
Quando Bibliotecas Compartilhadas Complicam Microserviços?
Bibliotecas compartilhadas são como impressora de escritório: Todo mundo usa, mas ninguém quer recarregar o papel.

Em arquiteturas de microserviços, conforme os sistemas crescem, um tema delicado surge: o compartilhamento de bibliotecas entre serviços. À primeira vista, pode parecer uma prática inofensiva ou até eficiente. Afinal, reutilizar código é uma boa prática. Mas, como veremos ao longo deste artigo, essa prática pode esconder armadilhas que comprometem justamente a independência e flexibilidade que tanto buscamos.
Discutiremos como a tentativa de reaproveitar bibliotecas pode levar a um acoplamento indesejado entre os serviços, dificultando sua manutenção e evolução. Além disso, vamos ver sobre as alternativas e boas práticas que podem ser adotadas para minimizar esses riscos e manter a arquitetura limpa e ágil.
Alguns dos pontos altos que vamos explorar são:
Os problemas de dependências compartilhadas: Como bibliotecas comuns podem afetar a independência dos serviços.
Evolução de bibliotecas: Dificuldades de versionamento e como mudanças podem causar uma reação em cadeia.
Boas práticas e soluções: Alternativas viáveis para garantir que bibliotecas sejam utilizadas de forma inteligente e sem comprometer a autonomia dos microserviços.
Vamos juntos entender onde estamos errando, e como evitar que o compartilhamento de bibliotecas transforme nossos microserviços em "micromonólitos". O objetivo aqui é garantir que nossos sistemas mantenham a agilidade, flexibilidade e independência que fazem dos microserviços uma abordagem tão boa.
Por que empacotamos código dentro de uma biblioteca?
Vamos começar com uma pergunta simples: por que, afinal, encapsulamos código dentro de uma biblioteca? Para responder isso, precisamos entender o que é, de fato, uma biblioteca no contexto da programação, mas antes, vale a pena explorar o significado original da palavra.
O que é uma biblioteca de código?
O termo "biblioteca" nos remete imediatamente à ideia de um local onde se armazenam livros — fontes de conhecimento organizadas para consulta. Curiosamente, a palavra biblioteca tem sua origem no latim "bibliothēca", que por sua vez vem do grego "bibliothḗkē" (βιβλιοθήκη), onde biblion significa "livro" e thḗkē significa "depósito" ou "lugar de armazenamento". Literalmente, uma biblioteca é um “local de armazenamento de livros”.
No entanto, tanto nas bibliotecas físicas quanto nas bibliotecas de código, o propósito vai além do simples armazenamento. Existe um processo de organização, curadoria1 e disponibilização de conhecimento, de forma que ele possa ser facilmente encontrado, acessado e reutilizado.
No mundo da engenharia de software, uma biblioteca de código atende a uma necessidade similar: ela concentra e organiza fragmentos de conhecimento técnico — funções, classes, módulos — que podem ser reutilizados sempre que necessário. Isso elimina a necessidade de "escrever um novo livro" — ou código — do zero.
A Evolução das Bibliotecas de Código
À medida que a complexidade dos sistemas crescia, surgia a necessidade de reutilizar código para evitar duplicação de esforços. Durante o início da história da programação, os desenvolvedores perceberam que podiam agrupar blocos de código reutilizáveis em bibliotecas, da mesma forma que um depósito de livros agrupa o conhecimento escrito. Assim como uma biblioteca de livros oferece uma curadoria do conhecimento, as bibliotecas de código passaram a oferecer funcionalidades já testadas e organizadas, economizando tempo e padronizando soluções.
Dessa forma, tarefas essenciais, como validação de dados, manipulação de datas ou cálculos matemáticos, passaram a ser concentradas em bibliotecas organizadas. Isso trouxe uma série de benefícios: economia de tempo no desenvolvimento, redução de erros (já que essas funções haviam sido previamente validadas) e consistência nas soluções.
A Curadoria nas Bibliotecas de Código
Mais do que um simples "depósito" de código, as bibliotecas de código exigem curadoria e manutenção. Assim como uma biblioteca de livros mantém seus acervos organizados e atualizados, as bibliotecas de código precisam ser bem estruturadas, versionadas e cuidadosamente mantidas para que possam ser efetivamente reutilizadas sem comprometer a integridade dos sistemas. Se mal organizadas ou negligenciadas, elas podem se tornar um ponto de acoplamento problemático entre sistemas, limitando a flexibilidade dos desenvolvedores.
Essa analogia com as bibliotecas físicas ajuda a entender que uma biblioteca de código é muito mais do que um conjunto de funções prontas — ela é um repositório de conhecimento organizado, que permite aos desenvolvedores reutilizar código de maneira eficiente e controlada. Ao encapsular o conhecimento técnico e as funcionalidades reutilizáveis, uma biblioteca de código permite que equipes de desenvolvimento se concentrem nas particularidades de seus projetos, sem precisar reinventar a roda.
Portanto, assim como a palavra "biblioteca" tem suas raízes no conceito de "armazenar livros", uma biblioteca de código é um local de armazenamento de conhecimento técnico, organizado de forma a ser facilmente reutilizado. Porém, seu valor não está apenas no armazenamento em si, mas na maneira como essas funcionalidades são curadas, mantidas e disponibilizadas. Como nas bibliotecas de livros, uma boa biblioteca de código garante que o conhecimento seja acessível, bem organizado e pronto para ser usado de forma eficaz.

O que torna o compartilhamento de bibliotecas tão atraente?
Esse conceito se tornou extremamente atraente para engenheiros de software. Afinal, em um mundo ideal, quem não gostaria de construir sistemas de forma mais rápida, reaproveitando código testado e confiável? A prática de criar bibliotecas começou a resolver um dos grandes dilemas da programação: como minimizar a redundância de código? Ao invés de copiar e colar a mesma função em vários lugares, bastava criar uma biblioteca para concentrar essa lógica comum e utilizá-la em diferentes partes do sistema. Isso não só evitava a duplicação de código, mas também facilitava a manutenção: quando uma função precisava ser ajustada ou corrigida, era só atualizar a biblioteca, e pronto – todas as partes que a utilizavam estariam automaticamente atualizadas.
Esse poder de reutilização faz o compartilhamento de bibliotecas parecer uma prática eficiente e segura aos olhos dos engenheiros de software. Imagine que você tem um conjunto de serviços que precisam calcular impostos. Em vez de escrever e manter o mesmo cálculo em vários lugares, você cria uma biblioteca que centraliza essa lógica. Agora, qualquer serviço que precise fazer esse cálculo pode simplesmente usar a biblioteca, sem precisar reinventar a roda. Essa abordagem reduz o esforço de desenvolvimento, aumenta a consistência (já que todos os serviços usarão a mesma lógica) e facilita a manutenção, já que, ao modificar a biblioteca, você garante que a atualização será refletida em todos os lugares que a utilizam.
No entanto, essa prática, tão atraente na teoria, traz consigo uma série de desafios e riscos, especialmente quando aplicada a arquiteturas de microserviços. O que inicialmente parece ser uma solução para reutilização de código pode, aos poucos, se transformar em um problema. Ao encapsular código em bibliotecas e compartilhá-las entre diferentes microserviços, há um potencial de criar dependências ocultas entre esses serviços. Esse compartilhamento excessivo pode acabar comprometendo a autonomia dos microserviços, que deveriam ser independentes. Assim, o que começa como uma solução elegante pode resultar em acoplamento, impactando a flexibilidade e a escalabilidade do sistema.
E é justamente aqui que surgem os problemas de dependências compartilhadas, o que nos leva ao próximo ponto crucial que precisa ser debatido...
Os Problemas de Dependências Compartilhadas
Você já se encontrou naquela situação em que tudo parece estar indo bem com seu sistema de microserviços, até que uma pequena atualização em uma biblioteca compartilhada quebra algo em produção? De repente, o que parecia uma simples mudança aciona uma reação em cadeia de falhas que afeta vários serviços, e o que deveria ser uma arquitetura independente e modular começa a mostrar sinais de dependência indesejada. Se isso já aconteceu com você – ou se você conhece alguém que passou por isso – então você já experimentou, em primeira mão, os problemas que o compartilhamento de bibliotecas pode causar.
O Acoplamento Indesejado
Cada serviço deve ser capaz de evoluir de forma autônoma, sem depender diretamente de outros serviços ou componentes. No entanto, quando bibliotecas são compartilhadas entre vários microserviços, estamos, de certa forma, estabelecendo uma ponte invisível entre eles. Essa ponte, que a princípio parece benéfica, pode rapidamente se transformar em um grande obstáculo.
Imagine que você tem um serviço de autenticação que compartilha uma biblioteca de validação de tokens com outros serviços. O serviço de pagamento, por exemplo, também depende dessa biblioteca para garantir que as transações sejam feitas apenas por usuários autenticados. Tudo parece funcionar bem até o dia em que alguém faz uma pequena alteração na biblioteca de validação – uma otimização de código, um ajuste de segurança – e, sem perceber, essa mudança quebra a lógica de validação de tokens no serviço de pagamento. O que era para ser uma simples atualização em um único serviço agora causa uma falha generalizada em todo o sistema.
Esse é o problema do acoplamento. Ao compartilhar bibliotecas entre microserviços, criamos dependências ocultas. Mesmo que os serviços estejam separados por domínios, o comportamento deles está ligado por essa biblioteca comum. Qualquer mudança, por menor que seja, pode ter efeitos colaterais inesperados em outros serviços que dependem dessa mesma biblioteca.
Impacto na Independência dos Serviços
Quando uma biblioteca mantida pela equipe A está espalhada por todo o ecossistema e sendo usada por diversos serviços, essa independência começa a se desfazer.
De repente, uma pequena alteração feita pela equipe A nessa biblioteca pode impactar múltiplos serviços que dependem dela. O que antes era uma mudança simples e autônoma agora se torna uma operação complexa, exigindo que outras equipes, cujos serviços dependem dessa biblioteca, façam uma coordenação minuciosa. A equipe A precisa sincronizar suas mudanças com os times de outros serviços, e isso adiciona uma camada de burocracia e testes que afeta diretamente a autonomia prometida pelos microserviços.
Pense no impacto disso no dia a dia do desenvolvimento. Cada vez que uma nova versão dessa biblioteca é lançada, os times que dependem dela precisam realizar testes de integração em seus próprios serviços, mesmo que não tenham feito nenhuma alteração no código de suas aplicações. O resultado? A velocidade com que as equipes podem iterar e entregar valor em produção começa a diminuir. O ciclo de desenvolvimento, que deveria ser ágil e independente, é interrompido pela necessidade de garantir que essa atualização não quebre algo em algum lugar do ecossistema. E, mesmo com todos os testes, sempre há o risco de algo passar despercebido, gerando um efeito dominó de problemas em produção.
Autonomia de Deploy
Se você já trabalhou com microserviços por tempo suficiente, provavelmente passou por um momento em que, durante o deploy de um serviço, percebeu que outro serviço, inesperadamente, também precisaria ser atualizado por causa de uma dependência compartilhada. Esse é um dos maiores pesadelos do compartilhamento de bibliotecas: a perda da autonomia nos deploys.
Você quer corrigir um bug no serviço de autenticação? Sem problemas, basta fazer o deploy da nova versão desse serviço, e os outros continuam funcionando normalmente. Mas, quando há uma biblioteca compartilhada envolvida, esse ciclo de deploy se complica. Agora, se o serviço de autenticação atualiza a biblioteca, o serviço de pagamento, que também depende dela, pode ter que ser implantado novamente – mesmo que o código do serviço de pagamento não tenha mudado.
Isso cria uma situação em que os microserviços começam a perder sua capacidade de ser autônomos. A cada nova atualização na biblioteca compartilhada, surge a dúvida: "Se alterarmos essa biblioteca, não vamos quebrar o build de outros serviços que dependem dela?" E, como a resposta nem sempre é clara, as equipes se tornam mais cautelosas, e os processos de deploy se tornam mais lentos e burocráticos. O que deveria ser uma arquitetura rápida e flexível se transforma em um ciclo de deploy rígido e interdependente, onde uma mudança em uma biblioteca pode impactar múltiplos serviços, forçando testes e ajustes inesperados.

O Dilema do Compartilhamento
Ao compartilhar bibliotecas entre serviços e apps, enfrentamos um dilema clássico: eficiência versus independência. De um lado, a reutilização de código através de bibliotecas compartilhadas pode parecer uma prática sensata e produtiva. Ela economiza tempo, evita a duplicação de código e oferece uma maneira padronizada de resolver problemas comuns. Mas, à medida que o sistema cresce, essas bibliotecas compartilhadas podem começar a agir como correntes que amarram os serviços uns aos outros.
Você já parou para pensar em quantas vezes teve que atrasar o deploy de um serviço por causa de uma dependência que estava fora do seu controle? Ou, talvez, tenha se deparado com um bug crítico que não estava no seu serviço, mas sim em uma biblioteca compartilhada, e precisou esperar que outro time o corrigisse antes de conseguir avançar? Essas situações são mais comuns do que parecem, e elas nos forçam a refletir: até que ponto o compartilhamento de bibliotecas entre microserviços é realmente vantajoso?
Essas dependências compartilhadas podem estar minando a flexibilidade e agilidade que os microserviços prometem oferecer. O que começou como uma estratégia de eficiência acaba, com o tempo, se transformando em um fardo que precisa ser constantemente gerenciado e equilibrado. E esse equilíbrio, por mais cuidadoso que seja, nem sempre é fácil de manter.
O Problema da Expansão de Responsabilidades
O que começou como uma solução simples e direta – uma pequena biblioteca encapsulando funcionalidades básicas – começa a se expandir à medida que novas demandas surgem. Pegando o exemplo de um ecossistema como o Spring Framework, as corporações muitas vezes criam suas próprias bibliotecas em cima de pacotes nativos, como o Feign Client. Elas encapsulam essas bibliotecas com customizações internas para atender a requisitos específicos de seus domínios.
No início, esse encapsulamento pode parecer uma boa ideia. Ele permite que as equipes desenvolvam funcionalidades rapidamente e com consistência em todos os microserviços. No entanto, à medida que novos requisitos surgem e os domínios se tornam mais especializados, essa biblioteca compartilhada começa a crescer, carregando consigo mais responsabilidades e regras de negócio.
Cada vez que uma funcionalidade é adicionada, ela pode introduzir novos comportamentos, padrões ou exceções que, inevitavelmente, começam a impactar todos os microserviços que dependem dela. O que era uma simples abstração de chamadas HTTP, como o Feign Client, pode começar a incorporar lógicas específicas de retry, circuit breakers, autenticação customizada e muito mais. Com isso, a biblioteca passa de um simples "ferramenta utilitária" para um artefato central de domínio, carregando consigo complexidades que impactam todo o ecossistema.
Agora, imagine que você está organizando uma grande conferência, e todas as palestras dependem de um único projetor. Cada palestrante tem uma apresentação diferente, com suas próprias necessidades e formatos, mas todos precisam usar o mesmo equipamento para exibir suas ideias. Agora, imagine que o projetor precisa de uma pequena atualização para funcionar melhor em algumas apresentações específicas. A equipe responsável pelo projetor decide ajustá-lo para otimizar o desempenho, mas, ao fazer isso, começa a surgir uma preocupação: "Será que esse ajuste vai afetar as outras palestras que ainda precisam do projetor?"
De repente, o que deveria ser um simples ajuste no equipamento se transforma em uma burocracia enorme. Cada palestrante precisa testar sua apresentação no novo projetor antes de subir ao palco, para garantir que tudo funcione perfeitamente. Isso gera filas, atrasos e, em vez de a conferência fluir com agilidade, o ritmo fica lento, com cada palestrante mais preocupado se sua apresentação vai funcionar do que com o conteúdo em si.
No mundo dos microserviços, essa conferência é como um sistema de várias equipes e serviços que dependem de uma biblioteca comum. O projetor é a biblioteca compartilhada, e cada palestrante é um serviço diferente. Cada vez que a biblioteca é alterada, todas as equipes que dependem dela precisam parar o que estão fazendo para garantir que suas aplicações ainda funcionem com a nova versão. O resultado é um processo de desenvolvimento mais burocrático, com mais reuniões, testes e coordenação do que o necessário – e tudo porque uma mudança pequena em um ponto central tem o potencial de afetar tudo ao redor.
Essa dependência centralizada compromete a independência dos times e desacelera todo o ecossistema de microserviços, assim como o projetor único trava o andamento da conferência. E é exatamente isso que acontece com uma biblioteca compartilhada que se expande demais. Ela carrega múltiplas responsabilidades e começa a ditar como os microserviços devem funcionar. Em vez de promover agilidade, acaba criando uma dependência que impede a evolução rápida e autônoma de cada serviço.
O que acontece no meio do caminho? A biblioteca começa a inflar com funcionalidades que não são necessárias para todos os serviços, mas que ainda assim precisam ser carregadas, testadas e mantidas. E quanto mais ela cresce, mais complexa se torna a manutenção e a integração com os diferentes microserviços. O resultado é uma biblioteca que, em vez de simplificar, começa a adicionar complexidade desnecessária, tornando-se um verdadeiro gargalo.
O Ponto Focal do Problema
O problema central aqui não é o crescimento da biblioteca em si, mas o fato de que ela está sendo usada de maneira indiscriminada por serviços que possuem necessidades diferentes. Ao continuar utilizando uma biblioteca compartilhada que evolui e se especializa, você está, essencialmente, forçando todos os serviços a carregar o peso de uma solução que não necessariamente se adapta às suas realidades. Isso cria um ciclo vicioso: quanto mais os serviços se especializam, mais funcionalidades precisam ser incorporadas na biblioteca, e mais ela começa a impactar todos os microserviços, mesmo aqueles que não precisam das novas funcionalidades.
Esse processo torna a evolução dos microserviços mais lenta e burocrática. Cada mudança na biblioteca requer uma série de testes e validações em todos os serviços que a utilizam, mesmo que a mudança tenha sido feita para atender a um único domínio. A independência dos serviços começa a se esvair, e os times ficam presos a um ciclo interminável de ajustes e validações.
Modelos Compartilhados e Bibliotecas de Domínio
Sam Newman, em sua obra Building Microservices (segunda edição), aborda com profundidade os perigos do acoplamento causado pelo compartilhamento de bibliotecas entre microserviços. Em um dos exemplos que ele menciona, uma empresa utilizava uma biblioteca de objetos de domínio – modelos que representavam as principais entidades do sistema – compartilhada por vários serviços. Inicialmente, isso parecia uma maneira eficiente de garantir consistência entre as equipes e acelerar o desenvolvimento. No entanto, conforme os serviços cresciam e novas funcionalidades eram adicionadas, essa estratégia começou a se mostrar problemática.
A situação descrita por Newman envolve uma alteração simples em um dos modelos compartilhados. Quando um campo adicional foi incluído em uma entidade, todos os serviços que utilizavam essa biblioteca precisaram ser atualizados. Isso não apenas gerou um esforço massivo de coordenação entre equipes, como também expôs a empresa a riscos de bugs e inconsistências. Se um único serviço não fosse atualizado corretamente, poderia haver falhas de comunicação e dados inválidos sendo processados.
Esse cenário mostra de forma clara como o acoplamento pode impactar diretamente a produtividade das equipes. Um simples campo adicionado em uma biblioteca de domínio pode exigir que todos os consumidores dessa biblioteca atualizem suas dependências e testem exaustivamente as mudanças.
Imagine a situação: uma equipe, ao tentar lançar uma nova versão de um serviço, descobre que precisa coordenar o deploy com outras cinco equipes que utilizam a mesma biblioteca. Isso introduz uma camada de burocracia que desacelera o processo de entrega de valor, exatamente o oposto do que microserviços deveriam promover. A capacidade de implantação independente, um dos pilares dessa arquitetura, é colocada em risco, e a agilidade das equipes diminui.
Além disso, o próprio risco de erro humano se intensifica. Quando uma biblioteca compartilhada precisa ser atualizada em vários serviços ao mesmo tempo, é mais fácil que pequenos deslizes ocorram. Talvez um campo não tenha sido corretamente mapeado, ou algum comportamento esperado não tenha sido replicado em todos os serviços. Esses pequenos erros podem não ser detectados imediatamente, mas podem causar grandes problemas mais tarde, em produção, onde dados inválidos ou comportamentos inesperados podem surgir.
Vamos imaginar um exemplo comum, inspirado no que Newman descreve. Suponha que você tenha uma biblioteca compartilhada de modelos que define como uma entidade "Cliente" deve ser representada no sistema. Essa entidade é usada em vários serviços, como faturamento, cadastro de clientes e análise de crédito. Quando um novo campo, como "data de renovação de contrato", é adicionado à entidade "Cliente", todos esses serviços precisam ser atualizados para lidar com essa nova informação. No entanto, alguns serviços podem não precisar dessa nova informação imediatamente. Mesmo assim, eles precisam atualizar suas dependências e passar por um ciclo de testes para garantir que nada foi quebrado.
Esse cenário não é apenas sobre esforço adicional. Quando você força todos os serviços a adotarem uma mudança simultaneamente, você está reduzindo a flexibilidade das equipes e centralizando as decisões de desenvolvimento. A autonomia das equipes – um dos maiores benefícios dos microserviços – é perdida, pois uma mudança que deveria ser local (em um serviço) agora impacta todo o ecossistema.
Explorando a Perspectiva com Ajuda de Outro Especialista
Sam Newman, oferece uma visão crítica sobre o compartilhamento de bibliotecas entre serviços. Ele argumenta que, embora a reutilização de código seja uma prática comum e, à primeira vista, eficiente, pode facilmente se transformar em uma armadilha de acoplamento, comprometendo a principal vantagem dos microserviços: a independência.
Newman cita um exemplo clássico de onde a reutilização de código pode gerar problemas: a serialização e desserialização de objetos de domínio. Quando uma organização decide criar uma biblioteca compartilhada para lidar com essas tarefas entre diversos microserviços, o objetivo inicial pode ser acelerar o desenvolvimento e garantir consistência. Contudo, o que acontece quando um campo precisa ser adicionado a uma entidade de domínio? Todos os microserviços que utilizam essa biblioteca agora precisam ser atualizados para incluir a nova versão. Nesse ponto, você perde a capacidade de realizar implantações independentes — um dos princípios mais importantes de uma arquitetura de microserviços.
Veja o que ele diz:
"A duplicação de código tem algumas desvantagens óbvias. Mas acho que essas desvantagens são melhores do que as desvantagens de usar código compartilhado que acaba acoplando serviços."
Essa frase reflete a postura firme de Newman em relação à duplicação de código. Embora a duplicação possa ser vista como algo "ruim" no desenvolvimento tradicional, ele argumenta que, no contexto de microserviços, a duplicação é uma troca aceitável em comparação com os perigos do acoplamento introduzido por bibliotecas compartilhadas. A duplicação permite que cada serviço evolua de forma independente, sem a necessidade de coordenar mudanças ou atualizações com outros serviços, preservando a autonomia e a flexibilidade da arquitetura.
Newman enfatiza ainda mais essa visão com uma outra frase-chave:
"Não viole o DRY em um microserviço, mas fique tranquilo ao violar o DRY em microserviços."
Aqui, Newman destaca uma distinção fundamental: dentro de um único microserviço, o DRY deve ser seguido com rigor. Isso significa que a duplicação de código ou lógica dentro de um serviço individual é algo que devemos evitar, pois pode criar complexidade desnecessária, aumentar o risco de erros e dificultar a manutenção. Dentro de um serviço, a aplicação tradicional do DRY faz todo sentido, já que a duplicação interna compromete a clareza e coesão do código.
No entanto, quando se trata de diferentes microserviços, a perspectiva muda. Newman comenta que é preferível permitir a duplicação de código entre microserviços, ainda que isso pareça contraintuitivo à primeira vista. Por quê? Porque tentar reutilizar código entre serviços, geralmente através de bibliotecas compartilhadas, introduz acoplamento. E em uma arquitetura de microserviços, onde a independência e autonomia são o alicerce, o acoplamento entre serviços deve ser evitado a todo custo.
O DRY como Duplicação de Conhecimento
É importante ressaltar que o conceito de DRY não se refere apenas à duplicação de código, mas sim à duplicação de conhecimento. Na segunda edição do livro, The Pragmatic Programmer, os autores Andy Hunt e Dave Thomas reforçam essa ideia ao afirmar que DRY trata-se de evitar a duplicação de intenções, regras de negócios e conhecimento fundamental que pode se dispersar e tornar o sistema inconsistente.
Portanto, a aplicação de DRY vai além da simples remoção de código duplicado. Ela envolve a gestão cuidadosa do conhecimento compartilhado. Isso significa que, em um contexto de microserviços, não há problema em duplicar código, desde que o conhecimento central que rege as regras de negócio esteja claro e seja gerido de forma independente em cada serviço. Na verdade, isso pode até ser preferível para evitar a dependência excessiva que bibliotecas compartilhadas criam.
Esse é um tema profundo, e em breve vou explorar o DRY como duplicação de conhecimento em um artigo específico, onde abordarei como esse princípio evoluiu além da simples ideia de eliminar repetição de código.
O Risco do DRY entre Microserviços
Quando se tenta compartilhar uma biblioteca entre múltiplos microserviços para “economizar” código, o ciclo de vida de todos os serviços acaba vinculado. Como discutido anteriormente, qualquer alteração na biblioteca — seja uma nova funcionalidade ou a correção de um bug — impacta todos os serviços que a utilizam. Isso gera um tipo de dependência indesejada, tornando muito mais difícil que cada serviço evolua de forma autônoma.
Por outro lado, a duplicação de código entre microserviços preserva essa autonomia. Cada serviço pode evoluir no seu próprio ritmo e de acordo com as suas necessidades, sem depender de mudanças feitas em outros serviços. Duplicar código, nesse caso, se torna uma estratégia defensiva contra o acoplamento excessivo. Embora à primeira vista pareça ir contra as boas práticas de engenharia, em sistemas distribuídos essa abordagem evita a complexidade de manter ciclos de vida sincronizados entre diferentes serviços.
Como Newman destaca, reutilizar código entre microserviços pode parecer uma prática eficiente, mas frequentemente mina os principais benefícios da arquitetura, que são a autonomia e a agilidade. Manter cada serviço com seu próprio conjunto de código, mesmo que isso implique duplicação, permite que eles evoluam sem precisar coordenar mudanças com outros times ou serviços.
A Realidade da Duplicação em Sistemas Distribuídos
Em sistemas monolíticos, a duplicação de código é de fato um problema grave. Imagine a mesma lógica de negócios espalhada em diferentes partes de uma aplicação monolítica. Qualquer mudança na lógica exigiria múltiplas atualizações, duplicação de testes e o risco de introduzir inconsistências seria enorme. Porém, em microserviços, o paradigma é diferente.
Imagine uma empresa que tem uma série de microserviços para lidar com diferentes aspectos do negócio: autenticação, faturamento e notificações. Todos esses serviços podem ter a lógica de manipulação de datas, por exemplo, duplicada. A solução tradicional seria encapsular essa lógica em uma biblioteca comum para evitar duplicação. No entanto, se uma mudança é necessária na maneira como as datas são tratadas, todos os microserviços que dependem dessa biblioteca precisam ser atualizados, gerando um ciclo de dependência que compromete a agilidade das equipes.
Ao invés disso, cada microserviço pode manter sua própria versão da lógica. Sim, isso implica um aumento de código duplicado, mas essa duplicação é insignificante em comparação ao custo de gerenciar dependências entre serviços. Cada microserviço pode atualizar sua própria lógica de acordo com suas próprias necessidades, sem se preocupar com os impactos nas outras partes do sistema.
Duplicação Consciente: Autonomia com Controle
É nesse contexto que surge a ideia de duplicação consciente: em vez de evitar a duplicação a qualquer custo, você avalia cuidadosamente os benefícios de manter os serviços separados e de duplicar partes específicas do código para garantir a independência e o isolamento. Esse tipo de duplicação permite que as equipes se movam com mais rapidez e façam alterações sem precisar coordenar com outras partes da aplicação.
Isso não significa que a duplicação deve ser feita sem critério. Ela precisa ser aplicada com responsabilidade e parcimônia. Se o código em questão é particularmente estável e raramente muda, a reutilização pode ser válida. Mas se o código está sujeito a mudanças frequentes, a duplicação pode ser a escolha mais segura para garantir a autonomia dos serviços.
O Custo da Reutilização Versus o Benefício da Duplicação
Portanto, quando Sam Newman sugere que é aceitável “violar o DRY entre microserviços”, ele está nos incentivando a adotar uma visão mais pragmática sobre a arquitetura de sistemas distribuídos. A reutilização de código é, sem dúvida, uma prática valiosa dentro de um ecossistema distribuído. No entanto, quando aplicada entre microserviços, o custo do acoplamento pode facilmente superar os benefícios.
A verdadeira questão não é se devemos ou não duplicar código, mas sim como podemos preservar a autonomia e a flexibilidade dos serviços. Se a duplicação é o caminho mais eficiente para garantir essa autonomia, então ela deve ser considerada uma prática válida — e muitas vezes, essencial. No fim das contas, a maior vantagem dos microserviços não é reduzir código duplicado, mas sim evoluir de forma independente, garantindo agilidade, escalabilidade e eficiência em todo o sistema.
Ufa! Quanto assunto e pontos a considerar! Espero que tenha ficado claro, se não ficou, deixe um comentário e vamos conversar sobre isso!
Agora vamos falar sobre outro grande desafios que enfrentamos!
O Desafio da Sincronização de Bibliotecas
Um dos maiores desafios de utilizar bibliotecas compartilhadas em ambientes de microserviços não é apenas lidar com a retrocompatibilidade ou as mudanças na funcionalidade. O problema se torna ainda mais complexo quando entra em cena a sincronização de trabalho entre diferentes equipes, que utilizam a mesma biblioteca. Quem é responsável pela manutenção? Quem deve corrigir um bug ou adicionar uma nova funcionalidade? Quando várias equipes dependem de uma única biblioteca, e não está claro quem "possui" aquele recurso, a gestão de mudanças se transforma em um verdadeiro labirinto organizacional.
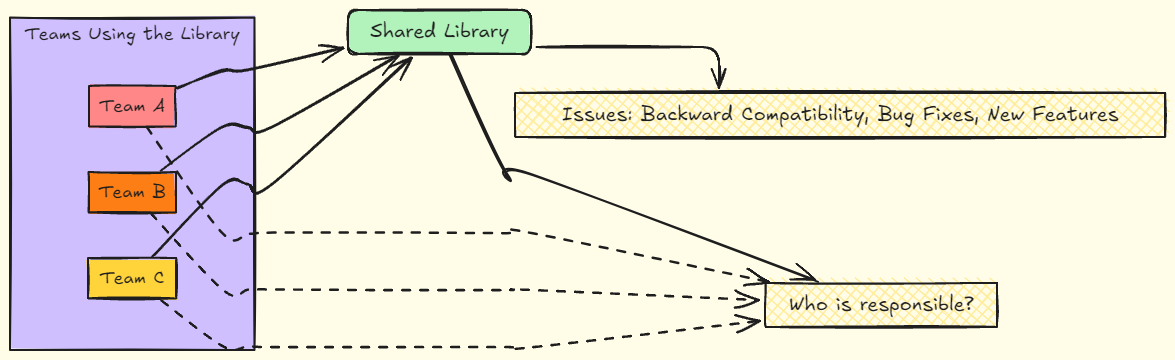
Imagine a seguinte situação: uma empresa possui uma biblioteca compartilhada que lida com logins, usada por dezenas de microserviços diferentes. Essa biblioteca foi criada há alguns anos por uma equipe que hoje nem trabalha mais no projeto original. Com o tempo, novas equipes começaram a usá-la, expandindo sua funcionalidade de maneiras diversas para atender às suas necessidades. Agora, um bug crítico de segurança foi encontrado na biblioteca e precisa ser corrigido com urgência. Mas a questão é: quem é responsável por fazer essa correção?
Nenhuma equipe de engenharia se sente "dona" da biblioteca. Cada time que usa a biblioteca tem seus próprios prazos e prioridades, e muitos desenvolvedores nem mesmo conhecem a fundo o código dessa biblioteca. A falta de clareza sobre a responsabilidade torna o processo de correção muito mais lento do que deveria ser. Além disso, mesmo que uma equipe assuma a tarefa de corrigir o bug, outras equipes precisarão testar seus serviços para garantir que a correção não introduza novos problemas, aumentando ainda mais a complexidade.
Como Sam Newman menciona em seu livro sobre microserviços:
“Cada atualização na biblioteca compartilhada requer que vários serviços sejam testados e implantados em conjunto.”
Esse ciclo de interdependência não só reduz a agilidade do processo de desenvolvimento, como também gera confusão. Programadores que nunca trabalharam diretamente com o código da biblioteca agora precisam interromper suas atividades principais, mergulhar em um código desconhecido e compreender todo o contexto histórico por trás de cada modificação feita anteriormente. Isso afeta diretamente a eficiência das equipes, que muitas vezes se veem obrigadas a trabalhar em algo que está fora de sua área de expertise, ao invés de focarem nas suas próprias entregas.
A Questão da Responsabilidade e a Fragmentação do Conhecimento
O problema se intensifica em empresas maiores, onde diferentes equipes usam a biblioteca para fins diversos, e muitas vezes essas equipes nem sequer se comunicam diretamente. A falta de um "dono" claro da biblioteca cria uma fragmentação do conhecimento. A equipe que originalmente criou a biblioteca pode já ter movido suas prioridades para outros projetos, e as novas equipes que começaram a usá-la frequentemente têm visões diferentes de como ela deve evoluir.
Esse vácuo de propriedade significa que, quando um problema surge, há um esforço considerável em alinhar diferentes times para que todos estejam na mesma página. Quem será responsável por analisar o bug? Quem define os critérios para a solução? Qual equipe terá a última palavra sobre as mudanças necessárias? Esse tipo de coordenação pode atrasar significativamente a resolução de problemas críticos e comprometer os prazos das entregas.
Agora, imagine que o bug de segurança precisa ser corrigido em menos de uma semana. Mas, como várias equipes utilizam a biblioteca de maneiras diferentes, o impacto da correção pode variar. Uma equipe pode estar pronta para adotar a nova versão imediatamente, enquanto outra ainda está no meio de um ciclo de desenvolvimento importante e não pode arriscar uma atualização naquele momento. A complexidade de alinhar todas essas realidades transforma uma simples correção em um processo altamente burocrático, onde cada mudança precisa passar por várias camadas de aprovação e testes. O resultado? Deploys mais lentos, maior complexidade, e a perda da agilidade que os microserviços deveriam proporcionar.
Como Newman observa, uma das maiores armadilhas da reutilização de bibliotecas compartilhadas em microserviços é que ela cria um acoplamento indireto entre serviços que, de outra forma, deveriam ser independentes. Essa dependência compartilhada faz com que equipes percam tempo precioso em tarefas de coordenação, testes e validações conjuntas.
O Impacto nos Prazos
Imagine agora uma equipe que está a duas semanas de uma entrega crítica para um cliente. Durante o ciclo de desenvolvimento, eles descobrem que precisam adicionar uma nova funcionalidade à biblioteca compartilhada que lida com relatórios de performance. Essa biblioteca já é usada por outros times que também estão em momentos críticos de seus projetos. A equipe decide adicionar a funcionalidade, mas logo percebe que a mudança introduziu um efeito colateral inesperado para outro serviço que utiliza a biblioteca de maneira diferente. Agora, além de resolver o problema no próprio código, eles precisam notificar as outras equipes, ajustar a biblioteca de maneira que não quebre o funcionamento de outros serviços e, pior, aguardam por feedback e validações de outros times.
Essa situação cria um verdadeiro efeito dominó: o prazo que antes parecia factível agora está comprometido porque a equipe está presa em um ciclo de correção de problemas que não eram originalmente deles. Outros serviços precisam ser testados e, em alguns casos, retrabalhados. O escopo do trabalho se expande de maneira incontrolável, e a equipe acaba gastando tempo precioso em algo que, idealmente, deveria ter sido uma alteração isolada.
Essa falta de clareza sobre quem é o responsável final pela biblioteca e as modificações necessárias causa atrasos significativos. Em vez de entregar novas funcionalidades rapidamente, como é esperado em um ambiente de microserviços, a equipe se vê imersa em processos de integração e verificação com outros times, resultando em entregas mais lentas e menos eficientes.
Estratégias para Mitigar o Problema Da Responsabilidade!
Uma das formas de mitigar esse problema é definir claramente a responsabilidade pela biblioteca desde o início. Isso pode ser feito através da atribuição de uma equipe específica como "dona" da biblioteca. Essa equipe seria responsável por sua manutenção, correções de bugs e adições de funcionalidades. Isso facilita o processo de atualização, pois há um time que entende a fundo a estrutura e pode garantir que as mudanças sejam feitas de forma segura.
Outra estratégia recomendada é a criação de contratos de versão claros para as bibliotecas. Em vez de exigir que todos os serviços sejam atualizados imediatamente, pode-se permitir que múltiplas versões da biblioteca coexistam, com um ciclo de vida claro para cada versão. Equipes que desejarem fazer uma atualização mais agressiva podem adotar a versão mais recente, enquanto outras equipes podem permanecer em uma versão mais estável até que estejam prontas para fazer a transição.
A sincronização de bibliotecas compartilhadas em ambientes de microserviços é um dos desafios mais críticos e subestimados pelas equipes de desenvolvimento. A falta de uma clara definição de propriedade, o impacto nas diferentes equipes e a necessidade de coordenação constante minam a agilidade esperada de uma arquitetura de microserviços. Quando várias equipes dependem da mesma biblioteca, mudanças que deveriam ser simples se tornam complexas e demoradas, comprometendo prazos e a eficiência dos times.
Para evitar esses problemas, é essencial definir claramente quem é responsável por cada biblioteca, criar contratos de versão e, quando possível, considerar o uso de microserviços dedicados para centralizar funcionalidades compartilhadas. Só assim é possível manter a independência e a agilidade que os microserviços prometem, sem cair nas armadilhas do acoplamento oculto.
Estratégias para Lidar com a Evolução de Bibliotecas sem Comprometer a Autonomia dos Microserviços
Conforme discutido, o crescimento de uma biblioteca compartilhada pode ser um desafio, especialmente quando ela se expande para atender a necessidades de múltiplos microserviços, com domínios e requisitos diferentes. Agora, é hora de explorar estratégias para lidar com essa evolução sem comprometer a agilidade e a independência de cada microserviço.
Versionamento Semântico
Uma das primeiras estratégias para evitar que uma biblioteca compartilhada se torne um gargalo é adotar versionamento semântico rigoroso. Ao versionar corretamente a biblioteca, é possível separar atualizações que não causam quebra (atualizações menores e patches) de atualizações que introduzem mudanças drásticas (major versions). Isso permite que diferentes microserviços usem versões diferentes da mesma biblioteca sem comprometer a estabilidade do sistema como um todo.
Com o versionamento semântico bem implementado, você pode garantir que serviços críticos continuem utilizando uma versão estável e testada da biblioteca, enquanto outros serviços, que têm mais flexibilidade para inovação, podem migrar para versões mais recentes. Isso evita que mudanças disruptivas causem efeitos colaterais em serviços que não estão prontos para adotar as atualizações.
Segregação de Bibliotecas por Domínio
À medida que os microserviços se tornam especialistas em seus respectivos domínios, uma abordagem eficaz é segregar as bibliotecas. Em vez de continuar inflando uma única biblioteca compartilhada com regras e lógicas de múltiplos domínios, considere criar módulos ou bibliotecas menores e específicas para cada contexto. Isso mantém a biblioteca enxuta e focada em um conjunto específico de responsabilidades.

Por exemplo, se uma biblioteca começou encapsulando chamadas HTTP, mas agora inclui lógicas de autenticação, caching e tratamento de falhas, é hora de separá-las em bibliotecas diferentes. Dessa forma, cada microserviço só carrega as dependências que realmente precisa. Essa separação garante que as equipes possam evoluir as bibliotecas de forma mais ágil, sem carregar funcionalidades que não utilizam.
Customização e Extensão via Composição
Uma estratégia importante para evitar o acoplamento excessivo em bibliotecas compartilhadas é garantir que elas sejam flexíveis e extensíveis por meio de composição, em vez de forçar uma única implementação centralizada. Isso significa que, ao invés de colocar diretamente lógicas específicas dentro de uma biblioteca compartilhada, como o Feign Client, cada microserviço pode compor suas próprias funcionalidades em cima dessa base, de acordo com suas necessidades.
Por exemplo, o Feign Client pode continuar sendo utilizado como a base para comunicação HTTP. No entanto, ao invés de adicionar funcionalidades como retry automático e autenticação diretamente dentro da biblioteca compartilhada, cada microserviço pode implementar essas estratégias de forma independente. Isso permite que o núcleo da biblioteca permaneça genérico – lidando apenas com a comunicação HTTP básica – enquanto cada serviço define seus próprios mecanismos para lidar com retries, autenticação ou qualquer outra lógica que seja específica daquele serviço.
E o interessante é que essa abordagem está profundamente alinhada com princípios sólidos de design de software, como o Princípio Aberto/Fechado (Open/Closed Principle) e a Separação de Responsabilidades (Separation of Concerns). De acordo com o Princípio Aberto/Fechado, uma biblioteca deve ser aberta para extensão, mas fechada para modificações diretas. Ou seja, a biblioteca central lida com a parte comum e genérica, enquanto os microserviços têm a liberdade de estender suas funcionalidades de acordo com suas necessidades específicas, sem precisar modificar o código principal da biblioteca. Isso garante flexibilidade, evitando a criação de dependências rígidas e promovendo a manutenibilidade a longo prazo.
Uso de Adapters para Lidar com Diferenças
Adapters são outra excelente estratégia para garantir que diferentes serviços possam usar a mesma biblioteca compartilhada, mas com comportamentos específicos e personalizados. Ao invés de exigir que a biblioteca central atenda a todas as necessidades de todos os serviços, você pode criar uma camada de adaptação (adapter) para ajustar as funcionalidades de acordo com o contexto específico de cada microserviço.
Por exemplo, imagine dois microserviços que utilizam a mesma biblioteca de comunicação HTTP para lidar com falhas de rede e realizar tentativas de retry:
Serviço de Pagamento: A lógica de retry pode ser mais conservadora. Talvez o serviço de pagamento precise de apenas duas tentativas de retry com um intervalo de 1 segundo entre elas, já que falhas frequentes podem sinalizar um problema crítico. Além disso, ele pode estar programado para desistir rapidamente ao detectar uma falha repetida, para não comprometer a experiência do cliente ou criar duplicatas de transações.
Serviço de Autenticação: Por outro lado, um serviço de autenticação pode ser mais tolerante a falhas e realizar até cinco tentativas de retry, com um intervalo de 500 milissegundos entre as tentativas. Como a autenticação é essencial para o funcionamento contínuo de outros serviços, ele pode ser configurado para ser mais persistente antes de desistir de estabelecer a comunicação.
Ao usar adapters, você mantém a biblioteca de comunicação HTTP genérica, sem sobrecarregá-la com essas regras específicas de retry. Cada serviço (pagamento e autenticação) pode definir sua própria lógica de retry por meio de um adapter, sem modificar diretamente a biblioteca central. Isso garante que a biblioteca permaneça simples e focada no que ela faz de melhor — lidar com comunicação HTTP — enquanto a lógica específica, como o número de tentativas e intervalos de retry, fica na camada de adaptação.
Mais uma vez, essa prática reforça os princípios de Separação de Responsabilidades e Princípio Aberto/Fechado, pois adapta-se o comportamento do sistema sem modificar diretamente a biblioteca. Os adapters permitem que cada microserviço implemente suas particularidades sem criar dependências rígidas ou forçar atualizações contínuas na biblioteca compartilhada.

Dessa forma, evitamos que a biblioteca se torne inflada com funcionalidades que nem todos os serviços necessitam. A simplicidade da biblioteca é preservada, ao mesmo tempo em que os serviços têm a liberdade de estender seu comportamento de acordo com as suas próprias necessidades.
Isolamento de Funcionalidades Sensíveis
Quando se trata de bibliotecas que envolvem lógica complexa ou sensível (como segurança, autenticação, ou manipulação de dados), uma abordagem recomendada é isolar essas funcionalidades em componentes independentes:
Isolamento em microserviços especializados: Ao invés de compartilhar uma biblioteca de segurança entre todos os serviços, crie um microserviço especializado que centralize a lógica de autenticação ou de criptografia. Assim, os microserviços podem delegar essas responsabilidades de forma segura e isolada, evitando quebras de funcionalidade caso uma mudança seja necessária.
Componentes independentes: Para funcionalidades sensíveis, evite criar bibliotecas gigantescas. Isolar essas funcionalidades ajuda a manter o impacto de mudanças restrito a um único componente, evitando que alterações em partes críticas da biblioteca afetem outros serviços.
Essa prática aumenta a resiliência do sistema, garantindo que falhas em um serviço específico não se propaguem para outros serviços que dependem da mesma funcionalidade.
Padronização de Convenções e Interfaces
Um dos maiores desafios em bibliotecas compartilhadas é garantir que todas as equipes as utilizem de forma consistente. Estabelecer padrões claros e boas práticas pode ajudar a reduzir os riscos associados ao uso inconsistente de uma biblioteca:
Convenções de desenvolvimento padronizadas: Defina convenções de uso, como padrões de nomenclatura, contratos de APIs e formas de tratamento de erros. Essas práticas padronizam o comportamento esperado e ajudam a criar um consenso entre as equipes, evitando conflitos ou mal-entendidos.
Interfaces consistentes: Use interfaces consistentes e previsíveis para interagir com a biblioteca. Isso facilita a integração e também reduz a necessidade de conhecimento profundo da biblioteca por parte de todos os desenvolvedores que a utilizam.
Padronizar a maneira como bibliotecas são consumidas ajuda a reduzir o risco de mal-entendidos ou uso inadequado, diminuindo o acoplamento e a necessidade de correções futuras.
Utilize Pacotes Independentes com Funcionalidades Bem Definidas
Quando for necessário compartilhar funcionalidades comuns, uma boa prática é dividir a biblioteca em pacotes independentes, em vez de criar um único pacote monolítico que contém tudo:
Pacotes desacoplados: Ao invés de criar uma biblioteca gigantesca que faz de tudo, divida as funcionalidades em pacotes pequenos e coesos (por exemplo, um pacote só para validação, outro para autenticação, etc.). Dessa forma, os microserviços só precisarão usar o pacote que realmente necessitam, o que ajuda a manter o isolamento.
Funcionalidades bem definidas: Cada pacote deve ser limitado a uma única responsabilidade, o que ajuda a minimizar o impacto de mudanças e permite que serviços diferentes utilizem versões diferentes de pacotes relacionados.
Essa abordagem modulariza o código, tornando mais fácil manter e atualizar partes individuais sem afetar o restante da base de código.
Limite a Frequência de Atualizações da Biblioteca
Se uma biblioteca está em constante evolução, isso pode forçar os serviços a manterem o ritmo das atualizações, causando interrupções frequentes. Para evitar isso:
Planeje ciclos de liberação controlados: Em vez de lançar atualizações de forma ad hoc, crie ciclos de liberação controlados e previsíveis. Isso permite que as equipes planejem suas próprias atualizações e testes em torno de uma programação previsível.
Evite mudanças triviais constantes: Reduza atualizações pequenas e triviais que não trazem valor real. Agrupe melhorias e correções em releases significativas para reduzir o número de implantações forçadas.
Controlar a frequência de mudanças mantém o sistema mais estável e reduz a pressão sobre os serviços consumidores.
As Perguntas Certas a Fazer!
É importante que as equipes revisitem o uso dessas bibliotecas periodicamente, fazendo algumas perguntas essenciais que podem revelar se a biblioteca ainda faz sentido ou se está criando mais problemas do que resolvendo. Aqui estão algumas perguntas que podem ser feitas para guiar essa análise:
A Biblioteca Encapsula Funcionalidades Úteis?
Quantos microserviços realmente precisam desta biblioteca?
Essa é uma das primeiras perguntas a fazer. Se uma biblioteca foi criada para ser compartilhada, ela realmente está sendo utilizada por múltiplos serviços ou apenas por um grupo restrito? Vale a pena mantê-la compartilhada se só um ou dois serviços a utilizam? Se poucos serviços estão utilizando, talvez não faça sentido mantê-la como um ponto central de dependência.
Ela encapsula comportamentos ou funcionalidades que são estáveis?
Bibliotecas úteis para múltiplos microserviços geralmente encapsulam comportamentos que não mudam com frequência, como validações de segurança ou formatos de resposta HTTP. Se o comportamento encapsulado é algo que raramente muda, a biblioteca pode ser uma boa solução. Mas se a funcionalidade está sempre sendo alterada, ela pode estar se tornando um ponto de atrito.
Estamos economizando tempo ou criando mais dependências?
O objetivo de uma biblioteca compartilhada deve ser simplificar e acelerar o desenvolvimento, mas é importante perguntar: estamos realmente economizando tempo ou apenas criando um ponto de acoplamento? Se toda vez que há uma mudança na biblioteca, várias equipes precisam interromper seus trabalhos para alinhar suas versões e fazer testes, o esforço pode não estar compensando a reutilização de código.
As funcionalidades são gerais o suficiente ou estão sendo especializadas?
A biblioteca deve encapsular funcionalidades que são realmente úteis para vários serviços. Se ela está começando a incluir lógicas ou comportamentos muito específicos de um domínio ou de um microserviço, pode ser hora de parar e refletir. Quando uma biblioteca começa a incorporar lógicas de negócios específicas, isso é um sinal de que ela está ficando especializada demais, o que aumenta o risco de acoplamento.
Quando a Biblioteca Começa a Ficar Complexa Demais
Conforme a biblioteca evolui, pode se tornar complexa demais e começar a incorporar responsabilidades que ela não deveria ter. Nesse ponto, é essencial questionar o propósito e a utilidade de mantê-la como uma dependência central. Aqui estão algumas perguntas que as equipes devem fazer:
Estamos começando a adicionar muita lógica específica de negócio?
Um dos maiores sinais de que uma biblioteca está ficando complexa demais é quando ela começa a conter lógicas de negócios que deveriam ser responsabilidade de serviços individuais. Se a biblioteca está incorporando regras que só fazem sentido para um grupo pequeno de microserviços, ela pode estar se afastando do seu propósito original de fornecer uma funcionalidade genérica e útil para vários serviços.
Quantas vezes estamos tendo que modificar a biblioteca?
Se a biblioteca está sendo modificada frequentemente, especialmente para acomodar novos comportamentos específicos de alguns serviços, isso é um forte indicativo de que ela está se tornando um gargalo. Uma boa biblioteca compartilhada deve ser estável e raramente necessitar de mudanças. Quando as atualizações são constantes, elas geram um ciclo de deploys interdependentes e aumentam o risco de erros.
Estamos conseguindo realizar deploys independentes?
A pergunta mais importante a se fazer é se os microserviços que utilizam a biblioteca ainda conseguem realizar deploys de forma independente. Se cada alteração na biblioteca requer que múltiplos serviços sejam atualizados ao mesmo tempo, ou que várias equipes entrem em um ciclo de testes e ajustes, a biblioteca pode estar comprometendo um dos princípios fundamentais dos microserviços: a capacidade de evoluir de forma independente.
A biblioteca está se tornando difícil de entender?
Um sinal claro de que uma biblioteca está se tornando complexa demais é quando os desenvolvedores têm dificuldade de entender como ela funciona. Se a biblioteca começou como algo simples, mas agora requer várias camadas de configuração ou modificações para se adaptar a diferentes serviços, ela pode estar sobrecarregada. Quando o código compartilhado fica difícil de compreender, aumenta a chance de erros e a equipe perde confiança em utilizá-lo.
A duplicação de código seria mais simples neste caso?
Finalmente, uma pergunta que muitas equipes não fazem, mas deveriam: seria mais fácil duplicar o código ao invés de continuar compartilhando a biblioteca? Talvez, a resposta seja um sim. Em vez de continuar inflando uma biblioteca que tenta atender a múltiplos serviços, duplicar o código pode devolver a autonomia às equipes e evitar o acoplamento que prejudica a flexibilidade e a agilidade.
Encontrando o Equilíbrio
Essas perguntas podem ajudar a equipe a identificar quando uma biblioteca compartilhada ainda está sendo útil e quando ela se tornou um obstáculo à evolução dos serviços. A chave é encontrar o equilíbrio entre reutilização e independência. O compartilhamento de bibliotecas pode ser uma solução poderosa, mas deve ser tratado com cuidado. Se a biblioteca começar a carregar muitas responsabilidades ou a dificultar os deploys, pode ser hora de repensar sua utilização e adotar uma abordagem mais leve, como a duplicação de código entre os serviços.
Por exemplo, se estamos lidando com bibliotecas de configuração de tecnologias como RabbitMQ ou Kafka, onde todos os microserviços utilizam as mesmas configurações e não têm particularidades, faz sentido compartilhar essas bibliotecas, pois isso evita a duplicação de configurações. O mesmo pode ser dito sobre bibliotecas de auditoria, logging ou error handler, onde a lógica é genérica e não precisa ser customizada para cada serviço.
Se uma biblioteca que centraliza regras de autorização, cálculos, ou regras centralizadas que poderiam estar em um domínio (serviço), por exemplo, acabar afetando o tempo de resposta de um microserviço ou sua operação devido a uma falha interna, ela pode causar mais problemas do que soluções.
Quando essas funcionalidades críticas são centralizadas em uma biblioteca compartilhada, os microserviços ficam dependentes de seu funcionamento. Isso significa que, se a biblioteca apresentar uma falha ou instabilidade, vários serviços podem ser impactados simultaneamente, resultando em interrupções em cadeia. Além disso, ao centralizar lógicas de negócio em uma única biblioteca, qualquer alteração ou correção precisa ser rigorosamente testada para garantir que não vá quebrar outros serviços que dependem dessa biblioteca. Isso pode atrasar o deploy de novos recursos e diminuir a agilidade dos times.
Portanto, é importante avaliar cuidadosamente quais funcionalidades fazem sentido estar em uma biblioteca compartilhada e quais devem ser implementadas diretamente em cada microserviço. Funcionalidades como manipulação de dados simples ou formatação de informações podem ser boas candidatas para centralização, enquanto regras de negócio específicas ou funcionalidades que afetam diretamente o desempenho e a segurança de um serviço devem, sempre que possível, ser isoladas no próprio serviço.
Essa separação de responsabilidades garante que os microserviços mantenham sua autonomia, possam escalar de forma independente e não fiquem vulneráveis a falhas em uma única biblioteca centralizada.
Ao fazer essas perguntas e refletir sobre as respostas, as equipes podem tomar decisões mais conscientes sobre como gerir suas bibliotecas e evitar o acoplamento indesejado que, muitas vezes, se infiltra sem que percebamos. A ideia é sempre manter o equilíbrio: garantir que a reutilização faça sentido, mas sem comprometer a agilidade e a autonomia dos serviços.
O Que é Curadoria em uma Biblioteca?
A curadoria em uma biblioteca, seja ela de livros ou de código, refere-se ao processo de seleção, organização e manutenção do conteúdo disponível para consulta. No contexto de uma biblioteca de livros, o bibliotecário ou curador tem o papel de garantir que o acervo esteja atualizado, relevante e acessível para os leitores, promovendo uma experiência eficiente de busca e uso de informações. Esse processo envolve várias atividades, como:
Seleção de obras: Escolher quais livros devem ser adquiridos para a biblioteca, com base nas necessidades e interesses da comunidade de leitores.
Organização do acervo: Catalogar e classificar os livros de forma lógica e acessível, utilizando sistemas de indexação, como o Dewey Decimal System ou a Classificação da Biblioteca do Congresso.
Manutenção: Cuidar para que os livros estejam em bom estado, substituir volumes antigos ou danificados e, às vezes, remover obras que estão desatualizadas ou que não são mais relevantes.
Apoio ao usuário: Ajudar os leitores a encontrar as informações que precisam, oferecendo suporte na navegação pelo acervo e, muitas vezes, sugestões de leituras adicionais.
Em resumo, a curadoria em uma biblioteca física é o processo ativo de gerenciar e organizar o conhecimento disponível, garantindo que ele seja atualizado, relevante e fácil de acessar.