

Precisamos conversar sobre Arquitetura Orientada a Eventos
Emitir evento não é o fim da conversa. É o começo da bagunça se você não souber o que está fazendo.

"Emitir evento e sair andando" não significa estar desacoplado de verdade.
Um dos grandes atrativos da arquitetura orientada a eventos (EDA) é o tal desacoplamento. E sim, ela oferece uma liberdade muito maior do que os modelos tradicionais de requisição e resposta.
No modelo tradicional, se o serviço A precisa do serviço B, ele faz uma chamada direta:
“Oi B, preciso que você aprove esse pagamento AGORA.”
E aí A fica esperando uma resposta de B. Se B estiver fora do ar, travado ou lento, A também falha. Esse é o famoso acoplamento temporal: se um não responde, o outro não segue. É um relacionamento dependente, quase um namoro codependente entre serviços. 😅
EDA promete o quê?
Na EDA, o serviço A simplesmente emite um evento, como por exemplo:
Evento: PagamentoAprovado
E segue sua vida.
Ele não sabe:
Quem vai escutar esse evento
O que cada um vai fazer com ele
Quando vão reagir (se é que vão)
Isso parece lindo:
“Olha só, o A não precisa mais conhecer ninguém. Tá tudo desacoplado!”
Mas… será mesmo?
Tecnicamente, sim.
Esse é o que chamamos de desacoplamento técnico:
A não conhece B
Não há chamadas diretas
Não há tempo de resposta exigido
Os serviços podem escalar separadamente
Mas do ponto de vista de negócio, o buraco é mais embaixo.
O desacoplamento lógico é outra conversa
Vamos imaginar o seguinte cenário prático:
O Serviço A aprova o pagamento de um pedido.
Ele publica um evento
PagamentoAprovado.A lógica de negócio diz que, após o pagamento aprovado, o pedido deve ser faturado automaticamente.
Quem fatura o pedido?
Um Serviço B, que escuta o evento e executa essa tarefa.
Agora pense:
Se ninguém estiver ouvindo o evento...
Se o Serviço B estiver fora do ar...
Se o handler quebrar silenciosamente...
O pedido nunca será faturado e o Serviço A nunca saberá que algo deu errado.
Esse é o ponto: o desacoplamento lógico não aconteceu
Mesmo sem chamada direta, o Serviço A depende do Serviço B para completar o fluxo de negócio. É como se A dissesse:
“Eu não te conheço, mas tô contando que você vai fazer sua parte.”
Ou seja:
A execução está desacoplada
Mas a responsabilidade do negócio continua interligada
Desacoplamento lógico significa que o sucesso do negócio não depende da reação de outro serviço. E isso, na prática, é muito mais difícil de alcançar do que parece.
Uma analogia simples
Imagine uma cafeteria. O atendente (Serviço A) coloca um pedido no balcão com um aviso:
“Pedido pronto para entrega.”
Ele não fala com o entregador (Serviço B), só deixa ali.
Se o entregador não pegar o pedido:
O cliente nunca recebe.
O atendente nem sabe que o pedido ficou lá.
Tudo funcionou "tecnicamente", mas a experiência do cliente quebrou.
Esse é o risco de confiar demais no “emitir e esquecer”.
A ilusão do 100% desacoplado
Muitos arquitetos caem nessa armadilha:
confundem baixo acoplamento técnico com independência real de negócio.
Mas a verdade é que um serviço pode não conhecer nenhum outro, e ainda assim depender deles para cumprir o que prometeu.
O Acoplamento Semântico Disfarçado
Um dos erros mais sutis e perigosos em arquiteturas orientadas a eventos é o acoplamento semântico. Ele não aparece em gráficos nem em chamadas diretas, mas está ali, escondido no que cada serviço “espera” que um evento signifique.
Vamos a um exemplo bem comum: um evento chamado ClienteAtualizado.
Na teoria, parece ótimo:
“Sempre que um cliente for atualizado, todos os serviços interessados ficam sabendo.”
Mas, na prática, cada serviço interpreta esse evento de um jeito diferente:
O Serviço de Marketing usa esse evento para atualizar listas de e-mail. Ele assume que o campo
emailsempre estará presente.O Serviço de Entregas precisa do campo
endereco.cidadepara atualizar a rota de envio e espera que ele nunca venha nulo.O Serviço de Compliance só considera a atualização válida se o
CPFjá tiver sido verificado e presume que isso já aconteceu toda vez que o evento é emitido.
Esses serviços não conversam diretamente entre si. Cada um escuta o evento e age com base no que acredita que ele significa.
A mudança que quebra tudo (sem ninguém perceber)
Agora imagine que o time responsável pelo evento ClienteAtualizado muda uma regra interna:
Antes, o evento era emitido somente quando informações críticas eram alteradas como endereço ou CPF. Agora, ele passa a ser emitido sempre que qualquer campo mudar, até mesmo algo irrelevante como o número do telefone.
E o que acontece?
O Serviço de Marketing começa a atualizar e-mails mesmo quando eles nem mudaram ou pior, sobrescreve com dados antigos.
O Serviço de Entregas quebra porque o campo
cidadeagora vem vazio (afinal, o endereço não mudou só o telefone).O Serviço de Compliance interpreta que o cliente passou por verificação de dados, mas isso não é mais verdade.
O evento foi emitido. Os consumidores o processaram. Nenhum erro de rede, nenhuma exceção visível. Mas... o sistema agora está logicamente inconsistente.
O que é acoplamento semântico, afinal?
É quando serviços não estão conectados diretamente, mas ainda dependem do significado do que o outro envia.
Você acha que está desacoplado, porque ninguém chama ninguém diretamente.
Mas na verdade, todo mundo está acoplado ao “intuito” daquele evento.
E se esse significado muda, tudo quebra silenciosamente.
O efeito dominó dos eventos centrais
Eventos “famosos” como PedidoCriado, PagamentoRecebido ou ClienteAtualizado geralmente são consumidos por vários serviços.
E aí mora mais um problema:
qualquer pequena mudança nesse evento pode causar um estrago em cadeia.
Renomeia um campo? Alguém quebra.
Muda o formato de uma data? Outro interpreta errado.
Adiciona um campo obrigatório sem valor default? Dá exceção no deserializador.
E o pior: você nem sempre sabe quem consome esse evento.
A EDA não exige que isso seja documentado. Parece liberdade, mas vira dívida técnica invisível.
Um bilhete na praça
Pense nos eventos como bilhetes deixados em um mural público.
Você escreve algo, deixa lá, e segue seu caminho.
Você não sabe quem vai ler… mas o que você escreveu pode mudar o que essas pessoas farão no dia delas.
Por isso, o fato de você não saber quem está ouvindo, não te isenta da responsabilidade sobre o que está sendo dito.
E é justamente aqui que começam os problemas com eventos mal projetados.
Eventos Anêmicos e o Desespero do Payload Genérico
“event_ocorreu” com 80 campos no JSON? Isso não é evento, é uma gambiarra síncrona disfarçada.”
Vamos imaginar uma situação real do dia a dia: você está numa empresa grande e recebe um e-mail com o seguinte título:
Assunto: "Ação realizada com sucesso"
Aí você abre o e-mail, e o corpo diz:
"Foi feito. Veja os detalhes abaixo."
...e vem um anexo com 80 páginas.
Você não sabe quem fez, o que fez, por que fez, quando fez, nem o que você deveria fazer com essa informação. Só sabe que “algo aconteceu”. Agora é você quem precisa escanear todo aquele PDF, tentar entender o contexto, identificar se precisa reagir ou se pode ignorar.
Esse e-mail é o equivalente a muitos eventos emitidos por aí.
Eventos anêmicos: o que são?
Eventos anêmicos são aqueles que não carregam semântica clara.
São genéricos, ambíguos, e jogam a responsabilidade de interpretação para quem consome.
Você já viu algo assim?
{
"event": "event_ocorreu",
"payload": {
"id": 123,
"nome": "João",
"email": "joao@email.com",
"cpf": "123.456.789-00",
"dataCriacao": "2023-05-01",
"ultimaAtualizacao": "2025-08-06",
...
// outros 70 campos
}
}Sem eventName, sem contexto, sem motivo aparente. Um event_ocorreu que tanto pode ser uma criação, uma atualização ou uma remoção. E o consumidor? Que se vire.
Qual o problema disso?
1. Você força o consumidor a ser mágico
Ele precisa “adivinhar” o que está acontecendo.
Precisa comparar valores atuais com anteriores, ou aplicar lógica de negócio para deduzir que foi uma atualização e não uma criação.
O evento não tem intenção. Ele é só um pacote de dados.
E evento sem intenção não é evento é só ruído.
2. Você perde clareza e aumenta a complexidade
Quanto maior e mais genérico o payload, mais difícil fica para outros serviços entenderem o que realmente mudou, e se devem ou não reagir.
Serviços começam a colocar lógica do tipo:
if (payload.email !== previousEmail) {
// então isso é uma atualização importante
}Ou pior:
if (payload.status === '2' && payload.tipo === 'A') {
// então é um evento válido para mim
}Isso cria acoplamento por inferência. Cada serviço precisa interpretar os dados com base em suposições internas, o que explode a complexidade e dificulta a manutenção.
3. Você expõe dados desnecessários ou sensíveis
Num payload de 80 campos, a chance de expor informação confidencial ou irrelevante é alta. Alguns consumidores nem deveriam ter acesso a certos campos (como CPF ou dados financeiros), mas como o evento é “genérico”, todo mundo recebe tudo.
Isso quebra princípios de segurança, privacidade e isolamento de domínios.
Eventos ricos em intenção, enxutos em forma
Um bom evento é semântico, explícito e focado.
Ele diz claramente o que aconteceu, por que aconteceu e qual foi o contexto da ação.
Por exemplo:
{
"eventName": "ClienteAtualizado",
"context": "PortalCliente",
"statusReason": "AtualizacaoDeEndereco",
"payload": {
"clienteId": 123,
"cpf": "2200088818"
"novoEndereco": {
"cidade": "Belo Horizonte",
"uf": "MG"
}
},
"timestamp": "2025-08-06T14:32:00Z"
}
Esse evento comunica:
O que aconteceu: Um cliente foi atualizado.
Onde aconteceu: Pelo Portal do Cliente.
Por que aconteceu: Por causa de uma atualização de endereço.
Quais dados são relevantes: Somente o endereço, e não o CPF, e-mail, RG ou qualquer outra coisa irrelevante.
Por que eventName, context e statusReason são importantes?
eventName: define a ação semântica. Torna o evento identificável e documentável.context: informa onde ou em qual fluxo esse evento foi gerado. Isso ajuda outros serviços a entenderem se devem reagir ou ignorar.statusReason: explica a motivação da emissão. Evita ambiguidades, dá rastreabilidade e melhora observabilidade.
Com esses campos, você transforma um pacote opaco de dados em uma mensagem clara de intenção.
Produtividade e manutenibilidade agradecem
Ao criar eventos com semântica clara, seus consumidores:
Não precisam interpretar dados — só reagir a ações claras.
Conseguem evoluir de forma independente, já que entendem o que o evento significa sem depender de lógica oculta.
Reduzem o risco de bugs silenciosos causados por inferências erradas.
Têm uma melhor observabilidade — porque logs, dashboards e alertas podem ser construídos com base em
eventNameestatusReason, e não em campos genéricos.
E o contrário? Um “evento” com todos os dados da entidade?
Isso é só uma API disfarçada de evento.
Você está emitindo um dump1 da entidade esperando que outros sistemas montem lógica em cima dela. Ou seja, você não desacoplou nada e apenas mudou o lugar onde o acoplamento acontece.
✅ Resumo:
Evento bom tem nome, tem motivo, tem foco.
Evite payloads gigantescos e genéricos.
Prefira eventos ricos em intenção, mesmo que enxutos em forma.
Campos como
eventName,contextestatusReasonnão são burocracia, são investimentos em clareza, rastreabilidade e autonomia entre serviços.
Actions vs Events: Quem faz o quê nessa história?
Em uma arquitetura orientada a eventos, falamos muito sobre eventos, o que aconteceu, quem emitiu, quem escutou, e o que fazer com isso. Mas pouco se fala sobre as ações que originam esses eventos. E isso pode causar confusão conceitual e técnica.
Vamos esclarecer:
🔁 Toda ação pode gerar um evento.
📣 Mas nem todo evento representa diretamente uma ação.
O que é uma Action?
Uma Action (ou Ação) é uma intenção ativa de mudança. É o "comando" que parte de um agente (humano ou sistema) para provocar uma reação.
Exemplos:
O cliente clicou em "Atualizar Endereço"
Um operador aprovou um pagamento manualmente
Um cron job do sistema iniciou o processo de conciliação
Essa ação não é observável diretamente pelo restante do sistema — ela dispara uma cadeia de eventos, que sim, serão percebidos e reagidos.
E o que é o Evento, então?
O Evento é o registro do que realmente aconteceu como consequência de uma ação (ou de outra cadeia de eventos).
Continuando os exemplos:
EnderecoAtualizadoé o evento resultante da ação "Atualizar Endereço"PagamentoAprovadoé o evento disparado após a ação de aprovaçãoConciliaçãoIniciadapode ser um evento emitido quando o job do sistema começa a rodar
O evento é uma mensagem de fato. Algo ocorreu. E outros serviços podem reagir a isso.
Então: A ação dispara o evento — e não o contrário.
Isso é importante. Eventos não devem ser confundidos com comandos.
Ação = "Quero que algo aconteça"
Evento = "Isso aconteceu"
E se quisermos salvar um histórico? Vale salvar as Actions?
Sim e pode ser extremamente útil para rastreabilidade, auditoria e analytics.
Persistir ações pode trazer clareza sobre intenção do usuário, frequência de operações, fluxos iniciados, erros de tentativa, etc.
Por exemplo, imagine uma tabela ActionHistory:
Essa tabela armazena ações tomadas por alguém (ou algo). Ela é diferente da tabela de eventos, que pode armazenar:

Mas por que salvar as Actions além dos Eventos?
A ação carrega a intenção, mesmo que falhe.
O evento carrega a consequência, caso tenha sucesso.
Juntas, elas contam a história completa.
Exemplo:
Ação: Cliente tenta atualizar o endereço →
Evento:
EnderecoAtualizadoemitido com sucesso
Ou:
Ação: Tentativa de atualizar o endereço →
Evento: Nenhum emitido (porque falhou na validação)
Você só vai saber que a tentativa existiu se registrar a action também.
O que persistir em uma tabela de histórico de Actions?
actionId: identificador únicoactionType: nome da ação (ex: "AtualizarEndereco")timestamp: quando foi feitauserIdousource: quem executoucontext: de onde veio (ex: Portal, API externa, cron job)status: sucesso, falha, pendenterequestPayload: os dados enviadoserrorMessage(opcional): se falhou, por quê?
Dê nome aos bois 😅
Ação é intenção,
Evento é consequência,
Uma arquitetura orientada a eventos fica mais rica e mais auditável quando a gente entende essa separação,
E sim, persistir ações é saudável, especialmente em sistemas críticos, financeiros, operacionais ou regulados,
É legal e importante a gente entender todos esses assuntos, talvez o diagrama abaixo possa ajudar também:
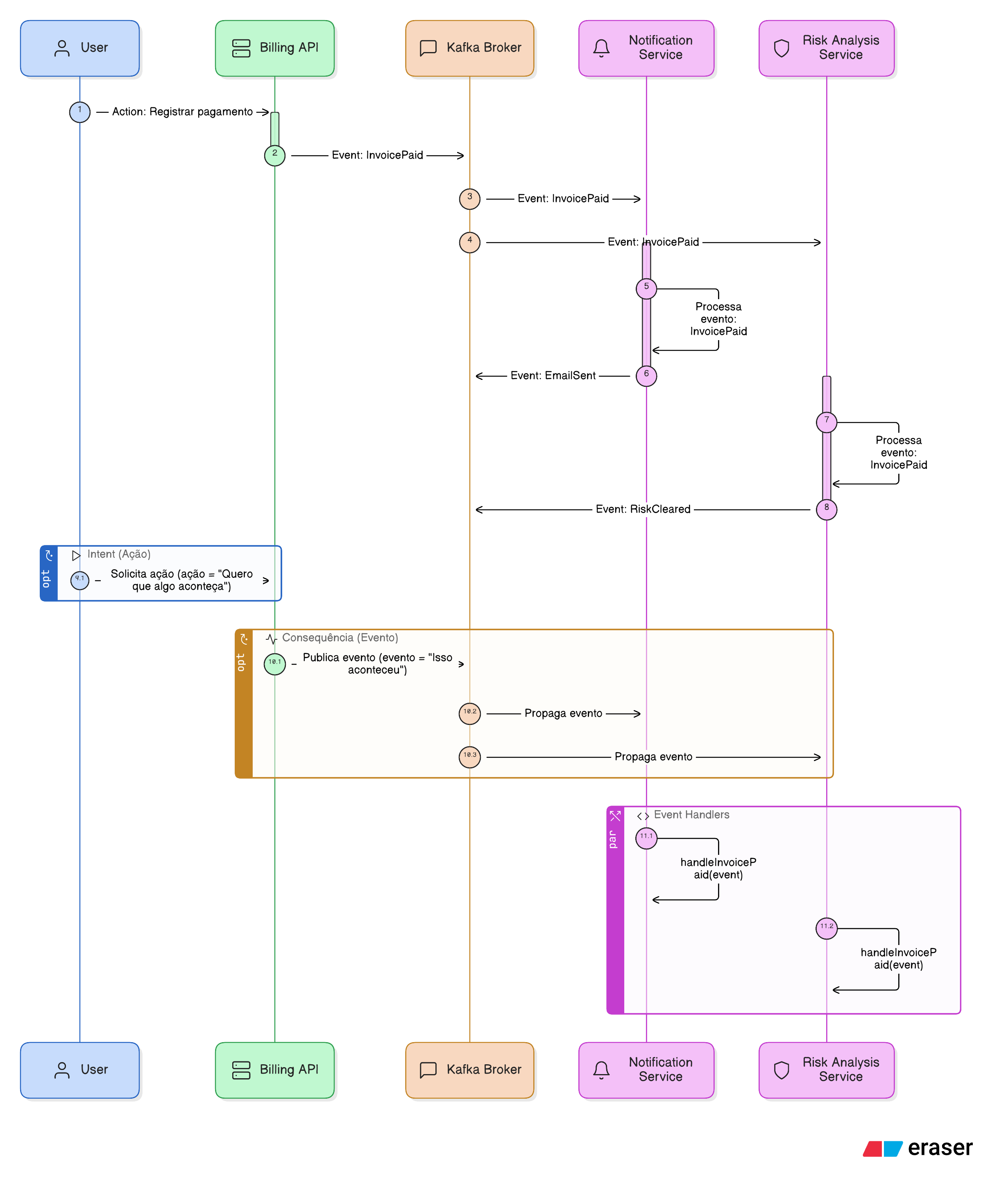
Handler: o profissional que atende a chamada do evento
Agora que você já entendeu a diferença entre ação (a intenção) e evento (o que aconteceu), está na hora de conhecer quem realmente faz algo com o evento: o handler.
Pense no evento como o telefone tocando.
O handler? É quem atende e faz algo útil com a ligação.
O que é um Handler, afinal?
Em uma arquitetura orientada a eventos, um handler é a unidade de lógica responsável por responder a um evento específico.
Quando um serviço escuta um tópico ou canal de eventos (ex: Kafka, RabbitMQ, SNS), ele precisa saber o que fazer quando um determinado evento chegar.
Essa responsabilidade fica centralizada em uma função ou classe chamada handler.
Ou seja:
O evento carrega a informação: "algo aconteceu".
O handler recebe esse evento e decide: "o que faço com isso?"
Onde ele aparece no código?
No mundo real, você pode encontrar um handler como:
class PedidoCriadoHandler {
async handle(event: PedidoCriadoEvent) {
// lógica para atualizar estoque, enviar e-mail, etc.
}
}Ou como uma função registrada em um consumidor Kafka, por exemplo:
kafkaConsumer.on('PedidoCriado', async (event) => {
// esse bloco é o handler na prática
});O ponto-chave é: o handler contém a lógica de reação a um evento específico.
Onde os programadores se confundem?
Handler não é service
Muitos confundem handler com service.
O handler usa um service, mas não é o lugar de ter regras de negócio profundas.
Ele deve delegar a lógica pesada para camadas apropriadas (ex: application service, use case, domain).
Handler não é o publisher
Alguns colocam lógica de publicação de eventos dentro de um handler — e isso pode ser perigoso se não estiver claro qual evento é resposta de qual ação.
Um handler deveria reagir a um evento, e se emitir outro evento, isso deve ser bem justificado e claro no design.
Handler não é repositório de lógica genérica
Colocar múltiplos eventos diferentes em um único handler é uma receita para o caos.
O ideal é um handler por tipo de evento, com responsabilidades únicas e bem definidas.
Papel do Handler na arquitetura orientada a eventos
O handler é o elo entre o evento passivo e a reação ativa.
Ele deve:
Ser especializado em um único evento
Ser fácil de testar isoladamente
Ser transparente: dado o evento, a reação deve ser clara
Delegar as decisões de negócio para as camadas corretas (use case, domain)
Ele não deve:
Tomar decisões fora do seu escopo
Acessar dados aleatórios para “complementar” o evento
Ser um lugar onde se faz tudo que sobrou
Uma analogia rápida
Imagine um botão de alarme de incêndio.
Quando alguém aperta (ação), isso dispara um alarme (evento).
Quem escuta o alarme? Os bombeiros.
O handler é o bombeiro de plantão. Ele não decide se houve incêndio nem emite o alarme, ele reage ao alarme e executa a ação necessária, como evacuar o prédio ou ligar os sprinklers2.
Se o bombeiro tiver que analisar 40 tipos de alarmes diferentes, sem saber qual é qual, a resposta vai ser confusa e atrasada. Cada alarme precisa de um handler preparado e treinado para aquele tipo específico de ocorrência.
✅ O que você precisa lembrar sobre handlers
Um handler é quem reage a um evento e decide o que fazer com ele.
Ele deve ser focado, claro, testável e isolado.
Não misture papéis: handler não é service, controller ou publisher.
Ele é o ponto de entrada para a reação ao evento, e deve ser simples, explícito e bem nomeado.
Claro! Vamos continuar com esse próximo tópico do artigo, agora abordando os perigos do excesso de eventos em uma arquitetura orientada a eventos. O estilo segue o mesmo: técnico, com analogia clara, conversado e provocativo.
Quando Tudo é Evento, Nada é Importante 🧨
Nem todo dado que muda é um evento digno de publicação.
Se cada coceira no sistema vira um “evento”, em pouco tempo você está gerenciando uma arquitetura que parece um organismo com hiperatividade sensorial: sente tudo, reage a tudo, mas não sabe o que é realmente importante.
E isso, meu caro leitor, não é arquitetura — é caos com nome bonito.
O problema do excesso de granularidade
Vamos imaginar uma entidade Cliente com os seguintes campos:
nome
telefone
e-mail
cidade
data de nascimento
Agora imagine que, a cada alteração em qualquer campo, seu sistema emite um evento específico:
ClienteNomeAlteradoClienteTelefoneAlteradoClienteEmailAlteradoClienteCidadeAlteradaClienteDataNascimentoAlterada
E sim, todos esses eventos vão parar no mesmo tópico Kafka.
E todos os serviços que escutam esses eventos... precisam decidir o que fazer com eles.
Resultado:
Serviços reagem a mudanças que não são relevantes para eles
Handlers precisam de lógica condicional para ignorar o que não importa
A fila fica poluída com ruído
O custo de observabilidade aumenta
A performance pode cair por causa de mensagens inúteis
Você cria uma avalanche de eventos irrelevantes, e no meio dela, o que é realmente importante passa despercebido.
Analogia: um sistema nervoso sem cérebro
Imagine um corpo humano que sente tudo com extrema sensibilidade — uma coceira, um vento, um fio de cabelo encostando — e reage fortemente a cada estímulo.
Agora tire o cérebro da equação.
O corpo reage a tudo, mas sem contexto, sem discernimento, sem prioridade.
Esse é o risco de um sistema com eventos demais e sem curadoria:
Você transforma sua arquitetura em um sistema nervoso sem cérebro.
Ou seja, você sente, dispara e processa… mas não pensa.
Sinais de que seu sistema está “reativo demais”
Handlers que fazem
ifpara ignorar 90% dos eventosLogs e dashboards cheios de eventos de “telefone alterado” ou “cor do botão clicado”
Services com alertas falsos por causa de eventos irrelevantes
Testes quebrando porque qualquer mudança de campo gera uma tempestade de notificações
O que fazer então?
Suba o nível de semântica
Em vez de eventos “microscópicos” como
TelefoneAlterado, pense em eventos que carregam intenção de negócio:ClientePreferenciasAtualizadasContatoPrincipalModificado
Agrupe eventos contextualmente
Agrupe alterações que fazem sentido em conjunto em eventos compostos e significativos.
Tenha critérios claros de publicação
Nem toda mudança de estado justifica um evento.
Tenha uma política: “Esse evento é útil para algum consumidor? Ele representa uma decisão de negócio?”
Evite "eventos de auditoria disfarçados"
Se o objetivo é rastrear mudanças, use logs de auditoria, não eventos em tempo real.
Publicar eventos demais sem objetivo e necessidade, não te dá mais controle, te dá mais confusão. Na dúvida, pense assim:
O evento comunica algo que importa para outros serviços?
Ele representa uma intenção de negócio, ou é só um espasmo do sistema?
Lembre-se caro leitor: eventos são sinais de significado, não notificações de qualquer alteração. Se tudo é evento, nada mais é prioritário e aí sua arquitetura não está sendo orientada a eventos, está sendo soterrada por eles.
Reprocessar Eventos Não é Tão Simples Quanto Parece
Reemitir um evento antigo pode ser um desastre se o sistema não for idempotente.
A ideia de "reemitir eventos antigos para corrigir dados" pode soar simples na teoria:
“É só dar replay nos eventos e deixar os serviços reconciliarem o estado.”
Mas em uma arquitetura orientada a eventos, essa operação exige maturidade.
Se não houver idempotência, controle de duplicidade e versionamento consciente, esse replay pode causar duplicações de efeitos colaterais, inconsistências silenciosas e falhas difíceis de rastrear.
Por que reprocessar eventos é tão delicado?
Imagine que um serviço recebe novamente um evento de PagamentoConfirmado.
Se ele não for idempotente, ele pode:
Gerar uma nova ordem de entrega
Reenviar e-mails de confirmação
Deduzir estoque novamente
Atualizar status já processado
Reprocessar sem cuidado transforma uma arquitetura desacoplada em uma fonte de efeitos colaterais imprevisíveis — e o pior: muitas vezes silenciosos.
O que é idempotência e por que você precisa dela
Idempotência significa:
“Executar a mesma operação mais de uma vez não muda o resultado final.”
No mundo de eventos:
Um evento processado duas vezes não deve gerar efeitos colaterais duplicados
Isso vale especialmente para ações como pagamentos, notificações, atualizações de status
Como garantir idempotência (sem acoplar no handler)
A lógica de idempotência não deve morar no handler.
Ela deve ser responsabilidade de um componente reutilizável — como um serviço de orquestração, um decorator, ou até infraestrutura de mensageria que controle:
Se o
eventIdouidempotencyKeyjá foi processadoQual foi o resultado da última execução
Se deve ignorar, repetir ou compensar
O handler só deve fazer seu trabalho se o evento for considerado "novo ou válido" para ser processado.
E quanto ao versionamento de eventos?
Outra armadilha comum no replay de eventos é processar versões antigas de forma cega.
Imagine que um handler moderno espera campos obrigatórios que não existiam na versão 1 do evento. Se ele receber esse evento e tentar tratá-lo como versão atual, você pode quebrar o sistema.
Por isso, todo evento deveria carregar um campo
version, e isso não deve ser tratado no handler cruamente, mas em serviços que sabem como interpretar ou traduzir cada versão.
Práticas que podem ajudar:
✅ Garanta idempotência com um serviço externo
→ Use tabelas de ProcessedEvents com eventId para evitar duplicidades
✅ Controle versionamento com responsabilidade clara
→ Não jogue o if (version === x) no handler —
→ Crie um EventVersionRouter ou uma entidade de domínio que saiba se adaptar à versão
✅ Tenha um mecanismo de replay testável
→ Evite replay direto em produção sem simulação
→ Garanta que múltiplos handlers possam consumir replays sem efeito colateral
✅ Inclua eventId, idempotencyKey e version em todos os eventos
🚨 Replay sem planejamento pode virar um monstro
O que parece uma simples reemissão de evento pode:
Disparar efeitos em cadeia que não deveriam ocorrer de novo
Criar inconsistências entre serviços que processam eventos de maneiras diferentes
Gerar comportamentos inesperados em sistemas que evoluíram semanticamente
Reprocessar eventos exige mais engenharia do que impulso.
É necessário projetar a arquitetura desde o início com idempotência e versionamento em mente, caso contrário, cada replay vira uma roleta russa.
O handler deve delegar.
Quem garante que o evento é válido, processável, atual ou duplicado...
é a infraestrutura, os serviços auxiliares e os contratos bem definidos.
Se não for assim, seu sistema orientado a eventos vira orientado ao pânico.
Eventos Sem Dono e a Governança Esquecida
Quem define a estrutura? Quem versiona? Quem garante que isso não vai mudar amanhã?
Eventos são como correspondências no correio de um sistema distribuído: alguém escreve, alguém recebe.
Mas e se ninguém souber quem escreveu, o que estava dentro, qual era o formato esperado ou por que a carta foi enviada?
Sem governança, eventos deixam de ser fontes confiáveis de informação e viram mensagens enigmáticas voando no escuro.
Quando eventos viram terra de ninguém
Arquiteturas orientadas a eventos costumam nascer com entusiasmo:
"Vamos publicar tudo! É assíncrono, escalável, bonito!"
Mas à medida que o sistema cresce, uma pergunta começa a assombrar o time:
Quem é responsável por esse evento aqui?
Posso alterar esse campo?
Alguém ainda consome isso?
Tem outro serviço emitindo o mesmo evento com estrutura diferente?
E aí você percebe:
não há contratos claros. Não há dono. Não há visibilidade.
❌ O que acontece quando não há governança
Times diferentes publicam eventos com o mesmo nome, mas com estrutura e semântica diferentes
Consumidores quebram silenciosamente porque um campo sumiu ou mudou de tipo
Eventos são alterados sem versionamento, causando inconsistência entre ambientes
Ninguém sabe se pode remover ou descontinuar um evento
Eventos viram APIs internas disfarçadas, com dados superdimensionados e sem contexto semântico
Eventos não são “payloads genéricos” — são contratos de domínio
Se você não trata eventos como contratos formais, você está criando o mesmo problema que APIs sem OpenAPI, sem versionamento e sem documentação causam mas agora em tempo assíncrono e distribuído, o que torna tudo pior.
🗂️ Governança exige três pilares fundamentais:
1. Event Schema
Todo evento precisa de um schema claro e versionado, com:
Campos obrigatórios e opcionais
Tipos de dados
Descrições de campos
Valor semântico de cada parte do payload
Pode ser feito com:
JSON Schema
Avro (muito usado com Kafka)
Protobuf
Ou até mesmo TypeScript com validação (para sistemas mais simples)
Sem schema, cada consumidor “acha” o que está chegando. E isso quase sempre dá errado.
2. Event Catalog
Você precisa de um catálogo público de eventos, como uma espécie de “Swagger dos eventos”:
Quais eventos existem
Quem os publica
Quem consome
Qual é a versão atual
Exemplo de payload
Justificativa de negócio
Ferramentas como Backstage, AsyncAPI, ou até Notion/Wiki bem organizado, ajudam muito aqui.
Sem catálogo, cada serviço vira uma caixa-preta com eventos voando pra todo lado.
3. Contrato de Responsabilidade
Cada evento deve ter um dono explícito:
Quem decide quando um novo campo pode ser adicionado?
Quem versiona o contrato?
Quem valida mudanças com os consumidores?
Sem esse “Dono do evento”, tudo é alterável por qualquer time, a qualquer momento e é assim que nascem os bugs que só explodem 3 semanas depois em produção.
A tentação de transformar eventos em APIs internas
Muitos times caem nessa armadilha:
Pegam uma entidade (
Cliente,Pedido,Pagamento)Serializam tudo em um JSON gigante
Publicam um evento chamado
EntidadeAtualizadaEsperam que os consumidores “se virem” com os dados
Isso é acoplamento disfarçado.
Você está expondo o estado interno do seu sistema como se fosse uma API, sem versionamento, sem controle, sem semântica.
Eventos devem carregar fatos relevantes, não entidades inteiras.
Eles devem comunicar “o que aconteceu”, não despejar um banco de dados no tópico Kafka.
Arquitetura orientada a eventos não é só publicar mensagens — é criar uma rede de contratos confiáveis.
Sem governança:
Os eventos perdem valor
Os consumidores vivem no escuro
Os sistemas se tornam frágeis e imprevisíveis
Com governança:
Eventos viram fontes confiáveis de verdade
Mudanças são seguras e versionadas
A comunicação entre serviços é clara, observável e rastreável
Se você não sabe quem manda nos seus eventos, alguém já está sofrendo com isso… você só ainda não percebeu.
Nem Tudo Que É Evento, É Arquitetura
Event-Driven Architecture parece simples à primeira vista.
Você emite um evento, alguém consome, tudo se resolve.
Mas como vimos neste artigo, por trás da beleza do desacoplamento, existe uma série de decisões arquiteturais que não podem ser ignoradas:
Nem todo evento é importante — e muito menos urgente.
Ações e eventos são diferentes — e confundí-los afeta o design do sistema.
Sem idempotência e versionamento, o reprocessamento vira uma armadilha.
Handlers não são lugares para lógica desorganizada.
E principalmente: eventos precisam de dono, contrato, e responsabilidade.
EDA não é sobre “emitir e esquecer”.
É sobre projetar sistemas que saibam ouvir, reagir e evoluir com clareza e confiança.
Um dump, nesse caso, é uma cópia bruta e completa de um objeto ou entidade, jogada em forma de evento, sem curadoria ou intenção clara.
Ou seja, ao invés de emitir um evento com um propósito específico e bem definido (ex: EmailDoClienteAtualizado), você apenas joga um JSONzão no tópico com tudo que existe no banco sobre o cliente.
Conhecidos como chuveiros automáticos, são dispositivos de combate a incêndio que fazem parte de um sistema de proteção contra incêndios.