
Distributed Lock: O que acontece quando dois cliques querem o mesmo lugar?

Você já tentou comprar um ingresso online e, ao clicar em pagar, apareceu a temida mensagem: “Esse assento acabou de ser reservado por outra pessoa”?
A sensação é estranha — você viu o lugar disponível, clicou rápido, já estava no carrinho… mas, de repente, ele sumiu. E o pior: você tem certeza de que foi rápido o suficiente. Como isso acontece?
Esse tipo de problema não tem a ver com lentidão ou má vontade do sistema. Na verdade, ele revela um desafio real e sutil que muitos sistemas enfrentam: várias pessoas acessando o mesmo recurso ao mesmo tempo. No mundo da tecnologia, chamamos isso de concorrência, e lidar com ela de forma segura é fundamental, especialmente em sistemas distribuídos.
Agora, imagine centenas de usuários tentando comprar os melhores assentos de um show, ao mesmo tempo, de diferentes lugares do país. Como garantir que dois usuários não consigam reservar o mesmo assento ao mesmo tempo, mesmo que estejam em servidores diferentes ou com conexões instáveis?
É aqui que entra o bloqueio distribuído (distributed lock) — uma solução poderosa e muitas vezes esquecida, mas que pode salvar seu sistema de bugs sutis e prejuízos enormes. Neste artigo, vou te explicar como esse conceito funciona, por que ele é tão importante, e como implementá-lo com um exemplo prático do mundo real: a reserva de assentos em um aplicativo de cinema.
O que é um bloqueio distribuído — e por que esse nome tão esquisito?
Tá, agora que você já viu o problema acontecendo — dois usuários tentando pegar o mesmo assento ao mesmo tempo — vamos conversar sobre essa tal de “distributed lock”.
O nome pode parecer meio técnico e até intimidador, mas a ideia por trás dele é bem simples.
Vamos por partes:
• Lock é “trava”, tipo uma chave que você usa pra trancar algo.
• Distributed é “distribuído”, ou seja, espalhado por vários lugares — nesse caso, por vários servidores, instâncias ou partes do seu sistema que estão rodando ao mesmo tempo.
Agora vamos traduzir isso pra algo mais do dia a dia.
A chave do banheiro no posto de estrada 🔐
Imagine que você está viajando de carro e para num posto de gasolina. Lá tem um único banheiro para os clientes (isso era muito comum antigamente nas estradas), e a chave dele fica presa a uma plaquinha enorme, com o nome do posto, justamente pra ninguém levar embora.
Se você quiser usar o banheiro, precisa pedir a chave no balcão. Enquanto você está com a chave, ninguém mais pode entrar. Eles precisam esperar você terminar e devolver a chave. Pronto. Isso é um lock.
Agora, pense que esse posto é um pouco melhor, tem vários funcionários espalhados — um em cada canto. E, para agilizar, todos compartilham a mesma chave do banheiro. Só que agora temos um novo desafio: como garantir que dois funcionários, em ambientes diferentes do posto de gasolina, não entreguem a chave ao mesmo tempo para duas pessoas diferentes?
É aí que a coisa complica. Se você tiver só um único lugar controlando o acesso à chave, tudo funciona. Mas se estiver distribuído, você precisa de uma forma inteligente e coordenada para garantir que apenas uma pessoa por vez receba a chave, não importa de onde o pedido venha.
Esse é o papel de um bloqueio distribuído em um sistema: garantir que, mesmo que você tenha várias partes do seu sistema rodando ao mesmo tempo (em servidores diferentes, em regiões diferentes, em instâncias diferentes), nenhuma ação crítica seja executada ao mesmo tempo por mais de uma pessoa.
Mas por que isso é importante?
Porque sistemas modernos são escaláveis. Eles estão em nuvem, são rápidos, lidam com milhares de requisições por segundo… mas também estão rodando em paralelo. E quando várias partes tentam modificar o mesmo recurso ao mesmo tempo — como um assento de cinema — você precisa de uma trava confiável, que funcione mesmo quando todo mundo está distribuído.
Sem isso, o caos reina: dois usuários compram o mesmo ingresso, o mesmo cupom é usado duas vezes, o estoque vai para -1.
“Mas não dá pra só bloquear em memória?”
Você pode estar pensando:
“Ué, mas não dá pra simplesmente bloquear a reserva em memória? Tipo, guardar uma flag no servidor dizendo que o assento já está sendo usado?”
Essa é uma pergunta super válida — e, na verdade, muito comum entre quem está começando a lidar com concorrência em sistemas.
A resposta é: sim, esse tipo de bloqueio funciona… mas só até certo ponto.
O nome técnico disso é mutex local (ou in-memory lock), e ele funciona muito bem quando você tem apenas uma instância da aplicação rodando — ou seja, tudo centralizado em um único servidor. Aí sim, travar em memória faz sentido: é rápido, simples e eficaz.
Quando o sistema cresce, o problema aparece
Agora, imagine que sua aplicação cresceu. Ela está rodando em várias instâncias, distribuídas em diferentes máquinas, containers ou regiões. Esse é o cenário típico de uma aplicação escalável, moderna — e é o que todo mundo busca com cloud e microserviços.
Nesse caso, o mutex local simplesmente não funciona mais.
Por quê? Porque cada instância da aplicação tem sua própria memória, seu próprio contexto. Se a instância A acha que o assento está bloqueado, a instância B não tem como saber disso — e vai permitir a reserva. Pronto, temos um problema: duas pessoas conseguiram reservar o mesmo recurso.
Mas Podemos Resolver no Pagamento… certo? Errado!
Talvez você esteja pensando:
“Ok, entendi que um mutex local pode permitir que dois usuários reservem o mesmo assento. Mas se isso acontecer, podemos simplesmente resolver no pagamento! Se o segundo usuário tentar pagar e o sistema perceber que o assento já foi vendido, é só exibir uma mensagem de erro para ele.”
Sim, tecnicamente isso é possível, mas agora pense na experiência do usuário...
A Frustração de Descobrir Tarde Demais
Imagine a cena:
1️⃣ Você entra no site, escolhe um assento perfeito no meio da sala, coloca no carrinho e avança para o pagamento.
2️⃣ Você preenche seus dados, escolhe a forma de pagamento, insere os detalhes do cartão e confirma a compra.
3️⃣ O sistema processa tudo, e então… PÁ!
“Desculpe, esse assento já foi reservado por outra pessoa.”
Isso é extremamente frustrante! Você já passou vários minutos no checkout, acreditando que aquele assento era seu. Agora precisa começar tudo de novo — e o pior: talvez os melhores assentos já tenham sido vendidos enquanto você tentava pagar.
Agora imagine isso acontecendo com centenas de usuários simultaneamente em eventos muito concorridos. A experiência fica caótica, e a empresa perde credibilidade.
Impacto no Negócio e na Experiência do Cliente
Esse tipo de problema não é apenas um erro técnico, mas um erro estratégico.
✔ Clientes frustrados → A chance de um cliente desistir e não tentar novamente é alta.
✔ Reputação da empresa → Se muitas pessoas passarem por isso, elas começam a duvidar da confiabilidade do site.
✔ Mais suporte ao cliente → Usuários reclamam, pedem ajuda, geram tickets e sobrecarregam o atendimento.
✔ Concorrência pode fazer melhor → Se um concorrente oferece um sistema de reserva sem esse problema, os clientes podem preferir comprar lá.
A solução é garantir que o usuário só avança para o pagamento se aquele assento realmente for dele por um tempo. E para isso, o Distributed Lock é essencial.
Onde isso realmente importa
Esse tipo de falha acontece muito em:
• Venda de ingressos, onde o mesmo assento pode ser vendido para mais de uma pessoa.
• Reservas de hotel ou restaurante, em que duas pessoas garantem a última vaga.
• Estoques limitados, em que dois clientes compram o último produto e depois a loja precisa cancelar manualmente um dos pedidos (dor de cabeça na certa).
• Cupons ou bônus, que são usados por mais de um cliente ao mesmo tempo — mesmo sendo válidos apenas uma vez.
Esses são problemas que não afetam só o sistema: afetam diretamente o cliente e a reputação da empresa. Causa frustração, gera suporte, quebra de confiança e prejuízo.
Pensar nisso é pensar no negócio, não só no código
Lidar bem com concorrência distribuída não é só uma preocupação técnica — é uma questão de garantir que a solução funcione de verdade no mundo real, com usuários reais.
Se você quer construir um sistema que lida com recursos escassos ou concorrência intensa, você precisa pensar em como garantir consistência e exclusividade de forma segura. Isso evita caos, retrabalho e perdas financeiras.
E é exatamente aí que entra o bloqueio distribuído: uma forma de garantir que, mesmo com várias instâncias rodando ao mesmo tempo, só uma delas possa acessar ou modificar um recurso crítico por vez.
No próximo tópico, a gente vai ver exatamente como isso funciona e como você pode aplicar essa estratégia no seu sistema de forma prática — e com ferramentas acessíveis, como o Redis.1
Como o bloqueio distribuído resolve isso na prática?
Agora que a gente já entendeu por que os bloqueios em memória não funcionam em sistemas modernos e distribuídos, vamos ver como o bloqueio distribuído entra em ação e mantém tudo sob controle.
1. Usuário começa o checkout → lock é adquirido
Tudo começa quando o usuário seleciona um ou mais assentos e clica em “continuar” para iniciar o processo de pagamento.
Nesse momento, sua aplicação consulta o sistema de locks distribuídos para verificar se é possível reservar os assentos escolhidos.
Esse lock é como uma reserva temporária: ele diz para o restante do sistema que “esses assentos estão sendo reservados agora, por este usuário específico”.
O lock pode ser armazenado em ferramentas como o Redis, usando comandos do tipo SETNX (set if not exists). Ele cria uma chave com o ID do assento, associando-a ao usuário ou sessão.
Se o lock for criado com sucesso, o fluxo continua normalmente. Se não, quer dizer que alguém já está no processo de checkout com aquele assento, e o sistema precisa alertar o novo usuário com uma mensagem do tipo:
“Opa! Esse assento está em processo de reserva. Tente novamente em instantes.”
2. Outros usuários não conseguem reservar o mesmo assento
Enquanto o lock está ativo, nenhuma outra instância do sistema pode criar outro lock para o mesmo assento. Isso evita que dois usuários entrem no checkout ao mesmo tempo acreditando que o assento é deles.
É nesse ponto que o bloqueio distribuído brilha: ele impede conflitos mesmo que os usuários estejam sendo atendidos por servidores diferentes, containers distintos, regiões diferentes da nuvem… não importa.
O lock é centralizado, confiável e respeitado por todo o sistema.
3. TTL: o guardião do bom senso
Agora vamos ser realistas: nem todo usuário que inicia o checkout finaliza a compra, certo?
• Ele pode fechar o app.
• A internet pode cair.
• Pode desistir no meio do caminho.
Se o lock fosse eterno, esse assento nunca mais poderia ser reservado. Por isso, a gente coloca um TTL (Time To Live) — ou seja, um tempo de vida limitado para o bloqueio.
Exemplo: o lock expira automaticamente em 10 minutos.
Isso significa que, se o usuário abandonar o checkout e sumir, o sistema libera os assentos automaticamente após esse tempo, permitindo que outros usuários tentem reservá-los.
TTL é o nosso plano B inteligente: ele evita que o sistema fique travado por locks esquecidos.
4. Finalizou o pagamento? Atualize o estado e só então libere o lock
Se tudo der certo — o usuário pagou e a transação foi concluída — o sistema deve:
Atualizar a base de dados, marcando os assentos como ocupados e confirmando a reserva.
Remover o lock manualmente do Redis, antes do TTL expirar.
Confirmar a reserva para o usuário, com segurança de que o assento já foi persistido no banco.
Essa ordem garante que:
O lock cumpriu seu papel de proteger temporariamente o recurso durante o processo crítico.
O dado foi salvo com segurança no banco de dados antes de liberar o recurso.
O sistema pode seguir livre para que outros usuários tentem reservar outros assentos — ou até o mesmo assento, se for uma nova sessão.

E se o usuário desistir no meio do caminho? Sem problemas:
O lock tem um TTL configurado, então ele expira sozinho após um tempo (ex: 10 minutos). Quando isso acontece, os assentos voltam a aparecer como disponíveis — com base no estado real da base de dados, que permanece como única fonte de verdade.
Reforçando da lógica do lock distribuído
• Ele é temporário, com TTL.
• Ele é centralizado, mesmo que o sistema esteja distribuído.
• Ele é protegido contra concorrência, impedindo ações duplicadas ou conflituosas.
• Ele não substitui a atualização do banco, mas atua como um buffer de proteção durante o processo.
Garantindo a Consistência: Redis e Banco de Dados Trabalhando Juntos
Agora que entendemos como o bloqueio distribuído funciona para garantir exclusividade temporária, surge uma pergunta essencial: onde a reserva confirmada deve ser armazenada?
O Redis é rápido, eficiente e perfeito para gerenciar bloqueios, mas ele não deve ser tratado como fonte de verdade para reservas confirmadas. Afinal, um lock no Redis não é a reserva em si — ele apenas impede concorrência enquanto o usuário finaliza o processo.
Uma reserva finalizada precisa ser persistida em um banco de dados relacional ou NoSQL, garantindo que o sistema possa recuperar essa informação a qualquer momento, independentemente da volatilidade do Redis.
1. Redis é Volátil, o Banco de Dados é Permanente
O Redis funciona em memória, o que significa que seus dados não são permanentes por padrão. Se o servidor Redis for reiniciado, qualquer lock ou dado armazenado sem persistência pode simplesmente desaparecer.
Agora imagine um cenário crítico:
• O usuário confirma o pagamento.
• A reserva é armazenada no Redis, mas não foi salva no banco de dados ainda.
• O Redis sofre um restart inesperado.
• A reserva desaparece, mas o pagamento já foi feito.
Isso gera um problema sério de inconsistência: o cliente pagou, mas o sistema não tem como provar que ele realmente reservou aquele assento.
A solução? Usar o Redis apenas para controle temporário e garantir que a reserva confirmada seja armazenada no banco de dados.
2. Fluxo Correto: Redis e Banco de Dados Trabalhando Juntos
O fluxo correto para evitar inconsistências segue três passos principais:
O Redis gerencia a reserva temporária com o lock
• Assim que o usuário inicia o checkout, um lock é criado no Redis.
• Enquanto o lock estiver ativo, nenhum outro usuário pode reservar o mesmo assento.
A confirmação da reserva deve ser feita no banco de dados
• Quando o usuário finaliza o pagamento, a reserva deixa de ser temporária e passa a ser permanente.
• Nesse momento, os dados são salvos no banco de dados relacional (PostgreSQL, MySQL) ou NoSQL (MongoDB, DynamoDB).
A remoção do lock deve ser a última etapa
• Apenas depois que a reserva foi gravada com sucesso no banco de dados, o lock é removido do Redis.
• Isso garante que o sistema nunca perca uma reserva confirmada.2
3. Estratégia de Confirmação Segura: Write-Ahead Logging
Em sistemas que precisam garantir consistência absoluta, uma abordagem comum é usar Write-Ahead Logging (WAL) ou transações distribuídas.
Isso significa que antes de remover o lock, o sistema pode:
1. Salvar um registro temporário da reserva no banco de dados como “pendente”.
2. Confirmar o pagamento.
3. Atualizar a reserva para “confirmada”.
4. Somente então, remover o lock no Redis.
Isso impede que falhas na transação façam com que assentos desapareçam sem um dono definido.
4. Por que não armazenar a reserva confirmada no Redis?
Alguns podem pensar: “Mas não seria mais rápido manter todas as reservas diretamente no Redis?”
Sim, o Redis é incrivelmente rápido, mas não é ideal para esse tipo de armazenamento permanente.
Aqui estão algumas razões:
✔ Persistência: O Redis pode perder dados em caso de falhas. O banco de dados garante que as reservas permaneçam salvas.
✔ Consultas e Relatórios: Buscar reservas confirmadas, gerar listas de assentos ocupados ou emitir comprovantes exige operações que fazem mais sentido em um banco de dados.
✔ Consistência Global: O banco de dados permite que todos os serviços tenham uma única fonte confiável de reservas confirmadas.
Redis e Banco de Dados Devem Trabalhar em Harmonia
O Redis é ótimo para gerenciar locks temporários e evitar concorrência, mas não deve substituir o banco de dados. A combinação correta é:
• Redis para gerenciar bloqueios e reservas temporárias.
• Banco de dados para armazenar reservas confirmadas de forma segura.
Essa estratégia garante que nenhuma reserva confirmada seja perdida, mesmo se houver falhas no Redis ou no servidor de aplicação.
No final das contas, trabalhar corretamente com Redis e banco de dados é mais do que uma questão técnica: é uma questão de garantir que o sistema seja confiável e funcione bem tanto para os usuários quanto para o negócio.
Write-Ahead Logging (WAL): Por que estamos falando disso aqui?
Se você nunca ouviu falar em Write-Ahead Logging (ou simplesmente WAL), não se preocupe — esse é um daqueles conceitos que muita gente só descobre quando o sistema começa a crescer e a segurança dos dados se torna realmente crítica.
Mas então… por que ele entrou nessa conversa sobre bloqueio distribuído e reserva de assentos?
Simples: porque nem sempre salvar no banco de dados é tão seguro quanto parece. Às vezes, você precisa garantir que, mesmo se o sistema cair no meio do caminho, a operação mais importante — como uma reserva — não será perdida ou deixada pela metade. E é exatamente isso que o WAL ajuda a resolver.
O que é o Write-Ahead Logging?
De forma bem direta, o Write-Ahead Logging (WAL) é uma técnica usada por alguns bancos de dados (como PostgreSQL, SQLite e outros) para garantir consistência e durabilidade dos dados.
O nome já dá uma boa pista: “escreva primeiro no log”.
Antes de o banco de dados realmente aplicar uma operação (como um INSERT, UPDATE, etc.), ele grava a intenção dessa operação num log especial de transações — chamado WAL log.
Só depois que essa informação é registrada no log é que a operação de fato acontece nos dados.
E o que isso resolve?
Esse log serve como uma espécie de diário de bordo do banco. Se algo der errado (ex: queda de energia, falha do sistema, pane no servidor), o banco pode consultar o log e refazer ou desfazer as operações incompletas, mantendo os dados consistentes.
Ou seja:
• 🔒 Nenhuma reserva confirmada é esquecida.
• 💣 Nenhuma operação pela metade quebra a integridade da base.
• 🔄 O banco consegue se recuperar sozinho em caso de falhas graves.
E o que isso tem a ver com bloqueio distribuído?
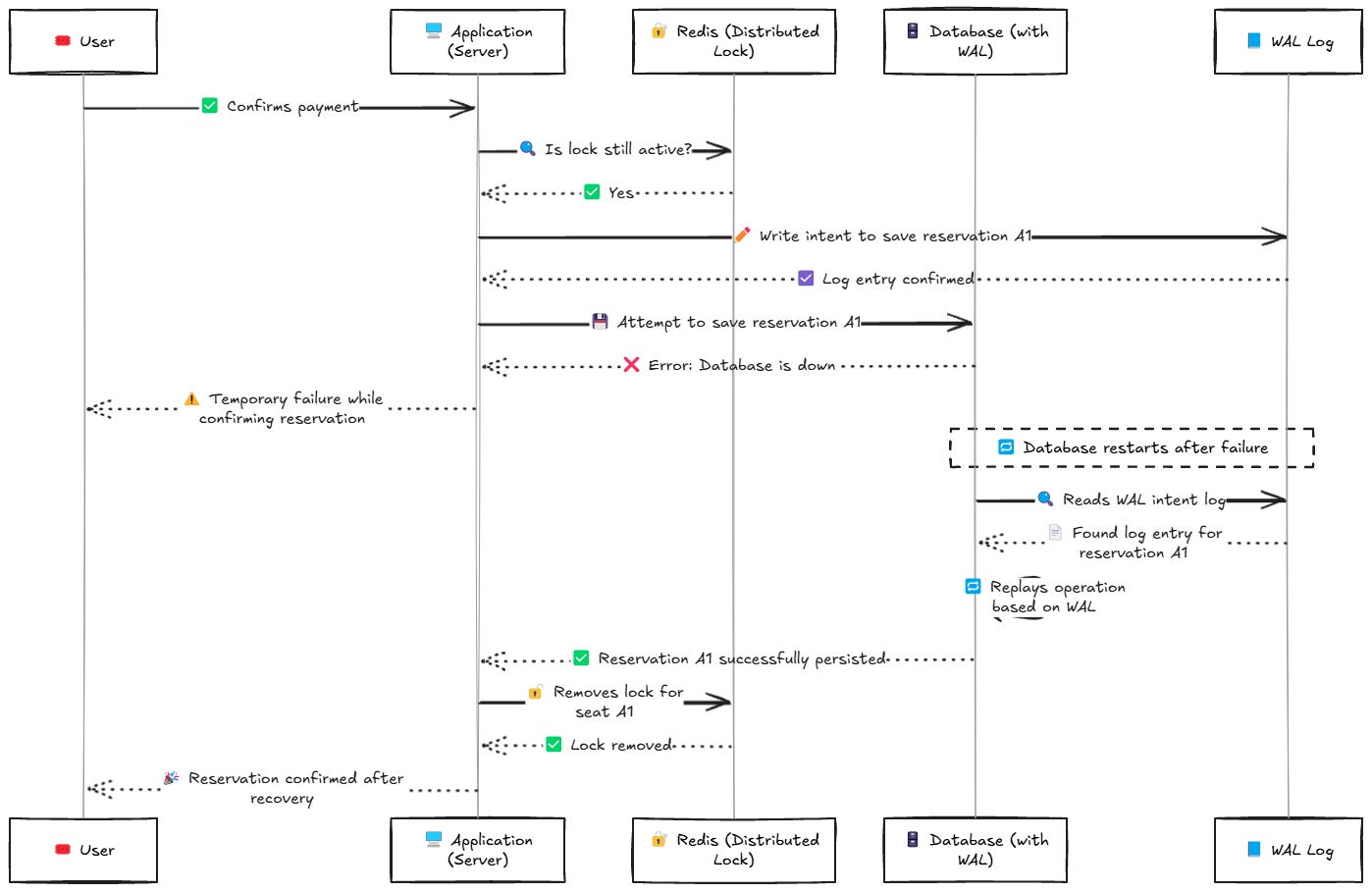
Imagine o cenário que vimos antes:
• Você criou um lock no Redis para o assento A1.
• O usuário finaliza o pagamento.
• Você grava a reserva no banco.
• E só depois, você remove o lock.
Agora pense: e se o servidor travar bem no meio da escrita no banco?
Sem WAL, você pode acabar com:
• O lock removido.
• A reserva não persistida.
• E o assento livre para outro usuário pegar.
Com WAL, mesmo que o servidor caia nesse momento crítico, o banco já tem registrado que a reserva ia acontecer. Então, quando voltar, ele sabe o que precisa fazer para finalizar a operação de forma segura.
Em que contextos o WAL é especialmente útil?
• Em sistemas que não podem perder transações: pagamentos, reservas, sistemas bancários, etc.
• Em operações que precisam ser atômicas, mesmo em ambiente distribuído.
• Quando você quer evitar a complexidade de implementar transações distribuídas completas, mas ainda assim garantir confiabilidade.
WAL não é um lock, mas é seu aliado
Importante dizer: o WAL não substitui o bloqueio distribuído. Ele complementa. Enquanto o lock impede que duas pessoas acessem o mesmo recurso ao mesmo tempo, o WAL garante que a operação não será perdida, mesmo que algo dê errado.
Quando falamos de sistemas distribuídos, o Redis ajuda a coordenar quem faz o quê, e o WAL garante que, uma vez decidido, a operação não se perde. Essa dupla pode salvar você de situações difíceis — principalmente quando a aplicação precisa de confiabilidade em alto nível.
Então sim, talvez o Write-Ahead Logging não esteja no centro da conversa sobre locks… mas quando você quiser garantir que tudo termine bem, mesmo nos piores cenários, é ele que vai estar lá para segurar a bronca.
Mas tem um outro detalhe que talvez você queira entender melhor e faço questão de explicar no tópico abaixo.
Como o Redis armazena os dados
Redis não funciona como um banco relacional, então ele não tem tabelas nem colunas como no PostgreSQL ou MySQL.
O Redis trabalha com estruturas de dados em memória, como:
• Strings
• Hashes
• Sets
• Lists
• Sorted Sets
• E outras
Mas o mais comum e direto é usar chave-valor simples (String → String). Redis é, por natureza, um key-value store.
No seu caso (reserva de assento), você usaria algo assim:
• Chave: "assento:B1"
• Valor: "usuario_123" ou "reserva_abcd"
Ou seja, o Redis vai armazenar algo assim:
"assento:B1" → "usuario_123"Essa entrada é uma chave chamada assento:B1, com um valor associado (como o ID do usuário ou da reserva).
Visualmente, é como se o Redis tivesse uma “caixinha” de chaves 📦:

Mas isso é só uma abstração mental — não tem tabela de verdade. Cada chave é armazenada de forma independente, direto na memória, e pode ter ou não expiração.
🚫 O que não tem no Redis:
• Não tem schema fixo (você define o que quiser nas chaves/valores).
• Não tem JOIN.
• Não tem colunas.
• Não tem índice relacional (só estruturas de dados otimizadas internas).
Naming das chaves
Você pode usar prefixos pra organizar melhor, como:
assento:B1
reserva:usuario_123
sessao:12345:assento:B1Assim você cria uma “estrutura” lógica dentro do Redis, mesmo que internamente ele não use tabelas.3
E se a gente usasse MongoDB com TTL e operações atômicas?
Embora o Redis seja o queridinho quando falamos de distributed locks, ele não é a única peça do jogo. Em alguns cenários, é possível usar o MongoDB como alternativa eficiente, aproveitando duas características importantes: operadores atômicos e documentos com TTL (Time To Live).
Como isso ajuda?
Ao armazenar os assentos em uma coleção, podemos aplicar uma operação atômica (findOneAndUpdate, por exemplo) para garantir que apenas uma transação consiga marcar o assento como reservado de forma segura. O MongoDB garante que essa operação seja indivisível, ou seja, nenhuma outra tentativa consegue modificar aquele documento enquanto a atualização está ocorrendo.
E o TTL?
Quando um usuário começa o processo de compra, o sistema pode criar um “documento de reserva temporária” com um campo de expiração. O MongoDB, com índice TTL configurado, automaticamente remove esse documento depois de um tempo se a compra não for concluída. Isso libera o assento novamente, evitando bloqueios permanentes por abandono de carrinho ou falhas no processo.
Em resumo:
• O lock acontece com uma operação atômica.
• O TTL evita bloqueios eternos.
• Tudo isso sem precisar de Redis.
Claro, isso exige cuidado com o design da base e a modelagem dos documentos, mas é uma alternativa viável, especialmente para quem já usa MongoDB e quer evitar introduzir mais uma tecnologia no stack.
Mas pera… o Redis não é mais rápido que o MongoDB?
Sim, o Redis é absurdamente rápido, justamente por rodar na memória RAM. Mas nem todo sistema precisa dessa velocidade extrema, e em muitos casos, a simplicidade e a consistência de manter tudo no MongoDB já são suficientes e até vantajosas.
Se seu sistema já usa o Mongo como banco principal, evitar adicionar mais uma tecnologia (como o Redis) pode reduzir a complexidade operacional, facilitar o deploy e manter tudo mais coeso. Além disso, o MongoDB lida bem com concorrência quando usamos as operações atômicas certas, e os TTLs ajudam a liberar recursos de forma automática e segura.
Ou seja: se o seu tráfego não é de altíssima escala ou se o tempo de reserva do assento não precisa ser resolvido em microssegundos, usar o Mongo pode ser um meio-termo muito eficiente, estável e fácil de manter.
E se a gente usasse filas junto com o Redis?
Talvez você esteja pensando:
“Ok, entendi que o Redis pode ser rápido, e o Mongo pode ser viável… mas e se a gente usar uma fila? Como isso entra na jogada?”
Boa pergunta!
Usar filas de mensagens (como RabbitMQ, Kafka ou até uma fila simples com Redis Streams) pode ser uma abordagem poderosa quando você quer controlar bem a ordem e a carga das requisições. A ideia é simples: ao invés de processar as reservas diretamente assim que o clique acontece, você joga o pedido numa fila, e um processo dedicado vai pegando esses pedidos, um por vez, para verificar e reservar os assentos.
O que isso resolve?
• Evita que dois usuários disputem o mesmo assento ao mesmo tempo.
• Garante uma ordem clara de chegada.
• Dá margem para reprocessar falhas ou escalar horizontalmente os consumidores.
Agora, entra o Redis de novo — só que dessa vez, não como lock, mas como armazenamento temporário de reservas em andamento, enquanto os pedidos estão sendo processados na fila. Ele também pode ajudar a criar um cache rápido de assentos já vendidos ou indisponíveis, aliviando a carga no banco principal.
Um pequeno exemplo:
1. O usuário clica para reservar um assento.
2. O sistema manda esse pedido para uma fila.
3. Um consumidor pega esse pedido, checa se o assento está livre, e grava no banco.
4. O Redis pode manter o status de assentos em tempo real (vendido, reservado, expirado etc.).
Essa arquitetura é super útil em cenários com altíssima concorrência, como venda de ingressos para grandes shows ou passagens promocionais — onde cada segundo (ou milissegundo) importa.
Distributed Lock Não é só sobre bloquear — é sobre garantir confiança
Ao longo deste artigo, a gente viu que trabalhar com concorrência em sistemas distribuídos é mais do que uma questão técnica — é uma questão de experiência do usuário, consistência dos dados e confiança no sistema.
Começamos com uma pergunta simples: “Como garantir que dois usuários não reservem o mesmo assento ao mesmo tempo?”
E a partir daí, mergulhamos em conceitos que, embora pareçam complexos à primeira vista, fazem total sentido quando colocados em cenários do mundo real:
• Bloqueio distribuído (Distributed Lock) como forma de garantir exclusividade temporária de recursos.
• Redis como store central confiável e rápido para coordenar esses bloqueios em ambientes escaláveis.
• E o papel essencial do Write-Ahead Logging (WAL) na proteção da integridade dos dados, mesmo quando tudo dá errado.
A combinação de lock distribuído com persistência confiável cria uma base sólida para qualquer sistema que lide com reservas, estoques, pagamentos ou qualquer tipo de recurso exclusivo.
No fim das contas, a mensagem é simples:
Não basta travar. É preciso garantir que, uma vez que uma decisão foi tomada, ela não se perca ou gere um estado inconsistente.
E é isso que torna um sistema confiável — tanto para o negócio quanto para o usuário.
Redis é um banco de dados em memória, super rápido, usado principalmente para cache, filas, contadores e armazenamento de dados temporários. Ele é do tipo key-value, ou seja, armazena dados como pares de chave e valor.
Por padrão, o Redis salva todos os dados diretamente na memória RAM, o que garante alta performance. No entanto, ele também pode ser configurado para persistir os dados no disco (HD ou SSD), usando dois mecanismos: RDB (Redis Database Backup), que salva snapshots periódicos, e AOF (Append Only File), que registra cada operação de escrita.
Assim, mesmo sendo um banco em memória, o Redis pode manter os dados salvos entre reinicializações, dependendo da configuração.
Por que a remoção do lock deve ser a última etapa?
O lock distribuído no Redis tem a função de garantir que nenhum outro usuário consiga reservar o mesmo assento até que a reserva esteja realmente concluída.
Se removermos o lock antes de gravar a reserva no banco de dados, corremos o risco de criar uma situação de condição de corrida.
Problema se o lock for removido antes de salvar no banco
Imagine este fluxo incorreto:
1️⃣ O usuário inicia o pagamento.
2️⃣ O sistema remove o lock no Redis antes de gravar a reserva no banco.
3️⃣ Enquanto a transação no banco de dados ainda está acontecendo, outro usuário tenta reservar o mesmo assento.
4️⃣ Como o lock já foi removido, o sistema permite a nova reserva antes que a reserva original tenha sido confirmada.
5️⃣ Agora temos dois usuários acreditando que reservaram o mesmo assento, mas apenas um deles terá a reserva no banco.
Isso é um erro crítico, pois pode resultar em overbooking ou problemas de concorrência no sistema.
Bora ver bem rapidamente como uma aplicação Spring Boot interage com isso na prática, com um exemplo direto e explicativo.
Vamos imaginar o seguinte:
• Quando o usuário seleciona o assento B1, queremos:
1. Verificar se ele já está reservado (ou seja, se a chave assento:B1 existe no Redis).
2. Se estiver livre, reservar por 10 minutos (TTL).
3. Se já estiver reservado, avisar o usuário.
Dependência no pom.xml
Se estiver usando Maven:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>E no application.yml:
spring:
redis:
host: localhost
port: 6379Serviço de reserva de assento
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;
import java.time.Duration;
@Service
public class AssentoService {
@Autowired
private StringRedisTemplate redisTemplate;
private static final Duration TEMPO_RESERVA = Duration.ofMinutes(10);
public boolean reservarAssento(String assentoId, String usuarioId) {
String chave = "assento:" + assentoId;
// Tenta setar a chave *somente se ela ainda não existe*
Boolean sucesso = redisTemplate
.opsForValue()
.setIfAbsent(chave, usuarioId, TEMPO_RESERVA);
return Boolean.TRUE.equals(sucesso); // true se reservou com sucesso, false se já estava reservado
}
public boolean assentoReservado(String assentoId) {
String chave = "assento:" + assentoId;
return Boolean.TRUE.equals(redisTemplate.hasKey(chave));
}
public String quemReservou(String assentoId) {
String chave = "assento:" + assentoId;
return redisTemplate.opsForValue().get(chave);
}
public void liberarAssento(String assentoId) {
String chave = "assento:" + assentoId;
redisTemplate.delete(chave);
}
}Como seria o uso no controller
@RestController
@RequestMapping("/assentos")
public class AssentoController {
@Autowired
private AssentoService assentoService;
@PostMapping("/reservar/{assentoId}")
public ResponseEntity<String> reservar(@PathVariable String assentoId,
@RequestParam String usuarioId) {
boolean reservado = assentoService.reservarAssento(assentoId, usuarioId);
if (reservado) {
return ResponseEntity.ok("Assento reservado com sucesso!");
} else {
String quem = assentoService.quemReservou(assentoId);
return ResponseEntity.status(HttpStatus.CONFLICT)
.body("Assento já reservado por: " + quem);
}
}
}Resultado
Com esse código (é o jeito mais simples e rápido de implementar, mas sei que existem códigos melhores, aqui é apenas um exemplo raso):
• O Redis armazena assento:B1 com valor "usuario_123" por 10 minutos.
• Se alguém tentar reservar durante esse tempo, vai receber uma mensagem de conflito.
• Se passar o tempo e o usuário não concluir a reserva, o Redis limpa automaticamente.