
Event-Driven Architecture: The Parts You Need to Know!
With the evolution of distributed systems and the growing need for flexibility and scalability, Event-Driven Architecture (EDA) emerges as a powerful approach. Instead of relying on direct and immediate interactions between services, EDA allows them to operate independently, reacting to events as they occur in the system. But what makes this architecture so effective? What are the components that enable systems to flow in an organized manner, even in complex and dynamic scenarios? Let’s explore how EDA is redefining the way systems communicate, while maintaining the autonomy and resilience that modern businesses seek.
Why is it called Event-Driven Architecture?
It's because events are the central focus. But what are events? They are facts that indicate something important has occurred in the system. It could be a user interaction with the system, like completing a purchase, or a technical operation, such as an IoT sensor detecting a temperature change.
Events indicate that something significant has happened in the system. Generally, they represent a change in state, but they can also involve other important occurrences that need to be communicated to interested services. However, they do not force a response. Each service that consumes the event decides whether to react, how to react, or even to ignore it. When an event is emitted, it simply informs that something has happened, leaving it up to other services to decide what to do with that information.
In other words, the event creates an opportunity for action, but it doesn't impose one.

What makes this different from other architectures?
In many traditional architectures, such as the request-response model, a service needs to directly call another service and wait for an immediate response to continue its processing. This creates a direct dependency relationship between services, leading to temporal coupling. In other words, services are tied to each other: if one fails, the other might fail as well. This direct interdependence can limit the scalability and flexibility of the system, especially in distributed environments.
In EDA, however, the scenario is quite different. When an event occurs, the service that generated the event simply emits the event itself and continues its course. It doesn’t need to worry about:
Who will consume the event.
How other services will process it.
When the event will be processed.
This intentional disconnect between services is called decoupling.

Where did the concept of Event-Driven Architecture come from?
The concept of Event-Driven Architecture didn’t emerge overnight — it is the result of an evolution that dates back to the early attempts to create asynchronous and distributed systems, long before the era of cloud computing and microservices. To understand where this approach comes from, we need to look back and examine how the communication needs between systems have evolved over the past few decades.
Roots in Asynchronous Architectures and Messaging Systems
In the 1960s and 1970s, when computers began to communicate with each other, synchronous communication — where one system makes a request and waits for an immediate response — was the standard approach. However, as systems became more distributed and networks expanded, this approach started to show its limitations. Slow or unstable networks could interrupt communication, making systems fragile and difficult to scale.
That’s when the first experiments with asynchronous architectures began to appear. The idea was to allow systems to exchange messages without having to wait for an immediate response, creating a message queue between them. This concept of asynchronous message exchange served as the foundation for what would later be called event-driven architecture.
In the 1980s, companies like IBM began working on enterprise messaging solutions that implemented these ideas. IBM MQ (Message Queue), launched in 1993, was one of the first tools that made it possible to exchange messages between systems in a reliable and asynchronous way, using message queues. It quickly became a standard in the market for enterprise systems that required high reliability and resilience. These queues ensured that messages (or events) could be stored and reprocessed in case of failure.
Adoption of Messaging Standards like JMS
In the 1990s, technology continued to evolve. Sun Microsystems released the Java Message Service (JMS) in 1998, which became one of the most widely adopted standards for asynchronous messaging. JMS allowed different systems to reliably exchange messages without the sending systems needing to know what the receiving systems did with those messages. This was an early step towards decoupling system components, one of the key pillars of event-driven architecture.
These advancements provided solutions to common distributed system problems such as message loss, processing bottlenecks, and the need for horizontal scalability. This paved the way for event-driven orientation to become an essential part of modern architectures in the decades that followed.
The Microservices Revolution and Cloud Computing
Despite these advances, the concept of event-driven architecture gained even more traction with the rise of microservices architectures in the early 2010s and the explosive growth of cloud computing.
Companies like Netflix, Amazon, and Google began adopting microservices-based architectures to handle their large-scale operations. As a result, the need for asynchronous and decoupled communication between independent services increased even more. These tech giants realized that synchronous communication (such as direct REST API calls) was not viable for global systems that needed to operate with high scalability, resilience, and availability. Event-driven architecture emerged as a natural solution for this scenario.
Events Everywhere
To understand the usefulness of EDA, imagine a familiar scenario: you're sleeping, and suddenly, your alarm clock rings. That sound is an event — a signal that something has happened. However, the ringing itself doesn’t force any action. You have the freedom to decide how to react: you can choose to wake up immediately, stay in bed for a few more minutes, or even ignore the alarm completely. This event creates the opportunity for a series of actions — like getting up, going to the bathroom, or making coffee — but the choice of how to proceed is yours.
So, after this brief analogy, it becomes easier to understand that when a customer places an order in an online store, the "order placed" event is generated. This event, by itself, simply informs that the order has been made and can trigger various actions: the payment service processes the purchase, the inventory checks availability, and the customer receives a notification. Each service reacts to the event independently, without directly relying on the others, making the system more flexible.
It’s as if each part of the system were a specialized professional who only acts when something related to their expertise happens.
Moreover, events can generate new events. For example, after the payment is approved, the logistics service may be triggered to ship the product. This creates a continuous flow of events, where services work in a decoupled manner, reacting only to the events that are relevant to them.
Events are First-Class Citizens in EDA
In software engineering, the concept of a "first-class citizen" refers to something that is considered central and essential within a system. A "first-class citizen" has the same privileges and importance as any other critical entity in the system. It is treated with priority, meaning that it has a clear and decisive role, without being secondary or disposable.
Events, in an event-driven architecture, are the main sources of information that drive the system’s behavior. They are not just occasional "triggers" — they are the core of everything. As I mentioned in the alarm clock example, the sound of the alarm might seem like a small thing, but it is what initiates, what gives the kick-start for others to react.
This approach gives events first-class status because the entire system's functionality depends on how services react to these events. Without the event, there would be no communication, no reaction, and therefore, the system would stagnate. When an event is emitted, it carries important information — we’ll talk more about this soon.
Furthermore, events are explicit. This means that when an event is emitted, all services that need that information can process it. This gives clarity and consistency to the system. Each service knows exactly which event to listen to and what to do with it. This kind of approach places events at the center of the system’s design, making them first-class citizens because they are non-negotiable for the proper functioning of the architecture.
Types of Decoupling in an Event-Driven Architecture
Consider the following situation: you're at work and need to send an email to a colleague asking for information. You send the email and continue with your tasks without waiting for the response. Your colleague might reply right away or in a few hours, but that doesn’t stop you from carrying on with your day. This scenario perfectly illustrates the concept of temporal decoupling.
When we apply this concept to software engineering, that’s exactly what happens. A service can "emit" an event and move on without relying on an immediate response from another service. For example, imagine an e-commerce system registers an order. The "order placed" event is emitted, but the payment or inventory service doesn’t need to process it at the exact moment it’s triggered. They can handle the event when they’re ready. There’s no temporal pressure typical of synchronous calls, where one service has to wait for another to finish before continuing.

Now, beyond time, let's think about responsibility. When a service emits an event, it doesn’t need to worry about who will consume it or how it will be handled. It only needs to ensure that the event is emitted clearly. Let’s take the same e-commerce example: the order service simply emits the "order placed" event. It doesn’t need to know if the inventory service will update the product quantities or if the logistics service will start preparing the shipment. Whoever is interested in that event will act according to what makes sense for their function. This is what we call functional decoupling. Each service does its job without depending on knowing what the others are doing.
Additionally, there's something I like to call domain decoupling. This brings a lot of flexibility. This is important because, if tomorrow you decide to add a new service — for example, an analytics service to monitor customer behavior — you don’t need to modify the order service for it to start sending events to the new service. You can delegate this responsibility to someone centralizing these events and making them available, so the new service just starts consuming the events.
This type of decoupling makes the architecture much more flexible and adaptable. You can evolve the system, add new services, or change the way events are processed without needing to restructure everything. It’s like building a Lego toy where the pieces can be swapped or repositioned.
Data Decoupling
In addition to the types of decoupling we’ve already discussed — temporal, functional, and domain — there’s another type that is gaining a lot of relevance in modern system development: data decoupling.
To understand this, imagine how older or monolithic systems work. Typically, all services or functionalities share the same database. This means that any data changes in one area can directly affect various other parts of the system. Furthermore, any issues with this shared database can impact the entire system.

In microservices architectures, services should be independent in terms of data. But we know that this doesn't always happen!
In an event-driven architecture, the scenario is different. Instead of making synchronous calls to query another service or sharing the same data schemas, a service simply listens to the events it needs. These events carry the relevant data so that each service updates its own database, without relying on a live query to another service's database.
This means that, instead of depending on a real-time query to another service's database, each service maintains its own copy of the necessary data, provided by the events. This allows services to remain independent, scalable, and less prone to failures.
In an EDA, the Order Service emits an "Order Placed" event, containing all the information about the order (such as the items and quantities purchased). The Inventory Service listens to this event and uses that information to update its own database, reducing the available quantity of products. Similarly, the Logistics Service can listen to the same event to start the shipping process.

Advantages of Data Decoupling in EDA
Elimination of Direct Dependencies: Services don’t need to make synchronous calls to each other to get data. Instead, they listen to relevant events, ensuring that each service is self-sufficient in terms of data.
High Resilience: If a service is temporarily offline, the event can still be processed later, ensuring that the service does not go down due to reliance on another service that is offline.
Better Scalability: Since services don’t rely on a central database or direct queries to other databases, they can be scaled independently without creating bottlenecks in synchronous calls.
Asynchronous Synchronization: Communication between services is done asynchronously, via events, allowing each service to process information at its own pace.
Reduction of Single Points of Failure: Without a shared database or reliance on direct queries between services, each service can fail or be updated independently, without compromising the functioning of the rest of the system.
While data decoupling offers several advantages, it also presents the challenge of eventual consistency. As services process events asynchronously, data between services may be temporarily misaligned until all events are processed.
Therefore, system architects need to consider:
How to ensure that events are delivered and processed reliably.
Strategies to handle errors or failures in event delivery.
Consistency guarantees — knowing when it’s acceptable to work with eventual consistency and when immediate consistency is required.
But where do the events go?
And the question that arises is: who makes this bridge? Who is responsible for ensuring that the event goes from the producer to the right services?
The answer lies in brokers or event buses. They are literally the bridge that connects the one who emits the event to those who need to listen to it.

In EDA, the broker plays the role of a distribution center. The event provider (like the ordering service in an e-commerce) does not need to worry about who will receive the event, when they will receive it, or how the event will be processed. All they do is leave the event in the hands of the broker, but let's understand this better with an analogy.
How does the broker achieve this decoupling?
To better understand how the broker contributes to decoupling in distributed systems, we can think of a common everyday situation: imagine you work in an office where the manager posts a memo on the bulletin board. Here, the manager is the event producer, the bulletin board represents the broker, and the memo is the event. The employees, who are the consumers, can read the memo when they have time.
The manager doesn’t need to know who will read it or when. He simply posts the information on the bulletin board, and the employees access the memo at their convenience. The memo remains accessible to all interested employees, without any need for intervention or control from the manager.
This is the essence of how the broker works in an event-driven architecture: the producer simply publishes the event, and the consumers process it when it is most suitable for them, ensuring decoupling and flexibility in the system. Multiple services may be interested in the same event, and the broker efficiently facilitates this distribution.
Why is this so important? Because by decoupling the services, we ensure that the system is more robust and can scale more easily. This approach not only decouples the services but also enhances the system's resilience and scalability, as each service can process events independently, at its own pace, without relying on direct queries to others.

This decoupling is essential in event-driven architectures, because the provider service does not need to understand how the message will be delivered or processed. The manager does not monitor each employee to ensure that it is read, the broker does not need to control what consumers do with the events, nor does it need to directly notify each one. Each consumer service is free to process (consume) the messages according to its own business logic.
Who can be the broker?
Now that we understand the crucial role of the broker in ensuring decoupling between services, the next question is: who or what can be this broker? In an event-driven architecture, the broker can be a specialized tool that manages asynchronous communication between event producers and consumers.
There are several widely-used solutions that can play the role of the broker. Here are a few examples:
RabbitMQ: One of the most popular message brokers that uses the AMQP protocol. RabbitMQ is known for its robustness, ability to efficiently route messages, and ensure that events are delivered correctly, even in case of failures.
Apache Kafka: Commonly used in high-scale systems that need to handle large volumes of real-time events. Kafka allows for the storage of events for an extended period, enabling consumers to "re-read" past events when necessary.
Amazon EventBridge: An AWS service that simplifies building event-driven architectures in the cloud. EventBridge allows integration between various services, both within AWS and third-party, with an advanced routing system.
Google Cloud Pub/Sub: The message broker from Google Cloud. It enables asynchronous and scalable communication between different services, supporting large event volumes with high reliability.
These brokers offer powerful tools to ensure that events reach their destinations, guaranteeing the scalability, flexibility, and decoupling that are central features of an event-driven architecture.
Where does the Broker send the events?
Once the broker receives an event, the next logical question is: where does it send these events?

The consumer services are those that are listening to or subscribing to certain events that the broker makes available. These consumers are interested in reacting to specific types of events. For example, in an e-commerce system, the payment service might be interested in the "Order Placed" event, while the inventory service would be interested in the same event to update the available product quantities.
The broker doesn’t actively send the events directly to consumer services. Instead, it organizes and makes the events available in appropriate channels, queues, or topics. The consumer services, in turn, monitor these channels and fetch the events when they are ready to process them, according to their needs and processing capacity. Depending on how the system is set up, the broker can:
Post the event to a queue: Each consumer accesses this queue to fetch the events at the appropriate time. This ensures that events are processed in order, one at a time, and each event is consumed by only one service.
Distribute the event via a topic: Multiple services can listen to the same event and process it simultaneously. In this case, each consumer service, such as the inventory or payment service, processes the event according to its responsibilities and business logic.
In the case of Amazon EventBridge, the broker can also configure targets, which are the consumers responsible for processing the events. These targets can be services such as AWS Lambda, SQS, SNS, or even external APIs via API Destinations.
It’s important to note that, even when EventBridge "triggers" the targets, this doesn’t characterize synchronous communication. The broker doesn’t wait for an immediate response from the consumer services. It simply sends the event to the target, and the target processes the event independently, maintaining asynchronous and decoupled communication. This ensures that services can operate without rigid dependencies between each other, which is crucial for the system's scalability and resilience.
Additionally, EventBridge allows the use of predefined rules to filter and route events efficiently. This ensures that each event is made available only to the consumers that need it, and in the appropriate format. In this way, services can fetch and process the relevant events at the right time, according to their own business logic.
This approach of queues, topics, and targets enables consumer services to be more flexible, processing events asynchronously and according to their own capacity, ensuring the system's scalability and resilience without introducing unwanted coupling.
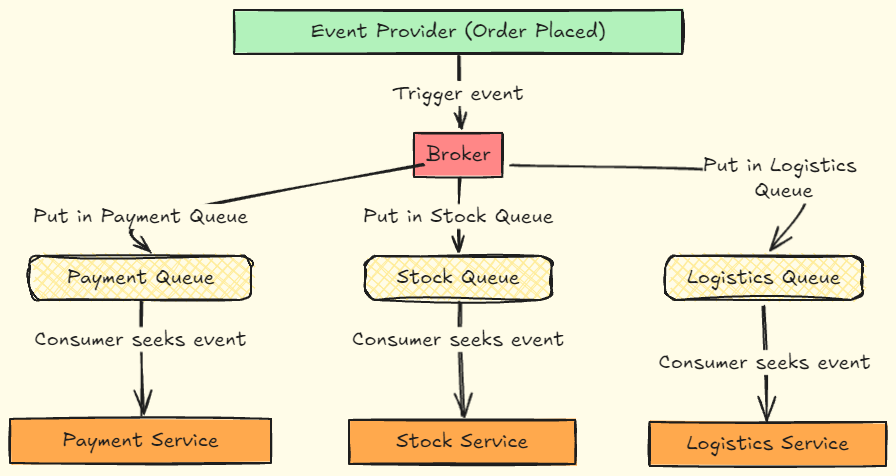
Why Queues?
Queues are a fundamental piece in many event-driven architectures because they solve several common problems in distributed systems, such as:
Temporal decoupling: Consumers are not always able to process events immediately. With a queue, the broker holds the events until the consumer service is ready to consume them, without impacting the system as a whole.
Load balancing: Imagine a consumer service needs to process thousands of events in a short period, such as during a Black Friday sale. By using a queue, the broker ensures that the service can consume the events according to its capacity, preventing overloads and failures.
Delivery guarantee: In critical systems, such as financial ones, it is vital that events are not lost. Using queues, the broker can ensure that each event is delivered and processed once, even if the consumer service is temporarily unavailable.
When the broker posts events to a queue, each consumer can connect to that queue and fetch events when ready. A common approach is the use of dedicated queues, where each consumer service has its own queue. The event is copied or distributed to multiple queues, and each service consumes it independently.
What if I choose RabbitMQ or Kafka as a broker?
When we talk about RabbitMQ and Apache Kafka, we are dealing with two extremely powerful tools for event-driven architectures. Both serve as brokers, but they do so in different ways. The beauty of these platforms is that, instead of communicating directly with a consumer service, you can opt to route the events to a queue or topic.
So, how does this work? Let’s take a closer look.
RabbitMQ: Queue as the Main Mechanism
If you opt for RabbitMQ, the core idea revolves around the use of queues. Think of Rabbit as a messaging hub, where events are routed to queues, and the consumer services fetch these events as they become available. The logic is simple: the event producer (like an order service, for instance) emits an event — say, "order placed" — and this event is directed to an exchange within RabbitMQ.
Now, the exchange acts like a router that decides where this event will go. Depending on the rules you configure, the event can be sent to one or more queues. And who’s waiting on the other side? The consumer services, which are connected to these queues, ready to grab the events when they are prepared to process them.
This means that the consumer doesn’t receive the event immediately but only when it goes to the queue and fetches the message. And here’s the interesting part: you have full control over how this happens. You can configure dedicated queues for a single service or share a queue among multiple consumers, balancing the load between them.
So, instead of direct communication, you're posting events to queues, and services consume them at their own pace. It’s like each service is a person picking up a package when they have time to open it.
Kafka: Topics as the Main Mechanism
Now, if you choose Kafka, the dynamic changes a bit, but the logic still revolves around decoupling. Instead of queues, Kafka works with topics. Imagine a topic as a large "logbook" where events are added, and consumers can "read" these logs as they arrive or even revisit older events.
In Kafka, when the event producer publishes an event like "order placed," it is placed into a specific topic, like "order_placed." What’s interesting is that consumers subscribe to these topics and can listen to the events as they arrive. And just like in RabbitMQ, consumers don’t receive events directly but rather when they’re ready to process them.
The advantage of Kafka is that it stores events for a period of time, or even indefinitely, depending on how you configure it. This means that if a consumer wants to "re-read" an event or process events in batches, they can do so without issues. This is super useful for those who need to audit or analyze events later.
And if you need more scalability? No problem! Kafka also offers partitioning, which means you can divide a topic into several parts, and different consumers can process those parts in parallel, improving system performance.
Now, let’s explore a situation where a direct and specific action is required, leading to the creation of a command.
Commands
Two fundamental concepts need to be made clear here: commands and events. While both are forms of communication between services, they have very distinct purposes and behaviors.
You already know what an event is. Now, imagine another situation: after reading (consuming) the memo on the bulletin board, you decide to go to John's office and ask him personally: "John, confirm if the restaurant reservation has been made." Here, you’re giving a direct order to John, expecting him to take an action in response (confirm the reservation). This is a command — a clear and specific instruction with an expectation of execution.
Similarly, in event-driven systems, a command, unlike an event that informs something has happened and allows services to react at their convenience, requests an immediate action and is directed to a specific service, expecting it to act according to the instruction.
For example, in an e-commerce system:
The order service may generate an "Order Placed" event, and when this fact is made available by the broker, other interested services can consume it.
However, the payment service, while processing this order, may need to send a command to the billing service, saying: "Charge this order." In this case, the command is a direct order that clearly specifies who must act and what action must be taken, leaving no room for ambiguity.
When to Use a Command in EDA?
The use of commands is essential when you need to ensure that an action is performed. In an event-driven architecture, where communication tends to be asynchronous and flexible, commands can complement events to ensure that specific tasks are executed at the right time and by the correct part of the system.
Instead of waiting for a service to passively react to an event, a command imposes direct responsibility on the receiving service. This is especially useful in cases where the action that needs to be performed is critical to the workflow, such as processing a payment or completing a transaction.
The real strength of understanding and using commands correctly lies in control. Using only events creates a decoupled system, but also a less directed one. Events are open "announcements," while commands are clear directives.
For example, if you need to ensure that a payment is processed before an order is shipped, a command would be the right choice. It orders the payment to be executed, ensuring that this service has no option to ignore or process the order without completing this critical step.
Thus, the command serves to fill in the gaps where the autonomy of services cannot compromise the consistency or completion of a specific task. It brings a layer of certainty within an event-driven architecture, where flexibility can sometimes mean not all parts of the system react as expected.
So, to summarize:
Direction: The command has a clear recipient. It is sent directly to a specific service that has the responsibility to process it and execute the requested action.
Intention: The command orders something to be done. The service that receives it must explicitly perform this action.
Example: A purchasing service sends a command to the payment service saying: "Process the payment for this order."
But now, let's dive into another question: how are events transported between services? The answer lies in the protocols that facilitate this exchange of information. Depending on the system’s context, the volume of events, and the needs for scalability and delivery guarantees, different communication protocols can be adopted.
Protocols in an Event-Driven Architecture
When we talk about event-driven architectures, one of the questions that always comes up is: which protocol is most commonly used in practice? After all, with so many options available — HTTP, AMQP, WebSockets, Kafka (which uses a binary protocol over TCP), MQTT, gRPC — it can seem complicated to choose the right path.
But in reality, the answer is directly related to the type of system you’re building, the volume of events you need to process, and the level of reliability you want to ensure. Still, some protocols are more common in event-driven architectures because of their flexibility and robustness.
HTTP: A Simple and Widely Used Solution
If we think of the simplest and most widely used solution, without a doubt, HTTP is one of the most common protocols. And this has a lot to do with its ease of implementation and the fact that almost every system supports HTTP.
The Hypertext Transfer Protocol is particularly practical when you’re just starting to implement an event-driven architecture or when the services are relatively simple and the event volume is low. For example, imagine an online payment system that emits a "payment approved" event via Webhook (which is just an HTTP request). The notification service can listen to this event and send a confirmation email to the customer.
This use of HTTP, especially with Webhooks, is very common because it works well in many cases and is easy to integrate with external services like SaaS. Companies that offer payment, CRM, or marketing automation services, for example, often provide events via Webhooks. This makes HTTP a practical solution for notifying other services when something important happens.
However, it’s important to remember that Hypertext Transfer Protocol has its limitations. If your system needs to process large volumes of events or you need a delivery guarantee, HTTP might not be the best choice because it wasn’t designed for persistence or high scalability.
When to Choose HTTP and When to Opt for Something More Robust like AMQP or Kafka?
This decision depends largely on what you expect from the system:
If the focus is on simplicity, quick integration, and you don’t need to process millions of events per second, HTTP (with Webhooks) is a great choice. It’s straightforward, and it’s easy to find support for it in almost any programming language or web service.
If you need robustness and reliability, where critical events can’t be lost, AMQP is the safer solution. Companies handling critical transactions or needing to guarantee single processing of each event tend to prefer this protocol.
Now, if you’re in a high-scale scenario, with massive volumes of events being processed in real time, Apache Kafka is, in practice, the most frequent choice. It allows huge amounts of data to flow continuously through the system without overloading services or creating bottlenecks.
And What About WebSockets and MQTT?
While WebSocket is more common in real-time applications, such as chats or online games, it is not as widely used in corporate event-driven architectures. This is because it requires a continuous connection, which can be hard to scale when talking about millions of events or complex systems. MQTT, on the other hand, is very popular in IoT (Internet of Things), where you have small devices that need to send events to a central server in a lightweight and efficient manner.
Now that we’ve talked about protocols, let’s discuss the structure of the message.
Anatomy of a Message
You might be wondering: how should this message be structured? After all, if the event is what happened (like a sale made or a payment processed), the message is the medium through which this event is communicated to other parts of the system.
In the context of distributed systems, it is crucial that the message is clear and complete, because it is what travels between services, passing through the broker and reaching the consumers that need to react to the event. Every detail of the message is important, and its structure needs to be well thought out to ensure that the system works effectively and remains decoupled.
The Difference Between the Event and the Message
First and foremost, as I mentioned in the article
The Untold Secrets of Asynchronous Communication in Microservices

In this article, we will discuss some of the challenges that arise when dealing with asynchronous communication in distributed architectures. We’ll explore where things can go wrong — from the improper use of queues to how they can harbor silent failures. Our goal is to shed light on common pitfalls and how to avoid them.
It’s important to understand that the event and the message are not the same thing, although they are closely related. The event is what happened, a fact of a significant occurrence. The message, however, is the medium by which you communicate this event to other parts. In short, the message contains the details of that event (such as order ID, item list, customer information) and is relayed by the broker to the interested services that are subscribed to process this type of event.
Now, the question is: how should this message be structured so that all services can understand it, process it, and act on it?
Let’s imagine the message as a package traveling from the event producer to the consumers, through the broker. This package needs to contain all the necessary information so that the consumer services can make a decision. It needs to be clear, flexible enough to accommodate different types of events, and at the same time, standardized so that all consumers understand its structure.
Event Envelope
A widely adopted practice in event-driven architecture is encapsulating the event within a structure called the Event Envelope. This envelope serves as an outer layer that wraps all the elements we discussed (type, ID, timestamp, source, data). It ensures standardized organization and facilitates event interpretation by any consumer service.
The idea of the Event Envelope is to ensure that the message is self-explanatory and contains all the essential elements, so any service that consumes the event knows how to process it. Here is a basic structure below.
Type of Event
This field is essential. The eventType informs the consumer what happened. Imagine the message is like a letter, and the eventType is the title of that letter. It clearly indicates what event was triggered.
For example, if the event is about a sale made, the eventType could be something like "OrderPlaced". If it’s about a payment, it could be "PaymentProcessed". This field ensures that consumers can quickly identify the type of event and, based on that, decide whether or not to process it.
{
"eventType": "OrderPlaced",
...
}Unique Event Identifier
The eventId is a unique identifier, like an ID for the event. It serves to track the event within the system. This is especially important in scenarios where you need to ensure that the event is processed only once. Additionally, in cases of errors or failures, the eventId helps to identify if an event has already been processed or if it is being processed again.
{
"eventType": "OrderPlaced",
"eventId": "123456-abc-789",
...
}With this field, each event has its own "fingerprint", which makes it easier to track throughout the message lifecycle.
Timestamp
In distributed systems, time is a critical factor. The timestamp indicates when the event occurred. This field helps consumers organize the processing of events and make time-based decisions.
For example, if a consumer service receives events in batches, it can process the events in the order in which they occurred, based on this timestamp. In addition, the field is useful for auditing and for resolving potential data conflict issues.
{
"eventType": "OrderPlaced",
"eventId": "123456-abc-789",
"timestamp": "2024-09-03T12:30:00Z",
...
}
Source
The source describes where the event came from. This is particularly useful when you have a system with multiple event producers. Imagine a scenario where different services can emit events of the type "OrderPlaced". With the source field, you can identify which service triggered the event, making it easier to track and organize the data.
{
"eventType": "OrderPlaced",
"eventId": "123456-abc-789",
"timestamp": "2024-09-03T12:30:00Z",
"source": "OrderService",
...
}Event Data
Here is the heart of the message. The data field contains the specific details of the event. If the event is about an order placed, for example, this field might contain the order number, purchased items, quantity, total amount, and other relevant information. The data is what truly matters to the consumers, as the information contained here will determine the actions each service will take.
An example for an "order placed" event might be:
{
"eventType": "OrderPlaced",
"eventId": "123456-abc-789",
"timestamp": "2024-09-03T12:30:00Z",
"source": "OrderService",
"data": {
"orderId": "12345",
"userId": "67890",
"items": [
{ "productId": "A1", "quantity": 2, "price": 30.00 },
{ "productId": "B2", "quantity": 1, "price": 90.00 }
],
"totalAmount": 150.00
}
}This field carries all the detailed information that each consuming service needs to act accordingly. The payment service, for example, will look at the totalAmount, while the inventory service will focus on the items to adjust the available quantities.
There are some variations and different approaches to structuring a message, depending on the system context, the tools, and even the preferences of the software architects.
Enriched Metadata Structure
In addition to basic fields like eventType, eventId, timestamp, and data, some systems prefer to enrich their messages with additional metadata. This metadata can include contextual information that helps consumer services interpret the event more efficiently, without the need for additional queries.
For example, in an 'order placed' event, beyond the order data, the message might contain information such as the customer's IP address, geographic location, or even prioritization tags. This allows consumer services to have a broader view of what happened without needing to retrieve this data from elsewhere.
An example with metadata could look like this:
{
"eventType": "OrderPlaced",
"eventId": "123456-abc-789",
"timestamp": "2024-09-03T12:30:00Z",
"source": "OrderService",
"metadata": {
"ipAddress": "192.168.1.1",
"location": "São Paulo, BR",
"priority": "high"
},
"data": {
"orderId": "12345",
"userId": "67890",
"items": [
{ "productId": "A1", "quantity": 2, "price": 30.00 },
{ "productId": "B2", "quantity": 1, "price": 90.00 }
],
"totalAmount": 150.00
}
}Structure with Separation of Event and Command
Another pattern you might encounter in some event-driven architectures is the separation between events and commands. While an event is a notification that something has happened, a command is an instruction that something needs to be done. This pattern is common in systems where the behavior of consumers is more proactive and not just reactive.
In practice, the difference between an event and a command can be subtle but important. The event informs that something has occurred, while the command indicates that something must be done. Some architects like to encapsulate these two ideas in different messages, with slightly distinct structures.
For example, an event message could look like this:
{
"eventType": "OrderShipped",
"eventId": "abcdef-123456",
"timestamp": "2024-09-04T09:15:00Z",
"source": "LogisticsService",
"data": {
"orderId": "12345",
"shippingProvider": "DHL",
"trackingNumber": "ABC123456"
}
}And a command message could have a similar structure, but with different semantics, requesting something to be done:
{
"commandType": "ProcessRefund",
"commandId": "xyz-789",
"timestamp": "2024-09-04T09:30:00Z",
"source": "CustomerService",
"data": {
"orderId": "12345",
"reason": "Product damaged",
"refundAmount": 150.00
}
}Here, the command indicates a specific action that needs to be performed — in this case, a refund — while the event simply communicates that something has already happened, such as an order being shipped.
CloudEvent-Focused Structure
Another anatomy that has been gaining a lot of popularity recently, especially in cloud-native systems, is the CloudEvent standard. This is an open-source standard that emerged to unify and standardize the structure of events in cloud computing environments. The goal of CloudEvent is to offer a consistent way to describe events across different platforms, such as AWS, Azure, or Google Cloud.
The structure of CloudEvent is quite similar to what we discussed earlier but follows a more rigid specification. It defines mandatory and optional fields that can be used to transport events between different services and messaging systems.
Here’s an example of a CloudEvent for an order placed:
{
"specversion": "1.0",
"type": "com.ecommerce.order.placed",
"source": "/order/service",
"id": "A234-1234-1234",
"time": "2024-09-03T12:30:00Z",
"datacontenttype": "application/json",
"data": {
"orderId": "12345",
"userId": "67890",
"items": [
{ "productId": "A1", "quantity": 2, "price": 30.00 },
{ "productId": "B2", "quantity": 1, "price": 90.00 }
],
"totalAmount": 150.00
}
}The fields of CloudEvent are more standardized and include:
specversion: The version of the CloudEvent specification.
type: The type of event (similar to eventType).
source: The origin of the event.
id: A unique identifier.
time: The time the event occurred.
datacontenttype: The type of data in the data field.
data: The content of the event.
The use of the CloudEvent standard is very common in environments where different cloud systems need to communicate with each other, facilitating interoperability and consistency in communication.
Now that we've discussed message structures, let's briefly talk about patterns.
Most Common Patterns in Event-Driven Architectures
In an event-driven architecture, the goal is to create a flexible. For this purpose, several patterns are used to organize the flow of communication between services. Let’s explore the most important ones:
Event Notification
Imagine a situation where you receive a message that says, "Something important happened." That's it. The notification doesn’t provide further details or require immediate action. This is called an event notification. The event is just a message indicating that something relevant occurred. Services can decide whether and how to react to this information.
Example: In an online store, when a customer places an order, the "Order Placed" event is emitted. From there, services like payment and inventory can act if necessary.
Event-Carried State Transfer
Now imagine that, in addition to saying something happened, the message includes all the details needed to act. That’s what happens here: the event not only notifies that something occurred but also carries important data about the state change.
Example: The "Order Placed" event can include information such as the customer’s name, the purchased products, and the total amount. This way, the services consuming this event have everything they need to do their job.
Event Sourcing
Have you ever thought of recording each state change of a system as a separate event? This is Event Sourcing. Instead of storing just the final state of an order, for example, you store all the events that led to it. If you need to go back to a previous state or understand how something changed over time, you can simply review the sequence of events.
Example: Each time an order changes status (received, paid, shipped), these events are recorded so the final state can be reconstructed at any time.
Publish/Subscribe
This pattern is quite common and easy to understand. Imagine you publish a message on a channel, and everyone interested subscribes to receive it. That’s Pub/Sub. The event producer publishes something, and all services that subscribed get notified and can react.
Example: In e-commerce, the order service publishes the "Order Placed" event, and the payment and inventory services, subscribed to that channel, consume the message and act accordingly.
Event-Driven Workflow
Instead of having a linear and rigid workflow, this pattern allows events to drive the sequence of actions in a system. An initial event can trigger other events, creating a decentralized workflow.
Example: The "Order Placed" event triggers "Payment Processed," which in turn triggers "Order Packaged," and so on, until the order is delivered.
Retry and Dead Letter Queues
In an ideal world, everything works perfectly on the first try. But in the real world, failures happen. This is where retry and dead letter queues come into play. When an event is not processed correctly, it can be retried. If the problem persists, the event is sent to a special queue called the Dead Letter Queue, where it can be analyzed and processed manually.
Example: If the payment service fails to process an "Order Placed" event due to a temporary error, the event will be retried. If it continues to fail, it goes to a Dead Letter Queue for further investigation.
Choreography
Here, each service acts independently, reacting to events as they arrive. There’s no central service coordinating what should happen. It’s like a dance, where each service "dances" according to the events it receives.
Example: The payment service processes the payment after the "Order Placed" event, and the inventory service reacts to the "Payment Processed" event. Everything happens without a central orchestrator coordinating the actions.
Conclusion
Event-Driven Architecture offers a powerful and flexible way to build distributed systems, where services are decoupled and react to events as needed. By understanding key concepts — such as events, commands, choreography, and orchestration, as well as the fundamental role of brokers — you can design systems that are scalable, resilient, and ready to meet the demands of the modern world. Mastering these patterns and practices is essential for building solutions that not only efficiently respond to changes but also allow for continuous evolution of the architecture.
But that’s not all, there are many other things we can address and talk about, I hope to bring more practical content in future articles! Thank you for reading and don’t forget to subscribe to this newsletter! See you next time!