
Microservices: Confiar, Validar ou Compartilhar?
Um contrato deve definir limites, não criar dependências rígidas. - Eric Evans

Quando trabalhamos com microsserviços, não basta apenas garantir que um serviço funcione bem isoladamente — existe outro desafio, a comunicação e colaboração entre eles. Isso é ainda mais crítico quando falamos de comunicação assíncrona, como no uso de filas (ex.: RabbitMQ, Kafka).
Imagine que temos um microsserviço A, responsável por coletar dados externos e enviá-los para uma fila. Do outro lado, um microsserviço B consome essas mensagens e precisa armazená-las ou processá-las. Mas aqui surge uma questão importante: os dados enviados por A já foram validados — B deve confiar neles cegamente ou validar novamente?
Essa dúvida levanta outras questões:
• Se A já validou, validar novamente em B seria redundante?
• Mas e se A tiver um bug e enviar um dado inconsistente? Como B se protege?
• Seria melhor compartilhar uma biblioteca de validação entre os serviços? Isso resolve todos os problemas?
O que parece um detalhe técnico pode impactar diretamente a confiabilidade e a resiliência do sistema. Neste artigo, vamos discutir quando e por que validar dados em diferentes pontos do fluxo e entender como evitar problemas comuns nessa integração.
Interfaces Externa e Interna
Imagine um restaurante movimentado. Os clientes chegam, olham o cardápio e fazem seus pedidos. Mas eles não vão direto para a cozinha, certo? Existe uma pessoa que intermedia tudo: o garçom.
O garçom recebe os pedidos, os organiza e os comunica à cozinha no formato certo. Se um cliente pedir algo que não existe no cardápio, o garçom avisa imediatamente — sem precisar incomodar o chef.
Aqui, o garçom representa a interface externa: ele protege a cozinha (o sistema interno) da complexidade e das inconsistências do mundo externo (particularidades de cada cliente), garantindo que apenas pedidos válidos e compreensíveis cheguem até lá.

Já a cozinha funciona com processos internos bem definidos: os chefs sabem exatamente como preparar os pratos, seguindo padrões claros e consistentes. Essa organização interna é a interface interna, que lida com os pedidos padronizados e mantém o sistema funcionando de forma eficiente.

Nos microsserviços, a interface externa assegura que as requisições do mundo externo cheguem no formato correto, enquanto a interface interna mantém o sistema organizado, facilitando a comunicação entre os serviços.
Por que tratá-las como independentes?
Interfaces externas e internas não devem ser apenas conceitos distintos; elas precisam ser tratadas como entidades independentes. Mas por quê?
Vamos entender isso com um cenário:
Imagine que o Serviço A consome dados de uma API externa, talvez uma integração com um sistema de pagamento. Essa API fornece informações sobre transações, como:
• transaction_id
• amount
• currency
• status
• user_info (contendo nome, e-mail e até o IP do usuário)
Agora, o Serviço A precisa enviar parte dessas informações para o Serviço B, que apenas calcula métricas financeiras, como o total faturado. Para essa tarefa, o Serviço B só precisa dos campos:
• amount
• currency
• status
Se o Serviço B consumir diretamente o formato recebido da API externa, ele se tornará um dependente direto desse contrato externo. Isso pode parecer inofensivo no início, mas pense no impacto de mudanças futuras.
Suponha que a API de pagamento decida:
• Renomear o campo amount para value.
• Remover o campo currency e passar a incluir essa informação dentro de um objeto pricing_details.
• Adicionar um campo extra chamado risk_score com análises antifraude.
Essas mudanças — que não têm nenhuma relação direta com a lógica interna de métricas — forçariam o Serviço B a ser ajustado, mesmo que ele não precise dessas informações adicionais. O acoplamento direto à estrutura externa causaria um efeito cascata, exigindo retrabalho desnecessário.
Agora, vamos ver a abordagem correta.
Separando as interfaces
O Serviço A deveria atuar como uma “camada de tradução” entre o mundo externo e o interno. Em vez de passar o payload original da API para o Serviço B, ele:
1. Valida a estrutura recebida, rejeitando mensagens inválidas ou incompletas.
2. Transforma os dados em um formato interno estável, adequado à lógica interna.
3. Publica essas informações na fila no RabbitMQ usando um contrato interno simples.
O formato enviado ao Serviço B poderia ser algo assim:
{
"amount": 150.00,
"currency": "USD",
"status": "completed"
}Esse formato é independente da estrutura original da API externa. Mesmo que novos campos surjam ou mudem na integração de pagamentos, o Serviço B continuará operando normalmente.
E Se Usarmos um Broker? Ainda Existe Interface?
No tópico anterior, vimos como separar as interfaces externas e internas ajuda a proteger os serviços de mudanças desnecessárias e a manter o sistema mais estável. Mas agora surge uma dúvida comum:
“Se dois serviços se comunicam através de um broker, como o RabbitMQ, ainda existe uma interface entre eles?”
A resposta é: sim, absolutamente!
O uso de um broker não elimina a necessidade de uma interface bem definida; ele apenas muda a forma como essa interface se apresenta.
Broker: Caixa de Correio, Não Comunicação Direta
O uso de um broker não elimina a necessidade de uma interface bem definida; ele apenas muda a forma como essa interface se apresenta.
Pense novamente no restaurante, mas agora com uma diferença: os pedidos não são entregues verbalmente ao chef. Em vez disso, os garçons registram os pedidos em um painel eletrônico. Esse painel não cozinha, não questiona e não valida os pedidos — ele apenas exibe as informações no formato previamente definido para que o chef possa entender e preparar os pratos corretamente.
Aqui, o painel eletrônico representa a interface entre garçons e cozinha, definida pela estrutura específica das informações exibidas: por exemplo, sempre no formato JSON com campos como {"mesa": 5, "prato": "Lasanha", "quantidade": 2}. Se um pedido chegar sem esses campos ou com tipos de dados incorretos, o chef terá dificuldades em interpretá-lo, mesmo que o painel o exiba.
Da mesma forma, o RabbitMQ é uma espécie de “caixa de correio” que transporta mensagens de um serviço para outro. Ele não compreende o conteúdo, apenas garante a entrega. No entanto, a interface entre os serviços permanece — só que, agora, ela se torna implícita no formato das mensagens que transitam pelo broker.
Logo, definir claramente o formato da mensagem, geralmente usando JSON, não é um detalhe opcional, mas uma necessidade fundamental para garantir que todos os “chefs” no sistema saibam interpretar corretamente os “pedidos” recebidos.
A Interface Invisível nas Mensagens
Mesmo sem uma API REST explícita, o formato das mensagens trocadas entre os serviços continua sendo a interface. Se o Serviço A decidir enviar um campo novo inesperado e o Serviço B não souber interpretá-lo, o sistema pode falhar.
Por exemplo, imagine a seguinte situação:
• O Serviço A envia a seguinte mensagem:
{
"amount": 150.00,
"currency": "USD",
"status": "completed"
}O Serviço B consome essa mensagem, calcula métricas e armazena os resultados.
Agora, suponha que o Serviço A seja atualizado e passe a enviar mensagens assim:
{
"amount": 150.00,
"currency": "USD",
"status": "completed",
"risk_score": 85
}Se o Serviço B não estiver preparado para lidar com esse novo campo risk_score, podem ocorrer comportamentos inesperados, desde erros de parsing até falhas na lógica de processamento.
Interface Além do Formato: O Comportamento
A interface entre dois serviços via broker não se limita ao formato das mensagens; ela também envolve o comportamento esperado.
Perguntas importantes incluem:
• Que tipos de mensagens o Serviço A pode enviar?
• O que o Serviço B espera receber?
• Como o Serviço B reage ao receber um campo inesperado ou uma mensagem malformada?
• Há garantias sobre a ordem das mensagens?
Se essas definições não forem respeitadas, o uso de um broker pode mascarar problemas que só aparecerão em produção, quando mensagens inesperadas ou com dados inconsistentes começarem a circular.
A Interface Interna Deve Ser Estável
Agora que entendemos a importância de separar as interfaces externa e interna, precisamos falar sobre um ponto fundamental: a interface interna deve ser projetada para as necessidades do sistema, e não apenas refletir o formato dos dados externos.
Essa estabilidade é o que garante que o sistema continue funcionando sem ajustes constantes sempre que uma API externa mudar.
Mas o que significa, na prática, ter uma interface interna estável? Vamos por partes.
Por que a Interface Interna Precisa Ser Estável?
Quando dois serviços se comunicam, o objetivo é que essa comunicação seja previsível, confiável e fácil de manter. Se o Serviço A apenas “repassa” os dados externos no formato recebido, o Serviço B fica sujeito a mudanças fora do controle do sistema — como atualizações na API de terceiros.
Por exemplo, imagine que o Serviço A recebe dados de uma API de pagamento. O formato original chega assim:
{
"transaction_id": "abc123",
"amount": 100.50,
"currency": "USD",
"payment_status": "approved",
"customer_info": {
"name": "Maria",
"email": "maria@email.com"
}
}Agora, suponha que o Serviço B precisa apenas das informações de valor e status. Se o Serviço A enviar o payload completo para o Serviço B, qualquer mudança futura nessa estrutura (como a renomeação de payment_status para status) pode quebrar o processamento.
Por isso, o formato interno deve ser simples e adequado às necessidades do Serviço B.
Princípios de uma Interface Interna Estável
Para garantir essa estabilidade, a interface interna precisa seguir alguns princípios:
1. Independência
O formato interno deve ser independente da estrutura externa. O Serviço A deve transformar os dados recebidos no formato que o Serviço B entende, sem depender diretamente da estrutura original.
Assim, se a API externa mudar, a adaptação acontece apenas no Serviço A, mantendo o Serviço B intacto.
2. Resiliência
O Serviço B não deve precisar entender regras ou formatos externos. Ele deve receber informações claras e consistentes.
Isso o torna mais resiliente, evitando falhas causadas por mudanças externas ou dados inesperados.
Benefícios dessa Separação
Ao seguir esse fluxo, ganhamos diversos benefícios:
• Menos impacto de mudanças externas: se a API externa mudar, apenas o Serviço A precisa ser ajustado. O Serviço B continua funcionando normalmente.
• Comunicação mais simples: a interface interna é mais clara, com apenas os dados necessários para o processamento.
• Manutenção facilitada: os times podem trabalhar de forma mais independente, sem precisar entender a estrutura externa.
• Evolução segura: o formato interno pode evoluir conforme as necessidades do sistema, e não conforme mudanças externas.
“Se houver muito compartilhamento, nossos serviços de consumo se tornam acoplados às nossas representações internas. Isso diminui nossa autonomia,”
― Sam Newman, Building Microservices: Designing Fine-Grained Systems
A Validação no Serviço B: Mais do Que Simples Precaução
Se o serviço A já validou os dados antes de enviá-los para a fila, por que o serviço B precisaria validar novamente? Essa dúvida é comum, e a resposta vai muito além de um simples “por precaução”.
O serviço B não deve confiar cegamente nos dados recebidos, mesmo que venham de outro serviço do mesmo sistema. Isso porque ele é o responsável pelas regras centrais do negócio, e garantir a qualidade dos dados processados é parte fundamental desse papel. Mas porque?
Pense um restaurante conceituado que recebe ingredientes de fornecedores externos. Mesmo que esses fornecedores sejam bem avaliados, o chef e sua equipe sabem que erros podem acontecer. Assim que os ingredientes chegam, eles passam por uma inspeção rigorosa: são verificados a qualidade, a procedência e a validade de cada item.
Se um lote de tomates, por exemplo, estiver com algum problema e o restaurante confiar cegamente no fornecedor, sem checar sua qualidade, isso pode comprometer o sabor e a segurança dos pratos servidos aos clientes. Da mesma forma, confiar apenas na origem dos ingredientes sem uma verificação adicional pode levar a problemas maiores na experiência do cliente e na reputação do restaurante.
Agora vamos trazer isso para nosso contexto. Imagine que o serviço A comece a enviar dados inconsistentes por conta de um bug, de uma atualização inesperada ou de uma falha momentânea na validação. Se o serviço B aceitar esses dados sem fazer uma verificação, o erro pode se espalhar e comprometer a integridade de todo o sistema. Assim como no restaurante, onde a inspeção dos ingredientes é fundamental para garantir a qualidade dos pratos, a validação dos dados entre microsserviços é crucial para manter o sistema seguro e confiável.
Em resumo, mesmo confiando nos dados que vêm de outra fonte, é essencial fazer uma checagem para evitar que erros passem despercebidos e causem problemas maiores.
Validações Exclusivas no Serviço B
Além de prevenir problemas, o serviço B pode necessitar de validações e ajustes específicos que fazem sentido apenas dentro do seu contexto. Veja alguns exemplos:
• Transformação de Dados:
Enquanto o serviço A pode coletar informações em um formato genérico, o serviço B pode exigir que esses dados sejam convertidos para um formato específico, compatível com sua lógica interna.
• Regras de Negócio:
Nem tudo que é válido para o serviço A atende aos critérios do serviço B. Assim, o serviço B pode precisar aplicar regras internas mais rigorosas para garantir que os dados se alinhem com suas particularidades.
• Verificação de Integridade:
Mesmo que os dados pareçam corretos à primeira vista, eles podem entrar em conflito com informações já presentes no serviço B. Uma verificação adicional é essencial para manter a consistência e a integridade dos dados.
Em resumo, enquanto o serviço A se encarrega de garantir que os dados sejam aceitáveis, é o serviço B que assegura que esses dados estejam corretos e alinhados com o contexto específico do negócio.
Quem Assume a Responsabilidade?
No final das contas, a questão não é apenas “é necessário validar de novo?”, mas sim “quem assume a responsabilidade pelos dados no estágio final do processo?”.
Se o serviço B simplesmente confiasse no serviço A, ele estaria delegando sua responsabilidade para outro serviço, o que pode ser perigoso. Em vez disso, ao validar os dados novamente, ele assume controle total sobre o que entra no sistema e garante que nenhuma informação errada ou inconsistente chegue ao coração do negócio.
Em sistemas distribuídos, não podemos confiar que um dado é válido apenas porque “veio de um serviço confiável”. Um erro em um ponto pode se espalhar, e validar no serviço B não é um desperdício de recursos, é um investimento na resiliência do sistema.
Portanto, sempre que surgir a dúvida: “Mas o serviço A já validou, preciso validar de novo no B?” – a resposta é sim, porque o serviço B é o guardião das regras de negócio, e garantir a consistência dos dados é sua responsabilidade direta.
Agora que isso está claro, vamos seguir em frente e explorar outras questões críticas sobre validação e confiabilidade em microsserviços!
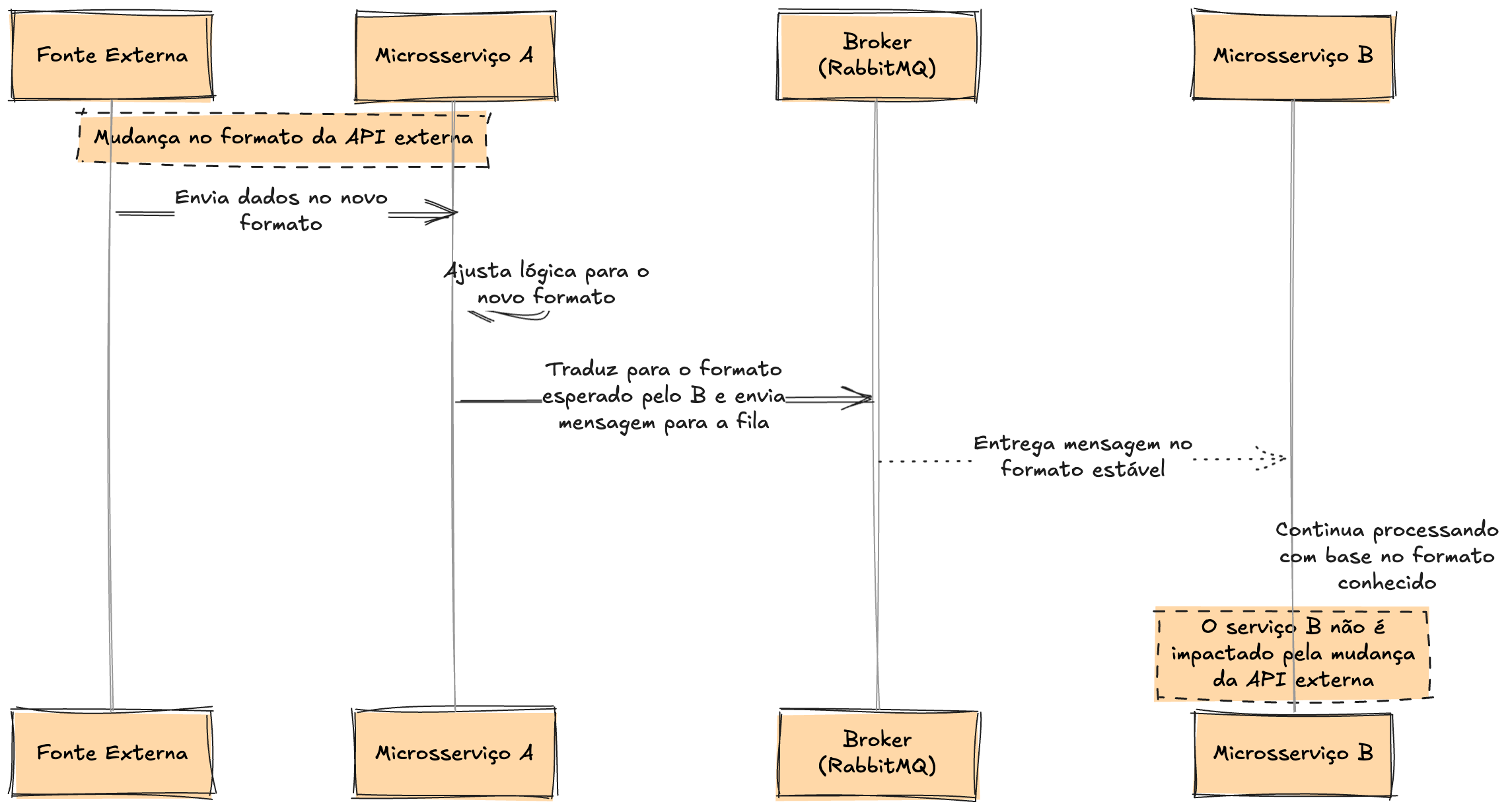
Impacto das Mudanças: Por Que Separar Interfaces Importa?
Mudanças são inevitáveis. APIs externas evoluem, dados ganham novos formatos, campos são adicionados e, às vezes, até a estrutura da informação muda completamente. Agora, imagine que a API usada pelo serviço A sofre uma alteração inesperada. Ele precisa ser ajustado para lidar com a nova realidade. Mas o serviço B não deve ser afetado por essa mudança.
Se os dois serviços compartilhassem a mesma interface, uma simples modificação externa poderia causar um efeito dominó, forçando mudanças em toda a arquitetura. Isso quebraria um dos princípios fundamentais dos microsserviços: evolução independente.
Então, como evitar esse problema?
A resposta está na separação clara entre interface externa e interface interna. O serviço A atua como um filtro e tradutor:
1. Recebe os dados externos no formato da API de origem.
2. Transforma essas informações para um formato estável, interno e confiável.
3. Publica a versão já adaptada na fila do RabbitMQ.
Assim, mesmo que o mundo externo mude, o serviço B continua operando sem precisar de ajustes, pois ele só interage com o formato padronizado que já conhece.
O Papel do RabbitMQ na Estabilidade
O RabbitMQ não é apenas um canal de mensagens, mas também uma barreira de proteção. Ele desacopla os serviços, permitindo que cada um evolua no seu próprio ritmo sem causar impacto direto no outro.
Isso significa que:
• Se o serviço A precisar se adaptar a um novo fornecedor de dados, ele pode fazer isso sem atrapalhar o serviço B.
• Se o serviço B quiser mudar suas regras de negócio ou melhorar suas validações, ele pode fazer isso sem se preocupar com alterações no serviço A.
• Se o serviço A ficar temporariamente fora do ar, as mensagens na fila continuam armazenadas até que ele volte a funcionar – evitando perda de dados.
No final das contas, essa abordagem garante que mudanças externas não se tornem problemas internos. O sistema se torna mais confiável, resiliente e previsível.
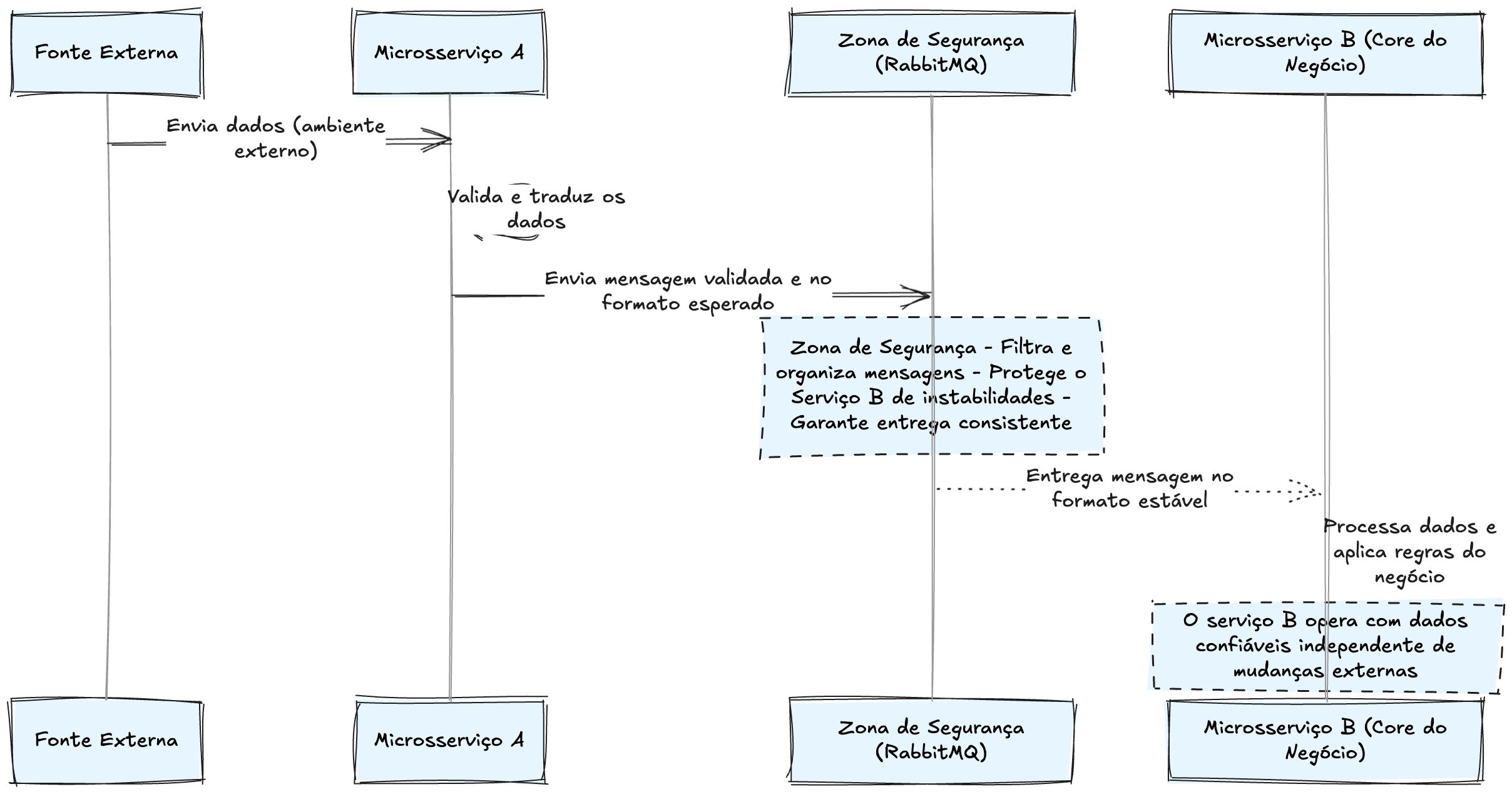
Resiliência e Estabilidade: Garantindo a Consistência
Com essa arquitetura, o serviço B foca exclusivamente na aplicação correta das regras de negócio, sem precisar se preocupar com os detalhes de onde os dados vieram ou como chegaram ali.
Isso fortalece o sistema como um todo:
• O serviço A pode se adaptar às mudanças externas sem afetar o resto da aplicação.
• O serviço B recebe apenas informações bem definidas e previsíveis, garantindo que suas regras continuem funcionando sem interrupções.
• O RabbitMQ funciona como um amortecedor, isolando falhas e mudanças entre os serviços.
Em um mundo onde a confiança e a consistência são essenciais, essa separação entre coleta de dados (A) e regras de negócio (B) não é apenas uma conveniência técnica – é um fator determinante para a robustez do sistema.
Validação de Dados vs. Aplicação de Regras de Negócio
Essa é uma confusão comum: validação de dados não é a mesma coisa que aplicação de regras de negócio. Embora pareçam conceitos próximos, misturá-los pode gerar um sistema engessado, difícil de manter e propenso a falhas.
Vamos separar bem as coisas.
O Que É Validação de Dados?
Validar dados significa garantir que a estrutura da informação está correta e coerente. São regras genéricas, aplicáveis a qualquer sistema que lide com esse tipo de dado, e não dependem de um contexto específico do negócio.
Pense em uma encomenda chegando a um centro de distribuição. Antes de ser enviada para um cliente, ela passa por uma triagem básica:
✅ O pacote tem um código de rastreamento válido?
✅ O endereço está preenchido?
✅ O peso informado está dentro dos limites permitidos?
Se qualquer uma dessas informações estiver incorreta, a encomenda nem sequer segue adiante. Esse processo é equivalente à validação de dados, que acontece no serviço A.
No contexto dos microsserviços, isso significa que o serviço A verifica coisas como:
• Campos obrigatórios estão presentes?
• Os formatos estão corretos? (e-mail, data, número, CPF, etc.)
• Valores numéricos estão dentro de um intervalo permitido?
Isso evita que dados corrompidos ou incompletos entrem no sistema.
O Que São Regras de Negócio?
Agora, imagine que a encomenda passou pela triagem e chegou ao setor de expedição. Aqui, as decisões são tomadas com base no negócio:
🚚 O cliente pode receber esse tipo de produto na sua região?
💰 O pedido pode ser aprovado ou precisa de verificação adicional?
📦 Esse item exige um tipo específico de embalagem ou manuseio especial?
Essas são regras de negócio. Elas não são universais; elas dependem do contexto do sistema e do que ele precisa garantir para funcionar corretamente.
Agora trazendo isso para os microsserviços:
• Uma data pode estar no formato correto, mas é válida no contexto do negócio? (Exemplo: uma data de expiração não pode estar no passado)
• Um pedido pode ser aceito? (Exemplo: ele atende aos critérios mínimos de valor ou ao estoque disponível?)
• Uma transação deve ser processada? (Exemplo: o usuário tem crédito suficiente para essa operação?)
Essas regras só fazem sentido dentro do serviço B, porque é ele quem conhece as exigências do domínio.
O Serviço A Nunca Deve Aplicar Regras de Negócio de B
Agora vem um ponto crucial: o serviço A nunca deve tomar decisões que pertencem ao serviço B.
O serviço A é apenas um coletor e validador de dados básicos. Ele pode transformar as informações para um formato mais estruturado e confiável, mas ele não decide o que fazer com esses dados.
Se A começasse a aplicar regras de B, isso geraria uma dependência indesejada, tornando o sistema mais difícil de manter e mais vulnerável a mudanças.
Por que isso é um problema?
1️⃣ Quebra do princípio de desacoplamento – Se as regras de B mudarem, A precisaria ser atualizado também, criando uma dependência indesejada.
2️⃣ Dificuldade na evolução do sistema – Se as regras de negócio precisarem mudar rapidamente, será necessário modificar mais de um serviço, aumentando o risco de falhas e o custo da manutenção.
3️⃣ Comportamento imprevisível – Se um erro ocorrer na validação de A, isso pode impedir que regras importantes sejam aplicadas corretamente em B, comprometendo decisões críticas do negócio.
Então, a função de A é garantir que os dados cheguem limpos e prontos para o serviço B, mas sem carregar nenhuma lógica do negócio.
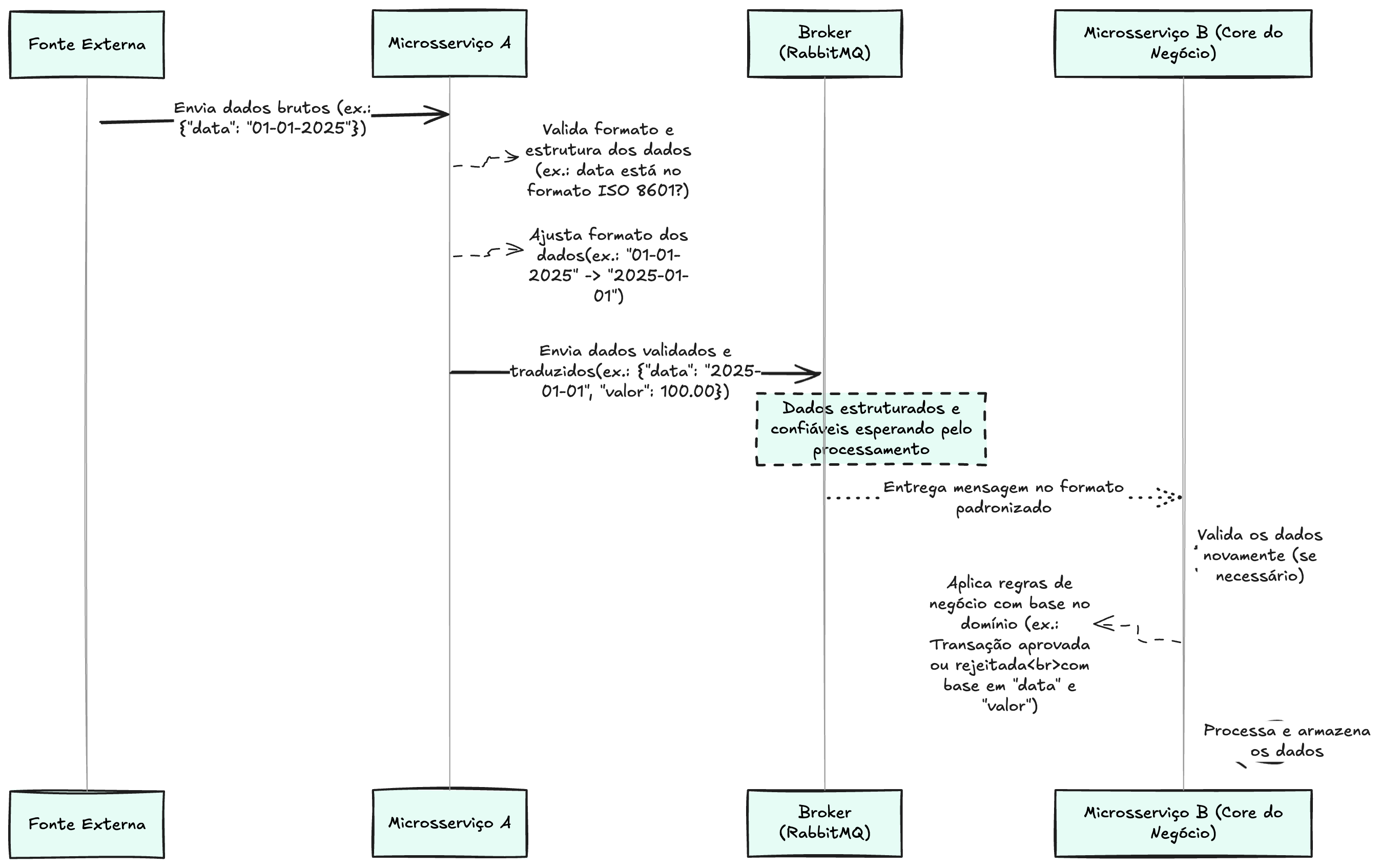
O Serviço B Deve Confiar na Validação de A?
Isso depende 😅. Mesmo que o serviço A tenha validado os dados antes de enviá-los para a fila, o serviço B pode querer verificar novamente algumas informações. Isso acontece porque a validação inicial em A garante que os dados estão corretos em nível estrutural, mas não garante que fazem sentido para o negócio.
Em alguns casos, B pode:
✅ Revalidar informações críticas, como garantir que um valor numérico esteja dentro dos limites esperados no domínio.
✅ Verificar consistência com outras informações já armazenadas no banco de dados.
Mas em outros cenários, B pode decidir confiar completamente na validação feita por A, evitando reprocessamentos desnecessários.
Tomar a decisão sobre o que validar novamente depende do nível de confiança entre os serviços e do impacto que um erro pode ter no negócio.
Se um erro nos dados puder comprometer operações importantes, é essencial validar novamente em B. Se o impacto for pequeno ou nulo e os dados já forem confiáveis, não há necessidade de repetição.
Compartilhar uma Biblioteca de Validação Entre os Serviços É Realmente uma Boa Ideia?
A ideia de compartilhar uma biblioteca de validação entre os serviços pode parecer, à primeira vista, uma solução eficiente. Afinal, por que replicar lógica de validação em dois lugares diferentes? No entanto, quando olhamos com mais cuidado para o cenário de microsserviços e seus princípios, percebemos que essa abordagem pode trazer mais problemas do que benefícios.
O Problema do Acoplamento
Microsserviços foram projetados para serem independentes e com Baixo Acoplamento.
Quando você introduz uma biblioteca compartilhada de validação entre os serviços, cria uma dependência técnica que pode dificultar a evolução de cada serviço. Imagine que você precise alterar a lógica de validação para atender a uma nova necessidade no serviço A. Essa mudança pode impactar o serviço B, mesmo que ele não precise dessa atualização, forçando ajustes desnecessários ou expondo-o a riscos.
Além disso, essa dependência cria um acoplamento rígido entre os serviços, o que contradiz o princípio de desacoplamento que torna os microsserviços tão eficientes. A autonomia de cada serviço é comprometida, dificultando sua manutenção e evolução.
A Validação em Cada Serviço Tem Contextos Diferentes
Se tem uma coisa que precisa ficar clara, é que a validação feita no serviço A e no serviço B não tem o mesmo propósito. Cada uma acontece em um contexto diferente e resolve problemas distintos.
O serviço A recebe dados de fontes externas e precisa garantir que eles estão bem formados – ou seja, que os campos obrigatórios existem, que os valores seguem os formatos esperados e que não há informações inválidas. Só depois disso ele envia esses dados para o RabbitMQ.
Já o serviço B não está preocupado com o formato dos dados, mas sim com o que eles significam no contexto do negócio. Ele precisa validar se aquela informação faz sentido antes de processá-la, persistí-la ou usá-la para alguma decisão importante.
Compartilhar uma Biblioteca de Validação?
Pode parecer tentador criar uma biblioteca de validação compartilhada entre os dois serviços, mas essa abordagem pode mais atrapalhar do que ajudar. Misturar validações técnicas (A) com validações de negócio (B) cria um código confuso e difícil de manter.
Isso pode gerar problemas como:
• Efeito cascata indesejado: Uma mudança na validação de A pode impactar B sem necessidade, forçando ajustes em um serviço que nem deveria ser afetado.
• Acoplamento desnecessário: B acaba dependendo de uma biblioteca que foi feita para resolver os problemas de A, o que pode levar a regras que não fazem sentido no seu contexto.
• Dificuldade de versionamento: Se A e B precisarem de versões diferentes da biblioteca, o gerenciamento fica complexo e aumenta o risco de conflitos.
Cada serviço deve ser dono das suas próprias regras de validação, respeitando a separação de responsabilidades. O que faz sentido para um, pode ser irrelevante para o outro – e é por isso que cada um deve lidar com suas próprias validações da forma mais clara possível.
Agora vamos falar sobre uma outra dúvida que pode surgir…
É Violação do DRY?
Se o serviço A já validou os dados antes de enviá-los, validar novamente no serviço B não seria redundante? Isso não viola o princípio do DRY (Don’t Repeat Yourself)?
Essa é uma dúvida comum, e a resposta pode surpreender.
O DRY não é apenas sobre evitar código duplicado, mas sim sobre evitar a duplicação de conhecimento. Se um conceito precisa mudar, ele deve ser modificado em apenas um lugar.
Por exemplo:
• Se a idade mínima para cadastro mudar de 18 para 21 anos, não faz sentido essa regra estar espalhada por diversos serviços, exigindo alterações manuais em cada um deles. Isso sim é uma violação do DRY.
• Já verificar se um campo obrigatório está presente ou se um e-mail tem um formato válido em diferentes pontos do sistema não é duplicação de conhecimento – são verificações de segurança e consistência feitas em contextos diferentes.
Por Que Validar em Vários Lugares?
Mesmo que pareça repetição à primeira vista, validar dados em diferentes serviços tem razões sólidas.
1. Segurança e Confiança
Cada serviço precisa garantir sua própria integridade. Você nunca deve confiar cegamente nos dados que recebe, mesmo que venham de outro serviço dentro do seu sistema.
Se o serviço A validar a entrada, mas por algum motivo uma falha ou erro inesperado permitir a passagem de dados inválidos, o serviço B precisa estar preparado para lidar com isso.
Pense nisso como um sistema de inspeção de bagagens em aeroportos. O passageiro pode ter passado pela segurança no embarque, mas ao chegar no destino, sua mala pode ser verificada novamente. Isso não é desperdício, é proteção contra riscos inesperados.
2. Independência dos Serviços
Cada microsserviço precisa ser autônomo. Se o serviço B depender do serviço A para garantir que os dados estão corretos, ele se torna frágil e acoplado.
O que acontece se o serviço A mudar sua lógica de validação ou introduzir um bug? O serviço B pode começar a falhar sem perceber a origem do problema.
Validar novamente no serviço B significa garantir que ele pode operar de forma independente, sem depender do funcionamento correto de outro serviço.
3. Contextos Diferentes
As validações feitas em A e B não são necessariamente as mesmas. O serviço A faz verificações básicas para garantir que os dados recebidos estão tecnicamente corretos (exemplo: formato de data válido, CPF bem formado, valores dentro de um intervalo esperado).
Já o serviço B valida se os dados fazem sentido dentro das regras de negócio.
Por exemplo:
• O serviço A pode validar que um campo “data de expiração” está no formato correto.
• Mas apenas o serviço B pode decidir se essa data realmente pode ser usada, considerando regras do domínio, como “a data precisa ser no futuro”.
O que parece ser a mesma validação, na verdade tem propósitos diferentes.
E o Custo de Manter Validações em Vários Lugares?
Manter validações em mais de um serviço pode parecer um custo extra, mas não validar pode custar muito mais caro.
Se um dado inválido entrar no sistema e não for barrado no serviço correto, ele pode se propagar e gerar falhas difíceis de rastrear.
Para minimizar o impacto da duplicação, algumas estratégias ajudam:
• Reutilização de Schemas – Definir esquemas estruturais compartilhados, como JSON Schema ou Protobuf, para garantir consistência sem criar dependências desnecessárias.
• Automação de Testes – Testes automatizados garantem que mudanças nas validações não causem falhas inesperadas.
No fim das contas, validar os dados onde realmente faz sentido não é desperdício – é garantia de confiabilidade.
Validar Não Viola o DRY, Mas Ignorar Pode
Se você está pensando que validar no serviço B é repetição, a realidade é o oposto: não validar pode criar dependências ocultas e comprometer a robustez do sistema.
O DRY é violado quando você precisa modificar uma regra de negócio em vários lugares porque ela foi espalhada entre serviços. Mas validação de dados não é regra de negócio, e sim uma proteção contra erros e inconsistências.
Portanto, validar dados nos serviços que os consomem não viola o DRY – na verdade, é um requisito fundamental para microsserviços independentes e confiáveis.
Agora que já esclarecemos esse ponto, podemos seguir para a próxima questão: como estruturar essas validações de maneira eficiente, sem criar acoplamento desnecessário?
O Papel Fundamental das Validações no Design de Microsserviços
Projetar microsserviços robustos não é apenas sobre dividir funcionalidades, mas sobre garantir que cada serviço seja autônomo, confiável e preparado para lidar com mudanças. E as validações desempenham um papel essencial nessa construção.
Validar dados em diferentes pontos não é desperdício nem violação do DRY – é uma estratégia fundamental para garantir a integridade e a resiliência do sistema. O DRY trata da duplicação de conhecimento, não da aplicação de medidas essenciais para proteger cada serviço contra falhas e inconsistências.
Quando separamos as interfaces externas (validação estrutural no serviço A) das interfaces internas (validação contextual no serviço B), criamos uma barreira natural contra efeitos colaterais. Isso permite que cada serviço evolua no seu próprio ritmo, sem se tornar dependente de como os outros validam ou processam os dados.
Mais do que evitar erros técnicos, a validação tem um papel estratégico: ela fortalece a confiança no sistema. Cada camada que valida os dados adiciona uma camada de segurança, reduzindo o risco de falhas catastróficas e garantindo que as regras de negócio sejam aplicadas com precisão.
No mundo dos microsserviços, a incerteza é inevitável – APIs mudam, formatos de dados evoluem e serviços podem falhar. Mas um sistema bem projetado não desmorona com cada mudança. Ele se adapta. E isso só acontece quando cada serviço assume a responsabilidade de validar e garantir a qualidade dos dados que consome.
Eu agradeço DE CORAÇÃO você ter lido até o final! Grande abraço! ❤️