
Beware of Anemic Domains!
The true essence of object orientation is lost when we settle for anemic domains.

The software development landscape is full of methodologies, standards and practices that emerge with the aim of optimizing processes, improving code quality and, above all, meeting constantly evolving business demands. However, not all of these practices are without criticism or controversy. One of them, which has generated debates among software developers and architects, is the model known as "Anemic Domain".
Characterized by a separation between data and business rules, the anemic domain, at first glance, may seem like a simplified and straightforward approach to software modeling. However, behind this simplicity hide a series of challenges and potential pitfalls that can compromise the robustness, maintainability and evolution of a system.
In this article, we will explore in depth the problems associated with anemic domains, seeking to understand the roots of these challenges and how they can affect software projects in different contexts. We are going to talk a lot about the topic and analyze its weaknesses and the reasons behind the criticism often directed at this approach.
If you like the content, please share and like the post! This helps and encourages me to continue bringing content in text form too!😄
History and Origins: When Domain Models Became “Anemic”
Before we dive into the tumultuous history of anemic domain models, let's understand what domain modeling is. Domain modeling is basically the representation of knowledge and logic related to a specific problem domain. Imagine you are trying to create software for a library. In this case you would have things like "Books", "Loans", "Users", etc. These are concepts from your domain, and how they interact with each other forms the basis of your modeling.
Now, since we're clear on domain modeling, let's address the intriguing term "anemic." When hearing the word "anemic," many people probably remember the last time they felt a little pale and lacking energy after donating blood or having a medical diagnosis related to a lack of iron. In medicine, anemia is a condition in which you don't have enough red blood cells to carry adequate oxygen to the body's tissues. In short: something vital is missing!
So how does this dark and somewhat depressing medical term relate to software? Well, it's basically an apt metaphor! An "anemic" domain model is one that lacks something vital: rich behaviors. These are models that have all the data, but no logic. It's like having a book (the object) with no story inside (the behavior), just words thrown into the wind. Imagine, how tedious it would be to leaf through page after blank page!
Now, you might be asking yourself, "Who in their right mind would create a book without a story?!" And that's where ORM (Object-Relational Mapping) frameworks come in.
There was a time, my friends, when programmers were absolutely enchanted with ORMs. And why wouldn't they stay? These magical little bits of frameworks promised to make data persistence (saving our precious data in databases) as simple as playing with Lego. And they actually delivered on that promise... with a few little gotchas.
The abstraction that ORMs brought made life easier for developers in many ways.1 However, with the almost exclusive focus on data persistence, the line between what was business logic and what was persistence logic started to get a little... blurred. Instead of building robust, behaviorally rich domain models, we started building models that looked more like simple data carriers, perfect for ORMs, but missing the true essence of object-oriented modeling. And so, almost without meaning to, we were mass producing anemic models, as if we were on a car assembly line without engines!
This separation between data and behav iors has started to become the norm. Many developers, intoxicated by the ease of ORMs, have forgotten that the heart of object-oriented modeling is not just about data; it's about capturing behavior, encapsulation, interaction and, well, life!
In short, like most stories involving humans and technology, it started with the best intentions. We took a wonderful tool, ORMs, and maybe we got a little too carried away. In the process, we have set aside some of the most basic principles of object-oriented design, leading to the propagation of anemic domain models.
But don't be discouraged, dear programmer! This is not the end of the story... as anemic models can be cured, and we have many topics to explore!
Characteristics of an Anemic Dominion: When Data Became the Kings and Entities Their Subjects
If I could use an analogy, the current situation of domain modeling in many systems is like a kingdom where data is the king and entities, once proud and powerful, have become mere subjects. In this kingdom, data sits on the throne, and business rules and logic are scattered throughout the castle's corners, hidden in dark rooms and winding corridors. Ah, my dear readers, allow me to tell you more about this peculiar kingdom.
Data-Centered Models
Data-centric models are like two-dimensional puzzles. They have all the bits, but lack the depth. Of course, in some contexts, such as simple CRUD (Create, Read, Update, Delete) applications or highly reporting-focused systems, these models are excellent. They are fast, direct and do not have complex logic to get in the way. It's a bit like using a hammer to hit a nail; simple and effective. But what if you have to deal with a screw?
Business Rules vs. Business Logics
Before diving deeper, let's untangle a tangle that has confused many: the difference between business rules and business logic.
Business rules are the fundamental principles that define the operation of a business. Think of them as the laws of a kingdom. For example, "a customer can only have one active loan at a time" or "all users must have a valid email address."
Business logic is more about how these rules are applied and executed. They are the tactics, the detailed plans and the processes. Using our kingdom analogy, it would be like the protocol of the royal guard when protecting the king.
To visualize this in practice, let's take a closer look at an example:
Imagine an e-commerce system that classifies its users based on the total amount spent in the last month. There are three user levels: Bronze, Silver and Gold. Each level receives a different promotion.
1. Business Rules
We establish the rules for classifying users:
Bronze: Users who spent up to $100 in the last month.
Silver: Users who spent between $101 and $500 in the last month.
Gold: Users who spent more than $500 in the last month.
enum UserTier {
Bronze = "Bronze",
Silver = "Silver",
Gold = "Gold"
}
class User {
email: string;
lastMonthSpending: number;
tier: UserTier;
constructor(email: string, spending: number) {
this.email = email;
this.lastMonthSpending = spending;
this.tier = this.classifyUser(spending);
}
private classifyUser(spending: number): UserTier {
if (spending <= 100) return UserTier.Bronze;
if (spending > 100 && spending <= 500) return UserTier.Silver;
return UserTier.Gold;
}
}Business Logics
Based on user rating, we grant different promotions:
Bronze: 5% discount on your next purchase.
Silver: 10% discount and free shipping.
Gold: 20% off, free shipping and early access to new products.
class UserService {
grantPromotion(user: User): void {
switch(user.tier) {
case UserTier.Bronze:
this.giveDiscount(user, 5);
break;
case UserTier.Silver:
this.giveDiscount(user, 10);
this.giveFreeShipping(user);
break;
case UserTier.Gold:
this.giveDiscount(user, 20);
this.giveFreeShipping(user);
this.giveEarlyAccess(user);
break;
}
console.log(`Promotions granted for ${user.email} with tier ${user.tier}`);
}
private giveDiscount(user: User, percentage: number): void {
console.log(`${percentage}% discount granted to ${user.email}`);
}
private giveFreeShipping(user: User): void {
console.log(`Free shipping granted to ${user.email}`);
}
private giveEarlyAccess(user: User): void {
console.log(`Early access to new products granted to ${user.email}`);
}
}This example well illustrates the difference between rules and business logic. The business rule (classify users) defines the clear criteria that each user must meet. The business logic details the benefits and promotions each classification should receive. Separating the two helps make code more manageable, testable, and easier to understand.
Entities: The Great Forgotten
Our poor entities, once holders of data and behaviors, have been relegated to simple data carriers in many modern systems. In ancient times, entities were powerful, controlling not only their own data, but also how that data could be used and manipulated. Now, in many systems, they are like decorative vases in a palace; pretty to look at, but without a real functional purpose.
Why is this a problem? Because without rich behaviors, entities become, well... anemic. And so, the logic and rules that should be encapsulated within them are often found in services or controllers. This can lead to a scattering of logic, making the system more difficult to maintain and evolve.
The Dispersion of Services
With business logic and rules being moved outside of entities, many systems now have services that are like mini monsters, trying to do everything. This approach can make logic more difficult to find and modify, especially when working in large teams. We will comment even more on these points in a moment!
Example Template
Now, let's look at a domain. Here we have a well-defined domain, centered on a user's email, that encapsulates both data and behavior:
import { Either, left, right } from '@/shared'
import { InvalidEmailError } from '@/entities/errors'
import { valid } from '@/entities/email-validator'
export class Email {
public readonly value: string
private constructor (email: string) {
this.value = email
Object.freeze(this)
}
public static create (email: string): Either<InvalidEmailError, Email> {
if (valid(email)) {
return right(new Email(email))
}
return left(new InvalidEmailError(email))
}
}What we see here is an Email entity that not only stores an email value, but also validates that email when creating an instance. This is an entity rich in behavior. In contrast, an anemic domain would only have the value property and all validation logic would be in some other service or controller.
Before continuing, I want to talk even more about the famous Services.
Beware of Multiple Services: The Problem of Having Too Many Cooks
Let's imagine a kitchen. Not just any cuisine, but that of a renowned restaurant. In this kitchen, we have several chefs, each specialist in their own niche: there is the pasta chef, the meat chef, the dessert chef and so on. Now, imagine if they all tried to make the same dish at the same time. Each chef adding an ingredient here, seasoning there, stirring the pot in his own way. It would be chaos! The resulting food would be intriguing at best and inedible at worst.
This is exactly what happens in many software systems when we move away from behavior-rich entities and allow logic to spread across a variety of services. The "chefs" in this case are the programmers, and the "dish" is our code.
The Seduction of Services
Services, at first glance, seem to be the perfect solution to all our problems. They promise to encapsulate complex logic, be reusable, and make our code "cleaner." However, when we adopt the anemic domain paradigm, many of these services become cluttered with logic, trying to compensate for the absence of behavior in our entities.
But why have so many developers fallen for this approach? The answer may lie in the initial simplicity it offers. Separating data from behavior at first may seem like a logical decision, especially when working with ORM frameworks that encourage this division. Additionally, there is a realization that by putting logic into services, code becomes more modular and therefore easier to manage.
The High Price of Dispersion
However, this approach has its price. When business rules and logic are spread across multiple services, the code becomes more difficult to understand. Imagine having to check five, ten, or even fifteen different services to fully understand a business flow.
Furthermore, testing this code is a herculean task. Each service can have its own dependencies, and mocking them all for unit testing can be exhausting. The irony? One of the arguments for this approach was precisely the ease of testing!
It does not stop there. When rules are scattered, there is a real risk that some of them will be implemented incorrectly or even forgotten. In the business world, this can translate into financial losses, reputational damage or legal problems.
In practice
Now let's take a look at a fictional example in TypeScript. Imagine we have an anemic User entity:
export class User {
public id: number;
public email: string;
public age: number;
}Given that our entity is anemic, we can have a service to check email validity and another to check age:
class EmailService {
isValid(email: string): boolean {
// email validation logic
}
}
class AgeService {
isAdult(age: number): boolean {
// age validation logic
}
}Looks organized, right? But what if we have to add more rules, like checking if a user can sign up for a certain course or if they can get a discount at a store? We would have to create more and more services, each containing a small piece of the overall logic.
Contrast this with a behavior-rich entity:
export class User {
public id: number;
public email: string;
public age: number;
isEmailValid(): boolean {
// email validation logic
}
isAdult(): boolean {
// age validation logic
}
}Here, all user-related logic is contained within the User class itself.
In summary, while services have their place in software architecture, we must be careful not to make them "mini monsters" that try to do everything, especially at the expense of anemic entities. This is a slippery slope that can lead to code that is difficult to manage, understand, and test. And as we always hear: "Too many chefs ruin the soup!"
Problems Associated with No-Behavior Domains: When Technology Becomes a Frankenstein
Object Orientation (OO) has always been like an elegant masquerade ball: everything has its place, its responsibilities and, of course, its elegance. Now, imagine if, at this ball, instead of skilled dancers, we had clumsy and dull robots. This is exactly the scenario many software projects find themselves in, thanks to behaviorless domains. Here, we will demystify the problems that arise when we neglect the dance of OO (Object Orientation).
Violation of Object Orientation principles: The first and most obvious wound is the brutal violation of the fundamental principles of OO. Encapsulation, one of the crown jewels of OO, is completely disregarded. Instead of protecting our precious data in its respective classes and ensuring it is only accessed or modified in appropriate ways, it is exposed as if it were at an antique fair at the mercy of the highest bidder. This, dear reader, is an affront to what OO stands for. Without encapsulation, our data can change in unexpected and unwanted ways. This is like inviting an elephant into a china shop; the chances of something going wrong are immense.
Difficulty in Refactoring and Evolving Software: Now, a moment of sincerity. Refactoring code is never a task that programmers wake up eager to do, right? But in an anemic domain, refactoring is difficult. With scattered business logic, finding all the points that need to be changed is challenging. And evolve? Well, inserting new functionality in such a scenario is complicated. The result can be a problem that makes everyone uncomfortable.
Compromised Testability: Imagine you are trying to put together a puzzle, but all the pieces are almost identical. Sounds insane, right? This is exactly how it feels when trying to test a domain without behavior. The sparsity of logic makes it extremely challenging to identify what and how to test. Furthermore, without proper encapsulation, ensuring data integrity during testing is an emotional rollercoaster. When logic and data are separated, testing becomes more of a guessing game than systematic practice. Instead of validating clearly defined behaviors, you end up trying to predict every possible scenario in which the data could change. It's like trying to predict the weather in a city that experiences all four seasons in one day. It's not only unpredictable, but also incredibly frustrating.
Let's talk more about how testability is completely compromised when we are in complex contexts.
The Labyrinth of a Behaviorless Domain
The journey of testability in anemic domains can be compared to the experience of someone trying to find their way out of a maze without a clear map. Yes, it's one of those intricate mazes you'd find in amusement parks, with multiple dead ends, twisting paths and, to spice it up even more, some mirrors that distort your image and perception. Let's dive into this analogy.
As you enter the maze, you realize that the walls are incredibly high and that you can't get an overview of what's coming. Without a clear map, you rely on your intuition and try to memorize the paths you've already taken. Now, suppose this maze changes configuration each time you visit it. Frustrating, isn't it? This is the feeling when trying to test domains that lack a clear structure and well-defined behavior.
Testing well-structured software is like having a map of the maze in your hands. You know where to start, which path to take, and where you're likely to encounter obstacles. On the other hand, in a domain without behavior, the logic is so scattered that it is like trying to decipher this maze without any guidance. You find yourself returning to the same points over and over again, not sure if you've covered all the critical areas.
Additionally, testing becomes not only a localization challenge, but also a reliability challenge. Without proper encapsulation, it is as if, when trying to exit the maze, the walls begin to move or disappear, making your exit even more uncertain. Ensuring data integrity during testing becomes an arduous task, as each attempt to find a correct path is hampered by unexpected changes.
And, to add a little salt to the wound, while you're in the middle of this chaotic maze, stakeholders are outside, waiting, watching your progress through a glass window, asking why it's taking so long to "just test" the software." Yes, dear readers, compromised testability is that experience, but with a keyboard and a screen in front of you.
Let's see a practical example of how testability is affected!
In our fictional e-commerce company, we have a class called VoucherService. This class is responsible for validating coupons that users apply to obtain discounts. Validating a voucher involves several steps, such as checking the expiration date, voucher type, geographic restrictions, and so on. However, in a parallel universe where programming is dominated by chaos (i.e. anemic domains), VoucherService has become a monstrosity with scattered and poorly encapsulated validations.
Let's take a look at this class and try to figure out how to test it:
class VoucherService {
// ... other properties
public validateVoucher(voucher: any, userLocation: string): boolean {
// Check voucher type
if (voucher.type === "FESTIVE" && new Date().getMonth() !== 11) {
return false; // because it's only valid in December
}
// Oh! We need to validate the expiry date too
if (new Date() > new Date(voucher.expiryDate)) {
return false;
}
// Oops! Almost forgot. There are location-based vouchers
if (voucher.restrictedTo && voucher.restrictedTo !== userLocation) {
return false;
}
// ... more scattered validations
return true;
}
}Tests:
import { VoucherService } from './VoucherService'; // assuming path
describe('VoucherService', () => {
let service: VoucherService;
beforeEach(() => {
service = new VoucherService();
});
test('should validate festive voucher', () => {
const voucher = {
type: 'FESTIVE',
expiryDate: '2023-12-31',
// ... other properties
};
expect(service.validateVoucher(voucher, 'US')).toBeTruthy();
});
// ... More tests for each condition
});What are the problems?
Scattered validations: As seen, our function has a series of validations, and each of them is a potential point of failure. The above test only covers one scenario. To cover all scenarios, we would have to write tests for each if condition, making our test suite extensive and confusing.
Date dependency: Validation of the "FESTIVE" type is sensitive to the current month. This means that our test above would only pass in December! Without injecting a date dependency (e.g. a Clock), testing this function throughout the year would be a nightmare.
Poor encapsulation: Because validation details are scattered, it is easy to miss or forget some validations. If, in the future, we decide to add more validation logic or change existing ones, maintenance becomes complex.
We can clearly see this occurring in the diagram below:
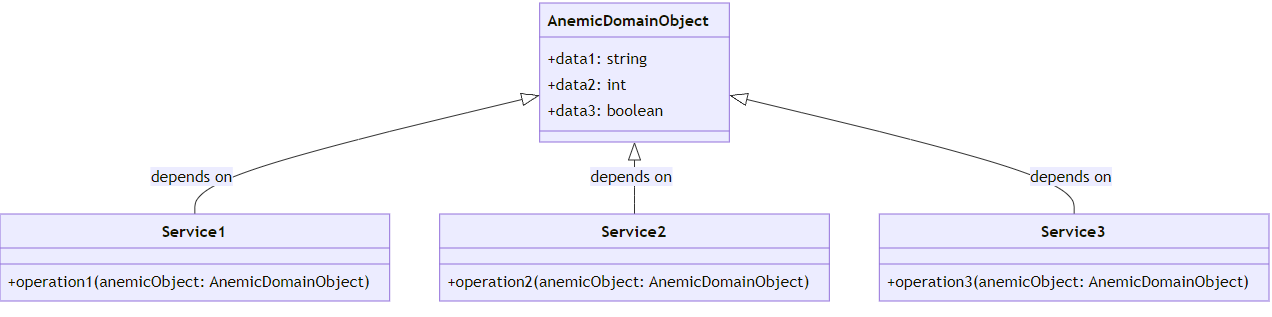
In short, our attempt to test VoucherService is like trying to solve a puzzle with missing pieces. Testability is seriously compromised due to scattered validations and lack of adequate encapsulation. Ah, life would be so much easier with a rich and well-structured domain!
How to Identify an Anemic Domain?
Based on everything we've already talked about, it's not very difficult, let's now highlight these points and add a few.
Stick-Thin Entities:
The first and most obvious sign is when your entities look more like data models than true entities. They are almost exclusively composed of properties and getters/setters. There is no behavior, there is no logic - just dry structures waiting for some sauce of logic that never arrives.
Ubiquitous Services:
These guys are the real protagonists in an anemic domain. They're everywhere, and usually have generic names like "UserService", "OrderService", and "EverythingButTheKitchenSinkService". They often carry the weight of all operations, leaving entities as mere bags of properties.
Lack of Encapsulation:
If you find that it's incredibly easy to access and modify the internal state of entities directly, it's likely that encapsulation has gone out the window. Remember, in a healthy domain, entities are like medieval forts, guarding their inner treasures and only allowing specific interactions through well-defined methods.
Business Rules in Strange Places:
In an anemic scenario, business rules have a strange tendency to appear in unusual places: controllers, utilities, and even UI layers. It's like finding your shoes in the fridge - definitely not where they belong.
Complex and Spread Tests:
Due to the scattering of logic, tests also tend to become scattered and complicated. Instead of testing cohesive behavior across an entity, you find yourself bouncing from one service to another, trying to trace the origin of a specific rule.
Entities Disconnected from Business Reality:
Its entities do not reflect the concepts of the business domain. Instead of having an "Account" entity that encapsulates the behavior of an account, you have an "AccountData" entity and an "AccountOperations" service. It's like having a separate car and driver, without a steering wheel to connect them.
Difficulty Talking to Domain Experts:
If you find yourself constantly having difficulty translating the requirements of domain experts into your code, it's likely that your domain is too disconnected from business reality. After all, it should be an almost direct translation, and not an epic worthy of a Greek epic.
Logic Reuse Becoming a Challenge:
In an anemic domain, reusable logic is like that sock that keeps disappearing in the laundry. You know it should be there, but it's almost impossible to find.
Now, take a deep breath. If your code shows many of the signs above, you may be navigating anemic waters. Let's talk more about the consequences.
Consequences in Large Corporate Systems
Great corporate systems, what a fascinating and challenging universe! This is where technology meets the intricate dynamics of large companies and their constantly evolving needs. However, when we enter the territory of the anemic domain, these complexities can take on worrying proportions.
Let’s start with communication between teams. In any large organization, it is imperative that development teams are on the same page. However, anemic dominance has the potential to undermine this attunement. With business logic and rules spread out, it's not uncommon for different teams to interpret roles and responsibilities differently. And let's be honest: who hasn't been in a meeting where two departments had completely different ideas about the same functionality?
Then we have the issue of data persistence. In a corporate environment, information often expands into enormous volumes. Maintaining data consistency and integrity is crucial. With business logic scattered and no clear sense of responsibility, ensuring that this data remains consistent and reliable becomes, well, a little more than a simple headache.
Diving deeper, let's think about the clarity of flows in a system. If you've ever tried to decipher a process or workflow on a domain-anemic system, you know that it can feel like you're trying to read a manual written in three different languages at the same time. Needless to say, this isn't good for productivity or team morale.
Now, if you are excited about the microservices approach, be aware. Microservices promise modularity and scalability, but when inserted into an anemic domain, they can inherit all the associated problems. The logic is dispersed across multiple services and orchestrating between them can resemble trying to drive a car with four steering wheels.
And, of course, there is the constant challenge of extending and adapting the software. In an ideal world, new features would be added fluidly and without many obstacles. However, with scattered logic and inconsistently applied business rules, each new feature can seem like a high-risk operation.
Finally, let's consider bug detection and data consistency. In an anemic system, bugs can be more elusive, appearing in unexpected places due to scattered logic. Have you ever seen that situation where a bug is fixed in one place and appears in another? And the inconsistency of the data... Ah, this could be the last straw, leading to inaccurate or, worse, wrong business decisions.
Do you recognize some of these challenges? Yes, they are very real and can arise when the software architecture is not carefully considered, especially in large corporate systems. And that's why, when facing these giants, we need to ensure our domain is strong, cohesive, and healthy. Because at the end of the day, a well-structured domain is not just good code; It's good for business.
I would like to talk about another point now, which we all need to be aware of to continue improving professionally.
Database Modeling Before Domain Modeling: A Fast Path to Anemic Software?
It's a beautiful day, and you're ready to start a new project. Excitement is in the air, ideas are flowing and coffee is freshly brewed in your cup. The first impulse? Start designing the database schema, right? Well, here's where we start down a dangerous path that can lead to anemic software. Allow me to break this down for you.
1. The Structural, Not Behavioral Mindset
When we start modeling the database, we naturally focus on the structures – the tables, keys, relationships and indexes. This puts us in a very “structural” mindset. Entities are viewed primarily as data containers, not as living objects with behavior.
2. The Cult of CRUDs
When taking the database-first approach, we often end up creating systems that are essentially a series of CRUD (Create, Read, Update, Delete) operations. Instead of modeling rich business logic and behaviors, we find ourselves stuck with a simplistic view, limited to direct manipulation of records.
3. Lack of Flexibility for Business Changes
Businesses change, and they change quickly. By defining rigid data structures at the beginning, we make the software more resistant to adaptations. Every time a new business need arises, instead of adjusting a behavior in the domain, we find ourselves restructuring the database, with all the headaches that entails.
4. The Belated Discovery of Complexity
Often, by focusing on the database first, we push complex business logic further into the development cycle. This can lead to late discoveries of crucial requirements or business nuances that, had they been addressed early on, could have led to a very different software design.
5. The Scattered Business Logic
When software is designed with the database as the main focus, business logic often gets scattered. It can be in database triggers, stored procedures, application code and even in the presentation layer. This makes the system not only difficult to maintain and evolve, but also a nightmare to test.
6. The Distant Gaze of Domain Experts
By focusing too much on database structure, we often distance ourselves from domain experts. These are the individuals who truly understand business problems and processes. If we are not in tune with them from the beginning, we run the risk of developing solutions that deviate from the real needs of the business.
What can we conclude on this topic?
Starting with database modeling is not, in itself, a fatal error. Truly effective and adaptable software starts with a deep understanding of the problem domain, not just the structure of how data will be stored. And let's be honest: no one wants to find themselves in the uncomfortable position of realizing, halfway through the project, that they're stuck in an anemic trap of their own creation. It is always tastier to savor the success of a well-structured project than the bitterness of rework and misunderstandings.
Now we can start talking briefly about rich domains, I won't go into depth as it will be a topic for a future article, but let's quickly talk about rich modeling!
The Essence of Behavior-Rich Domains!
The life of a programmer or software architect is not easy. We are often seen as those who simply "make things happen." But we're not magicians (well, maybe a little). The real trick is to adapt and shape our solutions according to the complexity of the demand. We are not merely doers, we are problem solvers. And let's be honest, you don't want a chef who just throws ingredients into a pan, right?
So how do rich domains come into this story? They are the compass that guides us. With them, we don't just code; We model the business, bringing to life the rules and processes that are the beating heart of the software.
Bringing Domain to Life: The Voucher Class
To illustrate this, let's talk about Voucher. An entity, at first glance, simple. But let's add layers of complexity and rich behaviors.
class Voucher {
private code: string;
private validityDate: Date;
private value: number;
private applied: boolean;
constructor(code: string, validityDate: Date, value: number) {
this.code = code;
this.validityDate = validityDate;
this.value = value;
this.applied = false;
}
isVoucherValid(): boolean {
const currentDate = new Date();
return currentDate <= this.validityDate;
}
applyVoucher(): void {
if (!this.isVoucherValid() || this.applied) {
throw new Error("Voucher cannot be applied.");
}
this.applied = true;
}
getValue(): number {
return this.value;
}
}
// Use-case example
class Product {
private price: number;
constructor(price: number) {
this.price = price;
}
applyDiscount(voucher: Voucher): void {
if (voucher.isVoucherValid() && !voucher.applied) {
this.price -= voucher.getValue();
}
}
}Here, the Voucher is not just a set of properties. It has behaviors that protect its integrity, such as checking its validity or ensuring it is not applied more than once. And when integrated into a Product, we see how this rich entity ensures that the discount is only applied if all rules are satisfied.
Now let's see a diagram that also represents this for us:

The ExternalService is a service that can interact with the RichDomainObject, but unlike the anemic domain, the rich domain does not rely heavily on external services to define its core behavior.

This approach not only makes business rules easier to implement, but also makes our code more resilient to errors. After all, when we know our domain deeply, and model it richly, our compass is always pointing in the right direction - towards robust and more reliable solutions.
Conclusion
Throughout our journey, we were able to understand not only the definition of this concept, but also its implications, its roots and, most importantly, how to avoid falling into this abyss.
Anemic domain can compromise a system's testability and even exacerbate problems in larger enterprise systems; an anemic domain can be a real hindrance to delivering high-quality software.
The Importance of Understanding
It has become clear that an approach focused solely on technology or data structure is insufficient. Instead, emphasis should be placed on truly understanding the problem at hand. The core of effective software development lies in a clear understanding of the problem domain and close collaboration with experts in that domain.
Modeling with Purpose
We also highlight the importance of starting with the domain rather than database modeling. This approach ensures that business logic and system behavior are placed at the forefront, thus preventing the software from becoming a mere representation of stored data.
Looking to the future
As we move forward, with the knowledge we have gained, we have a responsibility to approach software development with an open and critical mindset. We must constantly question ourselves, evaluating our decisions and ensuring that we are not falling into the traps of anemic domains.
It's important to remember that, as with any learning journey, the key is continuous reflection and the desire to improve. Therefore, as we sip our coffee (or tea, if you prefer) and contemplate our next project, let us take with us the lessons learned here and always aim to create systems that are robust, flexible and truly aligned with the needs of the business.
Before the rise of ORMs, dealing with databases in applications was in many ways a "manual" experience. Programmers had to write Structured Query Language (SQL) queries by hand to perform the most basic operations on a database. If you wanted to insert, update, retrieve, or delete a record, you were prepared to unravel the syntax and nuances of SQL.
Here is some of what the brave programmers went through:
Ad Hoc Queries: Every time a developer wanted to interact with the database, they needed to write a specific SQL query. This involved knowing the database schema and query syntax well.
Manual Mapping: Without ORMs to automatically map classes and objects from code to database tables and records, developers had to do this manually. Imagine having to remember and match each field in the object to a specific column in the database. I could sweat just thinking about it!
Inconsistencies between Databases: If an application needed to switch to a different database or support multiple databases, SQL queries often had to be rewritten. Why? Because not all databases speak the same "dialect" of SQL.
Security Issues: Writing SQL queries by hand opened the door to human error, especially vulnerabilities like SQL injection. If a programmer was not meticulous, they could accidentally create loopholes for malicious attacks.
Ah, but don't think that everything was suffering and despair. There was a beauty about that time. Programmers had absolute control over what happened between the application and the database. They deeply understood how their queries affected performance and data integrity. Think of it like making coffee. ORMs are like modern espresso machines - you press a button and you get your espresso. But before, it was like using a hand grinder and a French press. It was more work, but you felt every grain and controlled every step of the process.