
Cuidado com Domínios Anêmicos!
A verdadeira essência da orientação a objetos é perdida quando nos contentamos com domínios anêmicos.

O cenário do desenvolvimento de software é repleto de metodologias, padrões e práticas que surgem com o objetivo de otimizar processos, melhorar a qualidade do código e, sobretudo, atender às demandas de negócios em constante evolução. No entanto, nem todas essas práticas são isentas de críticas ou controvérsias. Uma delas, que tem gerado debates entre desenvolvedores e arquitetos de software, é o modelo conhecido como "Domínio Anêmico".
Caracterizado por uma separação entre dados e regas de negócios, o domínio anêmico, à primeira vista, pode parecer uma abordagem simplificada e direta para modelagem de software. No entanto, por trás dessa simplicidade, escondem-se uma série de desafios e potenciais armadilhas que podem comprometer a robustez, manutenibilidade e evolução de um sistema.
Neste artigo, vamos explorar a fundo os problemas associados aos domínios anêmicos, buscando compreender as raízes desses desafios e como eles podem afetar projetos de software em diferentes contextos. Vamos falar muito sobre o tema e analisar seus pontos fracos e as razões por trás das críticas frequentemente dirigidas a essa abordagem.
Se gostar do conteúdo, por favor, compartilhe e deixe seu like no post! Isso me ajuda e incentiva a continuar a trazer conteúdos em forma de texto também!😄
História e Origens: Quando os Modelos de Domínio Se Tornaram "Anêmicos"
Antes de mergulharmos na história tumultuada dos modelos de domínio anêmicos, vamos entender o que é modelagem de domínio. A modelagem de domínio é basicamente a representação do conhecimento e da lógica relacionados a um domínio de problema específico. Imagine que você está tentando criar um software para uma biblioteca. Nesse caso, você teria coisas como "Livros", "Empréstimos", "Usuários", etc. Esses são conceitos do seu domínio, e como eles interagem entre si forma a base da sua modelagem.
Agora, já que estamos esclarecidos sobre a modelagem de domínio, vamos abordar o intrigante termo "anêmico". Ao ouvir a palavra "anêmico", muitas pessoas provavelmente se lembram da última vez que se sentiram um pouco pálidas e sem energia após doar sangue ou de um diagnóstico médico relacionado à falta de ferro. Em medicina, a anemia é uma condição na qual você não tem glóbulos vermelhos suficientes para transportar oxigênio adequado para os tecidos do corpo. Em resumo: algo vital está faltando!
Então, como esse termo médico sombrio e um pouco deprimente se relaciona com software? Bem, é basicamente uma metáfora apropriada! Um modelo de domínio "anêmico" é aquele que carece de algo vital: comportamentos ricos. São modelos que têm todos os dados, mas nenhuma lógica. É como ter um livro (o objeto) sem nenhuma história dentro (o comportamento), apenas palavras jogadas ao vento. Imagine, que tédio seria folhear página após página em branco!
Agora, você deve estar se perguntando: "Quem em sã consciência criaria um livro sem história?!" E é aí que entram os frameworks ORM (Object-Relational Mapping).
Houve um tempo, meus caros, em que os programadores ficaram absolutamente encantadas com os ORMs. E por que não ficariam? Estes pequenos pedaços mágicos de frameworks prometiam tornar a persistência de dados (salvar nossos preciosos dados em bancos de dados) tão simples quanto brincar de Lego. E eles realmente cumpriram essa promessa... com algumas pequenas pegadinhas.
A abstração que os ORMs trouxeram facilitou a vida dos desenvolvedores em muitos aspectos.1 No entanto, com o foco quase exclusivo na persistência de dados, a linha entre o que era lógica de negócios e o que era lógica de persistência começou a ficar um pouco... borrada. Em vez de construir modelos de domínio robustos e ricos em comportamentos, começamos a construir modelos que se pareciam mais com simples transportadores de dados, perfeitos para ORMs, mas que deixavam de lado a verdadeira essência da modelagem orientada a objetos. E assim, quase sem querer, estávamos produzindo modelos anêmicos em massa, como se estivéssemos em uma linha de montagem de carros sem motores!
Essa separação entre dados e comportamentos começou a se tornar a norma. Muitos desenvolvedores, intoxicados pela facilidade dos ORMs, esqueceram que o coração da modelagem orientada a objetos não é apenas sobre dados; é sobre capturar comportamento, encapsulamento, interação e, bem, vida!
Em resumo, como a maioria das histórias envolvendo humanos e tecnologia, começou com as melhores intenções. Pegamos uma ferramenta maravilhosa, os ORMs, e talvez tenhamos nos empolgado um pouco demais. No processo, deixamos de lado alguns dos princípios mais básicos do design orientado a objetos, levando à propagação dos modelos de domínio anêmicos.
E assim, enquanto navegamos por esse mar de modelos de domínio, é bom lembrar que, assim como um corpo precisa de glóbulos vermelhos para funcionar corretamente, nossos modelos de domínio precisam de comportamento para realmente brilhar. Mas não desanime, caro leitor! Este não é o fim da história... pois os modelos anêmicos podem ser curados, e temos muitas aventuras (e tópicos) pela frente para explorar!
Características de um Domínio Anêmico: Quando os Dados Se Tornaram os Reis e as Entidades Seus Súditos
Se eu pudesse usar uma analogia, a situação atual da modelagem de domínio em muitos sistemas é como um reino onde os dados são os reis e as entidades, outrora orgulhosas e poderosas, tornaram-se meros súditos. Neste reino, os dados ocupam o trono, e as regras de negócios e a lógica estão espalhadas pelos cantos do castelo, escondidas em salas escuras e corredores sinuosos. Ah, meus caros leitores, permitam-me lhes contar mais sobre esse reino peculiar.
Modelos Centrados Apenas em Dados
Os modelos centrados em dados são como quebra-cabeças bidimensionais. Eles têm todos os pedaços, mas falta a profundidade. Claro, em alguns contextos, como em aplicativos CRUD simples (Create, Read, Update, Delete) ou sistemas altamente focados em relatórios, esses modelos são excelentes. São rápidos, diretos e não possuem uma lógica complexa para atrapalhar. É um pouco como usar um martelo para bater um prego; simples e eficaz. Mas e se você tiver que lidar com um parafuso?
Regras de Negócios vs. Lógicas de Negócios
Antes de mergulhar mais fundo, vamos desembaraçar um emaranhado que tem confundido muitos: a diferença entre regras de negócios e lógicas de negócios.
Regras de negócios são os princípios fundamentais que definem a operação de um negócio. Pense nelas como as leis de um reino. Por exemplo, "um cliente só pode ter um empréstimo ativo de cada vez" ou "todos os usuários devem ter um e-mail válido".
Já as lógicas de negócios são mais sobre como essas regras são aplicadas e executadas. Elas são as táticas, os planos detalhados e os processos. Usando nossa analogia do reino, seria como o protocolo da guarda real ao proteger o rei.
Para visualizar isso na prática, vamos ver de perto um exemplo. Imagine um sistema de e-commerce que classifica seus usuários com base no montante total gasto no último mês. Há três níveis de usuários: Bronze, Prata e Ouro. Cada nível recebe uma promoção diferente.
1. Regras de Negócios
Estabelecemos as regras para classificar os usuários:
Bronze: Usuários que gastaram até $100 no último mês.
Prata: Usuários que gastaram entre $101 e $500 no último mês.
Ouro: Usuários que gastaram mais de $500 no último mês.
enum UserTier {
Bronze = "Bronze",
Silver = "Silver",
Gold = "Gold"
}
class User {
email: string;
lastMonthSpending: number;
tier: UserTier;
constructor(email: string, spending: number) {
this.email = email;
this.lastMonthSpending = spending;
this.tier = this.classifyUser(spending);
}
private classifyUser(spending: number): UserTier {
if (spending <= 100) return UserTier.Bronze;
if (spending > 100 && spending <= 500) return UserTier.Silver;
return UserTier.Gold;
}
}Lógicas de Negócios
Com base na classificação do usuário, concedemos promoções diferentes:
Bronze: 5% de desconto na próxima compra.
Prata: 10% de desconto e frete grátis.
Ouro: 20% de desconto, frete grátis e acesso antecipado a novos produtos.
class UserService {
grantPromotion(user: User): void {
switch(user.tier) {
case UserTier.Bronze:
this.giveDiscount(user, 5);
break;
case UserTier.Silver:
this.giveDiscount(user, 10);
this.giveFreeShipping(user);
break;
case UserTier.Gold:
this.giveDiscount(user, 20);
this.giveFreeShipping(user);
this.giveEarlyAccess(user);
break;
}
console.log(`Promotions granted for ${user.email} with tier ${user.tier}`);
}
private giveDiscount(user: User, percentage: number): void {
console.log(`${percentage}% discount granted to ${user.email}`);
}
private giveFreeShipping(user: User): void {
console.log(`Free shipping granted to ${user.email}`);
}
private giveEarlyAccess(user: User): void {
console.log(`Early access to new products granted to ${user.email}`);
}
}Este exemplo ilustra bem a diferença entre regras e lógicas de negócios. A regra de negócios (classificar usuários) define os critérios claros que cada usuário deve atender. A lógica de negócios detalha os benefícios e promoções que cada classificação deve receber. A separação entre os dois ajuda a tornar o código mais gerenciável, testável e fácil de entender.
Entidades: As Grandes Esquecidas
Nossas pobres entidades, outrora detentoras de dados e comportamentos, têm sido rebaixadas a simples portadoras de dados em muitos sistemas modernos. O ideal era que as entidades fossem poderosas, controlando não apenas seus próprios dados, mas também como esses dados podiam ser usados e manipulados. Agora, em muitos sistemas, elas são como vasos decorativos em um palácio; bonitas de se olhar, mas sem um propósito funcional real.
Por que isso é um problema? Porque, sem comportamentos ricos, as entidades tornam-se, bem... anêmicas. E assim, a lógica e as regras que deveriam estar encapsuladas dentro delas são frequentemente encontradas em serviços ou controladores. Isso pode levar a uma dispersão da lógica, tornando o sistema mais difícil de manter e evoluir.
A Dispersão dos Serviços
Com a lógica de negócios e as regras sendo movidas para fora das entidades, muitos sistemas agora têm serviços que são como mini monstros, tentando fazer tudo. Essa abordagem pode tornar a lógica mais difícil de encontrar e modificar, especialmente quando se trabalha em equipes grandes. Vamos comentar daqui a pouco ainda mais sobre esses pontos!
Modelo de Exemplo
Agora, vamos observar um domínio. Aqui temos um domínio bem definido, centrado no e-mail de um usuário, que encapsula tanto dados quanto comportamento:
import { Either, left, right } from '@/shared'
import { InvalidEmailError } from '@/entities/errors'
import { valid } from '@/entities/email-validator'
export class Email {
public readonly value: string
private constructor (email: string) {
this.value = email
Object.freeze(this)
}
public static create (email: string): Either<InvalidEmailError, Email> {
if (valid(email)) {
return right(new Email(email))
}
return left(new InvalidEmailError(email))
}
}O que vemos aqui é uma entidade Email que não apenas armazena um valor de e-mail, mas também valida esse e-mail ao criar uma instância. Esta é uma entidade rica em comportamento. Em contraste, um domínio anêmico teria apenas a propriedade value e toda a lógica de validação estaria em algum outro serviço ou controlador.
Antes de continuar quero conversar ainda mais sobre as famosas Services.
Cuidado com Múltiplos Serviços: O Problema de Ter Muitos Cozinheiros
Vamos imaginar uma cozinha. Não qualquer cozinha, mas a de um restaurante renomado. Nessa cozinha, temos vários chefs, cada um especialista em seu próprio nicho: há o chef de massas, o chef de carnes, o chef de sobremesas e assim por diante. Agora, imagine se todos eles tentassem fazer o mesmo prato ao mesmo tempo. Cada chef adicionando um ingrediente aqui, temperando ali, mexendo o caldeirão ao seu modo. Seria um caos! A comida resultante seria, no mínimo, intrigante e, no pior dos casos, intragável.
Isso é exatamente o que acontece em muitos sistemas de software quando nos desviamos de entidades ricas em comportamento e permitimos que a lógica se espalhe por uma variedade de serviços. Os "chefs" neste caso são os programadores, e o "prato" é o nosso código.
A Sedução dos Serviços
Os serviços, à primeira vista, parecem ser a solução perfeita para todos os nossos problemas. Eles prometem encapsular lógica complexa, ser reutilizáveis e tornar nosso código mais "limpo". No entanto, quando adotamos o paradigma de domínio anêmico, muitos desses serviços se tornam abarrotados de lógica, tentando compensar a ausência de comportamento em nossas entidades.
Mas por que muitos desenvolvedores se apaixonaram por essa abordagem? A resposta pode estar na simplicidade inicial que ela oferece. Separar dados de comportamento em um primeiro momento pode parecer uma decisão lógica, especialmente quando se trabalha com frameworks ORM que incentivam essa divisão ou até mesmo outras ferramentas ou funcionalidades que o framework utilizado oferece. Além disso, há uma percepção de que ao colocar a lógica em serviços, o código torna-se mais modular e, portanto, mais fácil de gerenciar.
O Alto Preço da Dispersão
No entanto, essa abordagem tem seu preço. Quando as regras de negócios e a lógica estão espalhadas por vários serviços, o código torna-se mais difícil de entender. Imagine ter que verificar cinco, dez ou até quinze serviços diferentes para entender completamente um fluxo de negócios.
Além disso, testar esse código é uma tarefa desgastante. Cada serviço pode ter suas próprias dependências, e mockar todas elas para testes unitários pode ser exaustivo. A ironia? Um dos argumentos para essa abordagem era justamente a facilidade de teste!
E não para por aí. Quando as regras estão dispersas, há um risco real de que algumas delas sejam implementadas incorretamente ou até esquecidas. No mundo dos negócios, isso pode se traduzir em perdas financeiras, danos à reputação ou problemas legais.
Na Prática
Agora, vamos dar uma olhada em um exemplo fictício em TypeScript. Imagine que temos uma entidade anêmica User:
export class User {
public id: number;
public email: string;
public age: number;
}Dado que nossa entidade é anêmica, podemos ter um serviço para verificar a validade do e-mail e outro para verificar a idade:
class EmailService {
isValid(email: string): boolean {
// lógica de validação de e-mail
}
}
class AgeService {
isAdult(age: number): boolean {
// lógica de validação de idade
}
}Parece organizado, certo? Mas e se tivermos que adicionar mais regras, como verificar se um usuário pode se inscrever em um determinado curso ou se ele pode obter um desconto em uma loja? Teríamos que criar mais e mais serviços, cada um contendo uma pequena peça da lógica geral.
Contraste isso com uma entidade rica em comportamento:
export class User {
public id: number;
public email: string;
public age: number;
isEmailValid(): boolean {
// lógica de validação de e-mail
}
isAdult(): boolean {
// lógica de validação de idade
}
}Aqui, toda a lógica relacionada ao usuário está contida dentro da própria classe User.
Em resumo, enquanto os serviços têm seu lugar na arquitetura de software, devemos ter cuidado para não torná-los "mini monstros" que tentam fazer tudo, especialmente à custa de entidades anêmicas. Esse é um caminho escorregadio que pode levar a um código difícil de gerenciar, entender e testar. E como sempre ouvimos: "Muitos chefs estragam a sopa!"
Problemas Associados aos Domínios Sem Comportamento
A Orientação a Objetos (OO) é frequentemente vista como uma abordagem elegante na programação, onde tudo tem seu lugar e suas responsabilidades definidas. No entanto, atualmente, observa-se uma tendência crescente em direção à programação centrada em dados. Esse movimento tem levado muitos projetos de software a adotarem domínios sem comportamento específico. Vamos explorar e esclarecer os desafios que emergem quando subestimamos a importância da Orientação a Objetos (OO).
Violação dos princípios da Orientação a Objetos: A primeira e mais óbvia ferida é a violação brutal dos princípios fundamentais da OO. O encapsulamento, uma das joias da coroa da POO, é completamente desconsiderado. Em vez de proteger nossos preciosos dados em suas respectivas classes e garantir que só sejam acessados ou modificados de maneira adequada, eles são expostos como se estivessem em uma feira de antiguidades à mercê do melhor lance. Isso, querido leitor, é uma afronta ao que OO representa. Sem encapsulamento, nossos dados podem ser alterados de formas inesperadas e indesejadas. Isso é como convidar um elefante para uma loja de porcelanas; as chances de algo dar errado são imensas.
Dificuldade em Refatorar e Evoluir o Software: Agora, um momento de sinceridade. Refatorar o código nunca é uma tarefa que os programadores acordam ansiosos para fazer, certo? Mas em um domínio anêmico, a refatoração é difícil. Com a lógica de negócios dispersa, encontrar todos os pontos que precisam ser alterados é desafiador. E evoluir? Bem, inserir uma nova funcionalidade em tal cenário é complicado. O resultado pode ser um problema que deixa todos desconfortáveis.
Testabilidade Comprometida: Imagine que você está tentando montar um quebra-cabeça, mas todas as peças são quase idênticas. Parece insano, certo? É exatamente assim que se sente ao tentar testar um domínio sem comportamento. A dispersão da lógica torna extremamente desafiador identificar o que e como testar. Além disso, sem um encapsulamento adequado, garantir a integridade dos dados durante os testes é uma montanha-russa emocional. Quando a lógica e os dados são separados, os testes se tornam mais um jogo de adivinhação do que uma prática sistemática. Em vez de validar comportamentos claramente definidos, você acaba tentando prever todos os possíveis cenários em que os dados podem ser alterados. É como tentar prever o clima em uma cidade que experimenta todas as quatro estações em um dia. Não é apenas imprevisível, mas também incrivelmente frustrante.
Vamos falar mais sobre como a testabilidade é totalmente prejudicada quando estamos em contextos complexos.
O Labirinto de Um Dominío Sem Comportamento
A jornada da testabilidade em domínios anêmicos pode ser comparada à experiência de alguém tentando encontrar a saída de um labirinto sem um mapa claro. Sim, é um daqueles labirintos intrincados que você encontraria em parques de diversão, com múltiplos becos sem saída, caminhos tortuosos e, para apimentar ainda mais, alguns espelhos que distorcem sua imagem e percepção. Vamos mergulhar nessa analogia.
Ao entrar no labirinto, você percebe que as paredes são incrivelmente altas e que não consegue ter uma visão geral do que está por vir. Sem um mapa claro, você depende de sua intuição e tenta memorizar os caminhos que já percorreu. Agora, suponha que este labirinto mude de configuração a cada vez que você o visita. Frustrante, não é? Esse é o sentimento ao tentar testar domínios que carecem de uma estrutura clara e comportamento bem definido.
Testar um software bem estruturado é como ter um mapa do labirinto em suas mãos. Você sabe onde começar, qual caminho seguir e onde provavelmente encontrará obstáculos. Por outro lado, em um domínio sem comportamento, a lógica é tão dispersa que é como tentar decifrar esse labirinto sem qualquer orientação. Você se encontra voltando aos mesmos pontos repetidamente, sem ter certeza se cobriu todas as áreas críticas.
Adicionalmente, o teste torna-se não apenas um desafio de localização, mas também de confiabilidade. Sem um encapsulamento adequado, é como se, ao tentar sair do labirinto, as paredes começassem a se mover ou desaparecer, tornando sua saída ainda mais incerta. Garantir a integridade dos dados durante os testes torna-se uma tarefa árdua, pois cada tentativa de encontrar um caminho correto é prejudicada por mudanças inesperadas.
E, para adicionar um pouco de sal à ferida, enquanto você está no meio desse labirinto caótico, os stakeholders estão do lado de fora, esperando, observando seu progresso através de uma janela de vidro, perguntando por que está demorando tanto para "simplesmente testar o software". Sim, queridos leitores, a testabilidade comprometida é essa experiência, mas com um teclado e uma tela à sua frente.
Vamos ver um exemplo prático de como a testabilidade é afetada!
Em nossa empresa fictícia de comércio eletrônico, temos uma classe chamada VoucherService. Esta classe é responsável por validar cupons que os usuários aplicam para obter descontos. A validação de um voucher envolve várias etapas, como verificar a data de expiração, o tipo de voucher, restrições geográficas, e assim por diante. No entanto, em um universo paralelo onde a programação é dominada pelo caos (ou seja, domínios anêmicos), o VoucherService se tornou uma monstruosidade com validações dispersas e mal-encapsuladas.
Vamos dar uma olhada nessa classe e tentar imaginar como testá-la:
class VoucherService {
// ... other properties
public validateVoucher(voucher: any, userLocation: string): boolean {
// Check voucher type
if (voucher.type === "FESTIVE" && new Date().getMonth() !== 11) {
return false; // because it's only valid in December
}
// Oh! We need to validate the expiry date too
if (new Date() > new Date(voucher.expiryDate)) {
return false;
}
// Oops! Almost forgot. There are location-based vouchers
if (voucher.restrictedTo && voucher.restrictedTo !== userLocation) {
return false;
}
// ... more scattered validations
return true;
}
}Testes:
import { VoucherService } from './VoucherService'; // assuming path
describe('VoucherService', () => {
let service: VoucherService;
beforeEach(() => {
service = new VoucherService();
});
test('should validate festive voucher', () => {
const voucher = {
type: 'FESTIVE',
expiryDate: '2023-12-31',
// ... other properties
};
expect(service.validateVoucher(voucher, 'US')).toBeTruthy();
});
// ... More tests for each condition
});Quais os problemas?
Validações dispersas: Como visto, nossa função tem uma série de validações, e cada uma delas é um potencial ponto de falha. O teste acima cobre apenas um cenário. Para cobrir todos os cenários, teríamos que escrever testes para cada condição
if, tornando nossa suíte de testes extensa e confusa.Dependência de datas: A validação do tipo "FESTIVE" é sensível ao mês atual. Isso significa que nosso teste acima só passaria em dezembro! Sem a injeção de uma dependência de data (por exemplo, um
Clock), testar essa função ao longo do ano seria um pesadelo.Má encapsulação: Como os detalhes de validação estão espalhados, é fácil perder ou esquecer algumas validações. Se, no futuro, decidirmos adicionar mais lógicas de validação ou alterar as existentes, a manutenção se torna complexa.
Podemos ver claramente isso ocorrendo no diagrama abaixo:
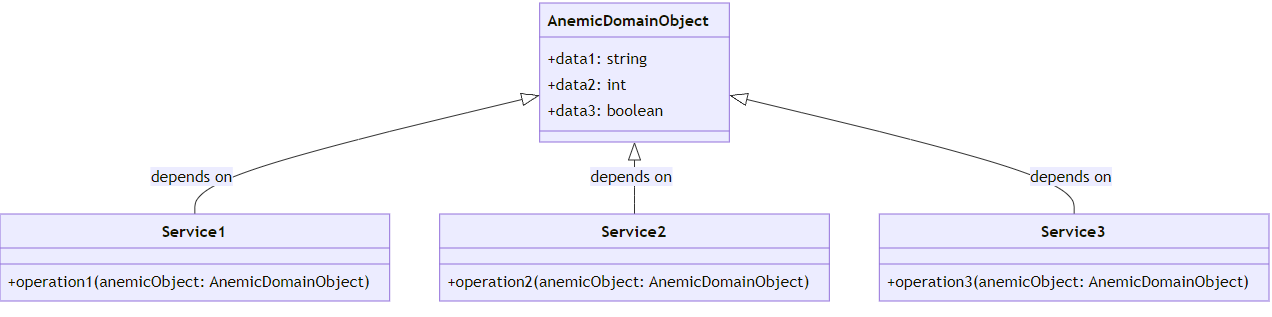
Cada um desses serviços depende do AnemicDomainObject para realizar suas operações. Isso ilustra a natureza de um domínio anêmico, onde a lógica de negócios é externalizada para serviços externos, em vez de ser encapsulada dentro do próprio domínio.
Em resumo, nossa tentativa de testar o VoucherService é como tentar resolver um quebra-cabeça com peças faltando. A testabilidade está seriamente comprometida devido à dispersão das validações e à falta de encapsulamento adequado. Ah, a vida seria tão mais fácil com um domínio rico e bem estruturado!
Como Identificar um Domínio Anêmico?
Com base em tudo o que já conversamos, não é muito difícil, vamos agora destacar esses pontos e acrescentar alguns.
Entidades Magras como Palitos:
O primeiro e mais óbvio sinal é quando suas entidades parecem mais modelos de dados do que verdadeiras entidades. Elas são quase que exclusivamente compostas por propriedades e getters/setters. Não há comportamento, não há lógica - apenas estruturas secas esperando por algum molho de lógica que nunca chega.
Serviços Onipresentes:
Esses caras são os verdadeiros protagonistas em um domínio anêmico. Eles estão por toda parte, e geralmente têm nomes genéricos como "UserService", "OrderService", e "EverythingButTheKitchenSinkService". Muitas vezes, eles carregam o peso de todas as operações, deixando as entidades como meros sacos de propriedades.
Falta de Encapsulamento:
Se você perceber que é incrivelmente fácil acessar e modificar o estado interno das entidades diretamente, é provável que o encapsulamento tenha sido jogado pela janela. Lembre-se, em um domínio saudável, as entidades são como fortes medievais, guardando seus tesouros internos e apenas permitindo interações específicas através de métodos bem definidos.
Regras de Negócio em Lugares Estranhos:
Em um cenário anêmico, as regras de negócios têm uma estranha tendência de aparecer em lugares inusitados: controladores, utilitários e até mesmo em camadas de UI. É como encontrar seus sapatos na geladeira - definitivamente, não é onde deveriam estar.
Testes Complexos e Espalhados:
Devido à dispersão da lógica, os testes também tendem a se tornar espalhados e complicados. Em vez de testar um comportamento coeso em uma entidade, você se encontra saltando de um serviço para outro, tentando rastrear a origem de uma regra específica.
Entidades Desconectadas da Realidade do Negócio:
Suas entidades não refletem os conceitos do domínio do negócio. Em vez de ter uma entidade "Account" que encapsula o comportamento de uma conta, você tem uma entidade "AccountData" e um serviço "AccountOperations". É como ter um carro e um motorista separados, sem um volante para conectá-los.
Dificuldade em Conversar com Especialistas de Domínio:
Se você se pega constantemente tendo dificuldade em traduzir os requisitos de especialistas do domínio para seu código, é provável que seu domínio esteja muito desconectado da realidade do negócio. Afinal, deveria ser uma tradução quase direta, e não uma epopeia digna de um épico grego.
Reutilização de Lógica se Tornando um Desafio:
Em um domínio anêmico, a lógica reutilizável é como aquela meia que sempre desaparece na lavanderia. Você sabe que deveria estar lá, mas é quase impossível encontrá-la.
Agora, respire fundo. Se seu código apresenta muitos dos sinais acima, você pode estar navegando em águas anêmicas. Vamos conversar mais sobre as consequências.
Consequências em Grandes Sistemas Corporativos
Grande sistemas corporativos, que fascinante e desafiador universo! É aí que a tecnologia atende às intrincadas dinâmicas de grandes empresas e suas necessidades em constante evolução. Contudo, quando entramos no território do domínio anêmico, essas complexidades podem tomar proporções preocupantes.
Comecemos com a comunicação entre times. Em qualquer organização de grande porte, é imperativo que as equipes de desenvolvimento estejam em sintonia. No entanto, o domínio anêmico tem o potencial de minar essa sintonia. Com lógica e regras de negócios espalhadas, não é incomum que diferentes equipes interpretem funções e responsabilidades de maneira variada. E sejamos honestos: quem nunca esteve em uma reunião onde dois departamentos tinham ideias totalmente diferentes sobre a mesma funcionalidade?
Depois, temos a questão da persistência de dados. Em um ambiente corporativo, as informações frequentemente se expandem em volumes enormes. Manter a consistência e a integridade dos dados é crucial. Mas com a lógica do negócio dispersa e sem um sentido claro de responsabilidade, garantir que esses dados permaneçam consistentes e confiáveis se torna, bem, um pouco mais que uma simples dor de cabeça.
Mergulhando mais fundo, pensemos sobre a clareza dos fluxos em um sistema. Se você já tentou decifrar um processo ou fluxo de trabalho em um sistema com domínio anêmico, sabe que pode parecer que você está tentando ler um manual escrito em três idiomas diferentes ao mesmo tempo. Não é preciso dizer que isso não é bom para a produtividade ou para a manutenção do código.
Agora, se você está empolgado com a abordagem de microserviços, esteja ciente. Os microserviços prometem modularidade e escalabilidade, mas quando inseridos em um domínio anêmico, podem herdar todos os problemas associados. A lógica se dispersa por vários serviços e a orquestração entre eles pode se assemelhar a tentar dirigir um carro com quatro volantes.
E, claro, há o desafio constante de estender e adaptar o software. Em um mundo ideal, novas funcionalidades seriam adicionadas de forma fluida e sem muitos obstáculos. Contudo, com a lógica espalhada e regras de negócio inconsistentemente aplicadas, cada nova funcionalidade pode parecer uma operação de alto risco.
Finalmente, consideremos a detecção de bugs e a consistência dos dados. Em um sistema anêmico, os bugs podem ser mais esquivos, aparecendo em lugares inesperados devido à lógica dispersa. Já viu aquela situação onde um bug é corrigido em um lugar e surge em outro? E a incoerência dos dados... Ah, essa pode ser a gota d'água, levando a decisões empresariais imprecisas ou, pior, erradas.
Reconhece alguns desses desafios? Pois é, eles são bem reais e podem surgir quando a arquitetura do software não é cuidadosamente considerada, especialmente em grandes sistemas corporativos. E é por isso que, ao enfrentar esses gigantes, precisamos garantir que nosso domínio esteja forte, coeso e saudável. Porque, no final do dia, um domínio bem estruturado não é apenas bom código; é bom para os negócios.
Gostaria de conversar sobre outro ponto agora, que inclusive todos nós precisamos estar atentos para continuar a melhorar profissionalmente.
Modelagem do Banco de Dados Antes da Modelagem do Domínio: Um Caminho Rápido para o Software Anêmico?
É um belo dia, e você está pronto para começar um novo projeto. A empolgação está no ar, as ideias fluindo e o café recém-passado na sua xícara. O primeiro impulso? Começar a desenhar o esquema do banco de dados, certo? Bem, aqui está onde começamos a trilhar um caminho perigoso que pode levar a um software anêmico. Permita-me desvendar isso para você.
1. A Mentalidade Estrutural, Não Comportamental
Quando começamos pela modelagem do banco de dados, naturalmente nos concentramos nas estruturas – nas tabelas, chaves, relações e índices. Isso nos coloca em um mindset muito "estrutural". As entidades são vistas primariamente como contêineres de dados, não como objetos vivos com comportamento.
2. O Culto dos CRUDs
Ao adotar a abordagem do banco de dados primeiro, muitas vezes terminamos criando sistemas que são essencialmente uma série de operações CRUD (Create, Read, Update, Delete). Em vez de modelar comportamentos e lógicas de negócio ricas, nos vemos presos a uma visão simplista, limitada à manipulação direta de registros.
3. Falta de Flexibilidade para Mudanças no Negócio
Negócios mudam, e eles mudam rapidamente. Ao definir rígidas estruturas de dados no início, tornamos o software mais resistente a adaptações. Toda vez que uma nova necessidade de negócio surge, em vez de ajustar um comportamento no domínio, encontramo-nos reestruturando o banco de dados, com todas as dores de cabeça que isso implica.
4. A Descoberta Tardia da Complexidade
Muitas vezes, ao focar primeiro no banco de dados, empurramos a lógica de negócios complexa mais para a frente no ciclo de desenvolvimento. Isso pode levar a descobertas tardias de requisitos cruciais ou nuances de negócios que, se tivessem sido abordadas no início, poderiam ter levado a um design de software muito diferente.
5. A Lógica de Negócios Espalhada
Quando o software é projetado com o banco de dados como foco principal, a lógica de negócios frequentemente se espalha. Pode estar nas triggers do banco de dados, nos stored procedures, no código da aplicação e até mesmo na camada de apresentação. Isso torna o sistema não apenas difícil de manter e evoluir, mas também um pesadelo para testar.
6. O Olhar Distante dos Especialistas de Domínio
Ao se concentrar demais na estrutura do banco de dados, muitas vezes nos distanciamos dos especialistas de domínio. Estes são os indivíduos que realmente entendem os problemas e os processos de negócios. Se não estivermos em sintonia com eles desde o início, corremos o risco de desenvolver soluções que se desviam das reais necessidades do negócio.
O que podemos concluir nesse tópico?
Começar pela modelagem do banco de dados não é, por si só, um erro fatal. Um software verdadeiramente eficaz e adaptável começa com um profundo entendimento do domínio do problema, e não apenas com a estrutura de como os dados serão armazenados. E sejamos honestos: ninguém quer se ver na posição desconfortável de perceber, a meio caminho do projeto, que está preso em uma armadilha anêmica de sua própria criação. É sempre mais saboroso saborear o sucesso de um projeto bem estruturado do que o amargor de retrabalho e mal-entendidos.
Agora podemos começar a falar brevemente sobre domínios ricos, não vou aprofundar pois será um tema para um próximo artigo, mas vamos conversar rapidamente sobre a modelagem rica!
A Essencia de Domínios Ricos em Comportamento!
A vida de um programador ou arquiteto de software não é fácil. Somos frequentemente vistos como aqueles que simplesmente "fazem as coisas acontecerem". Mas não somos mágicos (bem, talvez um pouco). O verdadeiro truque é adaptar-se e moldar nossas soluções de acordo com a complexidade da demanda. Não somos meramente executores, somos solucionadores de problemas. E sejamos honestos, você não quer um chef que apenas jogue ingredientes em uma panela, certo?
Então, como os domínios ricos entram nessa história? Eles são a bússola que nos guia. Com eles, não apenas codificamos; modelamos o negócio, dando vida às regras e processos que são o coração pulsante do software.
Dando Vida ao Domínio: A Classe Voucher
Para ilustrar isso, vamos falar sobre a Voucher. Uma entidade, à primeira vista, simples. Mas vamos adicionar camadas de complexidade e comportamentos ricos.
class Voucher {
private code: string;
private validityDate: Date;
private value: number;
private applied: boolean;
constructor(code: string, validityDate: Date, value: number) {
this.code = code;
this.validityDate = validityDate;
this.value = value;
this.applied = false;
}
isVoucherValid(): boolean {
const currentDate = new Date();
return currentDate <= this.validityDate;
}
applyVoucher(): void {
if (!this.isVoucherValid() || this.applied) {
throw new Error("Voucher cannot be applied.");
}
this.applied = true;
}
getValue(): number {
return this.value;
}
}
// Use-case example
class Product {
private price: number;
constructor(price: number) {
this.price = price;
}
applyDiscount(voucher: Voucher): void {
if (voucher.isVoucherValid() && !voucher.applied) {
this.price -= voucher.getValue();
}
}
}Aqui, a Voucher não é apenas um conjunto de propriedades. Tem comportamentos que protegem sua integridade, como verificar a validade ou garantir que não seja aplicado mais de uma vez. E quando integrado a um Product, vemos como essa entidade rica garante que o desconto só seja aplicado se todas as regras forem satisfeitas.
Agora vamos ver um diagrama que também representa isso para nós:

O ExternalService é um serviço que pode interagir com o RichDomainObject, mas ao contrário do domínio anêmico, o domínio rico não depende fortemente de serviços externos para definir seu comportamento principal.

Essa abordagem não apenas facilita a implementação das regras de negócios, mas também torna nosso código mais resiliente a erros. Afinal, quando conhecemos nosso domínio profundamente, e modelamos ele de forma rica, nossa bússola está sempre apontando na direção certa - para soluções robustas e mais confiáveis.
Conclusão
Ao longo de nossa jornada, pudemos compreender não apenas a definição desse conceito, mas também suas implicações, suas raízes e, o mais importante, como evitar cair nesse abismo.
O domínio anêmico pode comprometer a testabilidade de um sistema até exacerbar problemas em sistemas corporativos maiores, ou seja, pode ser um verdadeiro obstáculo para a entrega de software de alta qualidade.
A Importância do Entendimento
Ficou evidente que uma abordagem centrada apenas na tecnologia ou na estrutura de dados é insuficiente. Em vez disso, a ênfase deve ser colocada em entender verdadeiramente o problema em mãos. O núcleo do desenvolvimento de software eficaz está na clara compreensão do domínio do problema e na colaboração estreita com os especialistas desse domínio.
Modelando com Propósito
Também destacamos a importância de começar com o domínio e não com a modelagem do banco de dados. Essa abordagem garante que a lógica de negócios e o comportamento do sistema sejam colocados em primeiro plano, evitando assim que o software se torne uma mera representação dos dados armazenados.
Olhando para o Futuro
Enquanto avançamos, com o conhecimento que adquirimos, temos a responsabilidade de abordar o desenvolvimento de software com uma mentalidade aberta e crítica. Devemos nos questionar constantemente, avaliando nossas decisões e garantindo que não estamos caindo nas armadilhas dos domínios anêmicos.
É importante lembrar que, como em qualquer jornada de aprendizado, a chave é a reflexão contínua e a vontade de melhorar. Portanto, enquanto saboramos nosso café (ou chá, se preferir) e contemplamos nosso próximo projeto, levemos conosco as lições aprendidas aqui e miremos sempre em criar sistemas robustos, flexíveis e verdadeiramente alinhados com as necessidades do negócio.
Antes da ascensão dos ORMs, lidar com bancos de dados em aplicativos era, em muitos aspectos, uma experiência "manual". Os programadores precisavam escrever consultas SQL (Structured Query Language) à mão para realizar as operações mais básicas em um banco de dados. Se você quisesse inserir, atualizar, recuperar ou deletar um registro, preparava-se para desvendar a sintaxe e as nuances do SQL.
Aqui está um pouco do que os bravos programadores passavam:
Consultas Ad Hoc: Cada vez que um desenvolvedor quisesse interagir com o banco de dados, era necessário escrever uma consulta SQL específica. Isso envolvia conhecer bem o esquema do banco de dados e a sintaxe da consulta.
Mapeamento Manual: Sem os ORMs para mapear automaticamente as classes e objetos do código para as tabelas e registros do banco de dados, os desenvolvedores tinham que fazer isso manualmente. Imagine ter que lembrar e fazer a correspondência de cada campo do objeto com uma coluna específica do banco de dados. Dava para suar só de pensar!
Inconsistências entre Bancos de Dados: Se um aplicativo precisasse mudar para um banco de dados diferente ou suportar vários bancos de dados, muitas vezes as consultas SQL tinham que ser reescritas. Por quê? Porque nem todos os bancos de dados falam o mesmo "dialeto" de SQL.
Problemas de Segurança: Escrever consultas SQL à mão abria a porta para erros humanos, especialmente vulnerabilidades como injeção de SQL. Se um programador não fosse meticuloso, poderia acidentalmente criar brechas para ataques maliciosos.
Ah, mas não pense que tudo era sofrimento e desespero. Havia uma beleza naquela época. Os programadores tinham controle absoluto sobre o que acontecia entre o aplicativo e o banco de dados. Eles entendiam profundamente como suas consultas afetavam o desempenho e a integridade dos dados.
Pense nisso como fazer um café. Os ORMs são como as modernas máquinas de café expresso - você pressiona um botão e obtém seu espresso. Mas antes, era como usar um moedor manual e uma prensa francesa. Dava mais trabalho, mas você sentia cada grão e controlava cada etapa do processo.
Muito bacana! Eu descobri o nome do domínio com o qual lido todos os dias hahaha.
Sinto na pele os problemas que você citou, principalmente na hora de levantar requisitos que estendem o domínio (anêmico) já existente.
Ótimo artigo! Obrigado!
Aceito recomendações de leitura :D