
When Do Shared Libraries Complicate Microservices?
Shared libraries are like office printers: Everyone uses them, but no one wants to refill the paper.
In microservices architectures, as systems grow, a delicate issue arises: the sharing of libraries between microservices. At first glance, this may seem like a harmless or even efficient practice. After all, reusing code is considered a good practice. However, as we will see throughout this article, this approach can hide pitfalls that compromise the very independence and flexibility we strive for. 🙂
We will discuss how attempting to reuse libraries can lead to unintended coupling between services, making maintenance and evolution more difficult. Moreover, we’ll explore alternatives and best practices that can be adopted to minimize these risks and keep the architecture clean and agile.
Some of the key points we will explore include:
The problems of shared dependencies: How common libraries can affect the independence of services.
Library evolution: Versioning challenges and how changes can trigger a chain reaction.
Best practices and solutions: Viable alternatives to ensure that libraries are used intelligently without compromising the autonomy of microservices.
Let’s take this journey together to understand where we might be going wrong and how to prevent library sharing from turning our microservices into "micromonoliths." The goal here is to ensure that our systems maintain the agility, flexibility, and independence that make microservices such a strong approach.
Why do we package code into a library?
Let’s start with a simple question: why do we encapsulate code into a library in the first place? To answer this, we need to understand what a library is in the context of programming. But before diving into that, it’s worth exploring the original meaning of the word.
What is a code library?
The term "library" immediately brings to mind a place where books are stored—sources of knowledge organized for reference. Interestingly, the word library has its origin in the Latin word bibliothēca, which in turn comes from the Greek bibliothḗkē (βιβλιοθήκη), where biblion means “book” and thḗkē means “repository” or “storage place.” Literally, a library is a "place to store books."
However, in both physical libraries and code libraries, the purpose goes beyond mere storage. There is a process of organization, curation, and availability of knowledge so that it can be easily found, accessed, and reused.
In the world of software engineering, a code library serves a similar need: it centralizes and organizes technical knowledge—functions, classes, modules—that can be reused whenever needed. This eliminates the need to "write a new book"—or code — from scratch.
The Evolution of Code Libraries
As the complexity of systems grew, so did the need to reuse code to avoid duplicating efforts. Early in the history of programming, developers realized that they could group reusable blocks of code into libraries, much like a repository of books groups written knowledge. Just as a book library curates knowledge, code libraries curate tested and organized functionalities, saving time and standardizing solutions.
This way, essential tasks such as data validation, date manipulation, or mathematical calculations became concentrated in organized libraries. This brought a series of benefits: time savings in development, reduced errors (as these functions had already been validated), and consistency in solutions.
The Curation of Code Libraries
More than just a "repository" of code, code libraries require curation and maintenance. Just as a book library keeps its collections organized and updated, code libraries need to be well-structured, versioned, and carefully maintained so that they can be effectively reused without compromising system integrity. If poorly organized or neglected, they can become a problematic coupling point between systems, limiting developer flexibility.
This analogy with physical libraries helps us understand that a code library is much more than a set of ready-made functions—it is a repository of organized knowledge, allowing developers to reuse code efficiently and in a controlled manner. By encapsulating technical knowledge and reusable functionalities, a code library enables development teams to focus on the specifics of their projects without needing to reinvent the wheel.
Therefore, just as the word "library" has its roots in the concept of "storing books," a code library is a storage place for technical knowledge, organized in a way that it can be easily reused. However, its value lies not just in the storage itself but in how these functionalities are curated, maintained, and made available. Like book libraries, a good code library ensures that knowledge is accessible, well-organized, and ready to be used effectively.

What makes library sharing so attractive?
This concept has become incredibly appealing to software engineers. After all, in an ideal world, who wouldn’t want to build systems faster by reusing tested and reliable code? The practice of creating libraries began to solve one of the major dilemmas in programming: how to minimize code redundancy. Instead of copying and pasting the same function across different parts of a system, you could simply create a library to centralize this common logic and use it across multiple components. This not only eliminated code duplication but also made maintenance easier: when a function needed adjustments or fixes, you could just update the library, and voilà—all the parts using it would automatically be up to date.
This power of reuse makes library sharing seem like an efficient and safe practice to software engineers. Imagine you have a set of services that need to calculate taxes. Instead of writing and maintaining the same calculation logic in various places, you create a library that centralizes this logic. Now, any service needing that calculation can simply use the library without having to reinvent the wheel. This approach reduces development effort, increases consistency (since all services will use the same logic), and simplifies maintenance—modifying the library ensures the update is reflected wherever it is used.
However, this practice, while highly attractive in theory, brings with it a series of challenges and risks, especially when applied to microservice architectures. What initially seems like a solution for code reuse can gradually evolve into a problem. By encapsulating code into libraries and sharing them across different microservices, you run the risk of creating hidden dependencies between services. This excessive sharing can compromise the autonomy of microservices, which are meant to be independent. Thus, what begins as an elegant solution can result in coupling, impacting the system’s flexibility and scalability.
And this is where the issue of shared dependencies emerges, leading us to the next critical point that needs to be discussed...
The Problems of Shared Dependencies
Have you ever found yourself in a situation where everything seems to be going smoothly with your microservices architecture, until a small update to a shared library breaks something in production? Suddenly, what seemed like a simple change triggers a chain reaction of failures affecting multiple services, and what should have been an independent, modular architecture starts showing signs of unwanted dependencies. If this has ever happened to you—or if you know someone who has gone through it—then you’ve experienced firsthand the problems that sharing libraries can cause.
Unintended Coupling
Each service should be able to evolve autonomously, without directly depending on other services or components. However, when libraries are shared across multiple microservices, we are, in a way, establishing an invisible bridge between them. What initially seems beneficial can quickly turn into a major obstacle.
Imagine you have an authentication service that shares a token validation library with other services. The payment service, for example, also relies on this library to ensure that transactions are made only by authenticated users. Everything works well until one day someone makes a small change to the validation library—a code optimization, a security adjustment—and without realizing it, this change breaks the token validation logic in the payment service. What was meant to be a simple update in one service now causes widespread failure across the system.
This is the problem of unintended coupling. By sharing libraries between microservices, we create hidden dependencies. Even though the services are separated by domains, their behavior is linked through this common library. Any change, no matter how small, can have unexpected side effects on other services that rely on the same library.
Impact on Service Independence
When a library maintained by Team A is spread across the entire ecosystem and used by various services, that promised independence begins to unravel.
Suddenly, a small change made by Team A to this library can impact multiple services that depend on it. What was once a simple, autonomous change now becomes a complex operation, requiring other teams, whose services depend on the library, to coordinate carefully. Team A now has to synchronize their changes with other teams, and this adds a layer of bureaucracy and testing that directly impacts the autonomy promised by microservices.
Think about the impact this has on daily development. Every time a new version of the library is released, the teams that depend on it need to run integration tests on their own services, even if they haven’t made any changes to their application code. The result? The speed at which teams can iterate and deliver value to production begins to slow down. The development cycle, which should be agile and independent, is interrupted by the need to ensure that this update doesn’t break something somewhere in the ecosystem. And, despite all the testing, there is always the risk of something being overlooked, leading to a domino effect of issues in production.
Deployment Autonomy
If you’ve worked with microservices long enough, you’ve probably encountered a moment where, during the deployment of one service, you realized that another service—unexpectedly—also needed to be updated due to a shared dependency. This is one of the biggest nightmares of library sharing: the loss of deployment autonomy.
You want to fix a bug in the authentication service? No problem, just deploy the new version of that service, and the others continue to function as usual. But when a shared library is involved, this deployment cycle becomes complicated. Now, if the authentication service updates the library, the payment service, which also depends on it, may need to be redeployed—even though the payment service’s code hasn’t changed.
This creates a situation where microservices start to lose their autonomy. With each new update to the shared library, the question arises: "If we change this library, won’t we break the build for other services that depend on it?" And because the answer is not always clear, teams become more cautious, and the deployment processes become slower and more bureaucratic. What should be a fast and flexible architecture turns into a rigid and interdependent deployment cycle, where a change in one library can impact multiple services, forcing unexpected tests and adjustments.

The Dilemma of Sharing
When sharing libraries between services and applications, we face a classic dilemma: efficiency versus independence. On one hand, reusing code through shared libraries can seem like a sensible and productive practice. It saves time, avoids code duplication, and provides a standardized way to solve common problems. But as the system grows, these shared libraries can begin to act like chains that tie services together.
Have you ever had to delay a service deployment because of a dependency that was out of your control? Or maybe you encountered a critical bug that wasn’t in your service, but in a shared library, and you had to wait for another team to fix it before you could move forward? These situations are more common than they seem, and they force us to reflect: to what extent is sharing libraries between microservices truly advantageous?
These shared dependencies may be undermining the flexibility and agility that microservices promise to deliver. What started as an efficiency strategy gradually turns into a burden that must be constantly managed and balanced. And maintaining this balance, no matter how careful, is not always easy.
The Problem of Expanding Responsibilities
What began as a simple, straightforward solution—a small library encapsulating basic functionalities—starts to expand as new demands arise. Taking the example of an ecosystem like the Spring Framework, corporations often create their own libraries on top of native packages, such as the Feign Client. They encapsulate these libraries with internal customizations to meet the specific requirements of their domains.
At first, this encapsulation may seem like a good idea. It allows teams to develop functionalities quickly and consistently across all microservices. However, as new requirements emerge and domains become more specialized, this shared library starts to grow, carrying with it more responsibilities and business rules.
Every time a new feature is added, it can introduce new behaviors, patterns, or exceptions that inevitably begin to impact all the microservices that depend on it. What was once a simple abstraction for making HTTP calls, like Feign Client, may start to incorporate specific logic for retries, circuit breakers, custom authentication, and more. As a result, the library transforms from a simple utility tool into a central domain artifact, carrying complexities that impact the entire ecosystem.
Now, imagine you’re organizing a large conference, and all the presentations rely on a single projector. Each speaker has a different presentation, with their own needs and formats, but they all need to use the same equipment to display their ideas. Now, imagine the projector needs a small update to work better for some specific presentations. The team responsible for the projector decides to make adjustments to optimize performance, but as they do, a concern arises: “Will this adjustment affect the other presentations that still need the projector?”
Suddenly, what should have been a simple equipment tweak turns into a massive bureaucracy. Every speaker needs to test their presentation on the new projector before going on stage to ensure everything works perfectly. This creates delays, queues, and instead of the conference flowing smoothly, the pace slows down, with each speaker more worried about whether their presentation will function than about the content itself.
In the world of microservices, this conference is like a system of multiple teams and services that rely on a common library. The projector is the shared library, and each speaker is a different service. Every time the library is changed, all the teams that depend on it need to stop what they’re doing to ensure their applications still work with the new version. The result is a more bureaucratic development process, with more meetings, testing, and coordination than necessary—all because a small change in one central point has the potential to affect everything around it.
This centralized dependency compromises the independence of teams and slows down the entire microservices ecosystem, much like the single projector stalls the progress of the conference. And this is exactly what happens with a shared library that grows too much. It carries multiple responsibilities and starts dictating how microservices should function. Instead of fostering agility, it creates a dependency that hinders the rapid, autonomous evolution of each service.
What happens along the way? Bloat. The library starts to expand with features that aren’t necessary for all services but still have to be loaded, tested, and maintained. The more it grows, the more complex the maintenance and integration with various microservices becomes. The result is a library that, instead of simplifying, starts adding unnecessary complexity, becoming a true bottleneck.
The Focal Point of the Problem
The central issue here isn’t the growth of the library itself, but the fact that it is being used indiscriminately by services with different needs. By continuing to use a shared library that evolves and specializes, you are essentially forcing all services to carry the weight of a solution that doesn’t necessarily fit their realities. This creates a vicious cycle: the more specialized the services become, the more features need to be incorporated into the library, and the more it begins to impact all microservices, even those that don’t need the new functionalities.
This process slows down and bureaucratizes the evolution of microservices. Every change in the library requires a series of tests and validations in all the services that use it, even if the change was made to serve a single domain. The independence of the services starts to fade, and teams become stuck in an endless cycle of adjustments and validations.
Shared Models and Domain Libraries
Sam Newman, in his book Building Microservices (second edition), delves deeply into the dangers of coupling caused by sharing libraries between microservices. In one example he mentions, a company used a shared domain object library—models representing the core entities of the system—across multiple services. Initially, this seemed like an efficient way to ensure consistency between teams and accelerate development. However, as the services grew and new features were added, this strategy began to reveal its flaws.
The situation Newman describes involves a simple change to one of the shared models. When an additional field was included in an entity, all services using that library had to be updated. This not only led to a massive coordination effort between teams but also exposed the company to risks of bugs and inconsistencies. If even one service wasn’t updated correctly, it could result in communication failures and invalid data being processed.
This scenario clearly illustrates how coupling can directly impact team productivity. A simple field added to a domain library can force all consumers of that library to update their dependencies and thoroughly test the changes.
Imagine the situation: one team, while trying to release a new version of a service, discovers that they need to coordinate the deployment with five other teams using the same library. This introduces a layer of bureaucracy that slows down the process of delivering value—exactly the opposite of what microservices should promote. The ability to deploy independently, one of the pillars of this architecture, is put at risk, and team agility diminishes.
Moreover, the risk of human error intensifies. When a shared library must be updated across several services at once, small mistakes are more likely to occur. Maybe a field wasn’t mapped correctly, or some expected behavior wasn’t replicated in all services. These small errors might not be immediately detected but could cause significant issues later, in production, where invalid data or unexpected behaviors may arise.
Let’s consider a common example, inspired by Newman’s description. Suppose you have a shared model library that defines how a "Customer" entity should be represented in the system. This entity is used across several services, such as billing, customer registration, and credit analysis. When a new field, such as "contract renewal date," is added to the "Customer" entity, all these services must be updated to handle this new information. However, some services might not need this information immediately. Still, they must update their dependencies and go through a testing cycle to ensure nothing is broken.
This scenario is not just about additional effort. When you force all services to adopt a change simultaneously, you are reducing team flexibility and centralizing development decisions. The autonomy of teams—one of the biggest advantages of microservices—is lost because a change that should have been local (in one service) now affects the entire ecosystem.
Exploring the Perspective with the Help of Another Expert
Sam Newman argues that while code reuse is a common and seemingly efficient practice, it can easily turn into a coupling trap, compromising the main advantage of microservices: independence.
Newman cites a classic example of where code reuse can create problems: the serialization and deserialization of domain objects. When an organization decides to create a shared library to handle these tasks across multiple microservices, the initial goal may be to accelerate development and ensure consistency. However, what happens when a new field needs to be added to a domain entity? All microservices using that library must now be updated to include the new version. At this point, you lose the ability to deploy independently—one of the most important principles of a microservices architecture.
Here’s what he says:
"Code duplication has some obvious downsides. But I think these downsides are better than the downsides of using shared code that ends up coupling services."
This statement reflects Newman’s firm stance on code duplication. While duplication might be seen as "bad" in traditional development, he argues that in the context of microservices, duplication is an acceptable trade-off compared to the dangers of coupling introduced by shared libraries. Duplication allows each service to evolve independently, without the need to coordinate changes or updates with other services, preserving the architecture’s autonomy and flexibility.
Newman reinforces this view with another key phrase:
"Don’t violate DRY within a microservice, but feel free to violate DRY across microservices."
Here, Newman highlights a fundamental distinction: within a single microservice, DRY should be followed rigorously. This means that duplication of code or logic within an individual service should be avoided, as it can create unnecessary complexity, increase the risk of errors, and make maintenance more difficult. Inside a service, applying the traditional DRY principle makes perfect sense, as internal duplication compromises the clarity and cohesion of the code.
However, when it comes to different microservices, the perspective shifts. Newman argues that it is often better to allow code duplication between microservices, even though this may seem counterintuitive at first. Why? Because attempting to reuse code across services, usually through shared libraries, introduces coupling. And in a microservices architecture, where independence and autonomy are the foundation, coupling between services should be avoided at all costs.
DRY as Knowledge Duplication
It’s important to emphasize that the concept of DRY (Don’t Repeat Yourself) doesn’t just refer to code duplication, but rather to knowledge duplication. In the second edition of The Pragmatic Programmer, authors Andy Hunt and Dave Thomas, reinforce this idea by stating that DRY is about avoiding the duplication of intentions, business rules, and fundamental knowledge that could become scattered and make the system inconsistent.
Therefore, applying DRY goes beyond simply removing duplicate code. It involves the careful management of shared knowledge. This means that in the context of microservices, there’s no issue with duplicating code as long as the central knowledge governing business rules is clear and independently managed within each service. In fact, this approach might even be preferable to avoid the excessive dependency that shared libraries create.
This is a deep topic, and soon I’ll explore DRY as knowledge duplication in a dedicated article, where I’ll address how this principle has evolved beyond the simple idea of eliminating code repetition.
The Risk of DRY Among Microservices
When you try to share a library across multiple microservices to "save" on code, the lifecycle of all services becomes linked. As discussed earlier, any change in the library— whether a new feature or a bug fix— affects all services using it. This creates an unwanted dependency, making it much harder for each service to evolve autonomously.
On the other hand, duplicating code between microservices preserves that autonomy. Each service can evolve at its own pace and according to its needs, without relying on changes made to other services. Duplicating code, in this case, becomes a defensive strategy against excessive coupling. Although at first glance it may seem to go against good engineering practices, in distributed systems, this approach avoids the complexity of maintaining synchronized lifecycles across different services.
As Newman highlights, reusing code between microservices may seem efficient, but it often undermines the core benefits of the architecture—autonomy and agility. Keeping each service with its own set of code, even if it means duplication, allows them to evolve without needing to coordinate changes with other teams or services.
The Reality of Duplication in Distributed Systems
In monolithic systems, code duplication is indeed a serious problem. Imagine the same business logic scattered across different parts of a monolithic application. Any change to the logic would require multiple updates, duplicated tests, and the risk of inconsistencies would be enormous. However, in microservices, the paradigm is different.
Consider a company with a set of microservices handling different aspects of the business: authentication, billing, and notifications. All of these services might have duplicated logic for handling dates, for example. The traditional solution would be to encapsulate this logic in a shared library to avoid duplication. However, if a change is needed in how dates are handled, all microservices that depend on this library need to be updated, creating a dependency cycle that compromises team agility.
Instead, each microservice can maintain its own version of the logic. Yes, this increases duplicated code, but this duplication is insignificant compared to the cost of managing dependencies between services. Each microservice can update its own logic according to its specific needs, without worrying about the impact on other parts of the system.
Conscious Duplication: Autonomy with Control
This is where the idea of conscious duplication emerges: instead of avoiding duplication at all costs, you carefully evaluate the benefits of keeping services separate and duplicating specific parts of the code to ensure independence and isolation. This type of duplication allows teams to move faster and make changes without needing to coordinate with other parts of the application.
This doesn’t mean duplication should be done carelessly. It must be applied responsibly and sparingly. If the code in question is particularly stable and rarely changes, reuse may be valid. But if the code is subject to frequent changes, duplication may be the safest choice to ensure the autonomy of services.
The Cost of Reuse Versus the Benefit of Duplication
Therefore, when Sam Newman suggests that it’s acceptable to "violate DRY between microservices," he is encouraging us to adopt a more pragmatic view of distributed systems architecture. Code reuse is undoubtedly a valuable practice within a distributed ecosystem. However, when applied across microservices, the cost of coupling can easily outweigh the benefits.
The real question isn’t whether we should duplicate code, but how we can preserve the autonomy and flexibility of services. If duplication is the most efficient way to ensure that autonomy, then it should be considered a valid—and often essential—practice. In the end, the greatest advantage of microservices isn’t reducing duplicated code, but evolving independently, ensuring agility, scalability, and efficiency throughout the system.
Phew! So many topics and points to consider! I hope everything is clear, but if not, feel free to leave a comment and let’s discuss it further!
The Challenge of Library Synchronization
The problem becomes even more complex when work synchronization between different teams using the same library comes into play. Who is responsible for maintenance? Who should fix a bug or add a new feature? When multiple teams depend on a single library and it’s not clear who "owns" that resource, change management becomes a real organizational maze.
Without a clear ownership model, teams can face delays, miscommunications, and misaligned priorities when attempting to update the library. This lack of clarity can slow down the entire development process, as everyone waits for someone else to take responsibility.
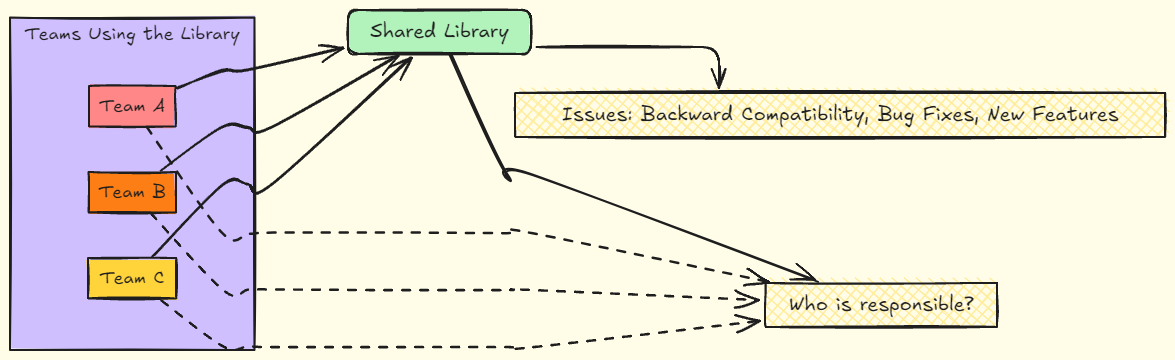
Imagine the following situation: a company has a shared library that handles logins, used by dozens of different microservices. This library was created a few years ago by a team that no longer works on the original project. Over time, new teams started using it, expanding its functionality in various ways to meet their needs. Now, a critical security bug has been found in the library and needs to be fixed urgently. But the question is: who is responsible for fixing it?
No engineering team feels like they "own" the library. Each team using the library has its own deadlines and priorities, and many developers aren’t even deeply familiar with the library’s code. The lack of clarity about responsibility makes the bug fix process much slower than it should be. Moreover, even if one team takes on the task of fixing the bug, other teams will need to test their services to ensure that the fix doesn’t introduce new issues, further increasing the complexity.
This scenario highlights the risks of shared libraries in distributed systems. Without clear ownership and proper management, a shared resource can become a bottleneck, slowing down the response to critical issues and complicating the coordination between teams.
As Sam Newman mentions in his book on microservices:
“Each update to the shared library requires multiple services to be tested and deployed together.”
This cycle of interdependence not only reduces the agility of the development process but also creates confusion. Programmers who have never worked directly with the library's code now need to interrupt their primary tasks, dive into unfamiliar code, and understand the entire historical context behind each modification. This directly impacts the efficiency of teams, who often find themselves working on something outside their area of expertise instead of focusing on their own deliverables.
The Issue of Responsibility and Knowledge Fragmentation
The problem intensifies in larger companies, where different teams use the library for various purposes, and often these teams don’t communicate directly. The lack of a clear "owner" of the library leads to knowledge fragmentation. The team that originally created the library may have shifted priorities to other projects, while new teams that started using it often have different visions for how it should evolve.
This ownership vacuum means that when an issue arises, a significant effort is required to align different teams. Who will be responsible for analyzing the bug? Who sets the criteria for the solution? Which team will have the final say on the necessary changes? This type of coordination can significantly delay the resolution of critical issues and compromise delivery deadlines.
Now, imagine that the security bug needs to be fixed within a week. But because several teams use the library in different ways, the impact of the fix varies. One team may be ready to adopt the new version immediately, while another is in the middle of an important development cycle and cannot risk an update at that moment. The complexity of aligning all these realities turns a simple fix into a highly bureaucratic process, where every change must pass through multiple layers of approval and testing. The result? Slower deployments, greater complexity, and the loss of the agility that microservices are supposed to provide.
As Newman observes, one of the biggest pitfalls of shared library reuse in microservices is that it creates indirect coupling between services that should otherwise be independent. This shared dependency causes teams to lose precious time in coordination, testing, and joint validations.
The Impact on Deadlines
Now imagine a team two weeks away from a critical delivery to a client. During the development cycle, they discover they need to add a new feature to the shared library that handles performance reports. This library is already used by other teams who are also at critical points in their projects. The team decides to add the feature, but soon realizes the change introduced an unexpected side effect for another service that uses the library differently. Now, in addition to solving the problem in their own code, they must notify other teams, adjust the library so it doesn’t break other services, and—worse—wait for feedback and validation from those teams.
This creates a domino effect: the deadline that once seemed feasible is now at risk because the team is caught in a cycle of fixing problems that weren’t originally theirs. Other services need to be tested and, in some cases, reworked. The scope of the work expands uncontrollably, and the team ends up spending precious time on something that, ideally, should have been an isolated change.
This lack of clarity about who is ultimately responsible for the library and its necessary modifications leads to significant delays. Instead of delivering new features quickly, as expected in a microservices environment, the team finds itself immersed in integration processes and checks with other teams, resulting in slower and less efficient deliveries.
Strategies to Mitigate the Responsibility Problem
One way to mitigate this issue is to clearly define the ownership of the library from the start. This can be done by assigning a specific team as the "owner" of the library. This team would be responsible for its maintenance, bug fixes, and feature additions. This makes the update process smoother, as there’s a team that fully understands the structure and can ensure that changes are made safely.
Another recommended strategy is to create clear versioning contracts for libraries. Instead of requiring all services to update immediately, it can allow multiple versions of the library to coexist, with a clear lifecycle for each version. Teams wishing to make a more aggressive update can adopt the latest version, while others can remain on a stable version until they’re ready to transition.
Sam Newman also suggests considering the use of dedicated microservices to handle features that would otherwise be centralized in shared libraries. This approach reduces the impact of changes since the dedicated microservice can be updated independently, without requiring all consumers to synchronize their lifecycles.
Strategies to Handle Library Evolution Without Compromising Microservice Autonomy
As discussed, the growth of a shared library can be a challenge, especially when it expands to meet the needs of multiple microservices, each with different domains and requirements. Now, it’s time to explore strategies to manage this evolution without compromising the agility and independence of each microservice.
Semantic Versioning
One of the first strategies to prevent a shared library from becoming a bottleneck is to adopt rigorous semantic versioning. By properly versioning the library, it’s possible to separate non-breaking updates (minor updates and patches) from breaking changes (major versions). This allows different microservices to use different versions of the same library without compromising the system’s overall stability.
With well-implemented semantic versioning, you can ensure that critical services continue using a stable, tested version of the library, while other services with more flexibility for innovation can migrate to newer versions. This prevents disruptive changes from causing side effects in services that aren’t ready to adopt updates.
Domain-Specific Library Segregation
As microservices become specialists in their respective domains, an effective approach is to segregate libraries. Instead of continuing to inflate a single shared library with rules and logic from multiple domains, consider creating smaller, domain-specific libraries. This keeps the library lean and focused on a specific set of responsibilities.
By adopting these strategies, teams can maintain the independence and agility that microservices promise, avoiding the pitfalls of hidden coupling through shared libraries.

For example, if a library initially encapsulated HTTP calls, but now includes authentication logic, caching, and failure handling, it's time to split them into different libraries. This way, each microservice only loads the dependencies it actually needs. This separation ensures that teams can evolve the libraries more efficiently without carrying functionalities they don’t use.
By segregating these concerns, teams can maintain cleaner, more modular libraries, allowing each service to only depend on the necessary parts. This approach not only reduces bloat but also helps maintain independence between services, enabling faster development and reducing unnecessary coupling.
Customization and Extension via Composition
Another key strategy to avoid excessive coupling is ensuring that libraries are flexible and extensible through composition, rather than forcing a single centralized implementation. This means that instead of embedding specific logics directly into a shared library (like Feign Client), each microservice can compose its own functionalities on top of that base, according to its individual needs.
For instance, Feign Client can still serve as the foundation for HTTP communication. However, instead of embedding features like automatic retries and authentication directly within the shared library, each microservice can implement these strategies independently. This allows the core library to remain generic—handling only basic HTTP communication—while each service defines its own mechanisms for retries, authentication, or any other logic specific to that service.
Interestingly, this approach is deeply aligned with solid software design principles such as the Open/Closed Principle and the Separation of Concerns. According to the Open/Closed Principle, a library should be open for extension but closed for direct modification. In other words, the core library handles the common and generic part, while the microservices have the freedom to extend its functionality according to their specific needs, without having to modify the core code of the library. This ensures flexibility, avoids the creation of hard dependencies and promotes long-term maintainability.
Using Adapters to Handle Differences
Adapters are an excellent strategy for allowing different services to use the same shared library while maintaining customized and specific behaviors. Instead of requiring the central library to meet all the needs of every service, you can create an adapter layer to adjust the functionalities based on the specific context of each microservice.
For example, imagine two microservices that both use the same HTTP communication library to handle network failures and perform retries:
Payment Service: In this case, the retry logic may be more conservative. Perhaps the payment service only needs two retry attempts with a one-second interval between them, as frequent failures could signal a critical issue. Additionally, it may be programmed to give up quickly if repeated failures occur to avoid compromising the customer experience or creating duplicate transactions.
Authentication Service: On the other hand, an authentication service might be more tolerant of failures and perform up to five retry attempts with a 500-millisecond interval between them. Since authentication is critical for the continuous operation of other services, it may be configured to persist longer before giving up on establishing communication.
By using adapters, you keep the HTTP communication library generic, without overloading it with specific retry rules. Each service (payment and authentication) can define its own retry logic via an adapter, without directly modifying the central library. This ensures that the library remains simple and focused on its core functionality—handling HTTP communication—while service-specific logic, like retry count and intervals, is managed in the adaptation layer.
Once again, this practice reinforces the principles of Separation of Concerns and the Open/Closed Principle, as it adapts the behavior of the system without directly modifying the library. Adapters allow each microservice to implement its own particularities without creating rigid dependencies or forcing continuous updates to the shared library.

This way, you avoid the library becoming bloated with functionality that not all services need. The simplicity of the library is preserved, while services have the freedom to extend its behavior according to their own needs.
Isolation of Sensitive Features
When dealing with libraries that involve complex or sensitive logic (such as security, authentication, or data handling), a recommended approach is to isolate these features into independent components:
Isolation into specialized microservices: Instead of sharing a security library across all services, create a dedicated microservice that centralizes authentication or encryption logic. This way, microservices can delegate these responsibilities in a secure and isolated manner, avoiding functionality breakdowns in case a change is necessary.
Independent components: Avoid creating massive libraries for sensitive functionalities. Isolating these features ensures that changes are restricted to a single component, preventing updates in critical parts of the library from affecting other services.
This practice enhances system resilience, ensuring that failures in one specific service do not propagate to others that rely on the same functionality.
Standardizing Conventions and Interfaces
One of the biggest challenges in shared libraries is ensuring that all teams use them consistently. Establishing clear standards and best practices can help mitigate the risks of inconsistent use:
Standardized development conventions: Define usage conventions, such as naming patterns, API contracts, and error-handling methods. These practices standardize expected behavior and help create consensus among teams, avoiding conflicts or misunderstandings.
Consistent interfaces: Use consistent and predictable interfaces for interacting with the library. This simplifies integration and reduces the need for deep knowledge of the library by all developers who use it.
Standardizing how libraries are consumed reduces the risk of miscommunication or misuse, minimizing coupling and the need for future corrections.
Use of Independent Packages with Well-Defined Features
When sharing common functionalities is necessary, a best practice is to split the library into independent packages instead of creating a single monolithic package containing everything:
Decoupled packages: Instead of creating a gigantic library that does everything, split functionalities into small, cohesive packages (e.g., one package for validation, another for authentication, etc.). This way, microservices only need to use the package they truly require, helping maintain isolation.
Well-defined functionalities: Each package should be limited to a single responsibility, minimizing the impact of changes and allowing different services to use different versions of related packages.
This modular approach makes it easier to maintain and update individual parts without affecting the rest of the codebase.
Limiting the Frequency of Library Updates
If a library is evolving constantly, it can force services to keep up with the updates, causing frequent disruptions. To avoid this:
Plan controlled release cycles: Instead of releasing updates ad hoc, create controlled and predictable release cycles. This allows teams to plan their own updates and testing around a clear schedule.
Avoid trivial constant changes: Reduce minor and trivial updates that don’t bring real value. Group improvements and fixes into significant releases to reduce the number of forced deployments.
Controlling the frequency of changes keeps the system more stable and reduces pressure on the consuming services.
The Right Questions to Ask
It’s important for teams to periodically revisit the use of these libraries, asking some essential questions that can reveal whether the library still makes sense or is causing more problems than it solves. Here are some questions to guide this analysis:
Does the Library Encapsulate Useful Features?
How many microservices actually need this library?
One of the first questions to ask is how widely the library is being used. If a library was created to be shared, is it really being used by multiple services or just a limited few? If only one or two services are using it, does it make sense to keep it as a central dependency?
Does it encapsulate behaviors or functionalities that are stable?
Libraries useful for multiple microservices typically encapsulate behaviors that don’t change frequently, such as security validations or HTTP response formats. If the behavior encapsulated is something rarely changed, the library could be a good solution. But if the functionality is always changing, it could be becoming a friction point.
Are we saving time or creating more dependencies?
The goal of a shared library should be to simplify and speed up development, but it’s important to ask: are we really saving time, or are we just creating a coupling point? If every time there’s a change in the library, multiple teams need to pause their work to align their versions and run tests, the effort may not be worth the code reuse.
Are the Functionalities General Enough or Becoming Specialized?
Is the library encapsulating behaviors that are truly useful to multiple services?
If the library is starting to include logic or behaviors very specific to one domain or microservice, it may be time to stop and reflect. When a library starts to incorporate domain-specific business logic, it’s a sign it’s becoming too specialized, increasing the risk of coupling.
When the Library Becomes Too Complex
As the library evolves, it may become too complex and start incorporating responsibilities it shouldn’t have. At this point, it’s essential to question its purpose and utility as a central dependency. Here are some questions teams should ask:
Are we starting to add too much specific business logic?
One of the biggest signs that a library is becoming too complex is when it starts to contain business logic that should be the responsibility of individual services. If the library is incorporating rules that only make sense for a small group of microservices, it may be straying from its original purpose of providing generic functionality.
How often are we having to modify the library?
If the library is being modified frequently, especially to accommodate new behaviors specific to some services, this is a strong indicator that it’s becoming a bottleneck. A good shared library should be stable and rarely need changes. When updates are constant, they generate a cycle of interdependent deployments and increase the risk of errors.
Can we still deploy independently?
The most important question to ask is whether the microservices using the library can still deploy independently. If each change to the library requires multiple services to be updated simultaneously, or if several teams need to go through a cycle of testing and adjustments, the library may be compromising one of the fundamental principles of microservices: the ability to evolve independently.
Is the library becoming difficult to understand?
A clear sign that a library is becoming too complex is when developers have difficulty understanding how it works. If the library started simple but now requires several layers of configuration or modifications to adapt to different services, it may be overloaded. When shared code becomes hard to comprehend, the chance of errors increases, and teams lose confidence in using it.
Would code duplication be simpler in this case?
Finally, a question that many teams don’t ask but should: would it be easier to duplicate the code rather than continue sharing the library? Maybe, the answer is yes. Instead of continuing to inflate a library that tries to serve multiple services, duplicating the code can return autonomy to the teams and avoid the coupling that hampers flexibility and agility.
Finding the Balance
These questions can help the team identify when a shared library is still useful and when it has become an obstacle to the evolution of the services. The key is finding the balance between reuse and independence. Sharing libraries can be a powerful solution, but it must be handled with care. If the library starts carrying too many responsibilities or hindering deployments, it may be time to rethink its use and adopt a lighter approach, such as code duplication across services.
For example, if we're dealing with configuration libraries for technologies like RabbitMQ or Kafka, where all microservices use the same settings and don’t have particular requirements, it makes sense to share these libraries, as it avoids duplication of configurations. The same can be said for audit, logging, or error handling libraries, where the logic is generic and doesn’t need to be customized for each service.
If a library that centralizes authorization rules, calculations, or other centralized rules that could belong to a specific domain (service), for example, ends up affecting a microservice’s response time or operation due to an internal failure, it can cause more problems than solutions.
When these critical functionalities are centralized in a shared library, microservices become dependent on its proper functioning. This means that if the library experiences a failure or instability, multiple services can be impacted simultaneously, resulting in cascading interruptions. Moreover, by centralizing business logic in a single library, any change or fix needs to be rigorously tested to ensure it doesn't break other services relying on that library. This can delay the deployment of new features and reduce the agility of the teams.
Therefore, it is important to carefully evaluate which functionalities make sense to be in a shared library and which should be implemented directly in each microservice. Features like simple data manipulation or formatting are good candidates for centralization, while specific business rules or functionalities that directly affect a service's performance and security should, whenever possible, be isolated within the service itself.
This separation of responsibilities ensures that microservices maintain their autonomy, can scale independently, and are not vulnerable to failures in a single centralized library.
By asking these questions and reflecting on the answers, teams can make more informed decisions about how to manage their libraries and avoid the unwanted coupling that often creeps in without being noticed. The goal is always to maintain balance: ensuring that reuse makes sense without compromising the agility and autonomy of the services.