
Kafka Anatomy
When we talk about Kafka, we're not just talking about messaging, but about a robust infrastructure that enables distributed architectures to thrive with consistency and low coupling.

If you clicked on this article, it's because this topic sparks your curiosity — or maybe you've heard so much about Kafka that you've decided to understand better what it is and why everyone is talking about it. And look, you're in the right place. Let's explore Kafka without any fluff, in a simple and accessible way.
Throughout this article, we'll take a deeper look at the "anatomy" of this message broker that's so widely used in the tech world. We'll understand how it works, with illustrations, and why it has become indispensable for so many companies.
What is Kafka?
It's worth knowing a bit about Kafka's history. It was created by LinkedIn back in 2010, when the company faced a common challenge in many tech companies: how to handle the massive amount of data generated by different systems in real-time. Apache Kafka was born to solve this, enabling systems to exchange information quickly and reliably. It was designed to be scalable, meaning it could grow along with the data volume and demand without losing performance. Later, Kafka was donated to the Apache Software Foundation, becoming open-source and gaining even more popularity.

Now, if you work with a distributed system, you know how challenging it can be to make different parts of the application communicate efficiently, without losing data or having messages take too long to arrive. This is especially critical when we talk about real-time processing. And this is precisely where Kafka makes all the difference.

Imagine an e-commerce company, as we mentioned earlier: every order placed on the website needs to be communicated to the inventory system, the payment system, the delivery team, and all of this has to be synchronized for the process to work seamlessly. Without a solution like Kafka, these messages could get lost or, even worse, arrive late, compromising the user experience. Kafka solves this communication problem between systems in a fast, scalable, and reliable way.

Now, to better understand how Kafka does this, we can think of it as a postal system. It receives messages from producers (the systems sending data) and delivers them to consumers (the systems that need the data). Kafka is the central platform that makes all this message traffic happen efficiently.
Producers are like senders, who send messages.
Consumers are like recipients, who receive these messages.
Kafka is the postal service that organizes, stores, and distributes these messages in an orderly manner.
Now, let's talk about the basic structure of a message in Kafka!
Main Elements of a Message in Kafka
When working with Kafka, messages (also known as events or records) are the essence of all communication between systems. So, it’s important to understand how these messages are composed and what they contain.
Typically, the messages you send or receive in Kafka are transmitted in JSON format, meaning a JSON payload with the data you want to share. This format is quite common, mainly because it's lightweight and easy to read, both for humans and systems. Now, let’s take a look at the main components of a message:
Key: This part is optional, but very useful when you need to ensure related messages are sent to the same partition. For example, if you have messages about customer orders, you can use the customer ID as the key to ensure that all orders from a specific customer go to the same partition and are processed in the correct order.
Value: This is where the actual message resides — the real data you are sending. This value can be almost anything: an event, a status, a survey response, etc. In the case of a JSON payload, it would be the entire content of the message being transmitted between systems.
Timestamp: Every message in Kafka has a timestamp that indicates when the message was created or logged. This is essential for monitoring the order of events and for tracking when the messages were generated. The timestamp is very helpful in systems that depend on the timing of events to function correctly.
Compression Type: Depending on the volume of data you are dealing with, Kafka allows messages to be compressed using algorithms like gzip or snappy. This helps reduce the message size and improves efficiency when sending large amounts of data, without losing integrity.
Headers (optional): These are small optional metadata that you can add to the message to include extra information without altering the main content. They are super useful for carrying additional data that consumers can use for processing decisions without changing the value of the message itself.
Partition and Offset ID: Once the message is written to Kafka, it is stored in a partition and assigned an offset. These two elements are fundamental for Kafka to ensure the correct delivery and reading of messages (we’ll talk much more about these two concepts soon).
And how does it get to Kafka?
As I mentioned earlier, most of the messages that travel through Kafka use JSON as the payload format, but it can vary depending on the case. The structure would look something like this:
{
"key": "survey_123",
"value": {
"surveyId": "survey_123",
"title": "Pesquisa de Preferências de Filmes",
"question": "Qual é o seu filme favorito?",
"answers": [
"A Origem",
"Interestelar",
"O Grande Truque",
"Dunkirk"
],
"responseCount": 457,
"createdAt": "2024-10-06T12:00:00Z",
"updatedAt": "2024-10-08T09:45:30Z",
"isActive": true,
"metadata": {
"surveyType": "multipleChoice",
"maxResponses": 1000
}
},
"timestamp": 1722873600000,
"headers": {
"source": "survey-platform",
"language": "pt-BR",
"content-type": "application/json",
"event-type": "surveyResponse",
"transaction-id": "f4d9a1b3-67d2-49b8-915b-df1dcee3bdf9"
}
}Topics
In Kafka, "topics" are like categories or themes that efficiently organize messages. Each topic groups together messages that deal with the same subject, making it easier to access and process the information you need.
For example, in an e-commerce system, you could have one topic for orders, another for payments, and one for notifications. Within each topic, messages are organized in chronological order, from oldest to newest.
Technically, a topic is where producers send (publish) messages about a subject, and consumers read them. This way, Kafka ensures that information is always in the right place, so systems can access it quickly and in an organized manner.

Here's an important detail: by organizing messages into topics, Kafka allows multiple consumers to access the messages simultaneously and independently. Each consumer can "subscribe" to a specific topic and get the messages it needs without interfering with others.
This is especially important when we talk about scalability. Imagine a shopping site with thousands of orders being placed every second. If all the orders were thrown into a single disorganized space, processing that data would be chaotic. But with topics, Kafka allows data to be processed in organized batches, making communication between systems fast and efficient.
Now that we understand this, let's see how Kafka divides these messages into partitions, allowing it to process data even faster and more scalably.
Partitions
When we talk about "partitions" in Kafka, we're referring to an intelligent way of dividing work to make the system faster and more efficient. Imagine you have to process millions of incoming messages all the time. If everything were processed in a single "production line," it could take a long time. This is where partitions come into play.
Think of partitions as small sections within a topic. A good everyday example would be organizing documents inside a folder. Imagine you have a folder called "Bills" (the topic), and within it, you create different sections like "Water," "Electricity," and "Phone" (the partitions). Instead of leaving all the documents mixed together, dividing them into sections makes organization easier and allows you to find and process the documents much faster.
Similarly, in Kafka, partitions help to divide messages within a topic, which makes accessing and processing those messages much more efficient.

Let's take the example from the image above: imagine you have a system that collects survey responses. Every time a user responds to a survey, this system sends a message to a Kafka topic called survey-responses. Now, if you have thousands of responses coming in at the same time, it would be very slow to process everything sequentially, one response after another. So, Kafka automatically divides these responses into partitions.
Partition 0 might receive some responses from a group of users.
Partition 1 might receive other responses, either randomly or based on a key (like the survey ID).
Partition 2 could receive more responses, ensuring that the workload is distributed among different partitions efficiently.

These partitions help distribute the processing load among multiple consumers. Instead of a single consumer handling all the responses, you can have multiple consumers, each responsible for processing one or more partitions simultaneously. This ensures that the system can handle large volumes of responses quickly and in a scalable manner.
What Are Offsets?
Imagine Kafka as a large logistics warehouse where packages (messages) are arriving from all directions. The warehouse needs to organize and send these packages to the correct destinations as quickly as possible.
If all the packages were placed in a single pile, the work would be chaotic and slow. Instead, the warehouse divides the packages into different aisles — and each of these aisles represents a partition.
Now, each package receives a serial number label — and this label is the offset. With this offset system, workers (consumers) know exactly where to pick up the packages, in what order, and if they get interrupted, they can return to the exact point where they left off.
After this little analogy, think of offsets as the unique numbering that Kafka assigns to each message within a partition. Every time a new message is written to a partition, it gets an offset number, starting at 0 and increasing as new messages are recorded.
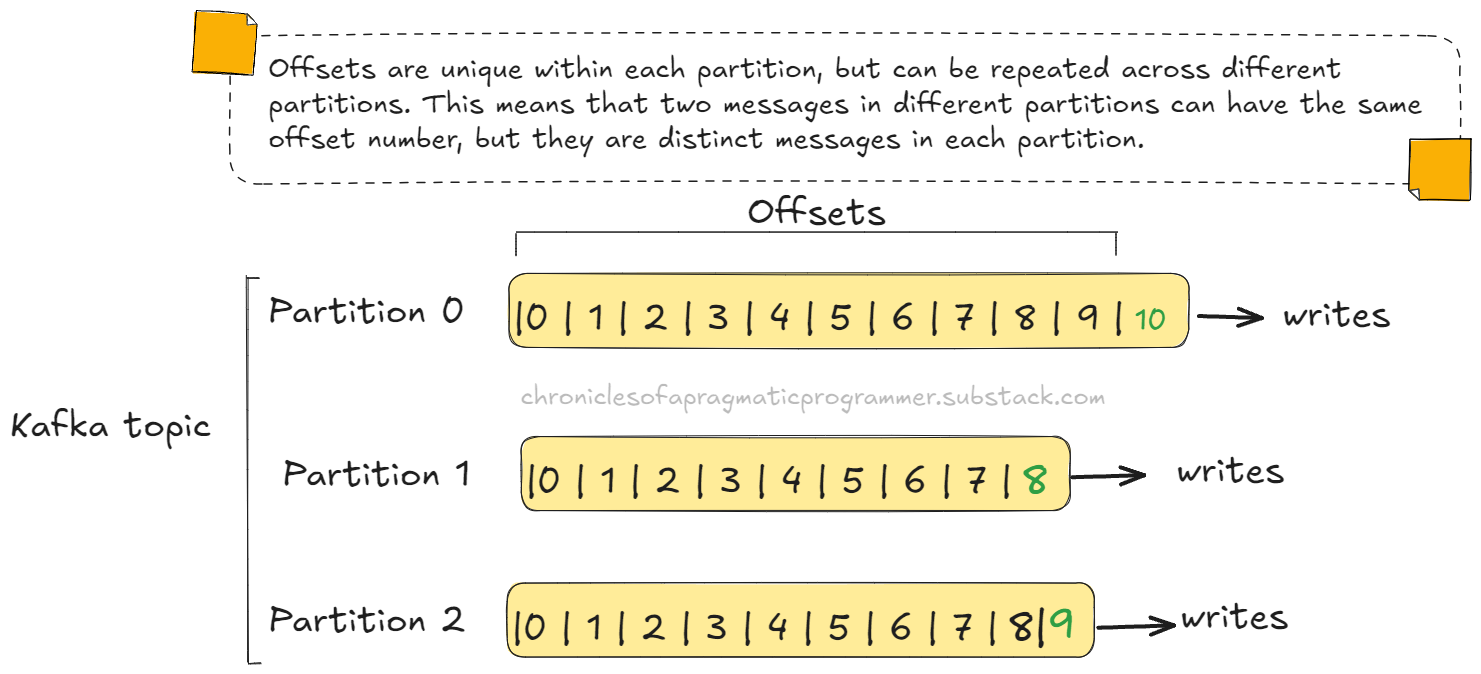
As you can see in the image, each partition (0, 1, and 2) has a sequence of offsets, and Kafka ensures that the order is maintained within each partition.
Partitions and Offsets:
The image shows three partitions of a Kafka topic (Partition 0, Partition 1, Partition 2). Within each partition, messages are recorded with sequential offsets. For example, in Partition 0, the most recent message is at offset 9.
Messages Writing Continuously:
Kafka is constantly writing new messages to the partitions. The arrows on the right indicate that as new messages arrive, they are written to the next available offset. When a new message is received, it will be written with the next offset number.
Unique Offsets for Each Partition:
It is worth noting that offsets are specific to each partition. In Partition 1, for example, the most recent message is at offset 8, while in Partition 2, the most recent offset is 9. These sequences may differ between partitions, but within each one, the order is always preserved.
Offsets are important because they ensure that consumers know exactly where to stop and where to resume reading when they return to consuming messages from a topic. If a consumer has read up to offset 5 in Partition 0, the next time it polls, it will start from offset 6. This ensures that no message is read more than once (unless intentionally reprocessed) and that no messages are skipped.
🚨 ATTENTION! 🚨 The offset does not contain the message itself. It serves as a "marker" indicating the position where the message is stored within the partition.
What Does This Mean in Practice?
Imagine you have a survey API that collects users' questions and answers. Every time a new survey is created, the API publishes a message in Kafka, sending that survey to a topic called survey-events. In this case, Kafka needs to manage large volumes of data, especially if this API is constantly receiving and sending new surveys.
Message Publishing by the API
When a new survey is created, the API publishes this message to the topic
survey-events.This message contains information such as the survey title, response options, and creation date.
Partitioning and Offsets
In Kafka, the topic
survey-eventsis partitioned, which means that messages are distributed among different partitions.Each message receives an offset within its partition.
For example, a message could be sent to Partition 0 with offset 10, while another might go to Partition 1 with offset 6. These messages are stored, waiting to be read by consumers.
Consumers Reading Messages
Imagine you have two different consumer services:
Response Collection Service: needs to monitor each new survey and prepare the system to receive responses.
Data Analysis Service: collects survey information to generate real-time reports and insights.
Both services consume messages from the topic
survey-events, but Kafka distributes the partitions among them. Offsets help consumers know where to resume reading.
How Offsets Ensure Continuity
Suppose the response collection service is consuming Partition 0 and has already processed up to offset 9. When a new message arrives at offset 10, it knows exactly where to continue.
If the data analysis service is reading Partition 1 and has processed up to offset 5, it will read the next message at offset 6.
If any of the services temporarily go down, when they come back, they don't lose the sequence of messages. Kafka stores the offsets and ensures each consumer continues from where it left off.
Benefits of Offsets
Without offsets, there would be no way to guarantee the correct order of messages or avoid repetitions.
Kafka, with its partition and offset logic, resolves this efficiently, allowing the system to grow while maintaining consistency even with a high volume of messages.
Summarized Flow
New Survey Created → The API publishes a message in Kafka.
Kafka Distributes the Message → The message goes to a partition and receives an offset.
Consumers Process Messages → Each consumer reads from the last offset where it left off.
Recovered Failures → If a consumer fails, it resumes from the last offset read without data loss.
Consumer services know exactly where to stop and resume, even in the event of failures. This makes Kafka a powerful tool for handling distributed real-time systems.
How Do Partitions and Offset Help?
Partitions and offsets play fundamental roles in Kafka, each helping in distinct ways:
Scalability: Partitions are crucial in making Kafka highly scalable. When the volume of messages grows, you can add more consumers, and each consumer can be responsible for one or more partitions. This helps distribute the workload, making message processing faster and more efficient without overloading a single processing point.
Parallel Processing: By dividing topics into partitions, Kafka enables parallel processing. This means that different consumers can process messages simultaneously, speeding up response time and increasing system throughput.

Order Maintenance: The offset is a unique number that identifies each message within a partition. It ensures that messages within each partition are processed in the correct order. For example, if you are processing an order flow and the first message is "Order 1" and the second is "Order 2," the offset preserves this sequence within the partition, ensuring that the messages are read in the order they were received.

Continuity and Resilience: Additionally, the offset helps ensure the continuity of processing. If a consumer fails or needs to restart, it can resume from the last processed offset. This ensures that no messages are lost and that processing continues from where it left off, providing resilience to the system.
Review
Topic = The "subject" (or category) of the messages.
Partition = The "divisions" within the topic, allowing for efficient and parallel processing of messages.
Offset = The "marker" for each message within a partition, allowing for precise control of processing.
Now that we understand these differences, let's talk about a very important component within Kafka.
The Role of Zookeeper in Kafka
Now that we've covered quite a bit, let's talk about a key player that works behind the scenes to ensure everything in Kafka runs smoothly: Zookeeper. Think of it as the conductor of an orchestra. But instead of coordinating musicians, it coordinates brokers, partitions, and, in older versions, even offsets and consumers. It's always there, keeping everything in sync so Kafka runs like a well-tuned machine.
But what does Zookeeper actually do? How does it ensure that Kafka keeps running efficiently, even in the face of failures? Let's dive in.
Broker Management: Keeping Things in Order
Kafka is a distributed system, which means you can have multiple brokers (or servers) running simultaneously. Each broker is responsible for storing and processing a set of partitions. But how does Kafka know which brokers are active and available to handle these partitions?
This is the first major function of Zookeeper. It keeps an updated list of all active brokers in the Kafka cluster. Think of it as a kind of "room manager," checking which servers are up, which are down, and redistributing tasks if necessary.

If a broker goes down, Zookeeper acts quickly. It reallocates the partitions that were the responsibility of that broker to another one that is still running. This is what makes Kafka so resilient. Even when part of the system fails, Zookeeper ensures that Kafka keeps operating almost without you noticing.
Offset Coordination: Then and Now
Remember the offsets we discussed earlier? They indicate to the consumer where Kafka should resume reading when processing restarts. But how does Kafka know exactly which offset each consumer stopped at, especially if something goes wrong?
Before Kafka Version 0.9:
Until version 0.9, Zookeeper was directly responsible for storing offsets. This meant that each time a consumer read a message, Zookeeper updated and stored the last offset read by that consumer. If something went wrong, like a system failure or restart, Zookeeper had the exact record of where each consumer stopped, allowing Kafka to resume reading at the correct point.
This approach worked well for smaller clusters, but as systems grew and more consumers were added, it began to overload Zookeeper. It wasn't designed to store high-frequency data like offsets, which limited Kafka's scalability.

Currently (Version 0.9 and Later):
With the introduction of version 0.9, Kafka began storing offsets internally in a special topic called __consumer_offsets. Now, instead of Zookeeper directly storing the offsets, Kafka itself manages and stores this data as messages within this topic. This allows Kafka to handle large volumes of consumers and data much more efficiently, without overloading Zookeeper.
Although Zookeeper no longer directly stores offsets, it still plays an important role in coordinating the overall cluster state. It keeps track of which brokers are active, manages partition leader elections, and coordinates consumers and their groups.
Partition Leader Elections
In Kafka, each partition has a leader, which is the broker responsible for managing reads and writes for that partition. The leader receives messages from producers and distributes them to followers — which are replicas of that partition on other brokers.

But what happens if the leader fails or becomes unreachable? This is where Zookeeper comes in, coordinating the process of electing a new leader quickly and automatically. In the image, if broker-1 fails, Zookeeper identifies this failure and chooses a new leader from among the followers — in this example, broker-2 would take over the leadership of partition-0 (and others if necessary). This ensures that consumers can continue to read messages from that partition.

This automatic failover mechanism is essential to ensuring high availability. Even in scenarios where a broker or partition becomes unavailable, the system remains resilient and data continues to flow. Zookeeper does all the management behind the scenes, without manual intervention, allowing Kafka to be scalable and robust to handle failures.
Therefore, with Zookeeper coordinating leader elections, Kafka ensures that message processing continues to flow, even in adverse situations such as a broker failure.
Cluster Monitoring
In a distributed system like Kafka, with multiple brokers, consumers, and partitions, keeping everything in sync is crucial. It's easy to imagine how chaotic things could get if no one were in charge.
Zookeeper is this central piece of orchestration. It ensures that each broker knows which partitions it is managing, that each consumer knows where it left off, and that the entire system is always aligned. It acts as the invisible manager, keeping all the gears of Kafka running smoothly.

Now, imagine a scenario where you're collecting thousands of survey responses in real-time in a Kafka system with multiple brokers and partitions. What would happen if one of the brokers failed? Without Zookeeper, you could lose important data, or the system might even stop processing messages. This would be disastrous in a system!
This is where Zookeeper comes in. It detects failures, reallocates work to other brokers, coordinates, and does all of this so efficiently that you rarely notice anything went wrong. This keeps Kafka highly available, reliable, and ready to scale as needed.
Zookeeper doesn't get as much attention as the other Kafka components, but it's the true hero behind the scenes. Without it, Kafka would lose its resilience, synchronization, and ability to self-recover in case of failures. It ensures that all parts of Kafka — from brokers to consumers — are always in harmony, working together efficiently and continuously.
Now let's focus a bit more on two fundamental roles that are slightly outside of Kafka's ecosystem.
Keep This Word in Mind: Asynchronous
When we talk about Kafka, one word you should always keep in mind is asynchronous. At the heart of the system are the producers and consumers, responsible for sending and receiving/handling data. However, the big secret behind Kafka's efficiency is precisely the asynchronous way this communication happens, allowing everything to work smoothly without rigid dependencies between parts. Let's better understand how this works.
Producers and Consumers: Sending and Receiving Without Rush
In Kafka, producers are those that generate data and send it to the broker, publishing their messages to topics. They can be any kind of service: from an e-commerce application sending order information to a monitoring system sending error logs. The most important thing here is that producers do not worry about who will consume these messages — they just send the data.
On the other hand, consumers are responsible for reading and processing these messages. They subscribe to the topics they are interested in and, as soon as they are ready, consume the data. The beauty is that they can do this at their own pace, without being synchronized with the producers. This means that even if a consumer is not available when the message is sent, it can access it later since Kafka stores the messages until they are consumed.
Asynchronous Communication
Here’s where the power of asynchronous communication comes in. When we say that communication between producers and consumers is asynchronous, we mean that they do not need to be in sync for the process to work. Producers do not need to wait for consumers to be ready to receive messages, and consumers can grab the messages when convenient.
This not only avoids bottlenecks but also makes the services extremely flexible. Each component works at its own pace without directly depending on the other. If a consumer takes longer to process a message or if there is a very high volume of data, nothing is lost or stuck — Kafka adapts, storing the data temporarily until the consumer can handle it.

Asynchrony is fundamental in distributed systems, especially when there are large volumes of data and multiple services interacting with each other. Without this feature, you would end up with bottlenecks, freezes, and overloads during peak data traffic moments. In the image above, we see this — a consumer API is unavailable, but Kafka will ensure that incoming messages are preserved until the consumer recovers and resumes processing them.
This independence between producers and consumers, facilitated by Kafka, makes the system robust and efficient, even in highly dynamic and large-scale environments. All of this, of course, thanks to the word you should keep in mind: asynchronous.
Great, we're almost at the end of this journey, and if you have any questions, feel free to leave a comment!
The Distributed Heart of Kafka
Now that we've covered logs, partitions, and consumers, it's time to talk about brokers. They are what make Kafka work in a distributed and scalable way. But what exactly are these brokers, and why are they so important? Let’s understand this together!
Imagine Kafka brokers as distribution centers in a large logistics network. Just like in a delivery system, where distribution centers receive, store, and send packages to different destinations, Kafka brokers do the same with messages. They receive messages from producers, temporarily store them, and deliver them to consumers in an organized and efficient way.
A broker in Kafka is simply a server that is part of the Kafka cluster. It is responsible for receiving data from producers, storing these messages in partitions (within topics), and then delivering the messages to consumers who subscribe to read them.

The Role of Brokers!
Horizontal Scalability: The ability to grow as demand increases.
Resilience: The ability to handle failures without system interruptions.
High Availability: Ensuring the system is always operational, even in case of failures.
In summary, brokers ensure that everything keeps flowing, even when failures occur. Now let’s briefly discuss some questions that may arise. I’ll list these questions in bullet points to better organize the reasoning.
Do Consumers Subscribe to Topics or Partitions?
Consumers in Kafka subscribe to topics. When a consumer subscribes to a topic, Kafka automatically distributes that topic's partitions among the consumers. This means that each consumer will be responsible for processing messages from one or more partitions, and it will keep reading messages in the order indicated by the offsets.
If you have a topic with three partitions and three consumers subscribed to that topic, Kafka will ensure that each consumer processes messages from a different partition. This guarantees that messages are processed in a parallel and distributed manner, which makes Kafka extremely flexible, allowing the system to scale as demand grows.
What If There Is Only One Consumer Per Topic? Is Kafka Still the Best Choice?
You might be wondering: "What if I only have one consumer interested in the topic? Is Kafka still the ideal solution?" That's a valid question, after all, Kafka shines in scenarios where multiple consumers are processing data in parallel. But let’s analyze this situation together.
Kafka was designed to handle large volumes of data and processing at scale. So, if you're dealing with a scenario where only a single service or system is interested in the messages of a topic, Kafka might seem like "using a cannon to kill a fly." But is it really?
When Is Kafka a Good Choice for a Single Consumer?
Even if there is only one consumer processing the messages of a topic, Kafka can still be a solid choice depending on your scenario. Let’s consider some situations where it stands out:
Data Volume: If you are dealing with large volumes of data (even if there's only one consumer), Kafka may still be ideal because of its ability to handle high-throughput streams and persist messages reliably. Kafka's performance and scalability are still a major advantage.
Persistence Guarantee: Kafka keeps messages stored for a configurable period, meaning that even if your only consumer is temporarily offline, it can come back and "read" the messages it missed without any issues.
Scalable Future: Today, you may only have one consumer, but what about tomorrow? Kafka allows you to easily add new consumers in the future if other systems or services also need access to the data. It adapts as your needs evolve.
But When Is Kafka Not So Ideal?
If your scenario involves just one consumer and the data volume is relatively small, Kafka might be too robust a solution. In that case, perhaps a simpler message queue (like RabbitMQ or SQS) could serve you better. These systems are lighter, easier to set up, and work well in scenarios where data volume is smaller, and simplicity is more important than scalability.
So, Kafka or Not?
The answer depends on your needs. If you are dealing with large volumes of data, want message durability, and are thinking about future scalability, Kafka is a great choice, even with just one consumer. But if your scenario is lighter and does not involve a lot of processing or data at scale, it might be worth considering simpler options.
In the end, Kafka is like a utility belt: it may seem like overkill for a small problem, but it is always ready to grow along with your demands. In this article, I won’t have time to dive into other important questions and doubts, but if you have any, feel free to leave a comment!
Conclusion
We covered a lot! By exploring the anatomy of Kafka, we understood how this distributed messaging platform operates efficiently and scalably. We started with the idea of topics and partitions, which help to divide and organize large volumes of data, allowing multiple consumers to process messages in parallel. We also discovered the crucial role of offsets, which ensure that each message is read in the correct order within a partition, enabling precise control over processing.
Additionally, we saw how the broker is the heart of Kafka, responsible for storing and distributing messages, and how Zookeeper keeps everything in sync, ensuring that brokers are always coordinated and consumers keep running even in the face of failures.
Finally, we understood that messages in Kafka are not just pieces of data — they have keys, values, timestamps, and other metadata that help maintain the integrity and traceability of information. With this, we saw that Kafka is more than just a simple messaging tool; it is a robust and flexible platform, essential for systems that need to process real-time data in a distributed and resilient way.
If you enjoyed the article, leave a like on the post and share it!