

Comunicação Assíncrona em Microserviços: O que poucos te contam?

Neste artigo, vamos conversar sobre alguns desafios que surgem quando lidamos com comunicação assíncrona em arquiteturas distribuídas. Vamos discutir onde podemos estar errando — desde o uso inadequado de filas e como elas podem carregar falhas silenciosas. Nosso objetivo é trazer à tona as armadilhas comuns e como evitá-las.
Se você já se perguntou por que a comunicação assíncrona entre seus microserviços não está funcionando tão bem quanto deveria este artigo é para você.
O que é Comunicação Assíncrona?
Comunicação assíncrona é como enviar uma carta pelo correio. Você escreve a carta, a coloca no envelope e a envia. Depois de enviar, você não precisa esperar na agência dos correios até que a pessoa receba e responda. Em vez disso, você continua com suas atividades, sabendo que a carta será entregue em algum momento.

Imagine que você está se comunicando com um colega. Se vocês dois estiverem conversando ao telefone, respondendo um ao outro imediatamente, isso seria uma conversa "síncrona" — tudo acontece ao mesmo tempo.
Agora, pense em quando você envia uma mensagem de texto. Seu colega pode não responder na hora; ele pode ver a mensagem mais tarde e responder quando for conveniente. Nesse caso, a comunicação é "assíncrona" — você não precisa esperar uma resposta imediata, e a conversa pode continuar em momentos diferentes.
Então, "assíncrona" significa simplesmente que as coisas não precisam acontecer ao mesmo tempo. Elas podem ocorrer em momentos diferentes, sem uma ordem fixa ou imediata.
A comunicação assíncrona brilha os olhos dos engenheiros de software porque, assim como no exemplo de postar uma carta, ela nos permite construir sistemas que não ficam presos esperando respostas imediatas. Imagine se, no mundo real, você tivesse que esperar na fila dos correios até que a pessoa recebesse e respondesse à sua carta. Seria extremamente ineficiente, não é? O mesmo vale para sistemas de software.
Quando um serviço não precisa esperar por uma resposta para continuar seu trabalho, ele pode operar de forma muito mais eficiente, lidando com várias tarefas ao mesmo tempo, sem ficar bloqueado por operações que demoram. Isso é essencial em sistemas complexos e de grande escala, onde a capacidade de processar grandes volumes de dados e interações de forma eficiente pode ser a diferença entre um sistema que escala e um que trava sob pressão.
Além disso, a comunicação assíncrona nos permite construir sistemas mais resilientes. Se um serviço estiver temporariamente indisponível, as mensagens ainda podem ser enviadas e processadas mais tarde, sem interromper o funcionamento de todo o sistema. Isso proporciona uma robustez que é muito difícil de alcançar com comunicação síncrona, onde a falha de um serviço pode causar o travamento de outros.
Vimos como a comunicação assíncrona nos permite enviar informações sem a necessidade de esperar por uma resposta imediata, um pouco como enviar uma carta pelo correio e seguir com o dia. Isso nos dá uma enorme liberdade para criar sistemas mais eficientes e resilientes. Mas, à medida que nos aprofundamos no funcionamento dessa comunicação, surge uma pergunta essencial: o que exatamente estamos enviando entre os sistemas quando usamos essa abordagem?
É aqui que a distinção entre eventos e mensagens se torna crucial. Embora comunicação assíncrona seja o "como" — a maneira como trocamos informações sem precisar de uma resposta instantânea —, precisamos entender "o que" está sendo trocado nessa comunicação.
Eventos e Mensagens: Entendendo a Diferença
Agora que já mergulhamos no conceito, é hora de explorar um tópico que, embora pareça simples à primeira vista, frequentemente gera confusão até mesmo entre programadores experientes: a diferença entre "eventos" e "mensagens".
Imagine que você está em uma festa e o momento exato em que o DJ solta a primeira música na pista de dança é o evento em si. Esse evento é um fato; algo que ocorreu e que marca o início da diversão. Mas, como você avisa seus amigos que a festa começou? Você pode mandar uma mensagem de texto, uma foto no grupo do WhatsApp ou até uma chamada rápida. A mensagem aqui é o meio pelo qual você comunica aos outros que o evento (a festa) começou.

No contexto de sistemas distribuídos, o evento é o que aconteceu: pode ser uma nova venda realizada, um pagamento processado, ou até mesmo um pedido sendo despachado. Ele é um registro de algo significativo que ocorreu em um sistema. Já a mensagem é como você comunica esse evento para outras partes do sistema, permitindo que elas reajam a ele de alguma maneira.
Essa distinção pode parecer clara agora, mas a verdade é que muitos desenvolvedores acabam confundindo esses dois conceitos. E não é por acaso. Em sistemas complexos, eventos e mensagens estão intimamente ligados e, muitas vezes, são utilizados em conjunto. Por exemplo, ao processar um pedido em um sistema de e-commerce, o evento "pedido realizado" pode ser encapsulado em uma mensagem e enviado para diferentes serviços que precisam saber dessa informação para realizar suas respectivas tarefas (como processar o pagamento, atualizar o estoque, ou notificar o cliente).

O que leva à confusão é que o evento e a mensagem frequentemente compartilham o mesmo conteúdo. Porém, é importante lembrar que o evento é o "o quê" — o fato que aconteceu — enquanto a mensagem é o "como" — o meio pelo qual essa informação é transmitida.
Programadores podem se confundir porque, no calor do desenvolvimento, a linha entre o "fato" e o "meio" pode se tornar borrada. Afinal, estamos sempre lidando com eventos encapsulados em mensagens, e essa proximidade pode nos levar a tratá-los como sinônimos. Mas reconhecer essa diferença é crucial para desenhar arquiteturas de software mais claras e eficientes.
Quando entendemos que o evento é o conteúdo, e a mensagem é apenas o transporte, conseguimos desenhar sistemas mais robustos. E, assim como na vida real, quando você separa o que aconteceu (o evento) de como você conta às pessoas (a mensagem), a comunicação se torna muito mais eficaz.
Além disso, essa clareza evita mal-entendidos e ajuda a manter o sistema organizado. Se você tratasse eventos e mensagens como se fossem a mesma coisa, poderia acabar enviando informações desnecessárias, ou pior, criando dependências entre partes do sistema que deveriam estar desacopladas. Isso pode levar a uma manutenção mais difícil, problemas de desempenho e até falhas que poderiam ter sido evitadas.
Outro ponto é que separar esses conceitos permite que você escolha as melhores ferramentas e estratégias para cada situação. Você pode usar um sistema de mensagens robusto para garantir que as informações sejam entregues com confiabilidade, enquanto utiliza eventos para desencadear ações em diferentes partes do sistema sem criar uma interdependência excessiva.
Embora a comunicação assíncrona brilhe aos olhos por todas as suas promessas de escalabilidade, resiliência e eficiência, é importante reconhecer que esse brilho também pode nos cegar para alguns desafios e armadilhas que ela traz. Assim como a tecnologia, que muitas vezes é vista como a solução para todos os problemas, a comunicação assíncrona, quando mal compreendida ou implementada de forma inadequada, pode introduzir complexidades que são difíceis de gerenciar. Vamos agora conversar mais sobre os desafios e pontos de atenção.
Os Desafios!
Vamos imaginar um sistema de processamento de pedidos em uma grande loja online. Cada vez que um cliente faz um pedido, várias operações precisam acontecer em paralelo: o pagamento deve ser processado, o estoque precisa ser atualizado, uma confirmação deve ser enviada ao cliente, e a logística deve ser notificada para preparar o envio. Em um sistema que utiliza comunicação assíncrona, essas operações podem ser enviadas como mensagens para diferentes serviços que as processam em tempos distintos. Isso permite que o sistema continue aceitando novos pedidos sem ficar preso esperando a confirmação de pagamento ou a atualização de estoque.
No entanto, esse cenário idealizado esconde algumas complicações. Vamos supor que o serviço responsável pelo pagamento fique temporariamente indisponível ou que a fila de mensagens fique sobrecarregada. De repente, pedidos que já foram confirmados pelo cliente podem não ser pagos, ou o estoque pode ser atualizado com atraso, levando a situações de overselling (vender mais do que o estoque disponível). Além disso, se a ordem de processamento das mensagens não for corretamente gerenciada, pode haver inconsistências, como o envio de um produto antes da confirmação de pagamento.
Esses são apenas alguns exemplos de como a comunicação assíncrona pode nos surpreender com desafios inesperados. Martin Fowler, comenta em um de seus artigos sobre microserviços que "a comunicação assíncrona é excelente para desacoplar sistemas e melhorar a escalabilidade, mas ao mesmo tempo, introduz uma complexidade significativa na gestão de estados e na garantia de consistência." Ele destaca que a dificuldade em gerenciar essas interações assíncronas pode levar a problemas de depuração, onde a causa de um erro pode estar em um ponto totalmente diferente do sistema em relação ao local onde o problema se manifesta.
Outro ponto a se considerar é a dificuldade de manter a visibilidade em sistemas distribuídos que utilizam comunicação assíncrona. Em sistemas síncronos, a cadeia de eventos é mais linear e previsível, o que facilita o rastreamento de falhas. Já em sistemas assíncronos, as mensagens podem seguir caminhos variados, dependendo do estado atual dos serviços, do tempo de resposta das filas, e até mesmo de falhas intermitentes de rede. Isso pode complicar muito o processo de identificação e correção de problemas.
Um exemplo teórico poderia ser um sistema bancário que usa comunicação assíncrona para processar transações entre contas. Se as mensagens que confirmam uma transferência de fundos não forem entregues ou processadas na ordem correta, isso pode levar a inconsistências críticas, como saldo incorreto nas contas dos clientes. A robustez que deveria ser garantida pela comunicação assíncrona pode, na verdade, se tornar um ponto de fragilidade se esses detalhes não forem cuidadosamente gerenciados.
Gerenciamento de Consistência Eventual
Imagine que você e seus amigos estão jogando um jogo de cartas, mas estão em diferentes salas da casa. Quando alguém faz uma jogada, eles gritam o movimento para que todos os outros saibam e possam ajustar suas cartas. Pode levar algum tempo até que todos ouçam e atualizem suas mãos, e, durante esse período, as cartas nas mãos de cada jogador podem parecer diferentes. No entanto, com o tempo, todos acabam recebendo a mensagem e ajustando suas cartas, garantindo que todos estejam em sincronia novamente.
Essa é a essência da consistência eventual: mesmo que as informações não estejam imediatamente sincronizadas em todos os lugares, eventualmente todas as partes do sistema refletirão o mesmo estado.
Agora, pense em um sistema de e-commerce que adota uma abordagem assíncrona. Imagine que o sistema permite que um cliente faça um pedido, e o pedido é confirmado antes que o processamento do pagamento tenha sido completamente concluído. Nesse cenário, o sistema pode ter um registro do pedido confirmado, enquanto o serviço de pagamento ainda está verificando se a transação foi bem-sucedida.
Se a transação falhar, haverá uma inconsistência temporária: o cliente pode ver o pedido como confirmado, mas o pagamento não foi realizado. Eventualmente, o sistema detectará a falha e corrigirá o estado, talvez cancelando o pedido ou solicitando uma nova tentativa de pagamento.
Manter a consistência eventual em sistemas assim exige estratégias cuidadosas, como mecanismos de compensação (para reverter transações), reconciliamento (para garantir que os estados inconsistentes sejam alinhados), ou auditorias periódicas (para revisar e corrigir discrepâncias). Essas estratégias adicionam complexidade ao sistema e requerem uma engenharia cuidadosa para evitar novos pontos de falha.
Sobrecarga de Mensagens e Backpressure
Outro desafio comum é a sobrecarga de mensagens, que pode acontecer quando um serviço envia mensagens mais rapidamente do que os destinatários conseguem processar. Isso pode levar a filas de mensagens excessivamente longas, latência crescente, e até a perda de dados se as filas atingirem sua capacidade máxima.
Para mitigar esses problemas, é necessário implementar mecanismos de backpressure, que basicamente "freiam" o envio de novas mensagens até que as anteriores tenham sido processadas. No entanto, implementar backpressure de forma eficiente não é simples. Requer um entendimento profundo do comportamento do sistema sob diferentes cargas e a capacidade de ajustar dinamicamente as taxas de envio e consumo de mensagens.
Falhas Silenciosas e Dead Letter Queues
Uma falha comum em sistemas assíncronos é o que chamamos de "falha silenciosa", onde uma mensagem não é processada corretamente, mas o sistema não falha visivelmente. Isso pode ocorrer devido a uma infinidade de razões: o serviço destinatário pode estar temporariamente indisponível, a mensagem pode estar corrompida, ou pode haver um erro na lógica de processamento. Vamos conversar mais sobre isso em breve. Mas como tentamos lidar com essas falhas?
Para lidar com isso, muitas arquiteturas implementam Dead Letter Queues (DLQs), que são filas especiais onde mensagens que falham repetidamente são enviadas para análise posterior. No entanto, essas filas são muitas vezes negligenciadas, levando a situações onde problemas críticos passam despercebidos por longos períodos. Gerenciar e monitorar DLQs de forma eficaz é essencial para garantir que falhas não se acumulem no sistema, mas isso requer disciplina operacional e ferramentas adequadas.
Esses problemas nos mostram que, enquanto a comunicação assíncrona nos oferece ferramentas poderosas, também precisamos estar cientes de que essas ferramentas vêm com suas próprias complexidades. A visão idealista de um sistema perfeitamente desacoplado e escalável pode nos cegar para os desafios reais que surgem na prática. Agora vamos ver e entender a perspectivas de outras programadores.
A Perspectiva de Sam Newman sobre a Comunicação Assincrona
Sam Newman, autor de livros sobre microserviços e outros assuntos, é uma das principais vozes na discussão sobre arquitetura distribuída, e ele oferece uma perspectiva bem equilibrada sobre os benefícios e desafios da comunicação assíncrona. Newman reconhece o poder e a flexibilidade que a comunicação assíncrona traz para arquiteturas distribuídas, mas ele também é cuidadoso em destacar os pontos de atenção que devem ser considerados ao adotar essa abordagem.
Uma das frases dele sobre o assunto é: "A comunicação assíncrona pode introduzir complexidade significativa, especialmente em termos de rastreamento e depuração." O que ele está destacando aqui é que, embora a comunicação assíncrona possa ajudar a desacoplar serviços e melhorar a escalabilidade, ela também torna o sistema menos previsível. Em sistemas síncronos, há uma sequência clara de chamadas e respostas, o que facilita a identificação de problemas. Em contraste, em sistemas assíncronos, as mensagens podem se mover através do sistema em tempos diferentes e tomar caminhos diferentes, tornando mais difícil rastrear a origem de um problema quando ele surge.
Newman também alerta sobre a "dificuldade em garantir a consistência dos dados" em sistemas que dependem fortemente de comunicação assíncrona. Como discutimos anteriormente, a consistência eventual é uma realidade em arquiteturas assíncronas, mas isso pode ser um grande desafio quando se trata de sistemas que requerem um alto grau de precisão e confiabilidade. Ele enfatiza que "ao projetar sistemas assíncronos, você deve estar preparado para lidar com a eventual inconsistência e garantir que isso não comprometa a integridade do sistema." Isso pode envolver a implementação de mecanismos de compensação, reconciliação periódica, ou até mesmo a aceitação de que certas operações podem falhar e precisam ser tratadas de maneira robusta.
Outro ponto interessante que Sam Newman levanta é sobre a "necessidade de uma boa observabilidade e rastreamento" em sistemas assíncronos. Ele diz que "sem uma infraestrutura adequada para rastrear mensagens e eventos através de múltiplos serviços, é muito fácil perder de vista o que está acontecendo no sistema." Isso é crítico porque, em um ambiente assíncrono, problemas podem surgir em qualquer ponto do pipeline de mensagens, e sem uma maneira de visualizar o fluxo de dados, as equipes de desenvolvimento podem acabar gastando muito tempo tentando diagnosticar problemas.
Além disso, Newman também aborda o risco de "acoplamento" que pode surgir em sistemas que utilizam comunicação assíncrona. "É fácil presumir que, por estarem se comunicando de forma assíncrona, os serviços estejam completamente desacoplados, mas isso nem sempre é verdade". Ele alerta que dependências ocultas podem surgir, especialmente se os serviços começarem a depender de determinados padrões de mensagem ou de tempos de resposta específicos. "A comunicação assíncrona pode criar a ilusão de independência quando, na verdade, os serviços estão firmemente entrelaçados por suas expectativas de troca de mensagens." Isso pode levar a problemas de manutenção e escalabilidade a longo prazo.
O autor enfatiza que o sucesso com comunicação assíncrona em microserviços requer não apenas uma boa compreensão dos benefícios, mas também um reconhecimento e mitigação dos desafios. Ele recomenda que as equipes sejam "deliberadas e conscientes" ao adotar padrões assíncronos, sempre considerando o impacto na complexidade geral do sistema. A mensagem central é que, embora a comunicação assíncrona possa ser extremamente poderosa, ela também exige uma abordagem cuidadosa para garantir que não introduza mais problemas do que resolve.
Então podemos ver que a comunicação assíncrona não é uma bala de prata. Precisamos dela obviamente pois ela oferece uma maneira poderosa de construir sistemas escaláveis e desacoplados, mas exige que os arquitetos e desenvolvedores estejam cientes das complexidades que vêm junto com essa flexibilidade.
Então vamos começar agora a conversar mais sobre algumas armadilhas que podemos encontrar em nosso dia a dia.
O Uso Errado de Queues em Comunicação Assíncrona
Quando se trata de sistemas distribuídos, é fácil cair na armadilha de acreditar que as filas são a solução mágica para todos os problemas de comunicação assíncrona. A ideia de desacoplar serviços, permitindo que cada um processe mensagens em seu próprio ritmo, pode parecer a resposta perfeita para lidar com a complexidade e a variabilidade de carga. No entanto, essa visão precipitada pode levar a um uso excessivo ou inadequado das filas, criando mais problemas do que soluções.
A Visão Precipitada: "Filas Resolvem Tudo"
Muitos programadores, especialmente aqueles que estão iniciando em arquiteturas de microserviços, podem ver as filas como uma ferramenta universal para resolver problemas de latência, escalabilidade e desacoplamento de serviços. A lógica parece clara: inserir uma fila entre dois serviços desacopla suas operações, permitindo que o produtor de mensagens continue seu trabalho independentemente da velocidade do consumidor. Isso, na teoria, deve reduzir gargalos e permitir que o sistema lide melhor com picos de carga.
No entanto, essa abordagem simplista pode ser enganosa. A realidade é que filas, quando mal implementadas ou utilizadas sem uma análise, podem introduzir novos desafios ao sistema. Acreditar que "filas resolvem tudo" ignora as nuances de como a comunicação assíncrona realmente funciona em um ambiente distribuído. Por exemplo, a introdução de uma fila pode adicionar complexidade ao fluxo de dados, aumentando a latência de ponta a ponta e dificultando a rastreabilidade de mensagens.
Quando filas são usadas indiscriminadamente, os problemas podem rapidamente se acumular. Uma das principais consequências é o acúmulo de mensagens que pode levar a uma sobrecarga. Sem uma estratégia clara para gerenciar o crescimento da fila, o sistema pode se tornar menos eficiente, com mensagens sendo processadas mais lentamente do que o esperado. Isso contraria o objetivo de usar filas para melhorar a performance.
Além disso, a introdução de filas em todos os pontos de comunicação pode criar uma falsa sensação de segurança. Engenheiros podem acreditar que, simplesmente porque uma fila foi inserida, o sistema agora é resiliente e capaz de lidar com falhas. No entanto, sem um planejamento adequado e sem considerar o comportamento dos serviços sob carga extrema, as filas podem se tornar pontos de estrangulamento, criando gargalos em vez de eliminá-los.
Repensando a Estratégia
É importante que todos entendam que filas não são a única ferramenta disponível para lidar com os desafios da comunicação assíncrona. Dependendo do contexto, outras estratégias como webhooks ou brokers de mensagens como Kafka podem ser mais adequadas. Webhooks, por exemplo, são ideais para notificações instantâneas onde a latência mínima é crítica, enquanto Kafka pode ser melhor em cenários onde grandes volumes de dados precisam ser ingeridos e processados de maneira eficiente.1
Ao projetar sistemas distribuídos, é essencial avaliar cada situação individualmente, considerando não apenas a necessidade imediata de desacoplamento, mas também os impactos de longo prazo no desempenho, na escalabilidade e na resiliência do sistema. A ideia de que "filas resolvem tudo" deve ser substituída por uma abordagem mais holística e estratégica, onde a escolha da ferramenta certa para o trabalho certo é guiada por uma compreensão profunda das necessidades e limitações do sistema.
As filas têm seu lugar em arquiteturas distribuídas, mas não são uma solução mágica para todos os problemas. A visão precipitada de que "filas resolvem tudo" pode levar a um uso inadequado que, em vez de melhorar, pode degradar o desempenho do sistema.
Mas o que acontece quando as coisas não saem como planejado? Mesmo quando as filas são implementadas com cuidado, falhas podem ocorrer – mensagens podem ser malformadas, serviços podem falhar temporariamente, ou as filas podem se encher inesperadamente. É aqui que as Dead Letter Queues (DLQs) entram em cena como uma ferramenta essencial para lidar com mensagens que não podem ser processadas de maneira normal.
Dead Letter Queues (Fila de mensagens não entregues)
Em sistemas distribuídos e assíncronos, lidar com falhas é parte integrante do processo. Nem todas as mensagens enviadas de um serviço para outro chegam ao seu destino final de maneira suave. Algumas ficam pelo caminho, seja por causa de um serviço temporariamente indisponível, uma mensagem corrompida, ou até mesmo um erro na lógica de processamento. Quando essas falhas ocorrem, precisamos de um mecanismo que permita detectar, analisar e, idealmente, corrigir esses problemas. É aqui que entram as Dead Letter Queues, ou DLQs.
O Que São Dead Letter Queues?
Podemos pensar em uma DLQ como a “caixa” onde vão parar as cartas que, por algum motivo, não puderam ser entregues ao destinatário. Imagine um serviço de correio que, ao tentar entregar uma carta, descobre que o endereço está incorreto ou que o destinatário não está disponível. Em vez de simplesmente descartar a carta, o serviço coloca essa correspondência em uma caixa especial onde cartas problemáticas são armazenadas até que possam ser revisadas e tratadas posteriormente.
Esse é o conceito básico por trás de uma DLQ em sistemas de mensagens assíncronas. Quando uma mensagem não pode ser processada após um certo número de tentativas — seja porque o serviço destinatário está indisponivel, a mensagem está malformada, ou há um erro de lógica — essa mensagem é desviada para a DLQ. O objetivo inicial dessas filas é permitir que os engenheiros de software possam revisitar essas mensagens falhadas, entender o que deu errado, e tomar as ações necessárias, seja corrigindo a mensagem, o código, ou até mesmo os dados que estão sendo processados.
A Percepção Errônea das DLQs
Apesar do objetivo claro das Dead Letter Queues (DLQs), muitos engenheiros têm uma visão equivocada de como elas devem ser usadas. Em vez de serem vistas como uma ferramenta para diagnóstico e correção de problemas, as DLQs acabam sendo tratadas como uma espécie de "caixa de descarte" onde as mensagens problemáticas simplesmente desaparecem, sem que ninguém preste a devida atenção. Isso cria um problema sério: as falhas silenciosas.
Mensagens que chegam a uma DLQ são indicativos de falhas no sistema — que podem ser pequenas ou isoladas, mas que, ao longo do tempo, podem se acumular e gerar grandes problemas. Vamos imaginar um sistema de envio de SMS para notificar clientes sobre o status de seus pedidos. Quando um pedido é confirmado, o sistema envia uma solicitação para a fila normal, de onde o serviço de SMS processa as mensagens e envia as notificações aos clientes.
Agora, imagine que algumas mensagens estão mal estruturadas — talvez com campos obrigatórios ausentes ou erros de formato. Nesse caso, o serviço de SMS tentaria processá-las, mas falharia, e essas mensagens seriam redirecionadas para a DLQ após o número máximo de tentativas de reprocessamento.
O sistema pode continuar funcionando normalmente para a maioria dos clientes, mas as mensagens que acabam na DLQ indicam que certas notificações críticas não foram enviadas corretamente. Se ninguém monitorar a DLQ e tomar as ações necessárias para tratar essas mensagens, alguns clientes podem nunca receber as atualizações de seus pedidos, levando a frustração e insatisfação.
Esse exemplo ilustra como as DLQs capturam falhas de mensagens que não podem ser processadas, mas também ressalta a importância de monitorá-las e agir proativamente para evitar a perda de mensagens importantes e manter a confiabilidade do sistema.
O Objetivo Inicial das DLQs e Onde Estamos Errando
O objetivo inicial das DLQs era atuar como um sistema de alerta para problemas que não puderam ser resolvidos no fluxo normal de mensagens. Essas filas foram projetadas para capturar erros que precisam de intervenção humana ou de processos automatizados de correção. Entretanto, o erro que muitos engenheiros cometem é tratar as DLQs como um depósito final de mensagens perdidas, sem estabelecer processos claros para revisar e tratar as mensagens que caem nessas filas.
Essa percepção errônea é perigosa porque transforma a DLQ de uma ferramenta proativa para a resolução de problemas em um buraco negro onde os erros se acumulam sem serem detectados. A DLQ não é um fim, mas sim um meio para um fim. O verdadeiro valor de uma DLQ vem de como ela é utilizada para identificar e corrigir problemas. Isso significa que as equipes de desenvolvimento e operação precisam estar atentas às mensagens que caem nessas filas, analisando-as regularmente e integrando processos que permitem corrigir as falhas que causaram essas mensagens a desviarem do fluxo normal.
Agora, vale a pena considerar como devemos abordar as DLQs em nossas arquiteturas. Dead Letter Queues são uma medida de segurança necessária, mas não podem ser uma desculpa para não resolver problemas reais no fluxo principal. Embora as DLQs sejam úteis para capturar falhas que poderiam passar despercebidas, elas não devem ser vistas como a solução final para esses problemas.
É tentador tratar as DLQs como uma rede onde você pode jogar todos os problemas e esquecê-los. Mas isso só adia o inevitável — um acúmulo de mensagens problemáticas que, eventualmente, pode se tornar incontrolável. A verdadeira eficácia de uma DLQ vem da capacidade de utilizá-la como um ponto de partida para melhorar continuamente o sistema, aprendendo com os erros e ajustando os processos para que as mensagens não precisem ser desviadas para a DLQ em primeiro lugar.
Falhas Silenciosas: O Perigo Oculto da Comunicação Assíncrona
Falhas silenciosas são uma das armadilhas mais traiçoeiras em sistemas de microserviços que utilizam comunicação assíncrona. Diferente de falhas evidentes, onde um serviço ou uma operação falha de maneira clara e gera alertas imediatos, as falhas silenciosas passam despercebidas, sem gerar alarmes óbvios, mas ainda assim comprometem o funcionamento do sistema.
Imagine que você está em um grande evento de música ao vivo. Cada instrumento de uma orquestra toca uma parte essencial da música, mas eles estão tocando sem a regência de um maestro. Agora, imagine que um dos instrumentos, como o violino, começa a tocar uma nota errada de forma intermitente. Essa nota errada é sutil, quase imperceptível, e por isso passa despercebida pela maioria dos ouvintes. O show continua, a plateia parece satisfeita, mas há algo na música que não soa perfeitamente como deveria.
Com o tempo, essas notas erradas começam a se acumular e, embora não sejam altas o suficiente para parar a música, elas começam a distorcer a melodia. A audiência não percebe imediatamente o problema porque o erro é pequeno e esporádico, mas o impacto se torna claro quando a harmonia geral começa a se desfazer. Apenas quando alguém começa a analisar a gravação ou um ouvinte com um ouvido muito atento nota algo errado, percebe-se que a música perdeu parte de sua beleza e precisão por conta dessas pequenas falhas que passaram despercebidas.
Da mesma forma, em sistemas de microserviços, as falhas silenciosas são como essas notas erradas: elas não interrompem o funcionamento do sistema, mas, ao acumular pequenas distorções, podem comprometer a integridade do resultado final. O sistema continua operando, mas as partes críticas podem estar sendo afetadas sem que ninguém perceba imediatamente, levando a problemas maiores no futuro.
Uma falha silenciosa pode ocorrer, por exemplo, quando uma mensagem é desviada para uma Dead Letter Queue, conforme comentamos anteriormente, devido a um erro sutil, como um campo faltando no payload da mensagem. Vamos imaginar que um campo obrigatório, como um identificador de cliente, esteja ausente. Essa ausência não vai, necessariamente, parar todo o sistema, mas fará com que aquela mensagem específica não seja processada corretamente. Sem esse campo, o serviço que deveria consumir a mensagem não consegue completar sua tarefa, e a mensagem acaba na DLQ.

O problema é que essa falha não gera um erro evidente no sistema. O processo pode continuar funcionando para outras mensagens, e a equipe de desenvolvimento pode nem perceber que algo está errado. A mensagem problematica fica "escondida" na DLQ, criando uma falha silenciosa.
A complexidade dessas falhas reside na dificuldade de detectá-las e depurá-las. Em muitos casos, a mensagem que caiu na DLQ pode ter sido enviada há horas ou dias, e o sistema já processou milhares de outras mensagens desde então. A falha, portanto, não é imediatamente visível, e pode exigir uma análise detalhada de logs, rastreamento de eventos, e investigação dos serviços envolvidos para entender o que deu errado.
Essa complexidade aumenta ainda mais quando consideramos que essas falhas silenciosas podem se acumular ao longo do tempo, especialmente em sistemas com alto volume de mensagens. Se não forem identificadas e resolvidas, essas falhas podem levar a atrasos nas entregas de funcionalidades, interrupções inesperadas, e uma crescente frustração tanto para a equipe de desenvolvimento quanto para os usuários finais.
Imagine o impacto em um cenário de negócios onde essas mensagens são críticas, como no processamento de pedidos ou na comunicação com clientes. Um campo ausente pode não parecer um grande problema inicialmente, mas se a falha silenciosa persistir, pode causar inconsistências nos dados, gerar erros em relatórios financeiros, ou até mesmo resultar em perda de receita.
Além disso, depurar essas falhas pode ser extremamente desafiador. Sem monitoramento adequado e ferramentas de rastreamento, identificar a causa raiz pode se tornar uma tarefa árdua, exigindo uma revisão detalhada de cada ponto do sistema onde a mensagem passou. Isso não só atrasa a resolução do problema, mas também atrasa a entrega de novas funcionalidades, já que a equipe precisa dedicar tempo e recursos para resolver essas questões ocultas.
Como Mitigar esse Risco?
Para mitigar as falhas silenciosas em uma comunicação assíncrona, os engenheiros precisam adotar uma abordagem que vá além do simples monitoramento básico. A chave é criar uma camada de visibilidade e controle que permita identificar e resolver essas falhas antes que elas se tornem um problema maior. Isso envolve uma combinação de práticas de engenharia, ferramentas adequadas e uma mentalidade proativa.
Primeiro, um dos passos fundamentais é implementar um monitoramento robusto. Isso significa configurar alertas que não apenas detectem falhas óbvias, mas também identifiquem padrões incomuns ou comportamentos que possam indicar que algo está fora do normal, mesmo que o sistema ainda esteja aparentemente funcionando. Por exemplo, se o número de mensagens desviadas para a DLQ começar a aumentar de forma sutil, isso deve acionar um alerta para que a equipe possa investigar antes que o problema se agrave.
Além do monitoramento, tracing é uma ferramenta poderosa para rastrear o caminho de cada mensagem através dos diferentes serviços. Com o tracing, os engenheiros podem seguir uma mensagem desde sua origem até o destino final, identificando exatamente onde algo deu errado. Isso não só ajuda a detectar falhas silenciosas, como também torna a depuração muito mais eficiente, permitindo que a equipe encontre rapidamente a causa raiz de um problema sem precisar analisar grandes volumes de logs manualmente.
Outra prática importante é validar rigorosamente as mensagens antes de enviá-las para os serviços de destino. Implementar validações estritas nos serviços produtores, como verificar a presença de todos os campos obrigatórios e garantir que os dados estejam no formato correto, pode evitar que mensagens incorretas sejam enviadas em primeiro lugar. Isso reduz a probabilidade de que mensagens falhas acabem na DLQ devido a problemas que poderiam ter sido evitados.
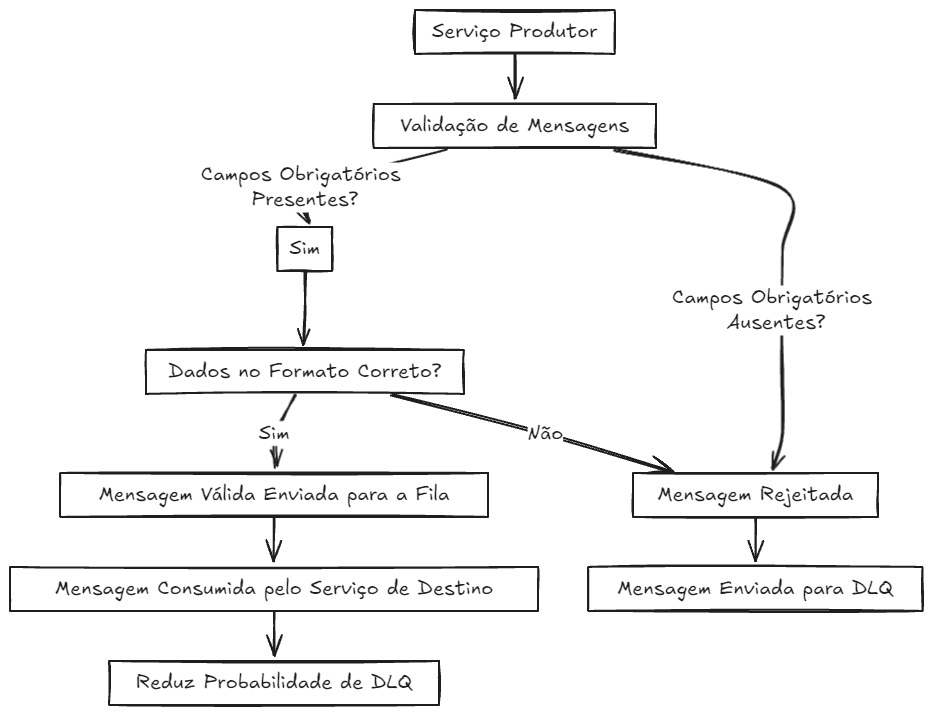
Além disso, processos de replay automatizados podem ser úteis para reprocessar mensagens que caem na DLQ, uma vez que o problema subjacente tenha sido resolvido. No entanto, é crucial garantir que o reprocessamento seja feito de forma controlada, para evitar que mensagens sejam reencaminhadas para a DLQ repetidamente. Isso requer que os engenheiros compreendam bem o que causou a falha inicial e que as correções sejam efetivas.
Outra estratégia é realizar auditorias regulares nas DLQs. Isso não significa apenas verificar se há mensagens na fila, mas sim analisar os tipos de falhas que estão acontecendo e ajustar o sistema para prevenir que essas falhas se repitam. As auditorias podem revelar padrões que não são evidentes no dia a dia, permitindo que a equipe faça melhorias contínuas.
Finalmente, cultivar uma cultura de comunicação e aprendizado contínuo dentro da equipe de desenvolvimento é essencial. Quando uma falha silenciosa é identificada e resolvida, a equipe deve compartilhar o conhecimento adquirido com todos os membros, documentar a causa raiz e as ações tomadas para evitar que o problema aconteça novamente. Essa prática não só fortalece o sistema a longo prazo, mas também aumenta a resiliência da equipe.2
Agora vamos conversar sobre algo muito importante em um ecossistema que se comunica de maneira assíncrona.
Problemas de Latência e Tempo de Resposta em Comunicação Assíncrona
Mesmo em uma arquitetura assíncrona, onde as mensagens são enviadas sem a necessidade de uma resposta imediata, o tempo de resposta do sistema como um todo pode ser comprometido, e o impacto pode ser significativo, especialmente em aplicações que exigem alta performance e baixa latência.
Para entender como isso acontece, imagine que você está em uma fila no banco. Se há apenas uma pessoa à sua frente, o atendimento é rápido. Mas se a fila começa a crescer, o tempo que você leva para ser atendido aumenta, mesmo que o banco tenha várias janelas de atendimento. O problema pode ser agravado se, por exemplo, um dos atendentes estiver mais lento do que o normal ou se houver uma operação mais complexa que todos os atendentes estão lidando. Nesse cenário, adicionar mais pessoas na fila apenas aumenta o tempo de espera para todos.
Em sistemas distribuídos, algo semelhante acontece. Se o serviço consumidor está sobrecarregado ou lidando com tarefas complexas, adicionar mais mensagens na fila só aumenta o tempo de resposta para cada mensagem individual. A latência não é mais apenas o tempo que leva para processar uma mensagem, mas também o tempo que a mensagem passa esperando na fila antes de ser processada.
A Fila Crescente e a Latência
Vamos imaginar um sistema de atendimento ao cliente em uma grande empresa de telecomunicações. Quando um cliente solicita suporte técnico, o sistema precisa executar várias etapas: identificar o problema, verificar o histórico de serviços do cliente, e, se necessário, agendar uma visita técnica. Em uma arquitetura de comunicação assíncrona, o serviço que recebe a solicitação do cliente coloca uma mensagem em uma fila para o serviço de diagnóstico, que analisa o problema relatado. Em seguida, outra mensagem é enviada para o serviço responsável por verificar a disponibilidade de técnicos, e assim por diante.
Inicialmente, essa abordagem parece eficiente. Cada serviço opera de maneira independente, e a comunicação assíncrona permite que o sistema continue processando outras solicitações sem precisar esperar que cada etapa seja concluída em sequência. No entanto, a situação pode se complicar quando a fila de mensagens começa a crescer.
Quando uma mensagem é colocada em uma fila, o tempo necessário para que ela seja processada depende de quantas outras mensagens já estão na fila e de quão rapidamente os serviços consumidores conseguem lidar com elas. Se, por algum motivo, o processamento desacelerar — talvez devido a uma sobrecarga no serviço de diagnóstico ou a um aumento inesperado nas solicitações de suporte — as mensagens começam a se acumular. Isso cria um efeito cascata: quanto mais mensagens na fila, mais tempo cada nova mensagem levará para ser processada.
Essa latência adicional pode se tornar perceptível para o cliente. Por exemplo, se o serviço de verificação de disponibilidade de técnicos está sobrecarregado e não consegue processar as mensagens rapidamente, o tempo total para agendar uma visita técnica aumenta. Mesmo que o sistema continue funcionando tecnicamente, o cliente pode ter que esperar mais tempo para receber uma solução para o seu problema.

Por que Escalar Mais Pods Nem Sempre Resolve
A ideia de escalar horizontalmente, adicionando mais instâncias do serviço (ou pods, se você estiver usando Kubernetes), parece uma solução lógica e direta para lidar com problemas de latência e capacidade. No entanto, isso tem suas limitações e pode, em alguns casos, até agravar os problemas que estamos tentando resolver. Por que?
Quando você adiciona mais pods, cada um desses pods precisa de recursos para funcionar – CPU, memória, e largura de banda de rede. No entanto, esses recursos são finitos. Imagine que todos esses pods estão sendo executados em um cluster de servidores. Se o cluster estiver rodando no limite da capacidade de hardware, adicionar mais pods não trará o benefício esperado.
Por exemplo, se a sua aplicação está limitada pelo processamento de banco de dados, adicionar mais pods não resolve o problema porque o banco de dados, que é um recurso compartilhado, continua sendo o gargalo. Em outras palavras, você está apenas criando mais instâncias que competem pelo mesmo conjunto de recursos escassos, e o impacto será mínimo.
Além disso, em ambientes de nuvem, escalar horizontalmente pode também aumentar os custos de forma significativa. Mesmo que você tenha recursos disponíveis, há um custo financeiro para cada instância adicional que pode não se justificar se o ganho de performance for marginal.

Contenção de Recursos
A contenção de recursos é outro problema crítico. Quando você escala horizontalmente, todos os pods ou instâncias precisam acessar recursos compartilhados, como um banco de dados central, um serviço de cache, ou até mesmo a rede. À medida que o número de pods aumenta, todos eles competem por esses recursos.
Vamos considerar o exemplo de um banco de dados centralizado. Se você adicionar mais pods que fazem consultas frequentes ao banco de dados, é provável que o banco se torne o gargalo. Isso porque, apesar de haver mais pods tentando processar mensagens, o tempo de espera para acessar o banco de dados aumenta, levando a uma latência mais alta para todos os serviços que dependem desse banco.
Essa contenção de recursos pode criar um efeito dominó, onde o aumento de pods não apenas falha em melhorar o desempenho, mas também degrada o desempenho de todo o sistema. O resultado é um sistema que, apesar de ter mais instâncias, opera de forma menos eficiente.
Complexidade de Sincronização
À medida que você adiciona mais instâncias de serviço, a complexidade de sincronização entre essas instâncias também aumenta. Em sistemas assíncronos, pode haver a necessidade de coordenar o estado entre diferentes instâncias de serviço para garantir a consistência dos dados.
Por exemplo, se vários pods estão processando diferentes partes de uma transação financeira, todos precisam estar em sincronia para garantir que a transação seja completa e consistente. Se a sincronização não for bem gerida, você pode introduzir latência adicional enquanto os pods tentam se coordenar, ou pior, pode haver inconsistências nos dados que podem levar a erros de processamento.
Em sistemas distribuídos, essa complexidade de sincronização pode ser exacerbada pela necessidade de coordenação entre pods em diferentes regiões geográficas ou em diferentes clusters. Cada nova instância adicionada ao sistema aumenta essa complexidade, o que pode levar a uma redução na eficiência geral do sistema.
Aumento da Latência em Cascata
Quando uma fila de mensagens já está crescendo rapidamente, adicionar mais instâncias para processar essas mensagens pode parecer uma boa solução. No entanto, isso pode ter um efeito paradoxal. À medida que mais instâncias tentam consumir as mensagens da fila, você pode acabar aumentando o número de mensagens colocadas na fila, se as instâncias estão gerando novas mensagens como parte de seu processamento.
Por exemplo, se cada instância que processa uma mensagem também gera outras mensagens para diferentes serviços, você acaba adicionando mais carga à fila. Isso pode criar um ciclo vicioso onde a tentativa de melhorar o desempenho acaba gerando mais trabalho para o sistema, levando a uma latência ainda maior.
Esse efeito em cascata significa que, em vez de aliviar a pressão sobre o sistema, você está apenas redistribuindo o problema de forma que ele se espalhe por mais partes do sistema. A fila de mensagens continua a crescer, e o tempo total para processar todas as mensagens pode aumentar, ao invés de diminuir.
A escalabilidade horizontal, não é uma solução mágica para problemas de latência em sistemas assíncronos. Como vimos, recursos limitados, contenção de recursos, complexidade de sincronização, e o risco de aumentar a latência em cascata são fatores que podem tornar essa abordagem ineficaz ou até mesmo contraproducente.
Vamos comentar sobre algumas estratégias que podem ajudar a mitigar os problemas de latência em sistemas assíncronos. Sabemos que em sistemas distribuídos, a latência pode surgir de formas inesperadas, mesmo em arquiteturas assíncronas, onde imaginamos que tudo fluiria de maneira suave e sem esperas. No entanto, a realidade é um pouco mais complicada, e é aí que entram algumas abordagens que podem fazer a diferença. Vamos falar sobre elas com mais detalhe e também os possíveis desafios que você pode enfrentar ao implementá-las.
Estratégias para Otimizar a Performance em Comunicação Assíncrona
Quando falamos de otimizar a comunicação assíncrona, estamos realmente buscando maneiras de tornar nossos sistemas mais eficientes e resilientes. Não existe uma bala de prata; cada abordagem tem suas vantagens e desafios. Vamos dar uma olhada em algumas estratégias que podem ajudar a melhorar a performance do seu sistema, sempre lembrando que o contexto é tudo.
Rate Limiting: Controlando o Acesso
Imagine uma estrada com um limite de velocidade. Rate limiting funciona exatamente assim: ele define quantas solicitações o sistema ou uma API pode receber em um determinado período de tempo. Isso impede que o sistema fique sobrecarregado quando há um pico de demanda.
Funciona assim: quando o limite é atingido, o sistema pode rejeitar as solicitações adicionais e pedir ao usuário para tentar novamente mais tarde, ou pode colocar essas solicitações em uma fila de espera. Dependendo do caso, o sistema pode até ajustar o limite dinamicamente com base na carga atual.
Essa técnica é especialmente útil em cenários onde a estabilidade é mais importante que a velocidade imediata. Mas, como tudo, tem seu lado B: se não for bem calibrado, pode deixar usuários esperando ou até piorar a experiência durante picos de acesso.
Prioridade de Mensagens
Nem todas as mensagens são iguais, certo? Em um sistema de suporte ao cliente, por exemplo, resolver uma falha crítica é muito mais urgente do que uma solicitação para alterar uma configuração. Por isso, faz sentido dar prioridade às mensagens mais importantes.
No entanto, há um porém: se você sempre prioriza certas mensagens, as de menor prioridade podem acabar esquecidas, acumulando-se na fila. Imagine um restaurante que só prepara os pratos mais complexos e deixa os pedidos simples para depois – os clientes que pediram algo simples acabam esperando mais do que o necessário.
Priorizar mensagens é uma boa estratégia, mas requer um equilíbrio cuidadoso para que as tarefas menos urgentes também sejam resolvidas em tempo hábil.
Circuit Breakers: Um Filtro Inteligente
Circuit breakers são como os fusíveis da sua casa. Quando um serviço está sobrecarregado ou falhando, o circuit breaker interrompe o fluxo de novas mensagens, dando tempo para o serviço se recuperar.
Isso evita que o problema se agrave, mas também pode criar um efeito colateral: as mensagens que foram bloqueadas ficam esperando, e quando o circuit breaker desativa, todas elas chegam de uma vez, potencialmente sobrecarregando o serviço de novo. Por isso, é essencial gerenciar essa situação com cuidado, talvez processando as mensagens em lotes menores ou com uma prioridade ajustada.
Tuning de Recursos: Dando o Melhor para Quem Precisa
Você já deve ter passado por isso: em um sistema crítico, como um serviço de monitoramento em tempo real, os recursos nunca parecem suficientes. O tuning de recursos é sobre garantir que os serviços mais importantes tenham o que precisam para funcionar sem problemas, mesmo durante picos de demanda.
Isso exige um bom entendimento do que cada serviço realmente precisa. Se você superdimensionar um serviço, pode acabar deixando outros sem os recursos necessários, criando novos gargalos. É uma questão de balancear as necessidades, ajustando constantemente conforme o uso do sistema evolui.
Filas Distribuídas: Espalhando o Trabalho
Agora, imagine um grande evento esportivo acontecendo em várias cidades ao mesmo tempo. Em vez de ter um único centro de venda de ingressos, você espalha pontos de venda por cada cidade. Isso reduz o tempo de espera para os fãs, que compram ingressos localmente, mas também adiciona complexidade na hora de sincronizar tudo.
Distribuir filas entre diferentes serviços ou regiões pode reduzir a latência, mas também pode introduzir novos desafios, como manter os dados sincronizados e garantir que todas as filas estejam consistentes. Se não for bem gerenciado, isso pode acabar criando mais latência e problemas do que resolver.
Batch Processing: Processando em Lotes
O batch processing é como fazer várias tarefas de uma vez em vez de uma por uma. Se você tem que enviar mil e-mails, por exemplo, é muito mais eficiente agrupá-los e enviar cem de cada vez.
A desvantagem? Essa abordagem pode introduzir um pequeno atraso, especialmente em sistemas que exigem respostas rápidas. Em contextos onde o tempo é crítico, essa latência pode ser um problema, então é preciso avaliar se os benefícios superam os riscos.
Perguntas que precisam ser feitas!
Implementar estratégias de comunicação assíncrona pode parecer complicado, mas é crucial para garantir que seu sistema funcione de maneira eficiente, seja resiliente e consiga escalar conforme necessário. Para ajudar você a escolher as estratégias certas, aqui estão algumas perguntas que vale a pena considerar:
Quais São as Prioridades dos Meus Serviços?
Pense: Quais serviços ou funcionalidades são absolutamente essenciais para o funcionamento do sistema e para a experiência do usuário?
Por que isso importa? Saber quais serviços são críticos vai ajudar você a decidir onde concentrar mais recursos, onde aplicar circuit breakers e quais mensagens devem ser tratadas com mais urgência.
Como é o Perfil de Tráfego do Meu Sistema?
Pergunte-se: Como o tráfego varia ao longo do dia, da semana ou durante eventos específicos? Existem picos previsíveis?
Por que isso importa? Entender os padrões de tráfego permite que você implemente rate limiting e ajuste os recursos de maneira mais eficiente, evitando sobrecargas em horários de pico.
Como Lido com a Latência?
Reflita: Qual é a tolerância à latência no meu sistema? Posso aceitar pequenos atrasos ou preciso de respostas em tempo real?
Por que isso importa? Avaliar a importância da latência vai ajudar você a decidir se técnicas como batch processing ou filas distribuídas são as mais adequadas para o seu cenário.
Estou Preparado para Lidar com Falhas?
Considere: Como meu sistema reage quando um serviço falha? Tenho mecanismos para impedir que uma falha se propague?
Por que isso importa? Circuit breakers são ótimos para isolar falhas, mas é fundamental ter um plano de recuperação e estar preparado para gerenciar o acúmulo de mensagens quando o serviço voltar ao normal.
Como Monitoro e Ajusto Meu Sistema?
Pergunte-se: Quais ferramentas estou usando para monitorar o desempenho e o estado dos meus serviços? Estou pronto para fazer ajustes conforme necessário?
Por que isso importa? O monitoramento contínuo e a capacidade de fazer ajustes dinâmicos são essenciais para manter o sistema funcionando de forma eficiente e resiliente à medida que as condições mudam.
A Sincronização Está Criando Problemas?
Pense: Minhas filas distribuídas estão introduzindo mais problemas do que resolvendo? A sincronização entre regiões ou serviços está causando inconsistências?
Por que isso importa? Avaliar se a complexidade adicional de manter filas distribuídas sincronizadas está realmente compensando a redução na latência ou se está criando novos gargalos pode ser crucial para o desempenho do sistema.
Conclusão
Neste artigo, exploramos armadilhas associados à comunicação assíncrona em arquiteturas de microserviços. Desde a tentação de considerar as filas como uma solução mágica para todos os problemas até os perigos das falhas silenciosas e como elas ocorrem.
A comunicação assíncrona oferece grandes benefícios em termos de escalabilidade e desacoplamento temporal, mas esses benefícios vêm com seus próprios riscos.
Em última análise, a chave para o sucesso em arquiteturas distribuídas é o equilíbrio. Na parte dois desse artigo vamos continuar a conversar e discutir mais tópicos que merecem atenção.
Aqui vou citar brevemente algumas das opções que você pode estudar e implementar:
Eventos e Pub/Sub (Publicação/Assinatura):
Descrição: O padrão Pub/Sub é uma forma de comunicação assíncrona onde componentes do sistema publicam eventos que outros componentes podem assinar. Isso cria um alto nível de desacoplamento, pois não há uma ligação direta entre quem publica e quem consome o evento.
Uso Comum: Ideal para sistemas onde múltiplos serviços precisam reagir ao mesmo evento de maneiras diferentes. Por exemplo, quando uma nova transação é processada, um serviço pode atualizar o saldo, outro enviar uma notificação, e outro registrar o evento para auditoria.
Ferramentas: Kafka, Redis Pub/Sub, Amazon SNS.
Callbacks:
Descrição: Em callbacks, uma função ou serviço assíncrono é invocado, e quando a operação é concluída, uma função de callback é chamada para processar o resultado. Isso é comum em APIs, onde a resposta ou o resultado de uma chamada inicial é tratado posteriormente.
Uso Comum: Muito usado em integrações de APIs, especialmente em chamadas HTTP assíncronas e frameworks JavaScript.
Ferramentas: Callbacks são mais um padrão de programação do que uma ferramenta específica, mas são amplamente suportados por diversos frameworks e bibliotecas.
Polling (Interrogação):
Descrição: No polling, um sistema verifica regularmente um recurso ou serviço para saber se uma tarefa foi concluída ou se há novos dados disponíveis. Embora não seja a forma mais eficiente, é útil quando não é possível implementar uma comunicação push.
Uso Comum: Adequado para sistemas onde a resposta em tempo real não é crítica ou quando há limitações técnicas para uma comunicação em tempo real.
Ferramentas: Pode ser implementado diretamente em scripts com ciclos de espera ou utilizando cron jobs.
Webhooks:
Descrição: Webhooks permitem que um serviço envie uma requisição HTTP POST para um URL específico quando um evento ocorre. Em vez de um sistema ficar constantemente verificando por novos dados, o serviço que detecta a mudança notifica diretamente o sistema interessado.
Uso Comum: Muito utilizado em integrações de sistemas, onde um serviço externo precisa notificar o sistema local sobre a ocorrência de um evento, como quando uma transação é completada em um serviço de pagamento.
Ferramentas: Webhooks são amplamente adotados por APIs modernas, como Stripe, GitHub, e outros serviços SaaS.
Para implementar um monitoramento robusto, é fundamental utilizar ferramentas que ofereçam não apenas visibilidade em tempo real, mas também a capacidade de identificar padrões e anomalias. Prometheus é uma excelente escolha para a coleta de métricas, especialmente quando combinado com Grafana para a visualização dessas métricas em dashboards. Com essas ferramentas, é possível configurar alertas personalizados que disparam quando certas condições são atendidas, como um aumento no número de mensagens desviadas para a DLQ. Esses alertas podem ser integrados com sistemas de notificação como PagerDuty ou Slack, garantindo que a equipe seja imediatamente informada de qualquer anomalia.
Além disso, o uso de AWS CloudWatch ou Azure Monitor pode ser particularmente útil em ambientes que utilizam serviços em nuvem, pois essas ferramentas oferecem integrações nativas com vários serviços, permitindo o monitoramento profundo das operações do sistema, inclusive DLQs. Ambas as ferramentas oferecem a capacidade de configurar alarmes com base em métricas personalizadas, como a taxa de crescimento de mensagens em uma DLQ.
Tracing Distribuído para Rastreabilidade
O tracing distribuído é essencial para seguir o caminho de uma mensagem através de diferentes microserviços. Ferramentas como Jaeger e Zipkin são amplamente utilizadas para implementar tracing distribuído. Essas ferramentas capturam informações detalhadas sobre cada passo que uma mensagem ou solicitação toma dentro de um sistema distribuído. Integrá-las com frameworks de microserviços como Spring Cloud (no ecossistema Java) facilita a implementação de tracing em cada serviço, permitindo que os engenheiros visualizem a trajetória completa das mensagens e identifiquem rapidamente onde uma falha ocorreu.
OpenTelemetry é outra ferramenta poderosa, pois fornece uma solução unificada para métricas, logs e tracing. Com ela, é possível monitorar o desempenho de cada componente de um sistema distribuído e detectar falhas silenciosas, analisando o percurso completo das mensagens em um só lugar.
Validação de Mensagens Rigorosa
Para garantir que as mensagens sejam validadas rigorosamente antes de serem enviadas para os serviços de destino, é essencial implementar mecanismos de validação no nível de aplicação. Frameworks como JSON Schema podem ser utilizados para definir e validar a estrutura de mensagens JSON antes que elas sejam colocadas em uma fila. Isso assegura que todas as mensagens contenham os campos obrigatórios e estejam no formato correto.
No mundo Java, bibliotecas como Hibernate Validator podem ser usadas em conjunto com Spring Boot para validar objetos antes de serem serializados e enviados para filas. Além disso, implementar testes de contrato utilizando ferramentas como Pact pode ajudar a garantir que as mensagens trocadas entre serviços sigam estritamente os contratos definidos, minimizando a chance de erros na produção.
Processos de Replay Automatizados
Automatizar o replay de mensagens da DLQ pode ser feito utilizando scripts ou ferramentas específicas que reprocessam as mensagens, uma vez que os problemas foram resolvidos. AWS Lambda, por exemplo, pode ser configurado para monitorar uma DLQ e, assim que um erro é corrigido, pode reprocessar automaticamente as mensagens, enviando-as de volta para a fila principal.
No Kubernetes, você pode implementar um Job ou CronJob que periodicamente verifica as DLQs e reprocessa as mensagens. É importante que esses processos de replay sejam configurados com salvaguardas, como limites de tentativas e validações adicionais, para evitar que mensagens defeituosas sejam reprocessadas indefinidamente.