
É fácil de manter?
O custo de manutenção é um dos maiores custos de um sistema de software. Não escreva um software que você não pode manter. - Robert C. Martin.

Código de fácil manutenção - essa é uma frase que você ouve muito na indústria de software. No entanto, o que realmente significa e por que é tão importante? Vamos comentar e discutir sobre esse tema!
O que significa?
Segundo o dicionário Oxford Languages, a manutenção é definida como:
Ação ou efeito de manter ou conservar.
Ação de fazer com que algo permaneça, perdure.
Trabalho regular ou periódico de conservação.
Vemos que a palavra "manutenção", na sua essência, é um conceito abrangente que engloba uma variedade de atividades, desde a correção de erros até a implementação de novas funcionalidades. Na indústria de software, a manutenção é um processo contínuo que ocorre ao longo da vida útil de um sistema. E ao falarmos em "facilidade", estamos nos referindo à redução da complexidade e do esforço necessários para realizar tais atividades de manutenção.
Agora, se levarmos para a engenharia de software, estamos nos referindo à prática de criar um código que possa ser facilmente compreendido, testado, modificado e estendido. É o princípio de produzir um software que seja não só funcional, mas também de qualidade, eficiente e, acima de tudo, sustentável no longo prazo.
Mas, por que a manutenção do código é tão crucial? A resposta é clara. O desenvolvimento de software não é um processo estático, mas uma jornada dinâmica. À medida que os requisitos mudam, que novas funcionalidades são necessárias ou que defeitos são descobertos, o código precisa evoluir. E aqui entra a necessidade de uma manutenção eficiente.
Se um código é difícil de manter, cada mudança se torna um desafio que consome tempo e recursos, com o risco constante de introduzir novos bugs.
Por que se importar com a manutenção?
Imagine por um momento que você acabou de comprar um carro novo. No entanto, mesmo sendo uma máquina tão impressionante, com o passar do tempo, será necessário fazer a manutenção regular para garantir que ele continue funcionando bem. Se ignorarmos a manutenção - trocas de óleo, alinhamento de rodas, verificações de freio, entre outros - é muito provável que nosso lindo carro comece a apresentar problemas.
Assim como carros, qualquer software também precisa de manutenção regular. À medida que o software é usado, modificado e evolui, surgem novos requisitos e os antigos podem mudar ou sofrer pequenas adequações. Além disso, bugs precisam ser corrigidos, afinal não existe nenhum sistema que não contenha bugs.
Aqui é onde a importância da manutenção de software realmente brilha. Um código de fácil manutenção não só torna essas tarefas inevitáveis menos onerosas, como também pode melhorar significativamente a qualidade geral do software. Manter a qualidade ao longo do tempo significa menos bugs, menos tempo de inatividade e, em última análise, usuários mais satisfeitos.
Aqui reside o verdadeiro desafio: o software não é apenas sobre o que ele pode fazer no início, mas o quão bem ele pode se transformar e evoluir ao longo do tempo de maneira confiável. Por isso, a manutenção do software deve ser uma prioridade.
Mas o que deveria ser fácil de manter? Quando falamos em manutenibilidade de código, estamos nos referindo a diversas unidades de código, desde as menores como funções ou métodos, até unidades maiores como classes, módulos, componentes e até mesmo sistemas inteiros.
Pense no software como sendo uma cidade. As funções e métodos seriam as casas e prédios, as classes seriam quarteirões, os componentes seriam bairros e o sistema completo seria a cidade em si. Agora, pense em uma cidade fácil de manter. As casas e prédios são bem projetados e construídos, o que reduz a necessidade de reparos frequentes. Os quarteirões têm infraestrutura adequada, como acesso a água, eletricidade e saneamento, o que facilita a vida dos habitantes. Os bairros são bem planejados, com fácil acesso a serviços e comércio, e a cidade como um todo tem um bom sistema de transporte e serviços públicos eficientes.
Agora pense nisso para nosso contexto, funções e métodos devem ser pequenos e ter uma única responsabilidade (princípio SRP). Isso torna mais fácil entender o que eles fazem e, se necessário, podemos alterar seu comportamento, estender ou corrigir um bug sem afetar outras partes do software.
As classes também devem ter responsabilidades claramente definidas e devem ser projetadas de tal forma que sejam coesas (ou seja, os métodos e propriedades dentro da classe estão intimamente relacionados) e com baixo acoplamento (ou seja, a classe não depende fortemente de outras classes).
Os componentes ou módulos, que são grupos de classes que trabalham juntas para fornecer determinada funcionalidade, também devem ser projetados com a manutenibilidade em mente. Isso significa que eles devem ser autocontidos e capazes de funcionar independentemente de outros componentes, tanto quanto possível. Sobre isso vamos comentar um pouco mais afundo.
Quatro características essenciais para qualquer classe!
Clareza: Sem dúvida é uma das características mais relevantes de uma classe facilmente mantida. Uma classe clara tem um nome que expressa efetivamente sua finalidade, métodos que são nomeados de acordo com as operações que realizam, e comentários que esclarecem as partes mais intrincadas do código. Se ao lermos uma classe, temos uma compreensão imediata de sua função no sistema global, então temos uma forte indicação de que é uma classe clara. Benefícios dessa abordagem incluem facilitar a onboarding de novos desenvolvedores no projeto e reduzir a quantidade de tempo gasto tentando entender o que a classe faz.
Coesão: Uma classe fácil de manter também é altamente coesa, o que significa que ela tem uma responsabilidade bem definida. Para programadores, coesão se refere à medida em que os elementos de uma classe pertencem juntos. Uma classe coesa faz uma coisa e faz bem, o que torna mais fácil entender, testar e modificar. A coesão promove a modularidade e a reutilização do código, pois uma classe que realiza uma única tarefa pode ser usada em vários contextos sem alterações.
Baixo acoplamento: Refere-se à interdependência entre as classes. Uma classe fácil de manter tem baixo acoplamento, ou seja, é independente e não depende muito de outras classes. Isso permite que mudanças sejam feitas em uma classe sem afetar outras partes do sistema. O baixo acoplamento é benéfico, pois ajuda a isolar as partes do sistema, facilitando a compreensão, teste e alteração do código.
Encapsulamento: É um princípio que permite esconder a complexidade interna dos componentes e expor apenas operações e atributos necessários para a interação com outros componentes. Uma classe bem encapsulada é como uma caixa preta: conhecemos suas entradas e saídas, mas não precisamos entender detalhadamente o seu funcionamento interno para usá-la. Isso favorece a clareza do código, torna-o mais seguro e menos propenso a erros, pois os detalhes internos de implementação estão 'protegidos' contra acesso direto e manipulação. Além disso, o encapsulamento torna o sistema mais flexível, pois se os detalhes internos de uma classe precisam ser alterados, essa mudança não afeta diretamente as outras partes do código que usam essa classe.
Combinando essas quatro características, criamos um cenário onde a manutenção do código se torna uma tarefa menos assustadora e mais gerenciável. Isso aumenta a produtividade da equipe também! Esses atributos são essenciais. Mas vamos olhar mais de perto para o terceiro e quarto, baixo acoplamento e encapsulamento.
Cuidado com o acoplamento!
Quando falamos em baixo acoplamento, estamos nos referindo a um cenário em que as classes têm poucas dependências, ou seja, uma classe não precisa saber muito sobre outras classes para funcionar. Vamos ver isso na prática, mas ao contrário, vamos utilizar um exemplo ruim, para que todos possam entender o quão sério é o forte acoplamento:
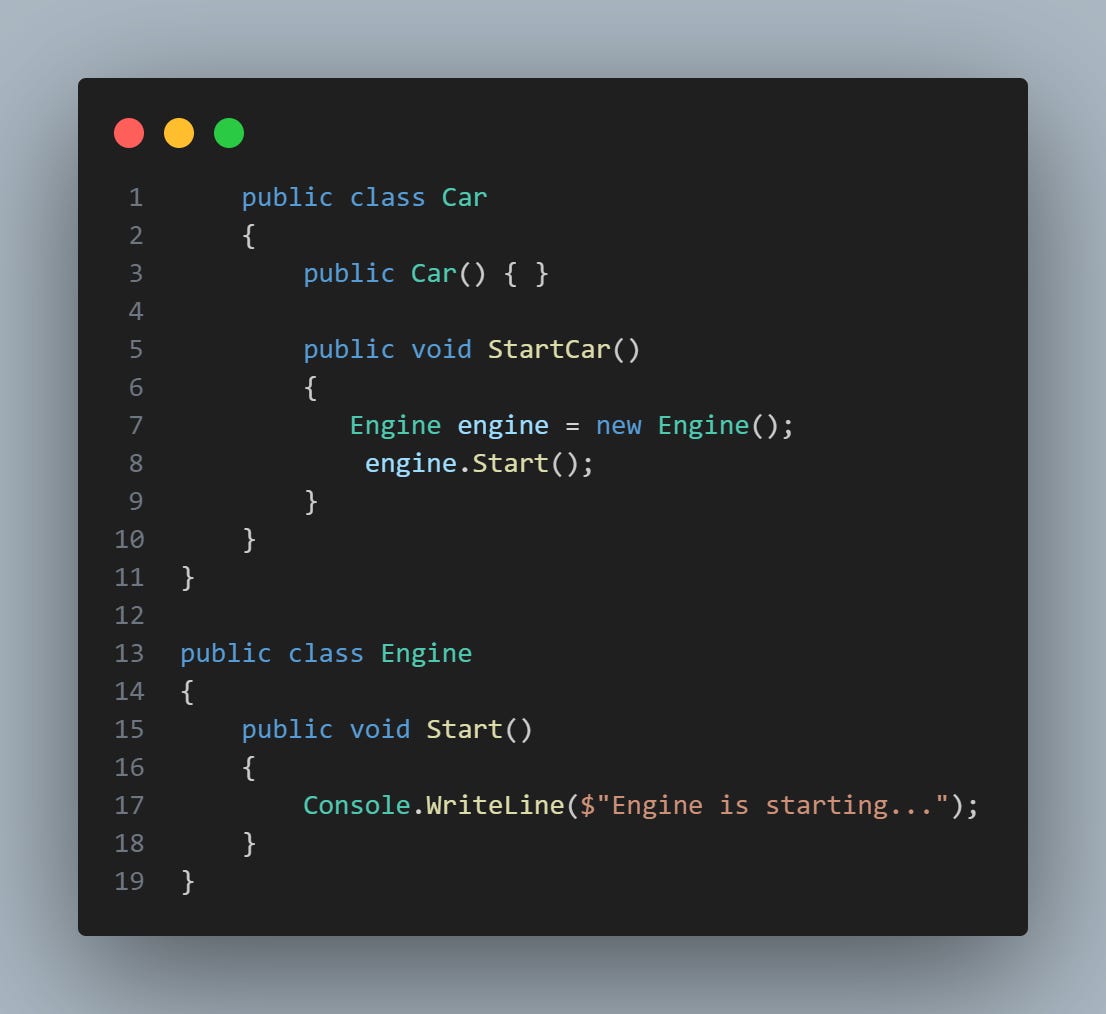
Aqui, a classe Car está fortemente acoplada à classe Engine. Isto é, a classe Car tem um alto nível de dependência da classe Engine, porque cria uma instância de Engine diretamente dentro do método StartCar.
Isso apresenta um problema, pois qualquer alteração na classe Engine pode afetar a classe Car. Além disso, fica difícil testar a classe Car isoladamente, porque o método StartCar sempre cria uma nova instância de Engine, então você não pode testar o método StartCar com uma instância simulada (ou "mock") de Engine.
Isso pode ser problemático em um sistema maior, onde a classe Engine pode ter suas próprias dependências e pode ser complexa para configurar para testes. Também torna o sistema como um todo menos flexível, porque você não pode, por exemplo, substituir Engine por uma versão diferente ou uma implementação totalmente diferente sem alterar a classe Car.
Gostaria de demonstrar como uma alteração na classe Engine pode impactar a classe Car no exemplo que forneci. Vamos pensar que, por alguma razão, a classe Engine precisa ser modificada para exigir um tipo de combustível no momento da inicialização:

Agora note o que ocorre na classe Car:

O erro na IDE nos alerta:
Não há nenhum argumento fornecido que corresponda ao parâmetro necessário 'fuelType' de 'Engine.Engine(string)'.
Este erro ocorre quando tentamos criar uma nova instância da classe Engine sem fornecer um argumento para o seu construtor que exige um parâmetro do tipo string para o fuelType. Mas você pode estar pensando:
“Ah, mas isso é tranquilo de resolver, basta criar um construtor vazio… certo?”
Criar um construtor vazio para a classe Engine não resolveria completamente o problema do acoplamento. A situação em que a classe Car é responsável por instanciar Engine persiste, criando um acoplamento direto entre as duas classes.
Isso significa que, se o processo de criação de uma Engine se tornar mais complexo no futuro (por exemplo, se a Engine precisar de outras dependências para ser instanciada), teremos que alterar a classe Car para acomodar essas mudanças. Isso contraria o princípio da responsabilidade única e pode levar a um código mais difícil de manter e testar.
Idealmente, gostaríamos de ter uma situação em que a Car simplesmente recebe uma Engine já criada que possa utilizar, sem ter que se preocupar com os detalhes de como a ela é criada. Isso é algo que a injeção de dependência nos ajuda a alcançar.
Vamos explicar isso mais profundamente e com uma analogia.
As vantagens da DI
A injeção de dependência é uma técnica usada na programação orientada a objetos que permite uma classe delegar a responsabilidade de criar suas dependências para uma entidade externa. Esta inversão de controle (no final do tópico vamos ver as diferenças entre inversão de controle e injeção de dependência) aumenta a flexibilidade e torna a classe mais fácil de ser testada e mantida. Como ocorre? Veja mais detalhadamente na nota do rodapé. 1
Vou tentar fazer uma analogia para que a explicação fique mais clara em sua mente. Imagine uma classe como sendo uma casa. Se a residência for responsável por gerenciar suas próprias dependências - digamos, produzindo sua própria eletricidade ou purificando sua própria água - qualquer problema ou mudança nessas dependências poderia afetar a casa inteira. Por exemplo, se o gerador que produz a eletricidade falhar, a casa fica no escuro. Além disso, se decidirmos mudar a fonte de energia, talvez de um gerador para energia solar, a casa deve ser adaptada para lidar com isso.
Agora, vamos pensar em uma casa que, em vez de gerenciar essas dependências internamente, está conectada à rede elétrica e à rede de água. A casa não se preocupa com como a eletricidade é produzida ou a água é purificada. Ela simplesmente "usa" esses recursos. Se decidirmos mudar a fonte de energia para energia solar, não precisamos mudar nada na casa. A mudança ocorre no nível da rede.
Isso é semelhante à DI. Em vez de uma classe ser responsável pela criação e gerenciamento de suas próprias dependências, essas dependências são "injetadas" nela de fora. Isso significa que a classe não precisa se preocupar com os detalhes de como essas dependências são criadas ou como elas podem mudar ao longo do tempo. Por exemplo. Em vez de criar um Motor diretamente, a classe Carro declararia que precisa de um Motor (geralmente através do construtor ou de um método setter), e então alguma entidade externa seria responsável por fornecer (ou "injetar") o Motor adequado.
Vamos voltar ao primeiro exemplo e realizar a adequação e desacoplar a classe:

O pequeno trecho abaixo, mostra como o desacoplamento fica visível:
Engine engine = new Engine("Gasoline");
Car car = new Car(engine);
car.Drive();Portanto, a injeção de dependência é uma técnica essencial e que ajuda a tornar o seu código mais modular, flexível e testável.
Obviamente não para por ai. Podemos utilizar interfaces (contratos) para fazer isso também. Então para esse caso a diferença é que a classe Engine implementa uma interface por exemplo IStarter. E apenas precisamos chamar a interface na classe Car:
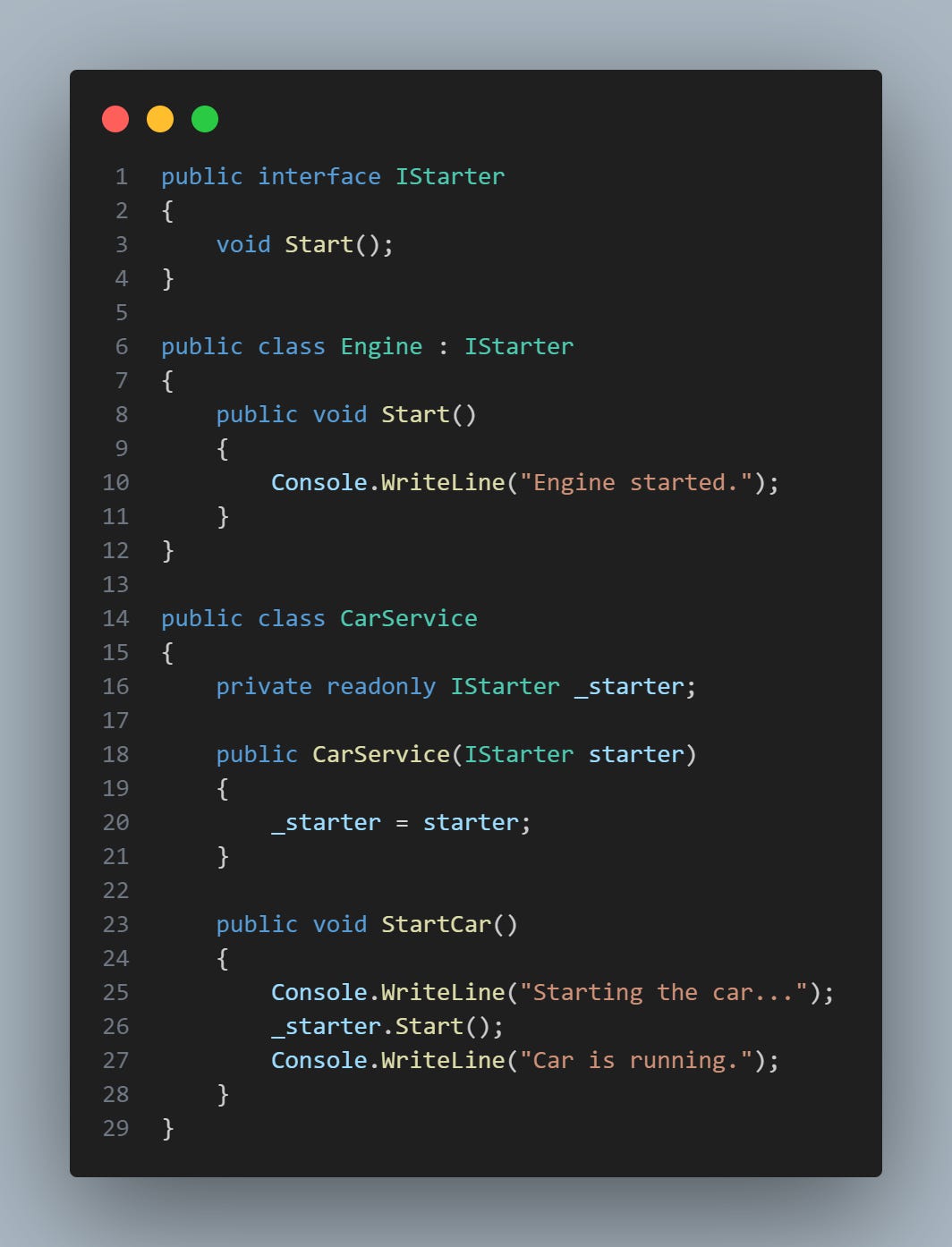
A escolha entre essas duas abordagens dependerá das necessidades específicas do seu projeto e da sua arquitetura.
Para uma explicação mais detalhada, leia abaixo sobre as diferenças entre os dois e como estão relacionados.
Inversão de Controle (IoC)
Inversão de Controle é um princípio de design no qual o controle do fluxo de um programa é invertido. Em vez de o código do aplicativo controlar o fluxo, um contêiner ou framework toma o controle. Isso permite maior desacoplamento e flexibilidade.
Injeção de Dependência (DI)
Injeção de Dependência é um padrão específico que implementa o princípio de IoC. É uma técnica que permite que um objeto receba suas dependências de fora, em vez de criar elas internamente. Isso também facilita o desacoplamento e torna o código mais testável.
Relação Entre IoC e DI
DI é uma forma de realizar a Inversão de Controle. Através da injeção, o controle sobre como e quando as dependências são criadas e associadas é retirado dos objetos dependentes e dado a um contêiner ou framework.
Exemplo:
Vamos para a classe Car que depende de um objeto Engine.
Sem IoC e DI: A classe
Carinstanciaria e controlaria o objetoEnginediretamente.Com IoC: O controle sobre como o objeto
Engineé criado e associado aoCaré retirado da classeCare gerenciado externamente.Com DI: O objeto
Engineé injetado na classeCarpor um contêiner ou construtor, em vez de ser criado pela própria classeCar.
É importante lembrar, enquanto IoC é um conceito mais amplo que inverte o controle do fluxo do programa, a Injeção de Dependência é uma técnica específica que implementa esse princípio, focando no modo como os objetos obtêm suas dependências.
Então, no exemplo anterior a interface IStarter é usada como uma abstração para a ação de iniciar. A classe Engine implementa essa interface, e a classe Car depende apenas da abstração (interface), e não da implementação concreta. Isso é uma forma de IoC, pois inverte o controle de como o comportamento de início é fornecido para a classe Car.
Além disso, é também é um exemplo de Injeção de Dependência, pois a dependência IStarter é injetada na classe Car através do construtor. Isso significa que a classe Car está desacoplada de qualquer implementação específica de IStarter
Encapsular… o que?
Vamos direto ao ponto. Pense em uma classe que em vez de ocultar corretamente detalhes que não deveriar estar expostos, faz seu trabalho muito mal. Quando há um encapsulamento vazado (ou vazamento de detalhes de implementação), significa que os detalhes internos de uma classe ou módulo estão sendo expostos e utilizados por outras classes ou módulos, o que leva a um acoplamento desnecessário.
Isso pode tornar o código muito difícil de manter e evoluir, porque qualquer mudança em um módulo pode ter efeitos colaterais indesejados em outros módulos que estão acoplados a ele. Além disso, vazar detalhes de implementação pode tornar o código mais difícil de entender e de testar, já que as dependências entre os módulos podem ser complexas e não óbvias.
É importante mostrar isso na prática. Vamos continuar utilizando o exemplo da classe Car e Engine, mas agora alterando um pouco a estrutura interna, veja o código na imagem abaixo:
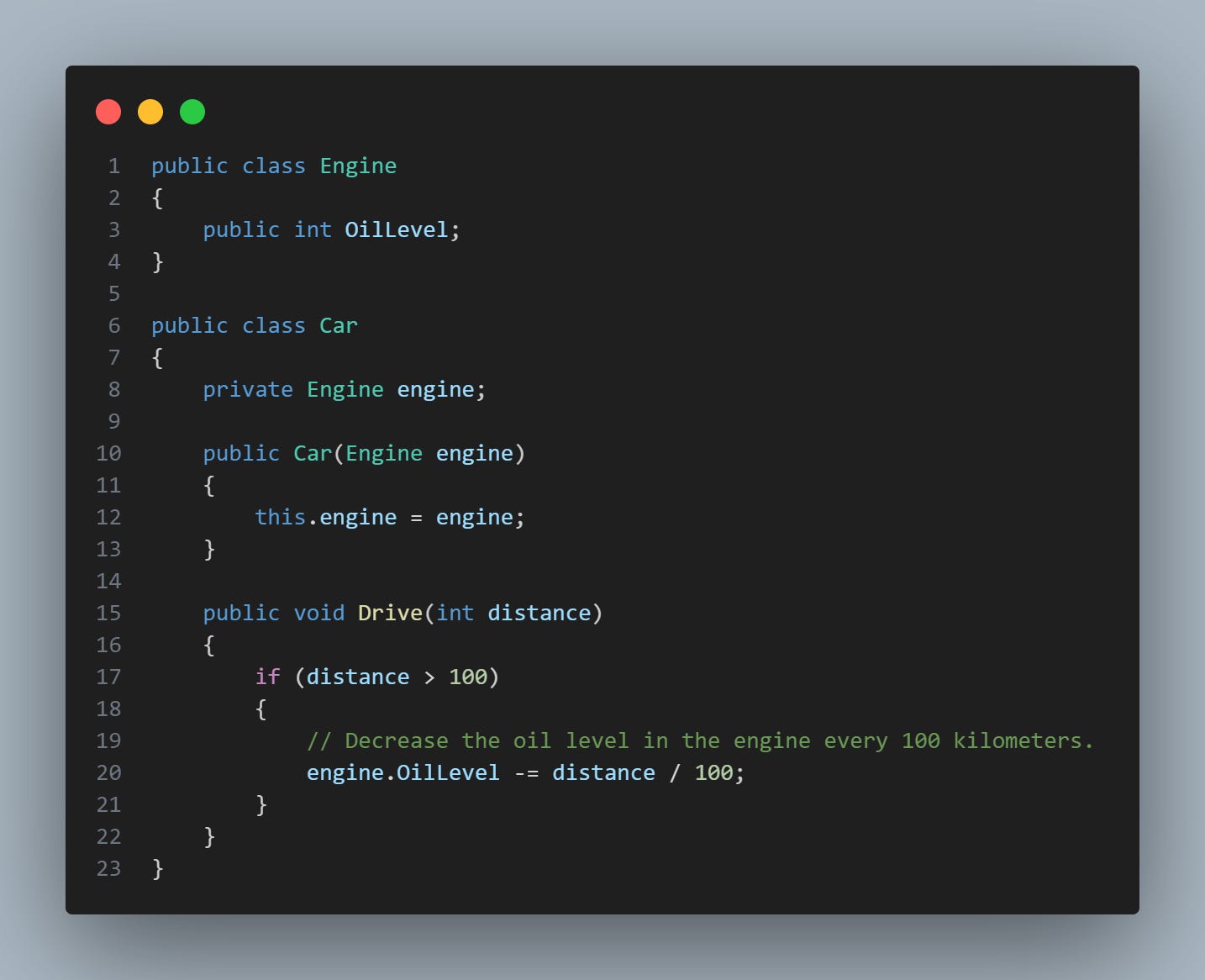
Neste exemplo, a classe Car está diretamente acessando e modificando o campo OilLevel da classe Engine. Então temos um detalhe de implementação sendo vazado? Por que? Note que a classe Car tem conhecimento dos detalhes internos da classe Engine e está diretamente manipulando seus campos.
Se, no futuro, a maneira como a classe Engine lida com seu nível de óleo mudar (por exemplo, talvez queiramos medir o nível de óleo em litros, em vez de um valor abstrato), teríamos que alterar o código na classe Car e em qualquer outra classe que acesse diretamente o campo OilLevel.
Para corrigir esse vazamento de encapsulamento, é muito melhor adicionar um método UseOil() na classe Engine e chamá-lo de dentro da classe Car:
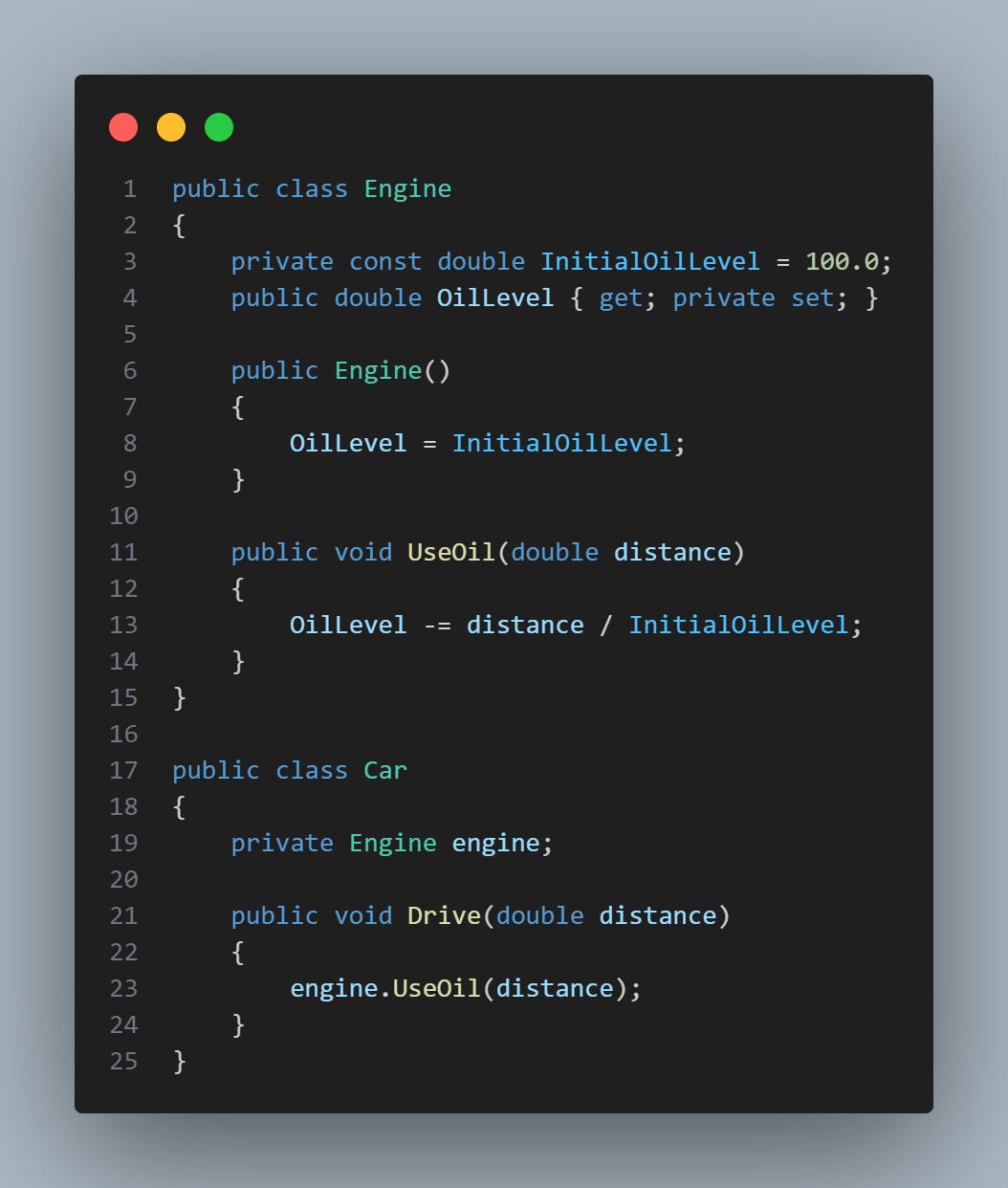
Podemos destacar alguns benefícios:
Melhor Organização e Legibilidade: Agora, é claro que a responsabilidade de gerenciar o nível de óleo pertence exclusivamente à classe
Engine. Isso torna o código mais fácil de ler e entender.Manutenibilidade: Se a lógica de como o óleo é usado precisar mudar no futuro, só precisamos alterar o método
UseOil()na classeEngine. Nós não teríamos que procurar em todo o projeto por lugares onde o campoOilLevelé acessado diretamente.Robustez: Ao encapsular a lógica do óleo dentro da classe
Engine, estamos protegendo a classeCarde possíveis bugs. Se houvesse um erro na lógica de uso do óleo, isso seria isolado na classeEnginee seria menos provável que afetasse a classeCar.
Ficou claro que a manutenção fica mais fácil!
É realmente fácil de manter?
Vamos para exemplos mais práticos do nosso dia a dia para mergulhar mais afundo no tema. Acho interessante iniciar falando de um assunto que muitos precisam prestar atenção no dia a dia, números mágicos no código.
À primeira vista, eles podem parecer inofensivos ou até mesmo uma forma conveniente de codificar rapidamente um determinado comportamento. No entanto, sua presença no código tem várias implicações negativas, muitas das quais são frequentemente ignoradas pelos desenvolvedores.
Um dos pontos cruciais frequentemente negligenciados é que essas constantes mágicas tornam o código menos compreensível. Quando você vê um número mágico no código, não é imediatamente claro o que esse número significa ou por que é importante. Vamos a prática!

Aqui, 20 e 30 são constantes mágicas que representam a taxa horária regular e a taxa horária de horas extras. No entanto, estas taxas não são explicadas no código, e se essas taxas precisarem ser alteradas no futuro, será necessário procurar por todas as ocorrências desses números no código.
Além disso, se o mesmo valor for usado em vários lugares, cada ocorrência terá que ser encontrada e alterada manualmente, aumentando a chance de erros.
Isso torna o código menos flexível e mais difícil de manter. Um programador que venha a trabalhar com esse código no futuro pode não saber o que esses números representam e pode ter dificuldades para modificá-lo ou estendê-lo. Uma abordagem mais clara, seria dar nomes significativos e mante-las em um único lugar para fácil modificação.
Mas talvez isso não seja um problema para você. Por isso gostaria de mostrar outro exemplo:
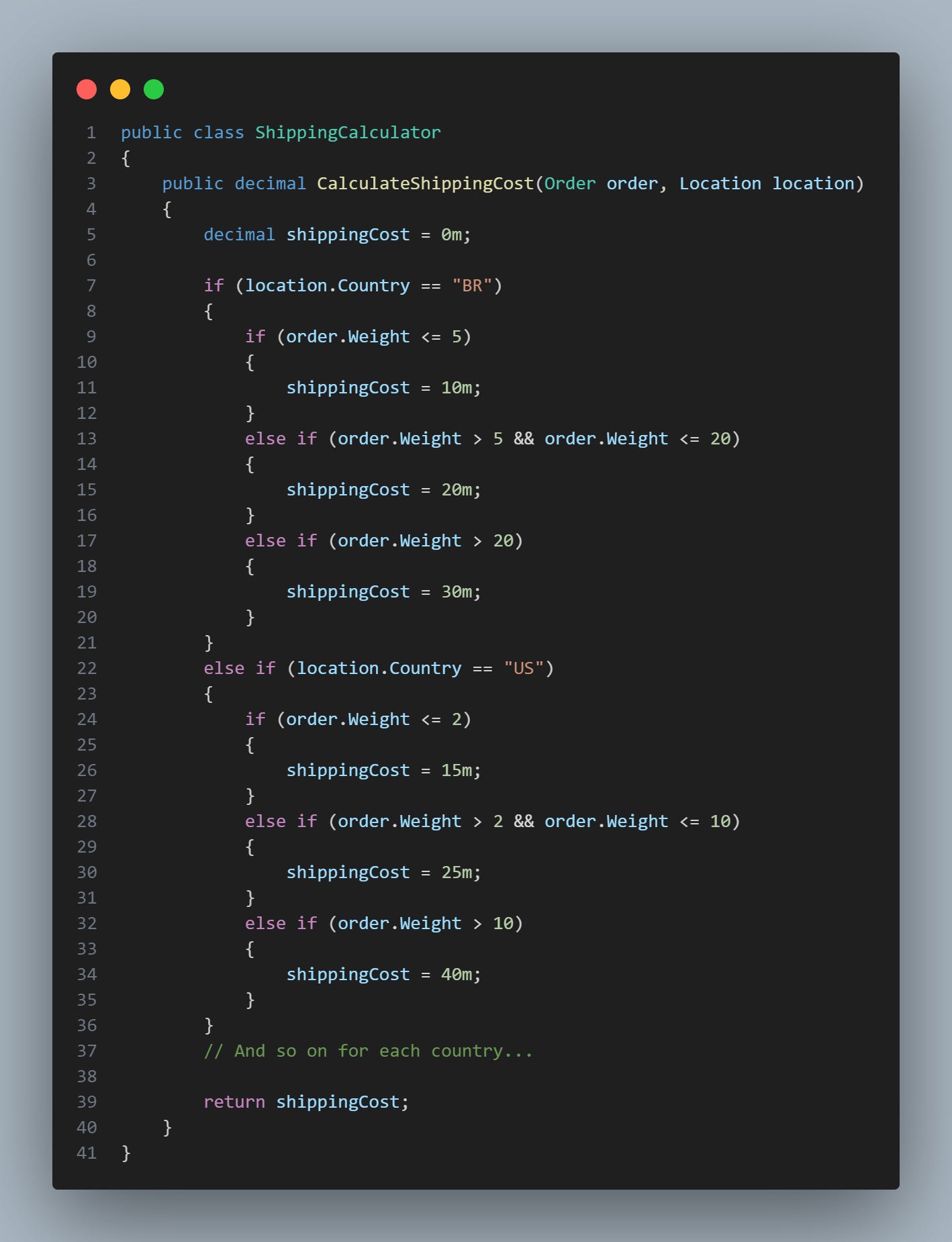
Em muitas plataformas de comércio eletrônico, há um aspecto que frequentemente aparece por trás das cortinas: um sistema de cálculo de frete. Este sistema, essencialmente, decide o valor que um cliente deve pagar para que sua compra seja entregue em seu endereço. E sabe como ele faz isso? Ele se baseia em vários critérios. Mas notou como o método está fazendo muitas coisas? À primeira vista, este método parece estar funcionando corretamente e atendendo ao propósito. No entanto, existem várias questões que podem torná-lo difícil de manter no futuro.
1. Complexidade e legibilidade: Com o tempo, à medida que a lógica de negócios se torna mais complexa (por exemplo, introduzindo taxas especiais para regiões específicas, ofertas especiais, etc.), a quantidade de if-else aumentará drasticamente, tornando o código cada vez mais difícil de entender e manter.
2. Violação do princípio Open/Closed: Fica claro que a classe/método viola o princípio Open/Closed, que afirma que o software deve estar aberto para extensão, mas fechado para modificação. Cada vez que uma nova regra é adicionada, o código precisa ser alterado.
3. Dificuldade de teste: Cada novo caso requer um novo teste, o que pode tornar os testes muito complexos. Além disso, se uma mudança for introduzida, pode ser difícil isolar o efeito dessa mudança nos testes existentes.
4. Repetição de código: A estrutura geral de cada condicional é a mesma, com a única diferença sendo os valores usados. Isso é uma repetição de código, que poderia ser evitada com um design melhor.
Uma solução possível para estes problemas seria utilizar o padrão de design Strategy, que permite definir uma família de algoritmos, encapsulá-los como classes separadas e torná-los intercambiáveis. Mas essa não é a única solução, vamos explorar rapidamente outras.
Para cada problema existem várias soluções!
Além do padrão Strategy, como mencionado anteriormente, existem outras abordagens que podem ser empregadas para tornar o código mais manejável, extensível e fácil de manter. Duas dessas abordagens são a segregação de responsabilidades e o padrão Specification.
A Segregação de Responsabilidades é um princípio que afirma que uma classe ou módulo deve ter apenas uma razão para mudar. Isto significa que cada classe ou módulo deve ter apenas uma única responsabilidade. Ao dividir o software em componentes que realizam uma tarefa específica, podemos isolar o comportamento e a complexidade. Isso torna o sistema como um todo mais compreensível e mais fácil de manter e estender.
Vamos voltar ao nosso exemplo de cálculo de frete. Nesse caso, o cálculo do custo de envio para cada país pode ser visto como uma responsabilidade separada. Portanto, podemos criar uma classe separada para o cálculo do custo de envio para cada país. Isso resultaria em classes como BrazilShippingCalculator, USShippingCalculator, etc. Cada uma contendo a lógica específica para o cálculo do custo de envio para esse país. Essa abordagem torna o fluxo do código e ramificações fácil de acompanhar, mais fácil de testar, manter e estender.
O padrão Specification, por outro lado, é um padrão que nos permite encapsular regras de negócios em classes separadas. Cada classe de especificação contém uma lógica de negócios que pode ser combinada com outras para criar regras empresariais mais complexas. O padrão é útil quando temos uma lógicas complexas que precisam ser representadas de maneira reutilizável e modular.
No exemplo de cálculo de frete, cada condição if-else pode ser vista como uma regra de negócios que pode ser encapsulada em uma especificação. Por exemplo, poderíamos ter especificações como IsHeavyPackage, IsLightPackage, IsMediumPackage, IsDestinationBrazil, IsDestinationUS, etc. Cada uma dessas especificações pode então ser usada para determinar o custo de envio apropriado. Apenas para sanar algumas dúvidas, veja como ficaria com o auxilio desse pattern:

Veja que essa regra importante e que afeta diretamente os usuários não está mais dentro de uma estrutura condicional propensa a erros. Agora temos uma classe própria para isso.
As abordagens proporcionam maneiras robustas de lidar com a complexidade, facilitando a manutenção e a extensão do código. A escolha entre elas (ou a combinação delas) dependerá da natureza específica do problema que você está tentando resolver. O importante é reconhecer que existem ferramentas e padrões disponíveis que podem nos ajudar a escrever código melhor e mais sustentável.
Nem tudo são rosas 😄, existem os prós e contras dessas abordagens e cuidados que devemos ter, não vou entrar muito afundo, mas apenas citar dois:
Gerenciamento de Especificações: Em sistemas grandes, pode haver muitas especificações diferentes. Gerenciar todas essas especificações e garantir que elas estejam corretas pode ser desafiador.
Custo de Abstração: Cada especificação é uma classe separada. Isso pode resultar em um grande número de classes, especialmente se você tiver muitas regras diferentes. Embora a organização seja importante, muitas classes podem ser difíceis de gerenciar.
Fique atento, é preciso saber utilizar com sabedoria cada solução. Rapidamente vamos as diferenças entre o Strategy e o Specification:
O Strategy Pattern é útil quando você tem vários algoritmos que podem ser usados intercambiavelmente.
O Specification Pattern é útil quando você precisa representar regras de negócios complexas de uma forma reutilizável.
Não se esqueça da Coesão!
A coesão é um princípio fundamental da engenharia de software que se refere à ideia de que uma unidade de código (por exemplo, uma classe) deve ter uma única, bem definida e focada responsabilidade.
Quando uma classe é coesa, todos os seus métodos e atributos estão diretamente relacionados à sua responsabilidade. Cada método deve contribuir para cumprir essa responsabilidade, e a classe não deve fazer nada que não seja diretamente relacionado à seus deveres.
Vamos considerar um exemplo. Digamos que temos uma classe "Carro". Uma classe Carro coesa poderia ter métodos como "Ligar", "Desligar", "Acelerar" e "Frear". Cada um desses métodos está diretamente relacionado à responsabilidade da classe Carro, que é representar e controlar um carro.
No entanto, se a classe Carro começasse a ter métodos como "SalvarNoBancoDeDados", "EnviarEmailDeConfirmação", ou "CalcularImposto", ela estaria se tornando menos coesa. Esses métodos não estão diretamente relacionados à responsabilidade de representar e controlar um carro, e deveriam estar em outras classes.
A detecção de classes que não estão coesas pode ser um pouco interpretativa, mas geralmente se você perceber que uma classe está fazendo muitas coisas diferentes, ou que alguns de seus métodos não parecem estar diretamente relacionados à sua principal responsabilidade, então é provável que a classe não esteja coesa.
Alguns sinais da ausencia da coesão:
Muitos campos ou propriedades: Se uma classe tem muitos campos ou propriedades, pode ser um sinal de que está fazendo muito. Por exemplo, uma classe
Ordercom campos para detalhes do pedido, informações do cliente e detalhes de pagamento pode ser dividida em várias classes menores, comoOrder,CustomerePayment.Métodos grandes: Métodos longos e complexos podem indicar falta de coesão. Muitas vezes, é possível dividir esses métodos em sub-rotinas menores, que podem ser movidas para suas próprias classes.
Alterações frequentes: Se você frequentemente precisa alterar uma classe devido a mudanças nos requisitos de negócio, pode ser um sinal de que essa classe tem muitas responsabilidades. Em vez de modificar uma classe grande e complexa, pode ser mais fácil e seguro alterar uma classe menor e mais coesa.
Dificuldade nos testes: Se é difícil escrever testes unitários para uma classe, pode ser um sintoma de falta de coesão entre outros problemas. Classes coesas geralmente são mais fáceis de testar, pois têm uma única responsabilidade e menores dependências.
Muitas dependências: Se uma classe depende de muitas outras classes para funcionar corretamente, é provável que ela esteja fazendo muito.
Nomes de métodos pouco relacionados: Se os métodos em uma classe parecem não ter relação entre si, pode ser um indicativo de que a classe está fazendo muitas coisas. Por exemplo, em uma classe
User, métodos comoLogin(),Logout(),Register()são coerentes e mostram um alto grau de coesão. No entanto, se a mesma classe também tiver métodos comoSendEmail(),CalculateTax(), CreateToken(), então, isso poderia indicar uma falta de coesão.Baixa coesão entre métodos e atributos: Em uma classe coesa, cada método usará um ou mais atributos da classe. Se uma classe contém métodos que não usam nenhum dos atributos da classe, isso poderia sugerir que a classe tem muitas responsabilidades e que tal método pode pertencer a outra classe.
Grande quantidade de código condicional: Se a classe/método tem muitas estruturas condicionais
if,else ifouswitch, pode ser um indício de que ela está fazendo muitas coisas. Refatorar o código para separar essas condições em classes diferentes pode melhorar a coesão.
Estas são apenas algumas dicas. A detecção de classes não coesas pode exigir prática e experiência. No entanto, ao se concentrar na manutenção da coesão, podemos melhorar significativamente a qualidade e a manutenibilidade do seu código.
A Intersecção Entre Testabilidade e Manutenibilidade
Programadores frequentemente se encontram em uma situação onde eles precisam modificar o código para corrigir um defeito, melhorar o desempenho ou adicionar um novo recurso. Sem testes adequados, esta é uma tarefa arriscada - podemos sem querer introduzir bugs no sistema.
Aqui reside a importância dos testes automatizados. Testes fornecem uma rede de segurança para os desenvolvedores. Se os testes foram bem escritos e cobrem uma grande parte de casos, os desenvolvedores podem fazer mudanças no código com confiança. Se eles quebrarem alguma coisa, os testes irão falhar, alertando-os do problema.
No entanto, para que os testes sejam úteis, eles devem ser mantidos em sincronia com o código que estão testando. Isso significa que, quando o código muda, os testes também podem precisar mudar. Portanto, é aí que entra a manutenibilidade. Se o código é fácil de manter, os testes também serão.
Além disso, se o código foi escrito com a testabilidade em mente, será mais fácil escrever testes para ele. E se tivermos testes para o código, será mais fácil mantê-lo. Mas fique alerta! Os testes precisam também respeitar princípios e boas práticas para que possam ser uma ferramenta auxiliar útil e abrangente. Escreva e dê valor aos testes!
Portanto, podemos ver que a testabilidade e a manutenibilidade não são apenas relacionadas, elas são mutuamente reforçadas. Um código que é fácil de testar é mais fácil de manter, e um código que é fácil de manter é mais fácil de testar.
Faça as perguntas certas!
Podemos fazer uma reflexão e analisar se o que estamos escrevendo e criando realmente faz sentido, e se principalmente é fácil de manter. Algumas perguntas podem ajudar:
Propósito e responsabilidades: Esta classe ou função que estou prestes a criar, tem um propósito claramente definido? Ela tem uma única responsabilidade ou está tentando fazer muitas coisas ao mesmo tempo?
Legibilidade: O código que estou escrevendo é claro e fácil de ler? Uma pessoa que nunca viu esse código antes poderia entender rapidamente o que ele faz?
Testes de Unidade: Como vou escrever testes de unidade para esse código? As funções são pequenas e independentes o suficiente para serem testadas isoladamente?
Dependências: O que este código depende para funcionar corretamente? As dependências estão claramente definidas e são facilmente substituíveis para facilitar os testes?
Futuro: Se tiver que modificar esse código no futuro, será fácil fazê-lo? Ou estou criando emaranhados complexos que serão difíceis de desvendar?
Refatoração: Este código é facilmente refatorável? Estou escrevendo o código de maneira que seja fácil fazer pequenas melhorias incrementais no futuro?
Conclusão
Em conclusão, a manutenibilidade de um software é uma propriedade crucial que, frequentemente, determina a longevidade e o sucesso de um projeto. Códigos fáceis de manter não só melhoram a qualidade e eficiência do software, mas também reduzem o custo total de propriedade ao longo do tempo.
A testabilidade, clareza, a coesão e o baixo acoplamento são atributos intrínsecos de um código fácil de manter. Testes unitários bem escritos melhoram a testabilidade e tornam a manutenção mais segura ao prevenir regressões. A coesão assegura que cada classe ou módulo do código tem uma única responsabilidade, tornando-o mais compreensível e fácil de modificar. O baixo acoplamento permite que os componentes de software sejam modificados ou substituídos de forma independente, promovendo a reutilização de código e a extensibilidade.
No entanto, alcançar esses atributos requer uma conscientização constante e uma disciplina rigorosa durante o processo de desenvolvimento. Requer a prática de bons princípios de design de software, como a injeção de dependência, a segregação de interface e o princípio da responsabilidade única. Além disso, precisamos constantemente refletir e questionar suas escolhas de design e implementação, se perguntando: "Isso torna o código mais fácil de testar? Isso torna o código mais fácil de entender? Isso torna o código mais fácil de modificar?".
Por fim, é importante lembrar que, embora a manutenibilidade seja importante, ela não é o único fator que determina a qualidade do software. Outros aspectos, como desempenho, segurança e usabilidade, também são fundamentais. Portanto, como em muitos aspectos do desenvolvimento de software, a manutenibilidade deve ser considerada em equilíbrio com esses outros fatores.
Inversão de Controle (IoC) é um princípio de design de software que se refere a delegar a responsabilidade da criação e gerenciamento de dependências para um "contêiner" externo, em vez de permitir que as classes gerenciem suas próprias dependências.
Na DI, o "contêiner" externo que é responsável por criar e gerenciar as dependências é geralmente um quadro de IoC ou um contêiner de IoC. Frameworks comuns incluem Spring no Java, ASP.NET Core em .NET, entre outros. Esses frameworks podem analisar o código, determinar quais classes dependem de quais outras classes, criar instâncias dessas classes na ordem correta e injetar essas instâncias onde necessário.
A Inversão de Controle é chamada assim porque inverte o fluxo de controle tradicional dentro de um programa. Em um programa sem IoC, a classe principal controla a criação e gerenciamento de todas as suas dependências. Isso significa que a classe principal tem um controle firme sobre o fluxo do programa. Com IoC, esse controle é invertido: o contêiner IoC é quem dita o fluxo de controle, controlando a criação de dependências e injetando-as onde necessário.