
O Efeito Pombo-Correio: O Perigo do Acoplamento de Passagem em Microserviços
A chave para uma arquitetura de microserviços eficaz é o isolamento — não apenas de dados, mas de mudanças. - James Lewis

Microserviços não são uma bala de prata. Eles prometem escalabilidade, flexibilidade e desacoplamento, mas trazem consigo uma série de desafios que só ficam evidentes quando você começa a implementá-los no mundo real.
Hoje vamos falar sobre um desses desafios que parece inofensivo à primeira vista, mas pode se tornar uma dor de cabeça à medida que o sistema cresce: o acoplamento de passagem. Neste artigo, vamos explorar como esse acoplamento surge, por que ele é problemático e, mais importante, como evitá-lo. Se você já passou horas lutando com dependências entre serviços ou viu pequenos ajustes se transformarem em “rollouts” gigantescos, este texto é para você. Afinal, no mundo dos microserviços, a diferença entre sucesso e frustração está nos detalhes.
O que é o acoplamento de passagem, afinal?
Sam Newman, em seu icônico livro Building Microservices, descreve esse tipo de acoplamento com clareza e profundidade. De forma objetiva, o acoplamento de passagem ocorre quando um microserviço (digamos, o Serviço A) envia dados para outro microserviço (Serviço B), mas esses dados não são realmente utilizados pelo Serviço B. Em vez disso, o Serviço B funciona apenas como um “mensageiro”, repassando as informações para um terceiro microserviço (Serviço C), que será o verdadeiro consumidor dessas informações.
O problema é que essa prática pode parecer inofensiva no início, mas logo se transforma em um entrave significativo. Por quê? Porque ela cria uma dependência desnecessária entre o Serviço A e o Serviço C, passando por B. A partir do momento em que algo no Serviço C precisa mudar — como o formato ou os dados esperados —, tanto A quanto B precisarão ser ajustados, mesmo que B não tenha nenhum interesse real nos dados que estão sendo transmitidos.
Pra tentar ilustrar, tente imaginar um pombo-correio encarregado de transportar uma mensagem de um remetente para um destinatário. O detalhe? O pombo não sabe o que está carregando, nem entende o significado ou o valor da mensagem — ele apenas leva o envelope de um ponto A para um ponto B. Mas, agora imagine que, durante a entrega, o destinatário decide mudar o formato da mensagem — de uma carta para um pacote. O que acontece? De repente, o pombo, que deveria ser apenas um mensageiro neutro, precisa ser adaptado para carregar o pacote. E, se houver outros pombos intermediários na jornada, todos eles precisarão ser ajustados também, mesmo sem interagir diretamente com a mensagem. Isso gera uma cadeia frágil de dependências desnecessárias.

É exatamente isso que acontece em sistemas com acoplamento de passagem. Serviços que deveriam ser independentes acabam sendo transformados em “pombos-correio”, intermediários que carregam dados sem compreendê-los, criando uma cadeia de dependências frágeis e difíceis de gerenciar. Sobre isso leia a nota, coloquei algumas observações interessantes para conversar.1
Mas por que isso acontece? Por que arquiteturas corporativas, mesmo projetadas por equipes experientes, acabam acumulando esse tipo de acoplamento? Vamos refletir sobre alguns aspectos. 👇🏼
O peso do pragmatismo corporativo
Muitas vezes, na busca por um Time to Market agressivo, tomamos atalhos. Um novo serviço precisa de dados? É mais rápido conectar diretamente ao intermediário mais próximo e passar tudo para frente. Esse pragmatismo funciona no curto prazo, mas cada conexão “rápida” adiciona uma nova camada de dependência e vulnerabilidade. Quantos sistemas corporativos nascem de decisões como “vamos só fazer funcionar agora e pensar em otimizar depois”?
Ao projetar sistemas, há uma tentação constante de simplificar as responsabilidades dos serviços intermediários. Faz sentido, certo? Se o intermediário apenas encaminha os dados, ele parece “simples”. Mas na prática, ele se torna um ponto crítico na arquitetura, responsável por satisfazer as necessidades de serviços que estão além de sua função principal. O que deveria ser um design simples acaba sendo o oposto.
Falta de visão de longo prazo
No calor do desenvolvimento, é comum perdermos de vista a evolução futura do sistema. Pergunte-se: quantas vezes você, como desenvolvedor ou arquiteto, pensou em como pequenas mudanças em um serviço podem impactar toda a cadeia de comunicação? Sistemas que funcionam bem no início frequentemente se tornam um pesadelo conforme crescem, porque ninguém considerou como o acoplamento de passagem ampliaria a complexidade.
A pressão por integração rápida
Em grandes organizações, diferentes times muitas vezes trabalham de forma independente, criando serviços isolados que precisam se comunicar para entregar valor ao cliente. A pressão por integração leva a soluções rápidas e frágeis, onde serviços intermediários são usados como “ponte” sem que haja uma reflexão mais profunda sobre o impacto dessa dependência.
Agora, pare e pense:
• Quantos dos seus serviços são pombos-correio, carregando dados que eles próprios nunca utilizam?
• Será que os atalhos que você tomou para acelerar a entrega não estão cobrando seu preço agora?
• E se cada pequeno ajuste em um serviço parecer causar uma avalanche de mudanças em outros, será que sua arquitetura está realmente preparada para evoluir?
Essas são questões que muitos arquitetos e programadores enfrentam diariamente, e o acoplamento de passagem é um lembrete de como decisões aparentemente inofensivas podem se transformar em grandes desafios estruturais.
O acoplamento em sistemas distribuídos nem sempre é óbvio, mas, quando se manifesta, geralmente é doloroso. - Sam Newman
Mas vamos continuar essa conversa. Há muito mais para explorar sobre como essas escolhas impactam nossas arquiteturas, e o que isso nos ensina sobre a construção de sistemas resilientes. Vamos dar um passo adiante e explorar como o acoplamento de passagem afeta um dos aspectos mais críticos na arquitetura de microserviços: os contratos entre APIs. Afinal, a verdadeira essência de uma arquitetura de microserviços bem-sucedida está na forma como seus serviços se comunicam — e é aí que o acoplamento de passagem começa a mostrar seus dentes.
Contratos de API: Quando o intermediário vira um refém
Se você já trabalhou com contratos entre APIs, sabe o quanto eles podem ser sensíveis. No cenário de um acoplamento de passagem, aquele “pombo-correio” que discutimos antes — não é apenas um simples carregador de dados, mas acaba se tornando um ponto crítico na cadeia de dependências.
Por quê? Porque ele precisa lidar com contratos que não pertencem a ele. Quando o serviço C (o destinatário final dos dados) altera sua API, o serviço B (o intermediário) precisa atualizar como passa as informações, mesmo que ele não utilize esses dados diretamente. Para piorar, o serviço A (o originador dos dados) também pode precisar ser ajustado para fornecer informações no novo formato exigido por C. E assim começa o efeito dominó: um pequeno ajuste no contrato de API de um serviço downstream2 reverbera por toda a cadeia, exigindo mudanças em serviços que nunca deveriam estar envolvidos.
O motivo pelo qual um serviço intermediário frequentemente carrega contratos de ambos os lados (upstream e downstream) está na sua posição na cadeia de comunicação. Por ser um ponto de passagem, ele é responsável por receber dados do serviço upstream (quem envia) e transmiti-los para o downstream (quem consome). Para fazer isso, ele precisa conhecer e respeitar os contratos de ambos.
Por que isso acontece?
1. Dependência para interpretar os dados recebidos:
O intermediário precisa entender o formato, os campos e as regras definidas pelo serviço upstream. Mesmo que ele não processe ou use diretamente essas informações, ele precisa garantir que os dados estejam no formato correto antes de repassá-los.
2. Responsabilidade de adequação ao downstream:
Ao passar os dados para o serviço downstream, o intermediário precisa garantir que o contrato do downstream seja respeitado. Se o serviço que consome dados espera um campo específico ou um formato exato, o intermediário precisa assegurar que está transmitindo algo que será aceito.
3. Falta de encapsulamento de lógica:
Quando o intermediário não encapsula a lógica de interpretação ou transformação dos dados, ele simplesmente replica os contratos upstream e downstream, tornando-se um ponto frágil no sistema. Isso faz com que ele dependa diretamente das definições de ambos os lados, sem autonomia para lidar com mudanças.
Agora, imagine isso em uma arquitetura com dezenas — ou centenas — de microserviços. Cada mudança de contrato se transforma em uma operação cirúrgica e sincronizada, onde cada serviço dependente precisa ser ajustado no momento certo. Parece exaustivo? É porque realmente é.
Rollouts: Quando planejar vira um desafio
Um rollout é o processo de colocar uma nova funcionalidade ou atualização em produção, buscando minimizar riscos e garantir uma transição suave. Em sistemas bem projetados, isso deve acontecer com flexibilidade e sem grandes interrupções. No entanto, quando há acoplamento de passagem, esse ideal se torna difícil de alcançar.
O problema começa com as dependências invisíveis. Um intermediário que deveria ser neutro acaba carregando mudanças upstream e downstream, exigindo atualizações sincronizadas entre múltiplos serviços. Isso leva a deploys em cadeia, onde qualquer alteração no serviço final (C) exige ajustes no intermediário (B) e no serviço inicial (A).
Se isso já soa complicado, imagine o cenário em grandes empresas: equipes diferentes, prazos distintos e prioridades conflitantes tornam a sincronização quase impossível. O que deveria ser uma simples mudança se transforma em um projeto gigantesco, com reuniões intermináveis e altos riscos de falhas.
Com acoplamento de passagem, rollouts deixam de ser um processo ágil para virar uma coreografia delicada e exaustiva.
O impacto direto do acoplamento de passagem
O maior problema aqui é que o acoplamento de passagem rouba a autonomia dos serviços. Em vez de evoluírem de forma independente, os serviços ficam presos em uma teia de dependências que exigem esforços coordenados. O objetivo de um rollout — realizar mudanças controladas e sem interrupções — é atropelado pela necessidade de alinhar contratos de API, sincronizar serviços intermediários e gerenciar a comunicação entre equipes.
A consequência? O time perde a agilidade para entregar valor rapidamente, os prazos ficam mais longos e os custos de desenvolvimento disparam. Em vez de focar na inovação, as equipes gastam energia tentando gerenciar um sistema que, ironicamente, deveria facilitar a escalabilidade e a independência.
O preço da complexidade
E aqui mais um custo do acoplamento de passagem: ele transforma mudanças simples em tarefas complexas. Cada contrato de API se torna um ponto de fragilidade, e cada rollout se torna uma dança cuidadosamente coreografada onde qualquer passo em falso pode quebrar toda a integração.
Vamos falar sobre contratos de API. Eles são, essencialmente, a “promessa” que um serviço faz para outro sobre como os dados serão trocados. Um contrato estável é a base para garantir que mudanças possam ser feitas sem quebrar a comunicação entre os serviços. No entanto, em sistemas com acoplamento de passagem, essa estabilidade é frequentemente comprometida. Por quê? Porque o intermediário carrega contratos que não pertencem a ele, mas que ele precisa transmitir, mesmo sem entendê-los completamente.
O impacto de um contrato instável
Um contrato instável é como uma ponte frágil: qualquer mudança pode causar um efeito cascata em toda a cadeia de microserviços. Uma simples alteração no downstream exige atualizações no intermediário e, muitas vezes, no upstream, transformando o que deveria ser um ajuste pequeno em um grande esforço de sincronização.
Esse cenário leva a desalinhamento de equipes, que precisam ajustar prioridades mesmo para mudanças que não as afetam diretamente, além de aumentar o risco de regressões, já que a cadeia inteira precisa ser testada. Como resultado, prazos desmoronam, com atrasos que podem transformar semanas em meses devido à necessidade de coordenação entre todos os serviços envolvidos.
O dilema da interdependência
E, sejamos sinceros, esse tipo de dependência é tudo o que uma boa arquitetura de microserviços deveria evitar. Microserviços deveriam permitir autonomia, facilitar mudanças independentes e promover o desacoplamento. Mas com o acoplamento de passagem e contratos instáveis, você acaba construindo uma teia de interdependências que amarra os serviços, dificultando não só a evolução do sistema, mas também o cumprimento de prazos estratégicos.
O verdadeiro preço dessa complexidade não é apenas técnico; ele é organizacional. Equipes frustradas, cronogramas irrealistas e objetivos adiados são apenas alguns dos sintomas de uma arquitetura que, no lugar de impulsionar a entrega de valor, se torna um obstáculo para ela. E isso nos leva a refletir: será que estamos realmente construindo sistemas escaláveis, ou apenas acumulando problemas que vão cobrar um preço alto no futuro?
A Ilusão de um Design Inteligente
Vamos conversar sobre um problema que pode facilmente passar despercebido: como microserviços de passagem podem parecer boas abstrações, mas na verdade acabam introduzindo o camadas de alto acoplamento. Esse equívoco acontece quando arquitetos e programadores confundem um serviço intermediário “genérico” com uma abstração verdadeiramente útil e coesa. O resultado? Um sistema que parece elegante na teoria, mas se torna um pesadelo para evoluir e gerenciar na prática.
Um sistema de vouchers
Imagine que você está projetando um sistema de e-commerce que oferece descontos para clientes através de vouchers. Para isso, temos três microserviços principais:
1. Serviço de Pedido: Responsável por processar os pedidos e aplicar descontos.
2. Serviço de Vouchers: Gerencia os códigos de voucher e verifica sua validade.
3. Serviço de Relatórios: Registra o uso de vouchers para fins de análise.
A arquitetura inicial é assim: o Serviço de Pedido chama o Serviço de Vouchers para validar um código de desconto. Se o voucher for válido, ele é aplicado ao pedido. Em seguida, o Serviço de Pedido passa os dados do voucher (como código e valor) para o Serviço de Relatórios, que registra o uso para análises futuras. Tudo parece funcionar bem até aqui, certo? Mas, como em muitos sistemas, você decide otimizar. Aqui começa a armadilha.
O “microserviço inteligente” que vira acoplamento de passagem
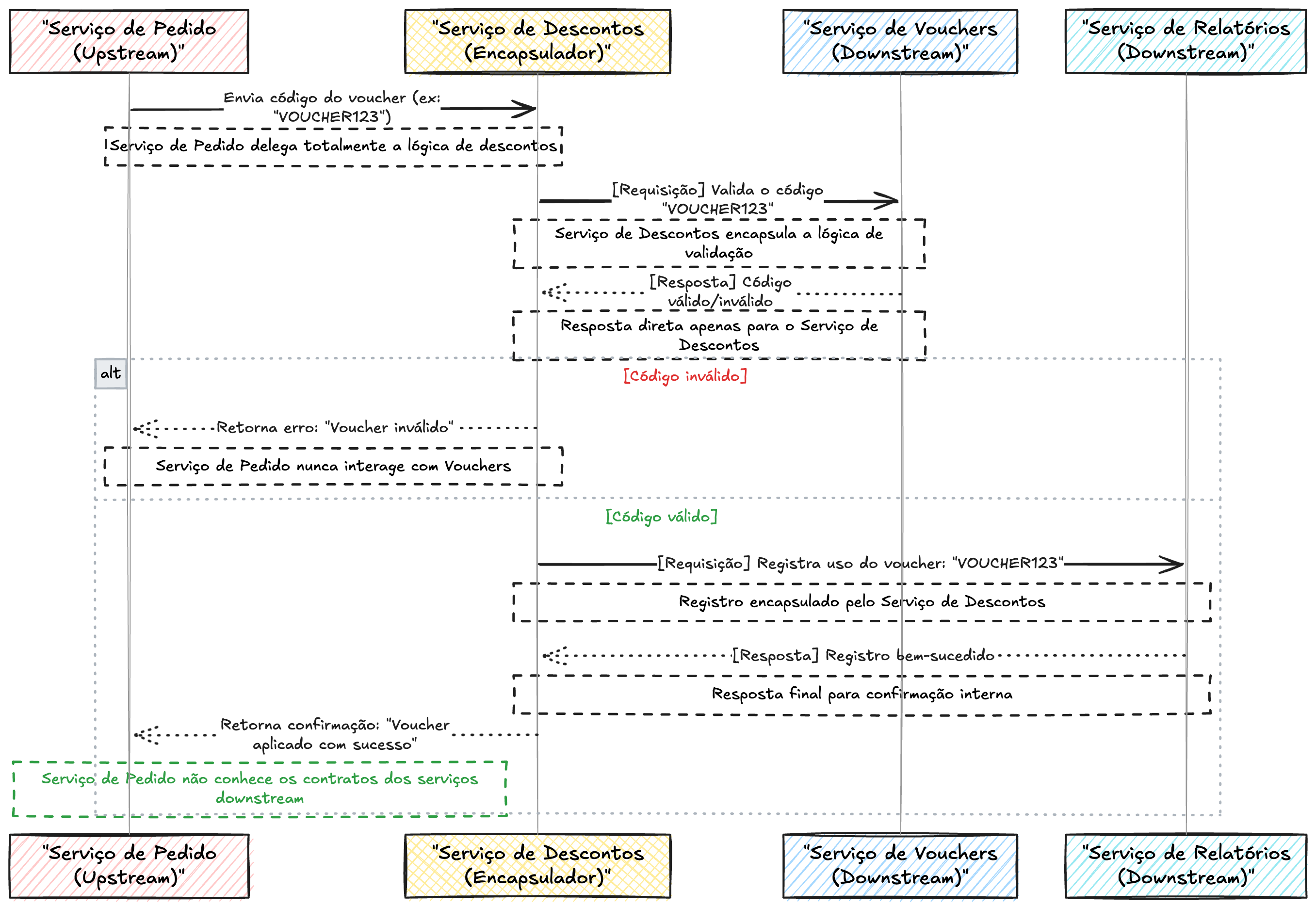
Imagine que alguém sugere criar um microserviço intermediário chamado Serviço de Descontos, que atuaria como uma “abstração inteligente”. A ideia inicial era que esse serviço centralizasse a lógica de validação e registro, unificando as interações entre o Serviço de Pedido e os serviços downstream (Vouchers e Relatórios). Mas na prática, o fluxo funciona de maneira diferente.
1. O Serviço de Pedido chama o Serviço de Descontos, enviando o código do voucher.
2. O Serviço de Descontos verifica a validade do voucher chamando o Serviço de Vouchers.
3. Após obter a resposta do Serviço de Vouchers (se o código é válido ou inválido), o Serviço de Descontos simplesmente devolve a resposta ao Serviço de Pedido, sem tomar nenhuma decisão ou executar qualquer ação adicional.
4. O Serviço de Pedido, com base na resposta recebida, decide como agir:
• Se o código for inválido, ele trata o erro.
• Se o código for válido, o Serviço de Pedido registra diretamente o uso do voucher no Serviço de Relatórios.
Parece uma boa ideia no papel, certo? Afinal, criar um ponto central para gerenciar descontos soa como uma boa prática arquitetural. Mas aqui está o problema: o Serviço de Descontos não agrega lógica própria ou valor real. Ele é apenas um pass-through coupling, um intermediário que repassa dados e delega toda a responsabilidade real para os serviços downstream (Vouchers e Relatórios).
Por que isso é um problema?
Embora o Serviço de Descontos pareça ser uma abstração útil, na prática ele introduz um acoplamento de passagem que cria mais problemas do que resolve. Eis os principais motivos:
1. Dependência indireta nos contratos
O Serviço de Descontos não encapsula verdadeiramente os contratos dos downstreams.3 Ele simplesmente repassa as requisições para os serviços downstream (Vouchers e Relatórios) e devolve as respostas ao Serviço de Pedido. Isso cria uma cadeia invisível de dependências.
• O resultado é que três serviços estão acoplados por essa cadeia: Pedido, Descontos e Vouchers. O que deveria ser uma abstração para simplificar o sistema na verdade o torna mais frágil e complexo.
2. O intermediário não agrega valor
O Serviço de Descontos não executa nenhuma lógica útil. Ele:
• Não interpreta respostas.
• Não encapsula detalhes dos serviços downstream.
• Não reduz a complexidade no Serviço de Pedido.
Ele funciona apenas como um canal que repassa mensagens entre os serviços. Essa “abstração” não faz nada além de adicionar um passo extra desnecessário ao fluxo, tornando o sistema mais complicado sem oferecer nenhum benefício real.

A ideia de criar abstrações genéricas é atraente. Em teoria, parece que estamos encapsulando a lógica e reduzindo dependências. Mas, quando um microserviço não processa, transforma ou interpreta os dados que repassa, ele não está agregando valor — ele está apenas transferindo responsabilidades.4
Como isso acontece?
• Confusão entre centralização e abstração: Arquitetos podem acreditar que centralizar a comunicação entre serviços é sempre uma boa prática. Mas, se o intermediário não adiciona lógica real, ele é apenas um ponto extra de fragilidade.
• Evitar duplicação a qualquer custo: Muitas vezes, o Serviço de Descontos é criado para “evitar duplicação” de chamadas aos outros serviços. No entanto, essa centralização acaba adicionando mais camadas e aumentando o acoplamento.
• Pressão por organização: Em sistemas grandes, a pressão para “organizar” as dependências pode levar à criação de serviços que apenas mascaram a complexidade, sem resolvê-la.
Agora, pense comigo:
• Quantos serviços em sua arquitetura atualmente apenas “passam dados adiante” sem fazer nada com eles?
• Será que essas “abstrações” são realmente úteis ou apenas criam um acoplamento desnecessário?
• E mais importante: como você garantiria que cada serviço em sua arquitetura tenha um propósito claro e significativo?
Essa reflexão é essencial para evitar que nossa arquitetura de microserviços se transforme em uma teia de dependências difíceis de gerenciar.
Soluções Propostas por Newman
Newman, em Building Microservices, apresenta estratégias práticas para lidar com os desafios causados pelo acoplamento de passagem. Ele destaca que não existe uma solução única ou definitiva, mas sim um conjunto de princípios que podem orientar arquitetos a projetar sistemas mais robustos e escaláveis. Vamos adaptar essas ideias ao exemplo do Serviço de Desconto e entender como elas se aplicam.
Eliminar o intermediário sempre que possível
Uma das soluções de Newman seria eliminar o Serviço de Descontos e permitir que o Serviço de Pedido se comunique diretamente com o Serviço de Vouchers e o Serviço de Relatórios. Nesse caso, o Serviço de Pedido validaria os vouchers diretamente com o Serviço de Vouchers e enviaria os dados relevantes ao Serviço de Relatórios, sem depender de um intermediário.
Por que essa abordagem faz sentido?
• Ela reduz o número de dependências, eliminando o intermediário que não agrega valor real.
• Permite que o Serviço de Pedido tenha controle direto sobre as interações, simplificando o fluxo de dados.
Pontos de atenção:
• Embora essa abordagem simplifique o fluxo, ela aumenta o acoplamento de domínio do Serviço de Pedido, que agora precisa conhecer os contratos tanto do Serviço de Vouchers quanto do Serviço de Relatórios. Isso pode ser aceitável em alguns cenários, mas deve ser cuidadosamente avaliado para evitar sobrecarregar o Serviço de Pedido com responsabilidades extras.
Delegar responsabilidades de forma mais inteligente
Outra solução apresentada por Newman é tornar o intermediário mais autônomo. Em vez de ser apenas um pass-through, o Serviço de Descontos pode ser projetado para processar e encapsular a lógica de validação e registro de vouchers. Por exemplo:
• O Serviço de Pedido envia apenas o código do voucher (ou outros dados relevantes junto) para o Serviço de Descontos.
• O Serviço de Descontos valida o código diretamente com o Serviço de Vouchers.
• O Serviço de Descontos então registra o uso do voucher no Serviço de Relatórios sem expor a lógica ou os contratos desses serviços para o Serviço de Pedido.
Por que isso é interessante?
• Encapsula a lógica de descontos: O Serviço de Descontos se torna responsável por toda a lógica de validação e registro, reduzindo o número de interações diretas do Serviço de Pedido.
• Reduz o impacto de mudanças em contratos: Como o Serviço de Pedido não conhece os contratos de Vouchers e Relatórios, mudanças nesses serviços não o afetam diretamente.
Ponto de atenção:
• Tornar o Serviço de Descontos “inteligente” pode introduzir complexidade extra nesse serviço. Ele precisa ser projetado com clareza e evitar sobrecarga, para que não se torne um ponto único de falha ou um gargalo no sistema. Além disso os contratos precisam ter consistência!
Perguntas que um arquiteto deve sempre se fazer
Antes de sair criando um novo serviço, é essencial parar e refletir sobre o impacto dessa decisão. Não apenas do ponto de vista técnico, mas também pensando em como isso afeta o negócio e a evolução do sistema.
Serviços de passagem podem se tornar gargalos se não forem projetados para encapsular e adaptar a lógica de comunicação. - Sam Newman
Quando você projeta um serviço de passagem, está basicamente decidindo onde colocar a responsabilidade por algo. Será que esse intermediário realmente agrega valor? Ele está simplificando as coisas ou criando mais camadas desnecessárias? Arquitetos experientes sabem que, muitas vezes, as maiores armadilhas vêm de decisões que, na hora, pareciam pequenas. Então, a pergunta inicial sempre deve ser: “Esse serviço realmente precisa existir?”
Negócio: Para quem estamos construindo isso?
Um serviço intermediário só faz sentido se ele estiver resolvendo um problema real. E, não se engane, nem todo problema técnico é realmente um problema de negócio. Se você está adicionando um intermediário apenas para “organizar o fluxo”, sem pensar no valor que ele agrega, talvez esteja complicando mais do que ajudando. Pense assim:
• Esse intermediário está alinhado com o objetivo maior? Ele está ajudando sua empresa a entregar valor mais rápido ou está introduzindo mais pontos de controle, atrasando tudo?
• E quanto à clareza? Será que as equipes conseguem entender o papel desse intermediário no fluxo de dados? Um sistema confuso não é só difícil de operar; ele também é difícil de explicar para quem toma as decisões estratégicas.
Além disso, considere as mudanças no domínio. Se o seu negócio muda frequentemente — como no caso de um sistema de vouchers, onde novas regras e promoções aparecem o tempo todo —, você precisa garantir que o intermediário seja capaz de encapsular essas mudanças sem propagá-las para todo o sistema. Se ele está apenas repassando dados de um serviço para outro, ele realmente está ajudando a lidar com essas alterações?
Contratos: O que estamos prometendo?
Agora, vamos falar sobre contratos novamente. Serviços intermediários geralmente “mascaram” os contratos dos serviços upstream e downstream. Mas, às vezes, essa máscara não é tão sólida quanto parece. Se o intermediário não adiciona lógica própria, qualquer mudança nos contratos dos serviços que ele conecta pode quebrar toda a cadeia. Isso cria um paradoxo: o intermediário deveria simplificar, mas, na prática, ele pode estar adicionando mais fragilidade.
Um bom arquiteto sempre se pergunta: “Se esse contrato mudar amanhã, o que vai acontecer?”. E mais: “Estou criando uma dependência aqui que vai dificultar a evolução do sistema?”. Se a resposta for sim, talvez seja melhor repensar.
Técnico: Estamos facilitando ou complicando?
Do ponto de vista técnico, os intermediários podem ser tanto uma bênção quanto uma maldição. Eles encapsulam complexidade ou criam uma nova camada de problemas? Pense nisso: um intermediário sem lógica própria — que apenas passa dados adiante — é, na prática, um ponto de fragilidade. Ele está acumulando responsabilidades que não são dele, como lidar com contratos que pertencem a outros serviços. Se ele parar de funcionar, o sistema inteiro pode ficar comprometido.
Além disso, há a questão da resiliência. O intermediário está preparado para lidar com falhas? Ele pode continuar operando de forma degradada, ou sua queda interrompe tudo? Esses são pontos que precisam estar claros antes de você introduzir um novo serviço no meio.
E, finalmente, não podemos esquecer dos rollouts. Um serviço intermediário pode complicar muito o processo de deploys sincronizados. Pense no impacto disso: você precisa atualizar o intermediário e os serviços conectados ao mesmo tempo. Isso não só aumenta o risco de erros, como também exige uma coordenação que nem sempre é prática em ambientes corporativos.
No final, tudo se resume a isso: o intermediário está ajudando ou atrapalhando? Ele facilita as mudanças ou está criando mais dependências que complicam o sistema? Arquitetos experientes sabem que boas decisões vêm de boas perguntas. Então, da próxima vez que você se deparar com a ideia de criar um novo serviço intermediário, pergunte a si mesmo (e à sua equipe):
• Esse serviço realmente precisa existir?
• Ele está alinhado com o que o negócio precisa?
• E, se algo mudar, como isso vai afetar o sistema como um todo?
Essas perguntas não são fáceis, mas são necessárias. Afinal, uma boa arquitetura não é só aquela que funciona hoje, mas aquela que pode continuar funcionando — e evoluindo — amanhã.
Do Pombo-Correio ao Despachante: Transformando Intermediários em Agentes Ativos
Lembra da nossa ilustração do pombo-correio? Ele faz o trabalho de carregar a mensagem, mas sem compreender o que está transportando ou para quem. No papel de mensageiro, ele parece útil à primeira vista, mas vimos que, quando o formato ou o conteúdo da mensagem muda, ele rapidamente se torna um problema. Se os destinatários mudarem suas exigências, o pombo precisa de ajustes e, se houver outros pombos intermediários, a confusão e o trabalho dobrado se espalham em cadeia. Então, a pergunta é: queremos um serviço que funcione como um pombo-correio? Claro que não.
Mas se o pombo não é a melhor escolha, quem seria? Aqui está a questão central: no lugar de um “pombo-correio”, o que realmente precisamos é de alguém que saiba o que está carregando e como lidar com o conteúdo que transporta. Precisamos de um serviço que entenda a mensagem, a transforme, a processe e, se necessário, ajuste seu formato para atender às necessidades do destinatário final. Em termos técnicos, isso significa projetar o intermediário para ser mais do que um pass-through coupling. Ele deve encapsular a lógica e assumir responsabilidades claras no fluxo de dados.
Transformando o mensageiro em um agente ativo
Imagine agora que, em vez de um pombo, temos um despachante especializado.

Esse despachante não só entende o conteúdo da mensagem como também sabe exatamente o que fazer com ela:
• Se a mensagem for uma carta, ele a entrega como está.
• Se o destinatário precisa de um pacote, ele ajusta o formato antes de enviar.
• E mais importante: ele não precisa que o remetente ou o destinatário final se preocupem com os detalhes dessa transformação.
A diferença entre um pombo e um despachante
Um pombo-correio é reativo: ele apenas transporta o que lhe foi dado. Qualquer mudança no conteúdo exige ajustes em quem o envia ou em quem o recebe. Já o despachante é proativo: ele entende o propósito da mensagem e se encarrega de adaptá-la conforme necessário. No contexto de microserviços um despachante é um intermediário inteligente que encapsula a lógica e evita expor contratos de outros serviços.
Por que um despachante é uma escolha melhor?
Escolher o despachante como metáfora para o serviço intermediário é, na verdade, uma escolha arquitetural. Um intermediário ativo:
1. Isola mudanças: Se o contrato de um serviço downstream mudar, o despachante lida com isso. Os serviços upstream não precisam ser ajustados.
2. Reduz dependências: Um despachante encapsula a lógica necessária para interagir com os serviços downstream, de modo que os serviços upstream não precisem conhecer os contratos ou as regras de negócio de todos os outros serviços envolvidos. Isso elimina a necessidade de alterações em cascata, caso algo mude.
3. Adiciona flexibilidade: Como o despachante compreende e transforma os dados, ele é capaz de lidar com múltiplos cenários e mudanças no formato da mensagem ou nas regras do domínio, sem propagar essas alterações para todos os serviços conectados.
4. Melhora a resiliência: Diferente de um pombo-correio, que depende de uma cadeia estável para funcionar, o despachante é autossuficiente. Ele pode lidar com falhas nos serviços downstream, implementar estratégias de fallback5 e até armazenar mensagens temporariamente para serem processadas mais tarde, garantindo que o sistema continue operando de forma consistente.
Bom fico por aqui!👨🏻💻 Muito obrigado por ter dedicado seu tempo para ler este artigo! Espero que ele tenha trazido reflexões úteis e ajudado a esclarecer alguns pontos sobre arquitetura e microserviços. Até a próxima e seguimos juntos nessa jornada de aprendizado e evolução!
Referências: Building Microservices, 2nd Edition - by Sam Newman
Talvez você esteja se perguntando: “Mas, se o intermediário não compreende os dados, isso não o torna mais genérico e flexível? E se ele for apenas um transportador ‘burro’, sem nenhuma lógica embutida, isso não evitaria a necessidade de adaptações futuras?” Essa é uma pergunta válida e merece ser discutida. Afinal, à primeira vista, pode parecer que um serviço genérico, que não interfere nos dados que transporta, é mais fácil de manter e gerenciar. Mas será que isso realmente ajuda? Vamos refletir juntos.
Primeiro, precisamos considerar o que significa “ser genérico” em um sistema de microserviços. Um intermediário genérico pode ser entendido como um serviço que apenas passa dados adiante, sem processá-los, transformá-los ou conhecer os contratos de quem os originou ou quem os consome. Em tese, ele se limita a um papel de “tubo de comunicação”. Parece simples, certo? Mas a simplicidade, neste caso, pode ser ilusória.
O problema com o “genérico que não compreende os dados”
O argumento de que a falta de compreensão dos dados evita dependências e a necessidade de adaptação tem um ponto cego: ele ignora que o problema real não é o intermediário em si, mas o efeito em cadeia que ele pode criar. Quando um intermediário não compreende os dados, ele depende completamente da estabilidade dos serviços upstream e downstream. Se um desses serviços mudar — como no caso de um contrato de API —, o intermediário, mesmo “genérico”, pode ser impactado. Por quê?
1. Porque ele é parte da cadeia de comunicação.
Se o contrato dos dados upstream mudar, o intermediário precisa garantir que os dados que ele está passando ainda sejam válidos para os serviços downstream. Ele pode ser “genérico”, mas ainda depende da consistência dos dados que transporta. E se ele não faz nada para validar ou adaptar os dados, quem terá que lidar com as consequências? Os serviços upstream e downstream, criando um efeito cascata.
2. Porque a “genérica neutralidade” é apenas aparente.
O intermediário pode não processar os dados, mas ele ainda carrega contratos implícitos. Por exemplo, se um serviço downstream exige um campo específico e esse campo muda ou desaparece no serviço upstream, o intermediário pode continuar passando os dados, mas o sistema quebra no consumidor final. A falta de lógica no intermediário não elimina as dependências — apenas as esconde.
Genérico não significa resiliente
Ser genérico não significa ser resiliente. Na verdade, um intermediário que não compreende os dados pode até parecer mais simples de gerenciar, mas ele perde uma oportunidade crucial: encapsular a complexidade e proteger os serviços conectados de mudanças indesejadas. Em vez de atuar como um isolante, ele se torna apenas mais um ponto frágil na cadeia.
Imagine um sistema onde o intermediário é projetado para apenas transportar dados, sem entender o que está carregando. Quando algo muda — por exemplo, o formato dos dados ou as regras de negócio associadas a eles —, os serviços upstream e downstream precisam se adaptar diretamente. Isso vai contra o princípio dos microserviços, que deveria promover independência e isolamento de responsabilidades.
Então, ser genérico não ajuda?
Depende. Em alguns casos, a neutralidade pode ser útil — como em sistemas onde os fluxos são extremamente estáveis e mudanças são raras. Mas em outros cenários, especialmente em sistemas que lidam com regras de negócio dinâmicas, as mudanças são inevitáveis. E quando elas chegam, um intermediário genérico se torna um peso morto, incapaz de ajudar na transição.
A verdadeira questão não é apenas se o intermediário é genérico, mas se ele está cumprindo um propósito claro e agregando valor ao sistema. Um intermediário que compreende os dados pode encapsular mudanças e proteger o sistema de impactos desnecessários. Já um intermediário que apenas repassa dados, sem agregar valor, está criando uma falsa sensação de simplicidade que, no longo prazo, pode se tornar um problema difícil de resolver.
Agora, pense comigo. Talvez ser genérico funcione em sistemas muito simples, mas será que isso escala bem em arquiteturas complexas e dinâmicas? No final, a decisão não é apenas técnica, mas também estratégica. Como você quer que seu sistema evolua no futuro? Fique com essa pergunta enquanto continuamos a explorar os próximos passos desse artigo.
Downstream
Definição : Um serviço downstream é aquele que consome dados ou funcionalidades fornecidas por outros serviços. Ele é tipicamente o receptor no fluxo de dados.
• No exemplo acima, o Serviço de Vouchers seria o downstream em relação ao Serviço de Pedido, pois está respondendo à solicitação enviada.
Upstream
Significa “a montante” no fluxo de dados.
Definição : Um serviço upstream é aquele que fornece dados ou funcionalidades dos quais outros serviços dependem. Ele é tipicamente a fonte ou origem do fluxo de dados.
• Por exemplo: em um sistema onde o Serviço de Pedido solicita informações ao Serviço de Vouchers, o Serviço de Pedido é considerado upstream em relação ao Serviço de Vouchers.
Quando dizemos que o Serviço de Descontos não encapsula verdadeiramente os contratos dos downstreams, significa que ele não esconde os detalhes dos serviços downstream (Vouchers e Relatórios) do Serviço de Pedido (upstream). Ele apenas repassa mensagens entre eles, mas não isola ou abstrai os contratos de modo eficaz.
Webhooks vs Serviços de Acoplamento de Passagem
Um webhook pode ser comparado a um “serviço de acoplamento de passagem” em um aspecto: ele não interpreta os dados que transporta. Mas há uma diferença fundamental: o webhook tem um propósito muito bem definido e limitado. Ele não tenta ser um intermediário geral entre múltiplos serviços.
Enquanto um serviço de acoplamento de passagem em microserviços pode ser problemático porque adiciona dependências ocultas e lógica implícita, o webhook não carrega contratos complexos ou responsabilidades extras. Ele é um mecanismo de notificação e, como tal, sua simplicidade é uma vantagem, não uma limitação.
Então, um webhook é desacoplado e eficiente?
Sim, se o seu propósito for limitado ao disparo de eventos e notificações. Webhooks funcionam bem em cenários onde:
• O consumidor é responsável por processar os dados recebidos.
• O produtor (quem envia o webhook) não precisa saber nada sobre como os dados serão usados.
No entanto, se o webhook começar a incorporar lógica adicional — como transformar dados (carregando consigo modelos e contratos de outros serviços) ou validar regras específicas —, ele pode perder sua simplicidade e começar a funcionar como um serviço intermediário genérico, o que o torna mais sujeito aos problemas de acoplamento que discutimos.
O propósito claro do webhook
A força de um webhook está no fato de que ele é projetado para ser simples e objetivo:
• Ele dispara eventos ou envia dados para outro sistema (geralmente via HTTP) quando algo relevante acontece.
• Ele não interpreta ou processa os dados enviados. Seu único trabalho é garantir que a notificação chegue ao destino, seguindo um contrato básico (geralmente o formato JSON ou outro padrão).
Nesse sentido, um webhook é desacoplado por design, pois não se preocupa com o que acontece no sistema que recebe o evento. Ele apenas comunica que algo aconteceu. O consumidor do webhook (o serviço externo) é quem decide como usar os dados.
Um fallback é uma solução ou mecanismo alternativo que é acionado automaticamente quando algo dá errado ou não está disponível no sistema principal. Ele é usado para garantir que, mesmo em caso de falha, o sistema possa continuar funcionando de maneira parcial ou degradada, em vez de parar completamente.
Por exemplo:
• Em um sistema de microserviços, se um serviço downstream estiver indisponível, o fallback pode retornar uma resposta padrão ou executar uma lógica alternativa para evitar a interrupção.
• Em interfaces de usuário, se uma imagem falhar ao carregar, um fallback pode exibir uma imagem genérica ou uma mensagem de erro amigável.
O objetivo principal do fallback é melhorar a resiliência do sistema, reduzindo o impacto das falhas no funcionamento geral e na experiência do usuário.