limited. However, as the system grows and becomes more complex, this organization can turn into a major challenge. 😬
Imagine your system has been running for a few years. It started small but now includes multiple modules, integrations with other systems, and a growing user base. Each time you need to add a new feature, you notice it impacts several layers at once. 😵💫
For example, if you need to change a business rule, this change might directly affect the application layer and, consequently, the UI (which must display the data correctly), while also forcing updates to the data access layer. This interdependence creates an environment where every change requires careful adjustments across various parts of the system, making the process slow and error-prone. 🐢💥 This is where the system begins to lose its agility.
Over time, this rigid structure becomes a trap. The need to keep all layers working perfectly together makes the system more fragile and harder to modify. The team spends more time figuring out how changes will impact different parts of the code than actually innovating and adding value. This also affects testing—testing one part of the system may require running several other parts, increasing complexity and time spent. 🕒
Additionally, relying on this classic layer-based architecture can make you a prisoner of the technologies chosen at the start of the project. For instance, replacing the database can become a nightmare because it’s so tightly integrated with the rest of the system that changing it might require refactoring several other parts. 🚧😟

What once seemed like a simple organization in the beginning now turns into a real burden, making the system’s evolution increasingly difficult. The separation between layers, which was supposed to be a benefit, ends up creating tight coupling—in other words, the layers become so dependent on each other that a small change in one can deeply impact the others. 😓
The Impact of Coupling on Engineering Teams ⚙️
Have you ever worked on a project where every change felt like walking through a minefield? A system where, over time, the parts became so intertwined that a simple change could trigger a domino effect, breaking other areas that seemed unrelated? If so, you know how this can turn the team’s work into a true nightmare. 😓
Testing Becomes a Nightmare 🧪
When a system is tightly coupled, testing a new feature becomes far more complicated than it should be. Imagine this scenario: you need to update a simple business rule. The problem is, since all the layers of the system are interconnected, you can’t test this change in isolation. To ensure everything works, you have to check interactions with the user interface, verify that data access still behaves correctly, and, of course, confirm that the database is responding as expected.
Sound familiar? This type of dependency creates a chain that makes every change risky. Suddenly, that small update ends up breaking parts of the system you never imagined would be affected. And worse: tests become longer and more complex, forcing the team to spend an excessive amount of time creating integration tests to ensure everything still works end-to-end. 🕒
Ever felt like you’re spending more time fixing bugs than building new features? That’s a classic sign of excessive coupling. 🔗

That fine line between unit tests and integration tests starts to blur. What should be a simple unit test, focused on a specific behavior, ends up becoming a disguised integration test. 😵💫 Why? Because tight coupling forces you to test multiple layers together—like business logic, data repositories, and even the interface. The result? Slower tests, harder to maintain, and a growing risk of introducing new bugs. 🐞
Launching New Features Becomes Slow and Risky 🚧
And what about new features? When the system is tightly coupled, releasing something new turns into a test of patience. Ever experienced this? A simple change in business logic might force you to tweak the user interface, adjust the services, and reconfigure the data layer. Something that should be resolved in a few days drags on for weeks, or even months. 🕒

Have you ever felt uncertain about the impact of your changes? 🤔 This happens because, in a tightly coupled system, you can never be sure what’s going to break. Sometimes, when adding a new feature, something that was working perfectly suddenly stops—and the worst part? You might not even notice it immediately. 😨
The issue could show up in a completely different layer. What should be a win for the team ends up causing anxiety and frustration. What’s going to break this time? 💥
Fixing Bugs Takes Much Longer 🐛⏳
And what about bugs? Do you find it difficult to figure out where they’re coming from? This is very common in tightly coupled systems. The behavior of one part of the system often depends on several others. To find the root cause of a bug, engineers have to investigate multiple layers, consuming precious time. 😓
Even when the problem is found, the solution is rarely in a single place. To fix one bug, you often end up adjusting several parts of the code, which increases the risk of introducing new issues while solving the original one.🙃 Ever experienced this? It feels like an endless cycle: you fix one bug, and others appear. The team grows frustrated, and delivering the solution takes much longer than it should. 🔄⏳
Code Quality Deteriorates 💻⬇️
Over time, tightly coupled systems start to lose code quality. Ever found yourself working on parts of the system you barely know just to make a simple change? 🤷♂️ This happens because, with so many dependencies, every change requires touching multiple areas, leading to quick fixes and “band-aid solutions”. 🩹⚠️
The pressure to deliver new features quickly often prevents the team from taking the time to refactor or improve existing code. Over time, the code becomes increasingly messy and hard to understand. And the more this happens, the harder it gets to maintain. 🛠️
Hexagonal Architecture: The Solution to Excessive Coupling 🛡️
After understanding the challenges of tightly coupled classes and layers, it’s time to explore an approach specifically designed to solve these problems. Hexagonal Architecture was introduced to create systems that are more flexible, maintainable, and resilient to change, breaking the cycle of frustration caused by excessive coupling between layers and classes. 🔗❌
This architecture, proposed by Alistair Cockburn in the early 2000s, focuses on decoupling business logic—the core rules and functionalities of the system—from any specific technology or implementation details, such as frameworks, databases, or user interfaces. 💡
At its heart, Hexagonal Architecture is about isolating the application core, keeping it independent of external communication interfaces, so it can evolve and be tested without dependencies. 🧩
The idea is to build the system around a solid core of business rules that doesn’t rely directly on external components. This ensures the core remains stable, allowing the system to adapt to changes in technologies or integrations without disrupting its fundamental logic. ⚙️🔄
Solving Problems with Hexagonal Architecture! 🛠️✨
Imagine if, instead of having tightly interconnected classes and layers—where a simple change affects multiple parts of the system—your code was organized so that the business logic was isolated from everything external. In Hexagonal Architecture, this central logic (the heart of the application) doesn’t need to “know” how data is stored or where requests come from. 💡
This separation protects us from the key challenges faced in tightly coupled systems, such as:
1. Easier Testing ✅
With business logic decoupled from external technologies, you can test its functionality in isolation, without having to instantiate multiple dependencies or layers. This eliminates the need for complex mocks and ensures the application’s behavior is validated quickly and effectively. 🧪
2. Adding New Features Without Impacting Other Parts of the System 🚀
In Hexagonal Architecture, adding a new feature or changing a business rule doesn’t require changes in the data storage layers or the user interface because these parts are isolated. This reduces the risk of introducing bugs into unrelated areas when making updates. 🔄🛡️
3. Easier Maintenance and Refactoring 🔧
Since each part of the system has clearly defined responsibilities and is less dependent on other layers, refactoring or making adjustments becomes much simpler, without causing a cascade effect. When a bug is found, it can be fixed in the isolated context of its functionality, without impacting other areas. 🐞💨
4. Faster Delivery Times ⏱️
The clear separation of responsibilities and isolation of business classes significantly reduces the time required to adjust features and fix bugs, positively affecting delivery times. ⚡
By removing direct dependencies between layers, Hexagonal Architecture allows us to build a system where each part can evolve independently. This means it doesn’t matter if we’re changing the database or updating the user interface—the business logic remains intact, without requiring extensive changes. 🌐🔗

The image above shows only the outer shell, and you can see the entire external world surrounding the hexagon. Soon, we’ll dive deeper into this image, adding more details and completing the interactions! 🛠️
In the upcoming sections, we’ll dive into the core concepts of Hexagonal Architecture and explore how it organizes these components to help us free the system from the challenges of tight coupling. 🔗❌
The Application Core 🎯
Hexagonal Architecture is built around the idea of protecting the application core, where the business rules reside. This core is the most valuable part of the system, as it defines what the system does—its functionalities, decisions, and how data is processed. 🛠️✨
The application core is a layer of code that contains the most critical business decisions and rules. It’s essential to understand that this part of the system must be entirely isolated from external concerns, such as user interface frameworks, databases, or any other infrastructure. Business logic should be independent of how data is stored or displayed. 🚀
For example, imagine a sales system. 🛒 The rules for calculating the final price of a sale based on discounts, taxes, or promotions should reside in the core. These rules should not depend on how sales data is stored in the database or how it’s displayed to the end user. 📊💬
The brilliance of Hexagonal Architecture is that it protects the core from external influences. This means that if one day you need to switch databases or change how users interact with the system, the core remains the same. It neither “knows” nor “cares” about external details, such as where data is stored or which technology is used in the interface. 💻
• Easy to Test 🧪: Since the core is independent of external technologies, it can be tested in isolation. You can ensure that business rules are functioning correctly without worrying about databases, frameworks, or APIs.
• Simplified Maintenance 🔧: With business rules isolated, it becomes easier to refactor the code or add new features without the risk of breaking other parts of the system. 🔄
• Greater Flexibility 🚀: By keeping the core free from implementation details, you can swap out parts of the system without modifying the business rules. For example, if you decide to switch from an SQL database to NoSQL, the core doesn’t need to change. 🔗
Why Is the Core Important? 💡
In chaotic systems, business rules are scattered across multiple layers and mixed with implementation details. This makes the system fragile and difficult to maintain. 😵💫 By focusing on the core, Hexagonal Architecture solves this problem, allowing the business logic to remain solid and unchanging, even when the rest of the system evolves. 🛡️
In the next section, we’ll dive into a fundamental concept of Hexagonal Architecture.
Driver Side and Driven Side
After understanding that the application core contains business rules and is well-protected, it’s time to explore how it interacts with the external world. To keep this communication organized and decoupled, Hexagonal Architecture introduces two well-defined sides: the Driver Side and the Driven Side. These concepts help us understand who initiates actions and who responds to them within the system. 🚦
What is the Driver Side?
The Driver Side is responsible for initiating actions in the system. It represents the inputs that reach the application core, such as user requests, external system calls, or events that trigger business logic. In other words, the Driver Side is what “drives” the flow of operations.
Here are some examples of the Driver Side in action:
• A user interaction triggering a request through a web or mobile interface.
• An API call from an external system sending data to the core.
• An event from a message queue initiating a business process.
It’s clear that the Driver Side is responsible for sending requests to the core and expecting it to make decisions based on business rules.
What is the Driven Side?🚗
If the Driver Side initiates actions, the Driven Side responds to the decisions made by the core. Once the core processes a request, it needs to perform external actions, such as saving data, sending notifications, or interacting with other systems. This is where the Driven Side comes into play.
Examples of the Driven Side:
• Database: When the core needs to save or retrieve information, it does so through the Driven Side, without knowing how the database is implemented.
• External Services: If the core needs to call a third-party API, such as a payment service, the Driven Side handles this.
• Email Sending: When the business logic decides an email must be sent, the Driven Side executes this action without exposing the core to the details of how it’s done.
The Driven Side carries out the external actions required by the core, but the core remains independent of the implementation details.
Why Is This Separation Important?
The separation between the Driver Side and the Driven Side is critical because it keeps the application core isolated from external implementations. On the Driver Side, actions come from outside and are directed to the core. On the Driven Side, the core triggers external interactions without needing to know how they are performed. This ensures the system remains flexible, maintainable, and resilient to changes.
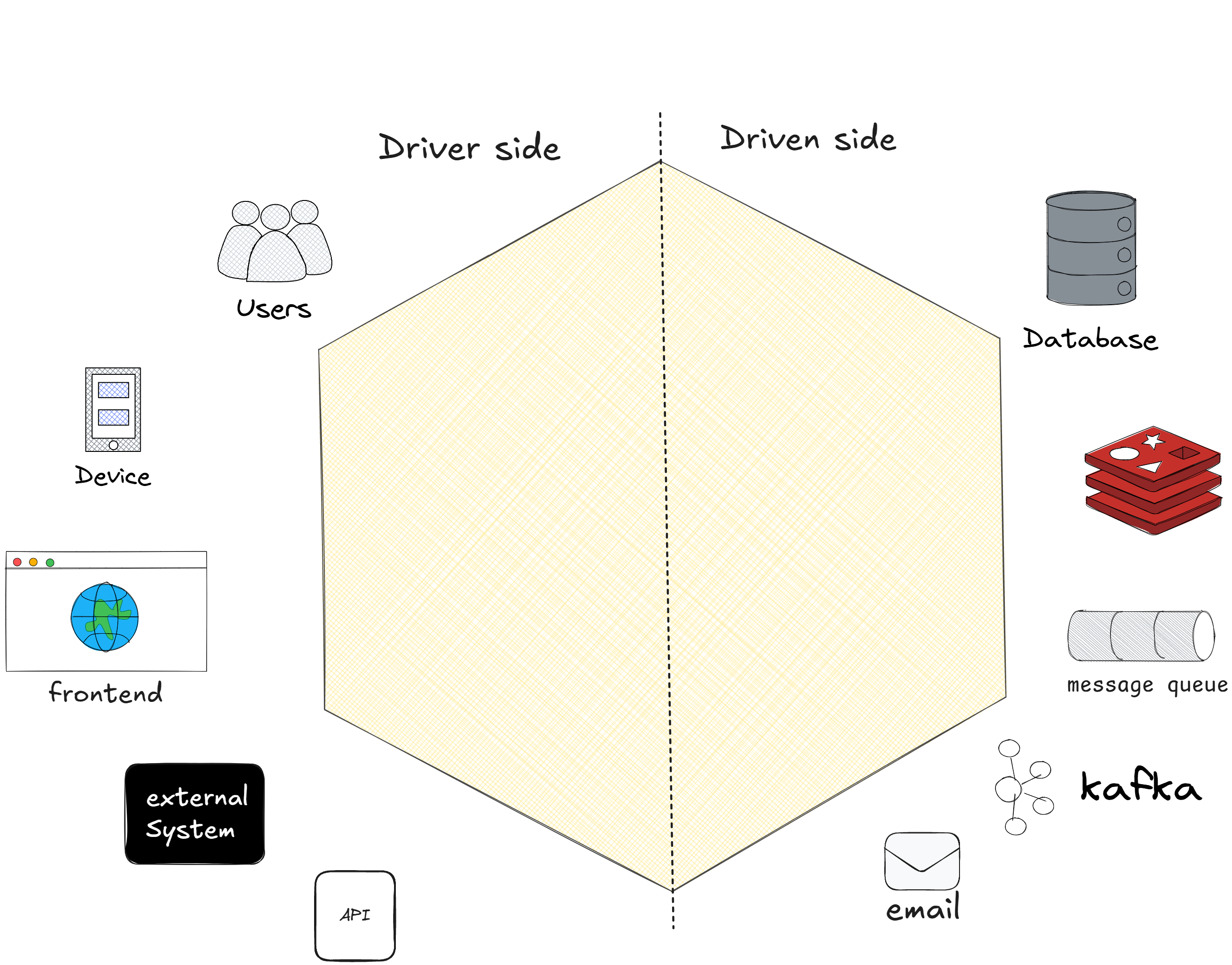
Now it’s time to talk about other fundamental concepts of this architecture!
What Are Ports in Hexagonal Architecture? 🧐
In Hexagonal Architecture, a Port is like a contract that defines clear communication rules between the application core and the external world. Ports specify “what” needs to be done in each interaction, but not “how” it will be implemented. This ensures that the application core doesn’t have to adapt to the specifics of external technologies, allowing it to remain focused on business rules.
How a Port Works
Think of Ports as service contracts. They specify what kind of data the core expects to receive and in what format it will send information, without needing to know where the data is coming from or going. Ports define the expectations for communication, creating a layer of protection and independence for the application core.
A Port Is a Contract!
Imagine hiring a delivery service. You create a contract stating that deliveries must be made to your doorstep and packages should arrive intact. The contract doesn’t care how the delivery is done—whether by bike, motorcycle, or car. This contract (Port) defines the “rule” of the delivery, ensuring you don’t have to worry about the details of how it’s executed. 🚚📦

In the application, a Port works exactly like this. It establishes a “delivery rule” for the data sent to the core, allowing it to operate independently of the details about how the data is captured or sent to the external world. ✨

Types of Ports in Hexagonal Architecture
• Input Ports: These are contracts that define how requests are delivered to the core. If an external API or a user sends a request, the Input Port ensures it is translated and delivered to the core in the expected format.
• Output Ports: These are contracts that define how the core sends data outward. If the core needs to save data or send a notification, the Output Port ensures that the data is sent in the expected format, without requiring the core to know how the destination will handle it.
Benefits of Ports as Contracts in Hexagonal Architecture
• Ease of Testing: Since the core is isolated by clear contracts, it’s easy to test business rules without relying on external technologies.
• Adding Features: New functionalities enter and leave the core through Port contracts, keeping the core focused on business rules.
• Simplified Maintenance: With Ports defining communication, you can change external components (like APIs or databases) without altering the core.
By functioning as contracts, Ports keep the application core independent and protected from external changes, always operating within the expectations defined by the Ports without worrying about external details.
Seeing Ports in Practice
Now that we’ve discussed the concept of Ports in Hexagonal Architecture, let’s see how they are implemented in practice. The idea here is to demonstrate how the application core can be structured in a flexible, independent, and decoupled manner. Below is an example using TypeScript that follows these principles. 💻✨
Input Port and Output Port
First, let’s define our Ports. The Input Port defines the interface for creating a new user, while the Output Port specifies how the use case saves the user in an external system.
// Input Port
export interface CreateUserPort {
create(user: Pretify<IUserCreate>): Promise<IUserToUI>;
}
// Output Port
export interface UserRepositoryPort {
create(user: IUser): Promise<IUser>;
}CreateUserPortis the Input Port that initiates the user creation action. It receives an input data object (IUserCreate) and returns a representation for the user interface (IUserToUI), keeping the use case focused solely on the logic of user creation.•
UserRepositoryPortis the Output Port that allows the use case to save the user in an external system (like a database). It abstracts data persistence, enabling theCreateUserUseCaseto interact with the repository without worrying about implementation details.
How These Ports Work Together
These Ports work in tandem to ensure that the application core remains independent of storage and presentation details, focusing solely on the business logic of user creation. This approach promotes flexibility, maintainability, and testability, making it easier to adapt the system to new requirements or technologies.
The User Factory
We will also introduce the concept of a factory for creating users. Instead of placing the logic for creating and validating a user directly in the use case, we use a factory to clearly separate responsibilities.
// Factory
export class UserFactory {
createUser(name: UserName, email: UserEmail, password: UserPassword): User {
return new User(name, email, password);
}
}
export class User implements IUser {
public id?: UserId;
public name: UserName;
public email: UserEmail;
public password: UserPassword;
public events: IUserEvent[] = [];
constructor(name: UserName, email: UserEmail, password: UserPassword, id?: UserId) {
if (name.length < 4) {
throw new Error("Name must be at least 4 characters long");
}
if (password.length < 8) {
throw new Error("Password must be at least 8 characters long");
}
if (!email.includes("@")) {
throw new Error("Email must be valid");
}
this.id = id;
this.name = name;
this.email = email;
this.password = password;
}
async domainEvents(): Promise<IUserEvent[]> {
return this.events;
}
async clearEvents(): Promise<void> {
this.events = [];
}
async addEvent(event: IUserEvent): Promise<void> {
this.events.push(event);
}
}Here, the UserFactory creates the user, and the User entity handles validation, such as ensuring the email is valid, the name has at least 4 characters, and the password is 8 characters long. This keeps the use case more organized and focused on its responsibility.
Implementing the CreateUserUseCase
In the example below, the CreateUserUseCase orchestrates the creation and persistence of a new user by leveraging Output Ports to keep the application core independent of external details. This design adheres to the principles of Hexagonal Architecture, promoting a modular and flexible structure.
Output Ports Used by CreateUserUseCase:
1. UserRepositoryPort
Defines the operations required to persist the user in a database or external system.
2. UserEventHandlerPort
Handles domain events, allowing the system to respond to important actions such as the creation of a new user.
3. PasswordHasherPort
Provides an abstraction for password hashing, isolating the use case from security implementation details.
These dependencies are injected via dependency injection, making it easier to replace or mock them for testing purposes.
@injectable()
export class CreateUserUseCase implements CreateUserPort {
constructor(
@inject("UserRepository") private userRepository: UserRepositoryPort,
@inject("UserEventHandler") private userEventHandler: UserEventHandlerPort,
@inject("PasswordHasher") private passwordHasher: PasswordHasherPort
) {}
async create(create: Pretify<IUserCreate>) {
try {
// Hashing password
create.password = await this.passwordHasher.hash(create.password);
// Creating user instance with internal validations
const user = new User(create.name, create.email, create.password, uuidv4());
// save user in repo
const persist = await this.userRepository.create(UserMapper.toPersistence(user));
// Emission of user creation event, if the user
if (persist.id) {
user.addEvent(new UserCreatedEvent(persist.id));
this.userEventHandler.handle(user.events[0]);
}
// Return a suitable user representation for the user interface
return UserMapper.toUI(persist);
} catch (error: any) {
throw error; // Allows the upper layer to handle the error as needed
}
}
}
Explanation of How It Works
Let’s break down the CreateUserUseCase step by step and see how each part contributes to making the use case more cohesive and independent.
1. Password Hashing 🔐
Instead of handling password hashing directly, the use case delegates this responsibility to the PasswordHasherPort, an injected interface specifically for hashing. This approach frees the use case from the technical details of security, allowing it to focus on its primary task: creating the user.
2. User Creation 👤
The User instance is created with the provided information and includes built-in validations, such as checking the name, email, and password strength. This ensures that the use case can fully trust the User entity to handle these details without being burdened by validation rules.
3. Repository Persistence 🗂️
Once the user is successfully created, the use case uses the UserRepositoryPort to store it, delegating the responsibility of persistence. A UserMapper is employed to convert the user into the required format for storage, keeping the use case independent of database specifics.
4. Emitting a Creation Event 📢
After the user is saved, the CreateUserUseCase triggers a UserCreatedEvent, signaling that the creation has been successfully completed. This event is managed by an event handler (UserEventHandlerPort), allowing the system to react to the event without requiring the use case to know how the reaction is implemented.
5. Returning to the User Interface 💬
Finally, the UserMapper converts the User entity into a format suitable for the user interface. This ensures that the use case remains compatible with the presentation layer without needing to understand its details.
Benefits of This Approach
With this structure, the CreateUserUseCase becomes more organized, and each component of the system performs a specific task. Here are the main advantages:
• Separation of Responsibilities: Each function—hashing, persistence, event emission— is handled by a specialized service, making the use case clear and focused on user creation.
• Ease of Testing: The use case dependencies are injected, allowing mocks to be used in tests. This enables testing the user creation logic without needing access to the database or external services.
• Scalability and Flexibility: Since everything is modularized, new features, such as adding events or new services, can be integrated without altering the use case. This makes the system more flexible and easier to expand.
This implementation of the CreateUserUseCase demonstrates how Hexagonal Architecture promotes a clean, responsibility-driven design. The result is a system that remains organized, sustainable, and ready to evolve as needs grow.
And What About Adapters? Let’s Dive Deeper!
Now that we understand the role of Ports as contracts, we can move on to Adapters. If Ports define the “delivery rules” between the core and the external world, Adapters are the executors of those rules. They ensure that the Port’s contract is fulfilled, organizing and formatting the data properly so the core can process it or send a response.
What Are Adapters?
Think of Adapters as the delivery service in the package example. The contract (the Port) specifies that the delivery must be made to your door in perfect condition, but the delivery service is what actually performs the task. It handles the practical details—whether by car, motorcycle, or bike—and ensures everything arrives according to the rules defined by the contract.

In the system, Adapters act exactly this way: they take data from the external world, organize, format, and translate this information into the format required by the application core. They also work in reverse, preparing the core’s data to be sent back to the external world.
How Do Adapters Work in the System?
When the application core needs to receive or send data, Adapters step in to transform information between external and internal formats. Here’s how they work:
Receiving a JSON Message
Imagine an external API sends a message in JSON format. The Adapter deserializes (converts) this message, adjusting it to the format that the application core understands. The core then processes this data without knowing it came in JSON—it only sees the data organized and ready for use.
Sending a Response
When the core processes a request and needs to send a response, the Adapter takes this response, transforms it into the appropriate format (such as an HTTP response or a message for a messaging system), and delivers it to the destination.
Where Do Adapters Appear in the Code?
In the context of our code example, imagine we have a use case like CreateUserUseCase, which defines the logic for creating a new user. This use case uses Ports to communicate its needs to external systems, but the Adapters are the actual implementations of these Ports:
• Database Adapter (Output Port): This Adapter connects the core to the database, enabling users to be saved in a concrete way while isolating the core from the specific details of the database being used.
• REST API Adapter (Input Port): This Adapter translates requests coming from a user interface or an external API, organizing the data so that the core can process it.

Adapters are responsible for the “delivery and collection” of data, as defined by the Port contracts. They handle the transformation and formatting of information so that the application core operates seamlessly, keeping it isolated from external details and allowing the entire system to evolve in an organized manner.
Implementing Adapters for Ports
Now that we’ve defined the Input and Output Ports, let’s explore how Adapters implement them, connecting the application core to the external world without requiring the core to worry about the specific details of communication or storage.
Database Adapter
To save a user in a real database, we create an Adapter that implements the Output Port UserRepositoryPort. This Adapter knows how to interact with the database, but the application core remains unaware of these details, which ensures a clean and modular design.
import 'reflect-metadata';
import { inject, injectable } from 'tsyringe';
import { UserRepositoryPort } from '../../../application/User/port/secondary/UserRepositoryPort';
import { IUser } from '../../../application/User/domain/IUser';
import { User } from '../../../application/User/domain/User';
import db from '../../../infrastructure/db/db';
import { PrismaClient } from '@prisma/client';
import { UnCaughtError } from "../../../Errors/Uncaught";
@injectable()
export class UserRepository implements UserRepositoryPort {
private db: PrismaClient;
private model: typeof db.user;
constructor() {
this.db = db;
this.model = this.db.user;
}
async create(user: IUser) {
try {
const exists = await this.model.findUnique({ where: { email: user.email } });
if (exists) {
throw new UnCaughtError('user already exists', 400);
}
const newUser = await this.model.create({
data: {
name: user.name,
email: user.email,
password: user.password,
id: user.id
}
});
return new User(newUser.name, newUser.email, newUser.password, newUser.id);
} catch (error: any) {
throw new UnCaughtError(error.message);
}
}
async findById(id: string) {
try {
const user = await this.model.findUnique({ where: { id: id } });
return user ? new User(user.name, user.email, user.password, user.id) : null;
} catch (error: any) {
throw new UnCaughtError(error.message);
}
}
async findByEmail(email: string) {
try {
const user = await this.model.findUnique({ where: { email: email } });
return user ? new User(user.name, user.email, user.password, user.id) : null;
} catch (error: any) {
throw new UnCaughtError(error.message);
}
}
}In this example, UserRepository implements the Output Port UserRepositoryPort. It interacts with the database using Prisma for persistence and data retrieval operations, but the application core doesn’t need to know these details—it simply delegates the responsibility to the Adapter.
Advantages of Using Adapters with Specialized Interfaces
Structuring the design with specialized interfaces offers several benefits beyond organization:
• Well-Defined Responsibilities:
By delegating each action to a specific interface (like UserRepositoryPort for persistence), the code remains cohesive and organized. Each interface handles a specific purpose, making it easier to read and maintain.
• Ease of Making Changes:
If you need to switch the database or add new features, you can modify only the Adapter implementation without altering the core. This provides flexibility and avoids extensive refactoring.
• Simplified Testing:
Separating responsibilities makes it easier to use mocks and conduct independent tests, eliminating the need to configure a real database in scenarios that don’t involve direct persistence.
• Adaptability:
With a modular design, it’s easy to add new functionalities, such as saving data to multiple databases or sending information to a message queue, by simply creating new implementations of the output interface.
REST API Adapter
Now, imagine receiving a request from a REST API to create a user. In this case, you’ll need an Adapter that uses the Input Port CreateUserPort, handling the external communication, such as deserializing the data received from the API and passing this data to the application core.
import 'reflect-metadata';
import { inject, injectable } from 'tsyringe';
import { CreateUserPort } from "../../../application/User/port/primary/CreateUserPort";
import { IUser } from '../../../application/User/domain/IUser';
import { UserMapper } from '../../mappers/UserMapper';
@injectable()
export class UserCreateController {
private userMapper: typeof UserMapper;
constructor(@inject('CreateUserUseCase') private userCreate: CreateUserPort) {
this.userMapper = UserMapper;
}
async create(body: { name: string; password: string; email: string }): Promise<any> {
try {
const userDTO = this.userMapper.toDomain(body);
const user = await this.userCreate.create({
name: userDTO.name,
password: userDTO.password,
email: userDTO.email
});
return user;
} catch (error) {
throw error;
}
}
}In the code above, UserCreateController is the Adapter that uses the Input Port CreateUserPort. It handles user creation requests from the API, converts the data into the appropriate format using UserMapper, and then calls the use case (CreateUserUseCase). This way, the Adapter manages external communication, while the core remains focused solely on business rules.
This modular structure makes the system adaptable and scalable, ready to respond to changes and new requirements without compromising the application’s cohesion or design.
How Adapters Enhance Flexibility and Delivery Agility
The diagram highlights the role of Adapters as implementations of the Ports, bridging the application core (where use cases and business logic reside) with the external world. Adapters ensure seamless communication while keeping the core independent of external dependencies, promoting flexibility and enabling faster, more efficient deliveries.

Key Points Showing How This Structure Provides Flexibility and Agility
• Separation of Responsibilities:
Adapters connect the application core to external systems (databases, APIs, etc.), keeping the core focused solely on business rules without relying on external technical details.
• Ports as Contracts:
Ports act as contracts between the core and the external world. Input Ports allow the core to receive information, and Output Ports allow it to send data. This structure leaves concrete implementations to the Adapters, ensuring clear boundaries.
• Dependency Injection for Flexibility:
Use cases depend on interfaces (Ports) that are injected, allowing Adapters to be swapped out without modifying the core. This makes replacing external systems, such as databases, quick and seamless.
• Ease of Testing:
Mocks or stubs of the Ports can be used to test the core’s business logic in isolation, without external dependencies, speeding up development and enabling continuous delivery.
• Adding Features:
New features can be implemented by creating new Adapters that follow the Port contracts, without modifying the application core. This allows the system to expand quickly and safely.
With Adapters, your application is always ready to grow and adapt—without complexity or headaches. Next, let’s look at how to test the UseCase. 🚀
Testing the Use Case
To ensure that the CreateUserUseCase is working correctly, we will create a test using mocks to simulate the behavior of the injected dependencies. This allows us to focus on the application core, testing the business logic independently of the external Adapters.
We will configure the mocks to simulate the behavior of the UserRepositoryPort and the PasswordHasherPort.
describe("CreateUserUseCase", () => {
let mockUserRepository: jest.Mocked<UserRepositoryPort>;
let mockUserEventHandler: jest.Mocked<UserEventHandlerPort>;
let mockPasswordHasher: jest.Mocked<PasswordHasherPort>;
let createUserUseCase: CreateUserUseCase;
beforeEach(() => {
mockUserRepository = {
create: jest.fn(),
findById: jest.fn(),
findByEmail: jest.fn(),
};
mockUserEventHandler = { handle: jest.fn() };
mockPasswordHasher = { hash: jest.fn().mockResolvedValue("hashed_password") };
createUserUseCase = new CreateUserUseCase(mockUserRepository, mockUserEventHandler, mockPasswordHasher);
});
it("should create and save the user in the repository", async () => {
const userData: Pretify<IUserCreate> = { name: "John Doe", email: "john.doe@example.com", password: "password123" };
const persistedUser = { ...userData, password: "hashed_password", id: "generated_id" };
// Arrange - Mock
mockUserRepository.create.mockResolvedValue(persistedUser);
// Act
const result = await createUserUseCase.create(userData);
// Assert
expect(mockPasswordHasher.hash).toHaveBeenCalledWith("password123");
expect(mockUserRepository.create).toHaveBeenCalledWith(expect.objectContaining({ name: "John Doe", email: "john.doe@example.com" }));
expect(result).toEqual(expect.objectContaining({ id: "generated_id", name: "John Doe", email: "john.doe@example.com" }));
});
it("should emit the 'user_created' event when creating the user", async () => {
const userData: Pretify<IUserCreate> = { name: "John Doe", email: "john.doe@example.com", password: "password123" };
const persistedUser = { ...userData, password: "hashed_password", id: "generated_id" };
// Arrange
mockUserRepository.create.mockResolvedValue(persistedUser);
// Act
await createUserUseCase.create(userData);
// Assert
expect(mockUserEventHandler.handle).toHaveBeenCalledWith(expect.objectContaining({ type: "user_created", payload: { id: "generated_id" } }));
});
Strengths of the Test
• Isolation of Business Logic:
With Hexagonal Architecture, external dependencies like the repository, event service, and password hasher are injected into the use case (CreateUserUseCase). This allows each dependency to be replaced with a mock during testing.
This isolation ensures that only the user creation logic is tested, without interacting with real systems like databases or authentication services.
• Mocks for Dependencies:
By using mocks for UserRepositoryPort, UserEventHandlerPort, and PasswordHasherPort, the test focuses on the methods and flows that truly matter, ensuring that business logic doesn’t rely on external implementations.
Mocks make the test fast and efficient, avoiding complex environment setups and making it easier to test specific cases, such as user creation, event dispatching, and error handling.
• Dependency Behavior Verification:
Each assertion checks a specific call, such as hashing, user persistence, or event dispatching. This guarantees that CreateUserUseCase interacts correctly with each dependency.
Hexagonal Architecture, by defining ports for each dependency, allows the test to validate these behaviors precisely, improving the quality and confidence in the code.
Now, let’s briefly discuss some important questions!
Difference Between Injection and Implementation in Input and Output Ports
In Hexagonal Architecture, it’s essential to understand how Input and Output Ports operate and how Use Cases and Adapters interact with them. The way injection and implementation occur varies between the Driver Side and the Driven Side. Take another look at the diagram.

Driver Side (Input Ports)
• Adapters Use Input Ports:
On the Driver Side (left side of the diagram), Adapters receive external requests (such as from a user interface or API) and use Input Ports to activate business logic. They trigger the application core through the Input Ports.
Example: UserCreateController uses the Input Port CreateUserPort to trigger CreateUserUseCase, where the logic for creating a user is executed.
• Use Cases Implement Input Ports:
Use Cases are responsible for business logic and implement Input Ports. This defines the contract that the Adapter follows to call the necessary functionalities.
Example: CreateUserUseCase implements the interface CreateUserPort, allowing the Adapter to use it to create a user.
• Injection on the Driver Side:
Use Cases do not inject Input Ports since they implement them directly. Instead, Adapters inject Use Cases to execute actions without needing to know the internal details of the logic.
Driven Side (Output Ports)
• Adapters Implement Output Ports:
On the Driven Side (right side of the diagram), Adapters provide the external functionalities the core needs by implementing Output Ports. They connect the core to external resources like databases or messaging systems.
Example: UserRepositoryAdapter implements UserRepositoryPort, allowing the Use Case to interact with the database to save the user.
• Use Cases Inject Output Ports:
On the Driven Side, Use Cases inject Output Ports to perform external operations in a decoupled way, without knowing implementation details. This allows the core to function without depending on specific external services.
Example: CreateUserUseCase injects UserRepositoryPort to save a user but doesn’t need to know where or how it happens.
This model of injection and implementation for Input and Output Ports ensures the system is scalable, modular, and easy to maintain. The application core focuses solely on business logic, while Adapters handle external interactions. This separation of responsibilities is essential for a flexible and adaptable system, maintaining a cohesive design over time.
Is There a Strict Rule About the Number of Layers in Hexagonal Architecture?
The simple answer is: no, there’s no strict rule about how many layers you should have in Hexagonal Architecture. The central goal of this architecture is to decouple the application core from the external world using Ports and Adapters, but the exact number of layers can vary depending on the project.
What Do Books and Practice Say?
If we look at books, articles, and talks on Clean Architecture and Hexagonal Architecture—like those by Alistair Cockburn or the well-known Robert C. Martin (Uncle Bob)—there’s no magic formula for the number of layers. The focus is always on flexibility and core isolation, not on a fixed number of layers.
What’s Common in Practice?
In many projects, we often see an organization with around 4 to 5 main layers. This, of course, depends on the complexity and level of abstraction required by the project. Typically, these layers include:
1. Core Layer: Where business rules and entities reside.
2. Ports: Interfaces that expose internal functionalities and define how the core communicates with the external world.
3. Adapters: Implementations of Ports that connect the core to the infrastructure.
4. Infrastructure: Where database configurations, APIs, message queues, and other external systems are managed.
In some projects, there might be an additional layer, such as an External Services Layer or an Integration Layer, which deals with third-party services, external APIs, or complex integrations. This is more common in larger systems or those with many external dependencies.
The Bottom Line
There’s no fixed number of layers in Hexagonal Architecture. The key is flexibility—structuring the system to meet the project’s needs without compromising its modularity or maintainability.
That’s it for this post! If you enjoyed the content, feel free to share! See you next time!😄