
Architectural Pitfalls: When Microservices Turn Out to Be Distributed Monoliths 😮
If you decompose a system incorrectly, you will build a distributed monolith... - Chris Richardson, Microservices Patterns: With Examples in Java

The concept of microservices is always on the rise. Many organizations implement it hoping to have more ease and agility in their daily lives. But these corporations and professionals who invest in this architecture must be aware of the complexity and difficulties they may encounter. I'm not talking about one or two challenges, I'm stating that high complexity is a fact! Dealing with services that handle different responsibilities has its price to pay, especially when the line between the efficiency of modularization and the tangle of interdependence begins to blur. In this context, a crucial question arises that many developers and software architects face: is your microservice actually a distributed monolith?
This dilemma is not just semantic, but reflects an operational reality where the promise of agility and scalability of microservices can be overshadowed by inadvertent complexity and management issues that are characteristic of monolithic systems. As we delve into this debate, it is essential to uncover the telltale signs of a distributed monolith and explore strategies for maintaining the true essence of microservices while ensuring that the architecture adopted promotes the independence, efficiency, and responsiveness that modern organizations demand.
If you like the content, please share and like the post! This helps and encourages me to continue bringing content in text form too!😄
What is a microservice? 🧐
Chris Richardson, author of the book "Microservices Patterns", comments that microservices are an architectural approach that structures an application as a collection of services. These services are characterized by being:
Organized around business capabilities: Each service is built around a specific business function and is designed to be a stand-alone, independent part of the total system. This allows different teams to focus on different services, each with its own development and deployment lifecycle.
Small team ownership: Typically, each microservice is maintained by a small team that is responsible for the entire lifecycle of the service, from development to operation. This promotes ownership and direct accountability, allowing teams to move quickly and make changes independently.
Microservices architecture enables organizations to deliver large, complex applications quickly, frequently, reliably, and sustainably, which is crucial to competing and succeeding in today's marketplace. This approach promotes fast and reliable software delivery aligned with DevOps principles, organization into small, decoupled teams, and an architecture that is decoupled, testable, and deployable. However, the transition to an isolated services context is not without challenges, on the contrary, challenges are common and we can often be going in the opposite direction! Like this?
In the book "Microservices Patterns", the concept of "distributed monoliths" is discussed in the context of the challenges and pitfalls that organizations may face when adopting a microservices architecture. Richardson warns that without careful consideration of design and implementation practices, organizations can end up building what he calls "distributed monoliths" rather than a true microservices architecture. Let's talk a lot about this topic in the topic below.
What is a distributed monolith? 🚨
Anyone who follows my articles knows that I like analogies. So I'm going to use one more to try to improve the understanding of what a distributed monolith would be.
Imagine for a moment that you are trying to put together a big puzzle. Each part represents a different service in its application. In the ideal microservices architecture, each piece fits perfectly into its place, contributing to the big picture without being overly dependent on the surrounding pieces. You can work on different sections of the puzzle simultaneously, with different groups of friends, without getting in each other's way. This is what makes the microservices approach so attractive: the ability to scale, modify, and maintain parts of the application independently.
Now, let's move on to the distributed monolith analogy. Imagine that instead of independent puzzle pieces, you have pieces that are attached to each other in groups. At first glance, it looks like you have several smaller sections to work with – a bit like microservices. But when you try to move or change a section, you find that it is inextricably linked to other sections. You and your friends find yourself constantly bumping into each other, trying to figure out how to change one part without taking half the puzzle apart.
This is the heart of a distributed monolith: despite the appearance of modularity, there is such a strong interdependence between services that the intended autonomy is more illusory than real. Just like a jigsaw puzzle, where interconnected pieces limit the freedom to work in independent sections, a distributed monolith restricts the agility and efficiency of the dev elopment team.
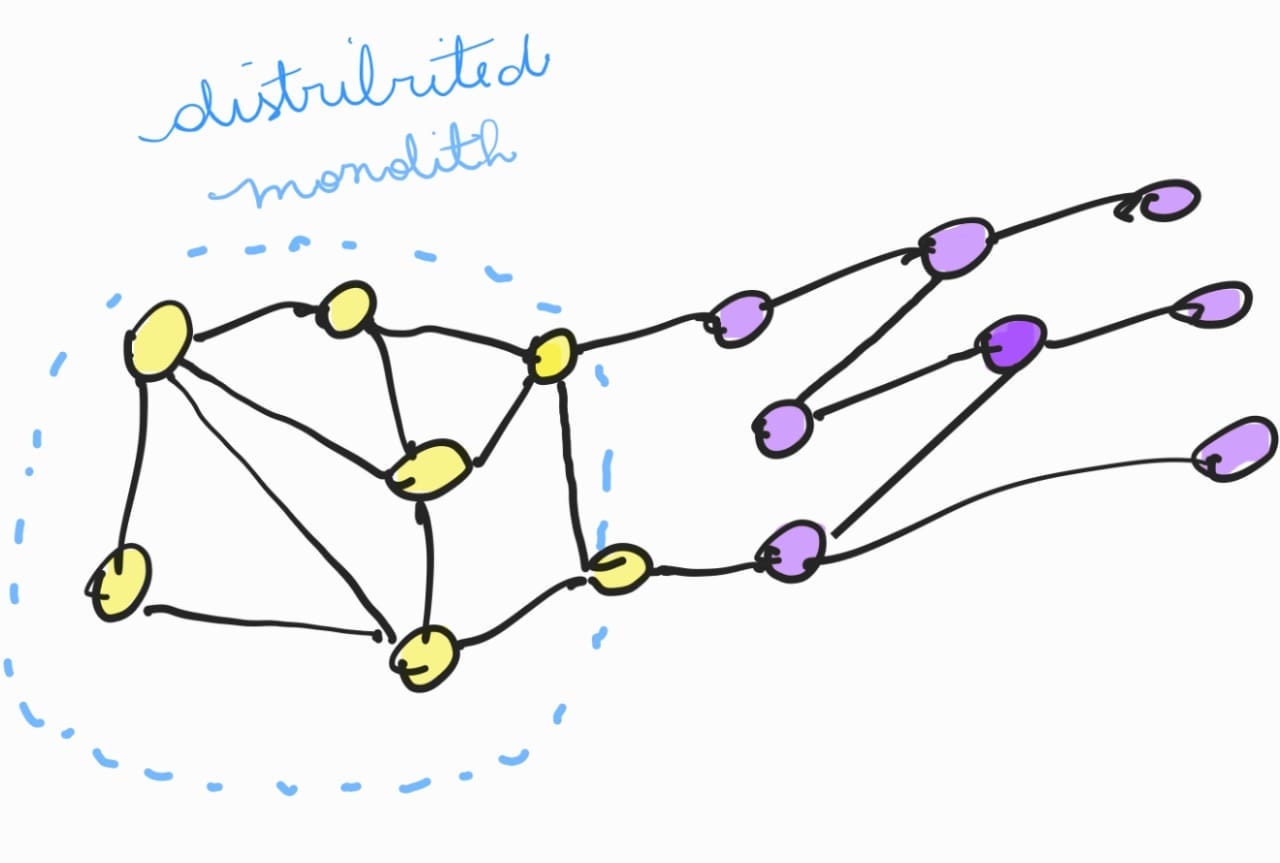
The key points to note here are the importance of independence and decoupling in microservices. It is not enough to simply divide an application into several services and communicate them via REST API; It is crucial that these services are truly autonomous, with no hidden dependencies tying them to one another. Synchronous communication, when excessive, can be a trap, creating points of failure and bottlenecks that affect the entire application.
But every problem has its origins, so let's better understand what can lead to monolithic distributed hell.
What leads down the dark path of the distributed monolith?
Breaking down a monolith into microservices is a complex and challenging task, fraught with potential pitfalls. One of the most significant mistakes that software architects and programmers can make in this process is failing to recognize the difference between simply dividing a system into smaller parts and truly restructuring the architecture to take advantage of the benefits of microservices.
This misconception can inadvertently lead to the creation of an ecosystem of distributed monoliths, rather than a cohesive and efficient microservices architecture. Let's explore the main points that contribute to this deviation:
Lack of understanding of business domains: One of the fundamental aspects of microservices architecture is alignment with business domains across bounded contexts. Without a clear understanding of these domains, architects may end up segmenting the monolith in a way that only reflects the existing technical structure, rather than reorganizing the application around its business functions. This results in services that are still tightly coupled in terms of business logic, leading to the creation of "mini-monoliths" that need to be constantly synchronized.
Excessive data sharing: A common mistake when decomposing a monolith is allowing microservices to share databases or data schemas. This creates a strong dependency between services and prevents them from evolving independently, since any change to the data schema can affect multiple services. Ideally, each microservice should own and manage its own database or dataset.
Excessive synchronous communication: When transforming a monolith into microservices, it can be tempting to maintain the synchronous communication patterns that were present in the original monolithic system. However, this can lead to high temporal coupling between services and increase the latency of the system as a whole. A well-designed microservices architecture prefers asynchronous and event-driven communications, promoting decoupling and independence.
Shared Queues: The misuse of shared queues between microservices is another indication that the architecture may be deviating from the fundamental principles of microservices and moving towards a distributed monolith. In an ideal scenario, queues should act as decoupling mechanisms, allowing services to communicate asynchronously and independently. However, when multiple parts of the system interact with the same queue - whether to read, write, or both - an implicit coupling between these services arises.
Underestimating operational complexity: Finally, a critical mistake is underestimating the operational complexity introduced by microservices. Each service adds to the system's attack surface, requiring security management, monitoring, logistics, and resilience. Without the proper tools and practices to manage this complexity, developers and operators can find themselves overwhelmed, leading to a situation where microservices are inadequately grouped or integrated to simplify management, culminating in the creation of distributed monoliths.
Avoiding these pitfalls requires a careful approach that considers both the technical and organizational aspects of microservices architecture. The key is to maintain a focus on service independence, understanding business domains, and adopting practices that support a distributed architecture.
Let's start by talking about how this distribution fails to centralize business!
Failure to Centralize Business Responsibilities
A critical point in the discussion about distributed monoliths is the failure to adequately centralize business logic. Let's unfold these aspects to better understand how they contribute to creating a distributed monolith rather than a well-defined microservices architecture.
Updating a simple validation rule in an environment where business decisions are decentralized can become a complex operation and prone to data inconsistency or unexpected errors. Decentralization occurs when business principles and rules are not maintained within a limited context, leading to their replication across multiple services. This phenomenon is commonly observed in architectures that, despite being designed to be microservices, end up functioning more like distributed monoliths due to the high coupling and dependency between services.
Problems arising from the decentralization of business logic
Logic Duplication: Without adequate centralization, each microservice may end up implementing its own version of validation logic. For example, if two different services need to validate user information, such as an email address or password, both may end up having their own code for this validation. This not only duplicates development effort, but also increases the likelihood of validation inconsistencies, where one service may accept a value that another rejects.
Data Inconsistencies: When business rules are not applied consistently across all services, data inconsistencies can occur. For example, if a service updates user data without applying all necessary validations, this data may be at odds with the expectations of other services that depend on this information, leading to errors and unexpected behaviors in the system.
Difficult to Maintain and Update: With business logic spread across multiple services, making changes becomes an arduous task. Updating a simple validation rule can require changes at multiple points in the system, increasing the risk of bugs and making the update process slow and error-prone.
Updating a simple validation rule in a decentralized business logic scenario can become a herculean task, especially when that logic is spread across multiple services in an uncoordinated manner. This problem is exacerbated in complex systems, such as microservices, where modularity and independence are fundamental. An illustrative example of this challenge can be observed in a system that involves validating and creating vouchers.
Imagine an e-commerce service that, in addition to managing products, shopping carts and payments, also offers a voucher system for discounts. The Voucher service, ideally, should be solely responsible for validating and creating new vouchers, ensuring that business rules specific to vouchers are centralized and consistent. These rules may include validating the voucher's expiration date, calculating the discount based on the total purchase value, limiting the use of the voucher to certain product categories, or verifying the user's eligibility for the discount.
However, in practice, the logic and business rules associated with vouchers can begin to infiltrate other services inappropriately. For example, the service responsible for the shopping cart may begin to incorporate its own logic for applying voucher discounts, perhaps because it needs to present the user with the full discounted amount before completing the purchase. Similarly, the user management service can begin implementing rules to determine whether a user is eligible to receive a voucher based on their purchase history.
This mess around vouchers leads to several problems. There is a duplication of efforts, as the same logic is implemented in multiple services, increasing the development and maintenance burden. Additionally, any change to voucher business rules — such as changes to eligibility conditions, discount calculations, or voucher types — requires updates to all services that have incorporated parts of this logic, which is prone to errors and inconsistencies. If a service fails to incorporate updates correctly, the system as a whole may begin to behave unpredictably, offering incorrect discounts or allowing the use of expired vouchers, for example.
This scenario contributes to the creation of a "distributed monolith", where, despite the appearance of modularity provided by microservices, the business logic remains interdependent and tightly coupled between services. This goes against the fundamental principles of a well-defined microservices architecture, which aims for clear separation of responsibilities and independence between services.

The development of new functionalities in this context becomes slower and more risky, since the interdependence between services increases the complexity of the system. Implementing a new business rule may require careful analysis of all affected services and precise coordination during the update to avoid system breakdowns.
How can we avoid this type of trap? Domain-Driven Design (DDD) offers an approach to mitigate these issues by emphasizing the importance of modeling services around business domain boundaries. In the context of our example, DDD would suggest building a rich domain model for the Voucher service, encapsulating all the logic and business rules pertinent to vouchers within that service. Other services, such as shopping cart and user management, would interact with the Voucher service through clearly defined interfaces (APIs), without directly incorporating any voucher-related business logic. This ensures that business rules remain consistent, centralized and easy to maintain, while maintaining modularity and independence of services.
I think it's important to briefly comment on this in the following sub-topic.
Defining the Voucher's Bounded Context
The first step would be to define the Bounded Context for the Voucher service. This would involve identifying the functional boundaries and responsibilities of the Voucher service, clearly distinguishing them from other domains such as shopping cart and user management. In a business context, this means understanding all operations, policies, and rules related to vouchers, such as issuance, validation, expiration, and usage restrictions.
From a technical perspective, this understanding translates into the modeling of entities, aggregates, and domain services that encapsulate the logic and business rules of vouchers. This helps ensure that the Voucher service is self-sufficient, managing all aspects related to vouchers without relying on logic implemented in other services.
Ubiquitous Language
Adopting a Ubiquitous Language within this Bounded Context helps align all team members (developers, domain experts, product managers, etc.) towards understanding the concepts and operations related to vouchers. This ensures that when it comes to "validating a voucher" or "issuing a new voucher", everyone understands exactly what these operations entail, both in terms of business rules and technical implementation.
Domain Modeling
With a clearly defined Bounded Context and adopted Ubiquitous Language, the team can then proceed to domain modeling. This entails creating a rich domain model that encapsulates voucher business logic and rules in an abstract and expressive way. This model serves as the backbone of the Voucher service, ensuring that all operations carried out through this service are in compliance with established policies and business rules.
Continuous Collaboration and Refinement
DDD does not view system design as fixed; rather, it promotes ongoing collaboration among team members to refine the domain model and adjust Bounded Contexts as new insights are gained. This ensures that the system remains aligned with business and technology needs, adapting to changes without compromising the clarity of domain boundaries or the cohesion of business logic.

By following these guidelines, DDD helps architects and experts create a microservices system in which each service, like Vouchers, is an island of consistency and autonomy, clearly delimited and aligned with the specific needs of the business domain it serves. . This minimizes the risk of creating a distributed monolith, where business logic becomes intertwined and diffused between services, harming the modularity, scalability and maintainability of the system.
Breaking apart a monolith without a clear strategy is the first step to creating a distributed monolith.
Interfaces and Integration
To interact with other services, such as the shopping cart and user management, the Voucher service would expose well-defined interfaces (APIs), which would allow specific operations, such as validating a voucher during checkout. These interfaces would be designed to limit access to the internal operations of the Voucher service, preventing the business logic of vouchers from being spread or duplicated in other services.
In the adjusted sequential diagram, it is clear that the communication of services that need to validate or consult Vouchers changes completely:

These C4 Diagrams and Sequence diagrams are great allies when we need to clearly visualize this within large systems and when breaking down monoliths.
Library Sharing and Coupling
The use of shared libraries between services is another area that deserves attention. Shared libraries can be extremely useful for avoiding code duplication and promoting consistent coding practices across your organization. However, when poorly managed, they can become an unwanted coupling point between services.
If multiple services rely heavily on the same libraries to perform critical tasks, any change to those libraries could require a wave of updates across all affected services. This not only increases the risk of introducing bugs, but also creates a scenario where the independence of each service is compromised. They become less able to evolve, be maintained, and scale independently, since changes to a central library can affect multiple services.
Dear reader, this subject is important, especially in corporations with a high degree of complexity with critical and fundamental systems!
Additionally, heavy use of shared libraries can mask complexity, causing developers to underestimate the actual coupling between services. This can lead to design decisions that favor short-term convenience over the long-term health of the architecture.
Let's explore some hypothetical scenarios about sharing internally created libraries to an enterprise ecosystem and how this might inadvertently contribute to the development of a distributed monolith, highlighting the challenges and implications of this coupling.
Scenario 1: Security Protocol Update
Imagine an internal library that handles authentication and security, widely used across multiple services to validate user tokens. A critical security update is required due to a new vulnerability. The change in the library requires an update to all services that use it. However, each service has its own release cycle and dependencies, making synchronous updating a logistical nightmare. This can result in a window of time where different parts of the system are at odds in terms of security, compromising the integrity of the system as a whole.
Scenario 2: Library Dependency for Data Operations
Consider a library that provides standardized access and manipulation for a shared database. While this can promote code reuse, it also creates a single point of failure. If the library has a bug or needs optimization to handle larger workloads, all services that depend on it will be affected. This not only increases the risk of service interruption, but also limits each service's ability to optimize its own data access to its specific needs.
Scenario 3: Change in Business Logic
A common internal library that manages shared business rules, such as price or discount calculations. A change in business rules requires a library update. However, different services may have interpreted or implemented the original rules slightly differently, adapting them to their specific needs. Centralized updating can inadvertently break custom logic across multiple services, leading to application inconsistencies and errors.
Invisible Coupling and Underestimated Complexity
Teams may underestimate the complexity of their architectures due to the extensive use of shared libraries, believing that services are more independent than they really are, but in reality, if poorly managed, this can become a huge headache.
When a shared library needs to be updated or refactored, teams can find themselves faced with a complex web of dependencies that weren't initially apparent. This “invisible” coupling can lead to significant coordination effort between teams to make changes that appear simple on the surface.

Implications
Architects and engineers should approach sharing libraries between services with caution, as it can introduce unwanted couplings and compromise the independence and ease of modification of each service. This is because shared libraries create a common code base that, if changed, can affect all services that use it.
When the decoupling is superficial, the distributed monolith emerges as a shadow over the architecture.
Let's review some considerations and best practices for managing the use of shared libraries:
Carefully Assessing the Need for Sharing
Responsibility Isolation: It is crucial for software engineers to define and preserve the unique responsibilities of each service within a microservices architecture. In doing so, each service must operate independently, with its functions and areas of activity well established. When it comes to the use of shared libraries, these should be reserved strictly for functionality that is cross-cutting and not specific to any particular business domain. Clear examples of such functionalities include logging operations, inter-service communication mechanisms, custom exceptions and authentication systems. These are considered common practices that support the underlying technical infrastructure of microservices, without directly intertwining with the specific business logic of any individual service.
Impact Analysis: Before adopting a shared library, it is crucial to evaluate the impact of your changes on consumer services. Is the library stable? How frequent are updates? Are the changes backwards compatible?
Guarantee of Independence of Services
Library Versioning: Using semantic versioning for shared libraries can help manage dependencies and ensure that incompatible updates do not affect existing services without adequate review.
Clear Contracts: Define and maintain clear contracts for the interfaces exposed by shared libraries. This helps ensure that expectations between consumer services and the library are well understood and maintained.
Carrying out Proofs of Concept (PoC)
Feasibility Validation: Carrying out PoCs before implementing and adopting shared libraries on a large scale is essential to validate technical feasibility and suitability for intended use in the various ecosystem services.
Side Effect Identification: PoCs help identify potential side effects or integration issues that may not be obvious early in development. This includes testing the library in different contexts and workloads to ensure scalability and performance.
Iterative Feedback: The PoC phase allows for an iterative feedback loop between library developers and its consumers (other services), facilitating adjustments and improvements before a wider release.
Business and Technical Considerations
Impact on Time-to-Market: The use of shared libraries can speed up initial development, but changes in these libraries can become blocks for updates or new features in services, affecting the time to launch of products or services.
Maintenance Cost: Engineers must consider the maintenance cost associated with shared libraries. Is the added complexity worth the code reuse?1
Culture of Collaboration: Foster a culture of collaboration and open communication among development teams to ensure that the needs and concerns of all services are considered in maintaining shared libraries.
In short, the decision to share libraries between services in a microservices ecosystem should not be made without considering the possible impacts. It requires careful assessment of technical and business needs, as well as careful implementation and management to avoid risks associated with coupling and loss of independence of services. Conducting PoCs is a critical step in this process, providing valuable insights and helping to ensure that the solution is robust, scalable, and aligned with the ecosystem's long-term goals.
Beware of Excessive Coupling!
In distributed architectures, such as those based on microservices, some level of coupling between services is normal and even inevitable. Different components need to interact and collaborate for the system to function as a cohesive whole. This includes exchanging information and coordinating between services to perform joint tasks, fulfill workflows, or maintain data consistency.2
However, it is essential to be aware of excessive coupling, which can become a major concern. Too tight coupling between services can lead to a series of problems.
Excessive Coupling: The Root of the Problem
In an ideal microservices architecture, each service is self-contained, managing its own business logic, data, and dependencies. Excessive coupling happens when distinct services, even physically separated (in different containers or servers), directly share data or states, creating an intrinsic dependence on each other.
How Excessive Coupling Hurts Microservices Principles
Violation of Independence: Microservices must be independent, allowing updates, scalability and maintenance without impacting other services. Data coupling compromises this independence, as changes to one service may require corresponding changes to the coupled services.
Resilience Degradation: One of the pillars of microservices is resilience, the ability for a service to fail without significantly affecting others. Data coupling creates single points of failure, where problems in one service can propagate, affecting other coupled services.
Obstacle to Scalability: Scalability becomes complex and inefficient when services are tightly coupled. Scaling a coupled service may require all related services to be scaled simultaneously, increasing costs and complexity.
The Importance of Isolation
Complete isolation of services is essential to maintain modularity, facilitate maintenance, and promote efficient scalability. Isolating services means that each one operates independently, without directly depending on the data or state of another service.
Operational Risks of Excessive Coupling
Inflexibility: The ability to quickly adapt and evolve services is hampered, as any change may require complex coordination between multiple services.
Increased Downtime: Failure of a service can lead to cascading failure, increasing system downtime and affecting the user experience.
Management Complexity: Management and monitoring become more challenging, requiring more complex tools and processes to ensure system integrity.
Impact on the Development of New Features
Excessive coupling between services can significantly slow down the development of new functionality. Development teams can find themselves tangled in a web of dependencies, making it difficult to implement, test and release new features in an agile manner.
E-commerce System
I want you to visualize an e-commerce system with two services: an Order service and an Inventory service. If the Order service directly accesses the Inventory service database to check product availability, a direct data coupling is created. This means that any changes to the Inventory data structure may require changes to the Orders service. Additionally, if the Inventory service fails, the Ordering service may become inoperable, even if its own infrastructure is intact.

Exploring the e-commerce system example more deeply, we can see how direct coupling between the Order service and the Inventory service can lead to a series of challenges and complications, clearly illustrating the problems associated with excessive coupling in an e-commerce system architecture. microservices.
Technical and Operational Challenges
Data Structure Changes: If the Inventory service decides to change its data structure - for example, to optimize storage or add new attributes to products - this change could break integration with the Ordering service. The Orders service may expect data in a specific format or rely on fields that are modified or removed, leading to failures and the need for immediate refactoring.
Cascading Failures: The direct dependence of the Order service on the Inventory service database means that any interruption to Inventory - whether due to overload, hardware failures or maintenance - directly impacts the functionality of the Order service. This can lead to a negative user experience where customers are unable to place orders even when other parts of the system are operational.
Difficulties in Scalability: Scalability becomes a significant challenge when services are tightly coupled. If the system experiences a spike in demand that requires more resources for the Order service, the performance of the Inventory service may be inadvertently affected due to data coupling, and vice versa. Scaling one service without impacting another requires careful coordination and can be inefficient.
Implications for Development and Maintenance
Barriers to Agile Development: The need to synchronize changes between the Ordering service and the Inventory service can significantly slow down the development cycle. New features that require changes to both services require cross-team coordination, cross-team reviews, and extensive testing to ensure that changes to one service don't break the other.
Complex Maintenance: Maintenance becomes more complex due to interdependence. Security updates, bug fixes or performance improvements in one service may require corresponding adjustments in the other. This not only increases maintenance effort, but also increases the risk of introducing new bugs during the update process.
Alternative Approach to Decoupling
A healthier approach to this scenario would be to implement a communication layer that decouples services. For example, the Ordering service could issue a request via API or an asynchronous messaging system to check product availability. The Inventory service would then respond with updated availability, without directly exposing its database. This allows each service to evolve independently while maintaining system integrity and resilience.

This scenario, where the Order Service and the Inventory Service communicate in a decoupled way through a message queue, is valid and quite common in the industry, especially in event-driven architectures.
Be careful with excessive synchronous communication!
Although synchronous communication can simplify the initial design, making it easier to understand the flow of data and operations, it introduces temporal coupling that can be problematic. Each request between services requires an immediate response, creating a direct dependency on the availability and performance of the called service. This not only increases the latency of the system as a whole, but also makes the system more fragile and less resilient to failures.
Synchronous communication in microservices
Synchronous communication occurs when a service A makes a request to a service B and waits for a response before proceeding. This pattern is intuitive and straightforward, mimicking common function calls in programming, which makes it attractive when decomposing a monolith. In the context of microservices, it is often implemented through REST or gRPC API calls, for example.
Applicability and Limitations
Although synchronous communication is suitable for operations that require immediate confirmation and consistency, such as some financial transactions or critical state updates, it has significant limitations in a distributed architecture:
Temporal Coupling: Services become heavily dependent on each other's availability and performance, which can lead to single points of failure.
Latency: The need to wait for responses can significantly increase overall system latency, especially if multiple synchronous chain calls are required to complete an operation.
Scalability: Scalability can be compromised, as the increase in the volume of requests can overload services and require proportional scalability of all services involved in the communication chain.
Dark Path to a Distributed Monolith
The excessive use of synchronous communication in an architecture that should be microservices, in some contexts may begin to indicate that we are starting a path towards a distributed monolith. Why? We return to highlighting that services become so interdependent that they lose the ability to function, evolve or be scaled independently. This is particularly true when synchronous patterns are used without careful consideration of their implications, leading to a complex mesh of direct dependencies.
First signs and warnings
Early signs that synchronous communication is driving a distributed monolith include:
Performance Degradation: An increase in overall system latency, where operations that should be fast begin to experience noticeable delays.
Cascading Failures: Failures or degradations in one service begin to directly impact other services, even if they do not share the same code base or infrastructure.
Difficulties in Independent Deployment: The need to coordinate updates and deployments between services suggests a high level of coupling.
Regarding the points above, I would like to mention some examples so that it is clear.
Performance degradation
Example: Imagine an e-commerce system where, when completing a purchase, the Orders service needs to confirm stock with the Inventory service, calculate shipping with the Logistics service and, finally, process payment with the Payments service . If each of these steps is done synchronously and one after the other, a delay in any service can significantly increase the total time to complete the purchase.
Questions to Ask:
"Is there a way to parallelize these checks or perform them asynchronously to reduce latency?"
"Can we implement a cache or fallback policy to handle the temporary unavailability of a service?"
Cascading failures
Example: Suppose the Payments service mentioned earlier is experiencing an outage. If the Order service cannot process a purchase without payment confirmation, the entire checkout operation is compromised, affecting the user experience, even if the Inventory and Logistics services are operating normally.
Questions to Ask:
"Can we introduce a messaging system or a queue to decouple the payment process from the checkout process?"
"Is there a contingency strategy, such as allowing offline or delayed payments, to maintain checkout functionality in the event of a Payments service failure?"
Difficulties in independent implementation
Example: Each time the Inventory service is updated to include new functionality, the Orders service also needs to be modified to accommodate these changes, even if its core logic has not been affected. This not only delays the release of new features, but also increases the risk of introducing bugs.
Always question:
"Are the services sharing business logic or data that could be encapsulated or abstracted?"
"Can we define more stable API contracts or use API versioning standards to minimize the impact of changes?"
But to deal with the challenges presented by excessive synchronous communication and avoid the unwanted evolution of a microservices architecture into a distributed monolith, it is important to adopt conscious strategies and pragmatic solutions. I want to comment on some that are applied in the industry and that are viable:
Asynchronous Communication Where Possible
Transitioning to asynchronous communication patterns, such as message and event queues, can significantly reduce temporal coupling between services. This allows services to operate more independently, without the need to wait for immediate responses.
Solution for Performance Degradation:
Implement message queues to decouple business processes, allowing critical operations such as order processing to continue even if a dependent service is slow or temporarily unavailable.
Use Resilience Patterns
Patterns such as Circuit Breaker, Bulkhead and Timeout can help prevent cascading failures and ensure that the system remains responsive even in the face of individual service failures.
Solution for Cascading Failures:
Implement the Circuit Breaker pattern in the Orders service to prevent calls to a Payments service that is consistently failing by using appropriate fallback logic.
Versioning Strategies and API Contracts
Defining and maintaining clear and stable API contracts, along with versioning strategies, can minimize the impacts of changes, allowing services to evolve more independently.
Solution for Difficulties in Independent Implementation:
Use API versioning to allow the Inventory service to introduce new functionality without forcing immediate changes to the Ordering service, facilitating independent deployment of services.
Implement Monitoring and Alerts
A robust monitoring and alerting system can help quickly identify performance issues and failures, enabling agile response before end users are significantly impacted.
Proactive Solution:
Configure monitoring dashboards and alerts based on critical metrics such as latency and error rates for each service, enabling proactive problem detection and resolution.
While synchronous communication is not the norm in microservices architectures, it has its place and may be necessary for certain operations that require consistency and immediate response. However, it is crucial to be vigilant about its use as the complexity of the service network increases.
In microservices architectures, the ideal is to favor asynchronous communication, which promotes decoupling between services. This allows each service to operate more independently, facilitating system scalability and maintenance. Asynchronous communication also reduces points of failure, as services are not blocked waiting for responses from each other, which increases the system's resilience.
I hope this topic is clear, let's now talk about another scenario that leads to microservices masquerading as monoliths.
Understanding the Problem with Shared Queues
Queues are essential components for asynchronous communication in distributed systems, allowing services to send and receive messages in a decoupled manner. However, sharing a single queue across multiple services introduces unwanted coupling, similar to the problems encountered with sharing databases across monoliths. This coupling manifests itself in several ways:
Message Format Coupling: All services that produce or consume messages from a shared queue must agree on a common message format. This limits the flexibility for services to evolve independently, as any change to the message format can affect all services connected to the queue.
Message Consumption Management: In a shared queue, there is a risk of one service consuming messages destined for another, unless there is a very well-defined way of filtering or routing messages, which adds complexity to the system.
Scalability and Resilience: Mutual dependency in a shared queue can create a single point of failure and make it challenging to scale services independently, as the load on the queue is shared among all services.
An order processing system
Imagine an order processing system where an "Order Creation" service sends new order information to a shared queue, from which an "Inventory Management" service and a "Payment Processing" service consume messages. Initially, this setup may seem efficient, but problems quickly emerge:
Modifications to the Order Service: If the "Order Creation" service needs to modify the structure of its messages to include new data, such as promotional codes, both consuming services need to be updated to handle the new format, even if that data does not are relevant to your operations. This slows down the delivery of new features and increases the risk of errors.
Peak Demand in Payment Processing: During a promotion, the volume of orders increases significantly, overloading the "Payment Processing" service. As a result, the "Inventory Management" service is also affected as messages accumulate in the shared queue, delaying inventory updates.
Failure in the Inventory Management Service: A failure in the "Inventory Management" service, which prevents it from consuming messages, can interrupt the entire order processing flow, as unconsumed messages accumulate, potentially even affecting the receipt of New requests.

Some essential questions that we must ask ourselves to analyze the context:
What is the point of sharing the queue?
Evaluate the motivation behind the decision. Is it for convenience, cost reduction, or is there a clearly defined business need?
How does queue sharing affect service autonomy?
Consider whether services can evolve, scale, and be maintained independently of each other, even while sharing the same queue.
Are there alternatives to queue sharing that still meet the requirements?
Explore other options, such as using multi-subscription topics or implementing dedicated queues for each service.
How will the message format be managed and versioned?
Determine whether there is a clearly defined messaging contract and how changes in message format will be managed to avoid disruptions to consumer services.
How will message processing be isolated between services?
Evaluate mechanisms to ensure that one service does not consume or interfere with messages intended for another service.
What are the scalability and resilience implications?
Consider how the system will respond to load spikes and failures. Does queue sharing introduce single points of failure or bottlenecks?
Answering these questions will help architects and everyone involved make more informed decisions about using shared queues, ensuring that the microservices architecture remains robust, flexible, and aligned with the organization's long-term goals.
Communication between business units is also hampered!
I want to address the issue of signals from a distributed monolith from the point of view of communication between development and business teams and how this may diverge from the core principles of microservices. I saw this in some corporate contexts, especially when they worked in banking institutions!
Signs of a Distributed Monolith in Communication and Business
Tightly Coupled Integrations: A clear indication of the presence of a distributed monolith within an architecture that, ideally, should favor independence and modularity between services. In a well-designed microservices architecture, each service is expected to have the ability to evolve and adapt autonomously, without the need for extensive coordination or constant renegotiations with other services within the same business ecosystem. This independence is crucial to taking advantage of the benefits of microservices architecture, such as development agility, scalability, and resilience. However, when we observe that changes in a specific service trigger a chain of adjustments and modifications in other related services, this denotes a problematic level of interdependence. Such a scenario reveals this coupling. I will leave more information and some points of attention in the footnote.3
Centralized Contract Generation: In a healthy microservices environment, each team is responsible for defining and maintaining contracts for their own services. If a single team or small core group is constantly involved in generating and reviewing contracts for most services, this could indicate that the services are not as autonomous as they should be, pointing to the presence of a distributed monolith.
Inefficient Communication between Teams: Frequent and efficient communication is crucial in a microservices environment, especially between development and business teams. If business teams frequently find themselves blindsided by changes or not understanding the impact of technical decisions, this could indicate a breakdown in communication and service autonomy, which is common in distributed monolith structures.
Impacts on deadlines and efficiency
Delays in Launches: The need for extensive coordination between teams to make changes can lead to significant delays in releasing new features or resolving issues. This is exacerbated in a distributed monolith, where dependencies between services are complex and poorly managed.
Operational Inefficiencies: Redundant effort in maintaining integrations and contracts between coupled services can lead to a significant waste of resources, both human and computational. This negatively impacts operational efficiency and can divert teams' focus from innovation initiatives.
Imagine a financial corporation with multiple development teams working on an asset management system. The "Portfolio Management" team needs to update its service to accommodate new asset types. However, this requires synchronized changes to the "Risk Analysis" and "Reporting" services due to a shared message queue and a common database. Negotiations between teams delay the launch, creating frustration among business stakeholders who expected a speedy launch of new financial products.
The aforementioned issue reflects a scenario where services and contexts go beyond their natural borders, invading domains that do not belong to them. This brings us back to the essence of Domain-Driven Design (DDD) that was discussed previously, which emphasizes the importance of clearly defining the responsibilities and limits of each service, ensuring that each one focuses on its inherent specialty. By adhering to DDD principles, we can avoid the proliferation of distributed monoliths, promoting a more cohesive, modular service architecture aligned with business objectives.
Possible solutions to improve communication
Contracts: Ensure that each service has its own contract, defined and maintained by the team responsible for the service. This promotes independence and facilitates communication between teams. The contexts and limits of each service must be clear, as a service reflects the business unit and its specialties!
Domain-Driven Design (DDD) Practices: Adopt DDD to align service structures with business domains, improving communication between development and business teams and ensuring services reflect business needs.
Culture of Feedback and Continuous Iteration: Promote a culture where feedback between development and business teams is constant and valued, allowing for quick and iterative adjustments to services.
Questions for Reflection
“How can we align our services with business domains to facilitate communication across teams?”
"What tools and practices can promote service autonomy and reduce unwanted coupling?"
"How can we improve our contract definition and management process to ensure the independence of services?"
Avoiding the formation of a distributed monolith requires an ongoing commitment to service independence, effective communication across teams, and the adoption of practices and tools that support a truly decentralized and agile microservices architecture.
And could tests be affected?
Could all of this that we have discussed throughout the article affect the tests? This question is difficult to answer because each system and its available services have a unique and particular context! But I will leave my opinion. To do this, let's go back to the example of order management in an online store.
In this system, we have different services to manage users, orders, payments and shipping. At first glance, these services appear well-defined and independent. However, as the system evolves, the lines between these services begin to blur. Updates to one service require coordinated changes to others, and the database, instead of being segregated by service, becomes a shared tangle of interrelated tables.
At this point, the complexity of the tests begins to reveal itself. Contract testing, designed to ensure that interactions between services remain consistent and predictable, becomes a challenge. What should be a simple interface check now requires a deep understanding of the changes cascading through the system. A change to the ordering service, for example, may unexpectedly affect the shipping service, requiring a battery of integration tests not only within the modified service, but also across all services that, in some way, depend on it.
This interdependence complicates not only the execution of tests, but also their maintenance. Tests that were previously isolated within a service context now need to be updated in response to changes in other services, increasing maintenance effort and the risk of errors. Integration tests, in particular, become laborious exercises, trying to simulate the complete production environment, with all its interconnected services, to ensure that the system as a whole works as expected.
Additionally, a lack of clarity around service boundaries can lead to tests that do not adequately cover usage scenarios. Fields and columns in shared databases can be modified or interpreted differently by different services, leading to inconsistencies that are only discovered during integration testing - or worse, in production. This not only delays development, but also undermines confidence in the quality of the system.
Unexpected behaviors become frequent visitors, manifesting themselves in ways that defy initial logic. It may be that a test passes when run in isolation within a service, but fails when the system is tested as a whole. These undesirable behaviors are symptoms of a design that, while it may have started with the intention of creating independent microservices, has slid into the complexity of a distributed monolith.
But then how to mitigate these risks? We can start spotting the signs and taking action before we enter monolithic distributed hell. There are strategies focused on reinforcing independence and clarity in interactions between services. Here are five straightforward strategies for maintaining test integrity:
Test Isolation with Mocks and Stubs: Use mocks and stubs to simulate interactions between services in tests. This allows each service to be tested in isolation, without directly depending on other services. By mocking external dependencies, you can verify the behavior of the service in question in a controlled and predictable manner, reducing the risk of unexpected failures due to external complexities.
Clear, Tested Service Contracts: Implement contract tests that validate interactions between services. Tools like Pact or Spring Cloud Contract can automate checking that interactions between consumers and service providers comply with defined contracts. This helps ensure that changes to one service don't break the expectations of dependent services.
Segmented Integration Testing Strategies: Instead of trying to test the entire system integration at once, break integration tests into smaller, more manageable segments, focusing on specific interactions between services. This not only makes tests clearer and easier to maintain, but also helps you quickly identify the source of a problem.
Independent Test Environments: Maintain independent test environments for each service, allowing teams to test their changes in isolation before integrating with the larger system. This facilitates early detection of problems and minimizes the impact of developing changes on other services.
Conclusion
As we navigate the intricate maze of systems architecture, the distinction between authentic microservices and disguised distributed monoliths becomes crucial, not only for the technical health of our platforms, but also for the agility and resilience of our organizations. Chris Richardson eloquently reminds us that inadequate decomposition of systems does not move us away from monolithism; rather, it drags us into a more insidious version of it – the distributed monolith.
The true essence of a microservices-based architecture lies in its ability to fragment complexity into manageable, autonomous units, each encapsulating a distinct facet of business logic. When this autonomy is compromised by overly coupled integrations, we lose not only technical agility, but also the ability to innovate and respond quickly to changing market needs.
Therefore, as we aspire to design systems that are truly modular and decentralized, we must be constantly vigilant for signs of coupling and hidden dependencies that threaten this modularity. The goal is not just to avoid building a distributed monolith, but to ensure that each microservice can flourish in its own ecosystem, contributing to the overall robustness and adaptability of the system.
To conclude, the path to an effective microservices architecture is continuous and full of learnings. It is a journey that requires not only a deep understanding of design and architectural principles, but also a willingness to adapt and evolve those principles as new challenges and understandings emerge. By remaining committed to clarity, modularity, autonomy, and boundaries, we can unlock the true potential of microservices and lead our organizations into a more agile and resilient future.
There are situations where it is really necessary or viable.
Sam Newman even comments on this point in his book Creating Microservices - 2nd Edition.
It is important to distinguish, however, integrations between different business units or between the company and its external customers. In these cases, adjustments resulting from changes to a service are natural and are part of the integration process between systems that, by nature, operate independently. Such adjustments are generally managed through well-defined interface contracts, which clearly establish expectations and requirements for interaction between the systems involved.
On the other hand, within the same business unit, the need for constant synchronization and reciprocal adjustments between services that should work independently signals a flaw in the architectural design. This scenario suggests that, despite the physical distribution of services, there is an unwanted fusion of responsibilities and dependencies, characteristic of a monolith in which the components are inseparable and interdependent. Such a configuration significantly complicates the maintenance, scalability and evolution of the system, contradicting the fundamental objectives of microservices architecture.