
The Untold Secrets of Asynchronous Communication in Microservices
In this article, we will discuss some of the challenges that arise when dealing with asynchronous communication in distributed architectures. We’ll explore where things can go wrong — from the improper use of queues to how they can harbor silent failures. Our goal is to shed light on common pitfalls and how to avoid them.
If you’ve ever wondered why asynchronous communication between your microservices isn’t working as smoothly as it should, this article is for you.
What is Asynchronous Communication?
Asynchronous communication is like sending a letter through the mail. You write the letter, place it in an envelope, and send it off. Once you’ve sent it, you don’t need to wait at the post office until the person receives and responds to the letter. Instead, you go about your activities, knowing that the letter will be delivered at some point.

Imagine you’re communicating with a colleague. If both of you are on the phone, responding to each other immediately, that would be a "synchronous" conversation — everything happens at the same time.
Now, think about when you send a text message. Your colleague might not respond right away; they might see the message later and reply when it’s convenient. In this case, the communication is "asynchronous" — you don’t need to wait for an immediate response, and the conversation can continue at different times.
So, "asynchronous" simply means that things don’t have to happen at the same time. They can occur at different moments, without a fixed or immediate sequence.
Asynchronous communication excites software engineers because, much like the example of mailing a letter, it allows us to build systems that aren't stuck waiting for immediate responses. Imagine if, in the real world, you had to wait in line at the post office until the person received and responded to your letter. That would be incredibly inefficient, wouldn’t it? The same principle applies to software systems.
When a service doesn’t have to wait for a response to continue its work, it can operate much more efficiently, handling multiple tasks simultaneously without being blocked by long-running operations. This is crucial in complex and large-scale systems, where the ability to process large volumes of data and interactions efficiently can make the difference between a system that scales and one that crashes under pressure.
Additionally, asynchronous communication allows us to build more resilient systems. If a service is temporarily unavailable, messages can still be sent and processed later without disrupting the entire system. This provides a level of robustness that is hard to achieve with synchronous communication, where the failure of one service can cause others to stall.
Understanding asynchronous communication, we see how it allows us to send information without waiting for an immediate response, much like mailing a letter and going on with your day. This gives us tremendous freedom to create more efficient and resilient systems. But as we delve deeper into how this communication works, an essential question arises: what exactly are we sending between systems when we use this approach?
This is where the distinction between events and messages becomes crucial. While asynchronous communication is the "how" — the way we exchange information without needing an instant reply — we need to understand the "what" that is being exchanged in this communication.
Events and Messages: Understanding the Difference
Now that we've delved into the concept of asynchronous communication, it's time to explore a topic that, although seemingly simple at first glance, often causes confusion even among experienced programmers: the difference between "events" and "messages."
Imagine you're at a party, and the exact moment when the DJ plays the first song on the dance floor is the event itself. This event is a fact; something that has happened and marks the beginning of the fun. But how do you let your friends know that the party has started? You might send a text message, a photo in a WhatsApp group, or even make a quick call. The message here is the medium through which you communicate to others that the event (the party) has begun.

In the context of distributed systems, the event is what happened: it could be a new sale, a processed payment, or even an order being shipped. It is a record of something significant that occurred within a system. The message, on the other hand, is how you communicate that event to other parts of the system, allowing them to react to it in some way.
This distinction may seem clear now, but the truth is that many developers end up confusing these two concepts. And it’s not without reason. In complex systems, events and messages are closely intertwined and often used together. For example, when processing an order in an e-commerce system, the "order placed" event might be encapsulated in a message and sent to various services that need this information to perform their respective tasks (such as processing payment, updating inventory, or notifying the customer).

What leads to confusion is that the event and the message often share the same content. However, it’s important to remember that the event is the "what" — the fact that happened — while the message is the "how" — the medium through which this information is transmitted.
Programmers can get confused because the line between the "fact" and the "medium" can become blurred. After all, we are always dealing with events encapsulated in messages, and this proximity can lead us to treat them as synonymous. But recognizing this difference is crucial to designing clearer and more efficient software architectures.
When we understand that the event is the content, and the message is merely the transport, we can design more robust systems. And, just like in real life, when you separate what happened (the event) from how you tell people (the message), communication becomes much more effective.
Moreover, this clarity avoids misunderstandings and helps keep the system organized. If you treat events and messages as the same thing, you could end up sending unnecessary information or, worse, creating dependencies between parts of the system that should remain decoupled. This could lead to more difficult maintenance, performance issues, and even failures that could have been avoided.
Another point is that separating these concepts allows you to choose the best tools and strategies for each situation. You can use a robust messaging system to ensure that information is delivered reliably, while using events to trigger actions in different parts of the system without creating excessive interdependencies.
While asynchronous communication is dazzling with all its promises of scalability, resilience, and efficiency, it’s important to recognize that this brilliance can also blind us to some of the challenges and pitfalls it brings. Just like technology, which is often seen as the solution to all problems, asynchronous communication, when misunderstood or improperly implemented, can introduce complexities that are difficult to manage. Let’s now discuss more about the challenges and key points to watch out for.
The Challenges!
Let’s imagine an order processing system in a large online store. Every time a customer places an order, several operations need to happen in parallel: the payment must be processed, the inventory needs to be updated, a confirmation must be sent to the customer, and logistics must be notified to prepare the shipment. In a system that uses asynchronous communication, these operations can be sent as messages to different services that process them at different times. This allows the system to continue accepting new orders without being stuck waiting for payment confirmation or inventory updates.
However, this idealized scenario hides some complications. Let’s suppose the service responsible for payment becomes temporarily unavailable or the message queue becomes overloaded. Suddenly, orders that have already been confirmed by the customer may not be paid for, or the inventory might be updated with delays, leading to situations like overselling (selling more than what’s available in stock). Additionally, if the order of processing messages is not correctly managed, inconsistencies can arise, such as shipping a product before payment confirmation.
These are just a few examples of how asynchronous communication can surprise us with unexpected challenges. Martin Fowler mentions in one of his articles on microservices that "asynchronous communication is great for decoupling systems and improving scalability, but at the same time, it introduces significant complexity in managing state and ensuring consistency." He highlights that the difficulty in managing these asynchronous interactions can lead to debugging issues, where the cause of an error might be in a completely different part of the system from where the problem manifests.
Another point to consider is the difficulty of maintaining visibility in distributed systems that use asynchronous communication. In synchronous systems, the chain of events is more linear and predictable, making it easier to trace failures. In asynchronous systems, however, messages can follow varied paths depending on the current state of services, the response times of queues, and even intermittent network failures. This can greatly complicate the process of identifying and fixing issues.
A theoretical example could be a banking system that uses asynchronous communication to process transactions between accounts. If the messages confirming a fund transfer are not delivered or processed in the correct order, this can lead to critical inconsistencies, such as incorrect balances in customers’ accounts. The robustness that should be guaranteed by asynchronous communication can, in fact, become a point of fragility if these details are not carefully managed.
Managing Eventual Consistency
Imagine you and your friends are playing a card game, but you’re in different rooms of the house. When someone makes a move, they shout it out so that everyone else knows and can adjust their cards. It may take some time for everyone to hear and update their hands, and during that period, the cards in each player’s hands may look different. However, over time, everyone eventually receives the message and adjusts their cards, ensuring that everyone is back in sync.
This is the essence of eventual consistency: even if information is not immediately synchronized everywhere, eventually all parts of the system will reflect the same state.
Now, think of an e-commerce system that adopts an asynchronous approach. Imagine that the system allows a customer to place an order, and the order is confirmed before the payment processing is fully completed. In this scenario, the system may have a record of the confirmed order while the payment service is still verifying whether the transaction was successful.
If the transaction fails, there will be a temporary inconsistency: the customer might see the order as confirmed, but the payment has not gone through. Eventually, the system will detect the failure and correct the state, perhaps by canceling the order or requesting a new payment attempt.
Maintaining eventual consistency in such systems requires careful strategies, like compensation mechanisms (to reverse transactions), reconciliation (to ensure inconsistent states are aligned), or periodic audits (to review and correct discrepancies). These strategies add complexity to the system and require careful engineering to avoid introducing new points of failure.
Message Overload and Backpressure
Another common challenge is message overload, which can happen when a service sends messages faster than the recipients can process them. This can lead to excessively long message queues, increasing latency, and even data loss if the queues reach their maximum capacity.
To mitigate these issues, it’s necessary to implement backpressure mechanisms, which essentially "slow down" the sending of new messages until the previous ones have been processed. However, implementing backpressure effectively is not simple. It requires a deep understanding of the system’s behavior under different loads and the ability to dynamically adjust message sending and consumption rates.
Silent Failures and Dead Letter Queues
A common failure in asynchronous systems is what we call a "silent failure," where a message is not processed correctly, but the system doesn’t visibly fail. This can happen for many reasons: the recipient service might be temporarily unavailable, the message might be corrupted, or there might be an error in the processing logic. We’ll discuss this more in detail soon. But how do we try to handle these failures?
To address this, many architectures implement Dead Letter Queues (DLQs), which are special queues where messages that fail repeatedly are sent for later analysis. However, these queues are often neglected, leading to situations where critical problems go unnoticed for long periods. Effectively managing and monitoring DLQs is essential to ensure that failures do not accumulate in the system, but this requires operational discipline and proper tools.
These challenges show us that while asynchronous communication offers powerful tools, we must also be aware that these tools come with their own complexities. The idealistic vision of a perfectly decoupled and scalable system can blind us to the real challenges that arise in practice. Now, let’s explore and understand the perspectives of other programmers.
Sam Newman's Perspective on Asynchronous Communication
Sam Newman, author of books on microservices and other topics, is one of the leading voices in the discussion of distributed architecture, and he offers a well-balanced perspective on the benefits and challenges of asynchronous communication. Newman acknowledges the power and flexibility that asynchronous communication brings to distributed architectures, but he is also careful to highlight the points of caution that should be considered when adopting this approach.
One of his statements on the subject is: "Asynchronous communication can introduce significant complexity, especially in terms of tracking and debugging." What he is emphasizing here is that while asynchronous communication can help decouple services and improve scalability, it also makes the system less predictable. In synchronous systems, there is a clear sequence of calls and responses, which makes it easier to identify problems. In contrast, in asynchronous systems, messages can move through the system at different times and take different paths, making it harder to trace the source of an issue when it arises.
Newman also warns about the "difficulty in ensuring data consistency" in systems that heavily rely on asynchronous communication. As discussed earlier, eventual consistency is a reality in asynchronous architectures, but this can be a major challenge when dealing with systems that require a high degree of precision and reliability. He emphasizes that "when designing asynchronous systems, you must be prepared to handle eventual inconsistency and ensure that it does not compromise the integrity of the system." This might involve implementing compensation mechanisms, periodic reconciliation, or even accepting that certain operations may fail and need to be handled robustly.
Another interesting point that Sam Newman raises is the "need for good observability and tracing" in asynchronous systems. He states that "without adequate infrastructure to trace messages and events across multiple services, it is very easy to lose sight of what is happening in the system." This is critical because, in an asynchronous environment, problems can arise at any point in the message pipeline, and without a way to visualize the data flow, development teams may end up spending a lot of time trying to diagnose issues.
Moreover, Newman also discusses the risk of "coupling" that can arise in systems using asynchronous communication. "It's easy to assume that because services are communicating asynchronously, they are completely decoupled, but that's not always the case." He warns that hidden dependencies can emerge, especially if services start relying on specific message patterns or response times. "Asynchronous communication can create the illusion of independence when, in reality, services are tightly intertwined by their expectations of message exchange." This can lead to long-term maintenance and scalability issues.
The author emphasizes that success with asynchronous communication in microservices requires not only a good understanding of the benefits but also recognition and mitigation of the challenges. He recommends that teams be "deliberate and mindful" when adopting asynchronous patterns, always considering the impact on the overall complexity of the system. The central message is that while asynchronous communication can be extremely powerful, it also requires a careful approach to ensure it doesn't introduce more problems than it solves.
So, we can see that asynchronous communication is not a silver bullet. It offers a powerful way to build scalable and decoupled systems but requires architects and developers to be aware of the complexities that come with this flexibility.
Now, let's start discussing some of the pitfalls we might encounter in our day-to-day work.
The Misuse of Queues in Asynchronous Communication
When it comes to distributed systems, it’s easy to fall into the trap of believing that queues are the magic solution to all asynchronous communication problems. The idea of decoupling services, allowing each to process messages at its own pace, can seem like the perfect answer to dealing with complexity and load variability. However, this rushed vision can lead to the overuse or improper use of queues, creating more problems than solutions.
The Rushed Vision: "Queues Solve Everything"
Many developers, especially those new to microservices architecture, may see queues as a universal tool to solve latency, scalability, and service decoupling issues. The logic seems straightforward: inserting a queue between two services decouples their operations, allowing the message producer to continue its work regardless of the consumer’s speed. In theory, this should reduce bottlenecks and allow the system to better handle load spikes.
However, this simplistic approach can be misleading. The reality is that queues, when poorly implemented or used without careful analysis, can introduce new challenges into the system. Believing that "queues solve everything" ignores the nuances of how asynchronous communication actually works in a distributed environment. For instance, introducing a queue can add complexity to the data flow, increasing end-to-end latency and making message traceability more difficult.
When queues are used indiscriminately, problems can quickly pile up. One of the main consequences is message buildup, which can lead to system overload. Without a clear strategy for managing queue growth, the system may become less efficient, with messages being processed more slowly than expected. This contradicts the goal of using queues to improve performance.
Moreover, introducing queues at every communication point can create a false sense of security. Engineers may believe that simply because a queue has been inserted, the system is now resilient and capable of handling failures. However, without proper planning and without considering the behavior of services under extreme load, queues can become choke points, creating bottlenecks instead of eliminating them.
Rethinking the Strategy
It’s important to understand that queues are not the only tool available to address the challenges of asynchronous communication. Depending on the context, other strategies like webhooks or message brokers like Kafka may be more suitable. Webhooks, for example, are ideal for instant notifications where minimal latency is critical, while Kafka might be better in scenarios where large volumes of data need to be ingested and processed efficiently.1
When designing distributed systems, it’s essential to evaluate each situation individually, considering not only the immediate need for decoupling but also the long-term impacts on system performance, scalability, and resilience. The idea that "queues solve everything" should be replaced with a more holistic and strategic approach, where the choice of the right tool for the right job is guided by a deep understanding of the system’s needs and limitations.
Queues have their place in distributed architectures, but they are not a magic solution to all problems. The rushed vision that "queues solve everything" can lead to improper use, which, instead of improving, can degrade the system’s performance.
But what happens when things don’t go as planned? Even when queues are carefully implemented, failures can occur — messages can be malformed, services can temporarily fail, or queues can unexpectedly fill up. This is where Dead Letter Queues (DLQs) come into play as an essential tool for handling messages that cannot be processed normally.
Dead Letter Queues
In distributed and asynchronous systems, dealing with failures is an integral part of the process. Not all messages sent from one service to another reach their final destination smoothly. Some get lost along the way, whether due to a temporarily unavailable service, a corrupted message, or even an error in processing logic. When these failures occur, we need a mechanism that allows us to detect, analyze, and ideally correct these issues.
What Are Dead Letter Queues?
We can think of a DLQ as the “bin” where letters that couldn’t be delivered to the recipient for some reason end up. Imagine a postal service that, when attempting to deliver a letter, discovers that the address is incorrect or the recipient is unavailable. Instead of simply discarding the letter, the service places it in a special bin where problematic letters are stored until they can be reviewed and handled later.
This is the basic concept behind a DLQ in asynchronous messaging systems. When a message cannot be processed after a certain number of attempts—whether because the recipient service is unavailable, the message is malformed, or there is a logic error—that message is diverted to the DLQ. The primary purpose of these queues is to allow software engineers to revisit these failed messages, understand what went wrong, and take the necessary actions, whether it be correcting the message, the code, or even the data being processed.
The Misconception of DLQs
Despite the clear purpose of Dead Letter Queues (DLQs), many engineers have a misguided view of how they should be used. Instead of being seen as a tool for diagnosing and fixing issues, DLQs often become a kind of “dumping ground” where problematic messages simply disappear without receiving proper attention. This creates a serious issue: silent failures.
Messages that end up in a DLQ are indicative of system failures — which might be small or isolated, but can accumulate over time and result in significant problems. Let’s imagine a system that sends SMS notifications to customers about the status of their orders. When an order is confirmed, the system sends a request to the regular queue, from which the SMS service processes the messages and sends notifications to customers.
Now, imagine that some messages are malformed — perhaps missing required fields or having formatting errors. In this case, the SMS service would attempt to process them but fail, and those messages would be redirected to the DLQ after the maximum number of reprocessing attempts.
The system may continue functioning normally for most customers, but the messages that end up in the DLQ indicate that some critical notifications were not sent successfully. If no one monitors the DLQ and takes corrective actions to handle these messages, some customers may never receive their order updates, leading to frustration and dissatisfaction.
This example illustrates how DLQs capture failures of messages that cannot be processed, but it also highlights the importance of monitoring them and taking proactive action to prevent the loss of important messages and ensure system reliability.
The Initial Purpose of DLQs and Where We’re Going Wrong
The initial purpose of DLQs was to act as an alert system for problems that couldn’t be resolved in the normal message flow. These queues were designed to capture errors that require human intervention or automated correction processes. However, the mistake many engineers make is treating DLQs as the final resting place for lost messages, without establishing clear processes for reviewing and addressing the messages that end up in these queues.
This misconception is dangerous because it turns the DLQ from a proactive problem-solving tool into a black hole where errors accumulate without being detected. The DLQ is not an end but a means to an end. The real value of a DLQ comes from how it is used to identify and correct problems. This means that development and operations teams need to be attentive to the messages that land in these queues, regularly analyzing them and integrating processes that allow for the correction of the failures that caused these messages to deviate from the normal flow.
Now, it’s worth considering how we should approach DLQs in our architectures. Dead Letter Queues are a necessary safety measure, but they cannot be an excuse for not addressing real problems in the main flow. While DLQs are useful for capturing failures that might go unnoticed, they should not be seen as the final solution to these problems.
It’s tempting to treat DLQs as a safety net where you can toss all the problems and forget about them. But this only postpones the inevitable—a buildup of problematic messages that can eventually become unmanageable. The true effectiveness of a DLQ comes from the ability to use it as a starting point for continuously improving the system, learning from mistakes, and adjusting processes so that messages do not need to be diverted to the DLQ in the first place.
Silent Failures: The Hidden Danger of Asynchronous Communication
Silent failures are one of the most insidious pitfalls in microservices systems that utilize asynchronous communication. Unlike obvious failures, where a service or operation fails clearly and generates immediate alerts, silent failures go unnoticed, without triggering obvious alarms, yet they still compromise the system's functionality.
Imagine you’re at a large live music event. Each instrument in an orchestra plays an essential part of the music, but they’re playing without a conductor. Now imagine that one of the instruments, like the violin, starts playing a wrong note intermittently. This wrong note is subtle, almost imperceptible, and so goes unnoticed by most listeners. The show goes on, the audience seems satisfied, but there’s something about the music that doesn’t sound quite as it should.
Over time, these wrong notes start to accumulate and, although they’re not loud enough to stop the music, they start to distort the melody. The audience doesn’t notice the problem right away because the error is small and sporadic, but the impact becomes clear when the overall harmony starts to break down. It’s only when someone starts to analyze the recording or a listener with a very keen ear notices something wrong that they realize that the music has lost some of its beauty and precision because of these small, unnoticed flaws.
Similarly, in microservices systems, silent failures are like these bad notes: they don’t stop the system from working, but by accumulating small distortions, they can compromise the integrity of the final result. The system continues to operate, but critical parts may be affected without anyone noticing immediately, leading to bigger problems down the road.
A silent failure might occur, for instance, when a message is diverted to a Dead Letter Queue, as we discussed earlier, due to a subtle error like a missing field in the message payload. Let’s imagine that a required field, such as a customer identifier, is missing. This absence won’t necessarily stop the entire system but will prevent that specific message from being processed correctly. Without this field, the service that is supposed to consume the message cannot complete its task, and the message ends up in the DLQ.

The problem is that this failure doesn’t generate an obvious error in the system. The process may continue working for other messages, and the development team may not even realize that something is wrong. The problematic message remains "hidden" in the DLQ, creating a silent failure.
The complexity of these failures lies in the difficulty of detecting and debugging them. In many cases, the message that ended up in the DLQ might have been sent hours or days ago, and the system has already processed thousands of other messages since then. The failure, therefore, is not immediately visible, and it may require detailed log analysis, event tracing, and investigation of the involved services to understand what went wrong.
This complexity increases even further when we consider that these silent failures can accumulate over time, especially in systems with a high volume of messages. If not identified and resolved, these failures can lead to delays in feature delivery, unexpected interruptions, and growing frustration for both the development team and end users.
Imagine the impact in a business scenario where these messages are critical, such as in order processing or customer communication. A missing field might not seem like a big problem initially, but if the silent failure persists, it can cause data inconsistencies, generate errors in financial reports, or even result in lost revenue.
Moreover, debugging these failures can be extremely challenging. Without proper monitoring and tracing tools, identifying the root cause can become an arduous task, requiring a thorough review of every point in the system where the message passed through. This not only delays problem resolution but also delays the delivery of new features, as the team needs to allocate time and resources to resolve these hidden issues.
How to Mitigate This Risk?
To mitigate silent failures in asynchronous communication, engineers need to adopt an approach that goes beyond basic monitoring. The key is to create a layer of visibility and control that allows for identifying and resolving these failures before they become a larger problem. This involves a combination of engineering practices, appropriate tools, and a proactive mindset.
First, one of the fundamental steps is to implement robust monitoring. This means setting up alerts that not only detect obvious failures but also identify unusual patterns or behaviors that may indicate something is amiss, even if the system appears to be functioning normally. For example, if the number of messages diverted to the DLQ begins to subtly increase, this should trigger an alert so the team can investigate before the problem escalates.
In addition to monitoring, tracing is a powerful tool for tracking the path of each message through different services. With tracing, engineers can follow a message from its origin to its final destination, pinpointing exactly where something went wrong. This not only helps detect silent failures but also makes debugging much more efficient, allowing the team to quickly find the root cause of a problem without having to manually analyze large volumes of logs.
Another important practice is rigorously validating messages before sending them to their destination services. Implementing strict validations on the producer services, such as verifying the presence of all required fields and ensuring that data is in the correct format, can prevent incorrect messages from being sent in the first place. This reduces the likelihood of failed messages ending up in the DLQ due to issues that could have been avoided.

Additionally, automated replay processes can be useful for reprocessing messages that fall into the DLQ once the underlying issue has been resolved. However, it is crucial to ensure that the reprocessing is done in a controlled manner to prevent messages from being repeatedly sent back to the DLQ. This requires engineers to have a solid understanding of what caused the initial failure and to ensure that the corrections are effective.
Another strategy is to conduct regular audits of the DLQs. This doesn’t just mean checking for messages in the queue, but analyzing the types of failures that are occurring and adjusting the system to prevent these failures from recurring. Audits can reveal patterns that are not evident in day-to-day operations, allowing the team to make continuous improvements.
Finally, cultivating a culture of communication and continuous learning within the development team is essential. When a silent failure is identified and resolved, the team should share the knowledge gained with all members, document the root cause, and the actions taken to prevent the issue from happening again. This practice not only strengthens the system in the long run but also increases the resilience of the team.2
Now, let’s discuss something very important in an ecosystem that communicates asynchronously.
Latency and Response Time Issues in Asynchronous Communication
Even in an asynchronous architecture, where messages are sent without the need for an immediate response, the overall system response time can be compromised, and the impact can be significant, especially in applications that require high performance and low latency.
To understand how this happens, imagine you are in line at a bank. If there’s only one person ahead of you, service is quick. But if the line starts to grow, the time it takes for you to be served increases, even if the bank has multiple service windows. The problem can be exacerbated if, for example, one of the tellers is slower than usual or if there’s a more complex operation that all tellers are dealing with. In this scenario, adding more people to the line only increases the wait time for everyone.
In distributed systems, something similar happens. If the consumer service is overloaded or dealing with complex tasks, adding more messages to the queue only increases the response time for each individual message. Latency is no longer just the time it takes to process a message but also the time the message spends waiting in the queue before it can be processed.
The Growing Queue and Latency
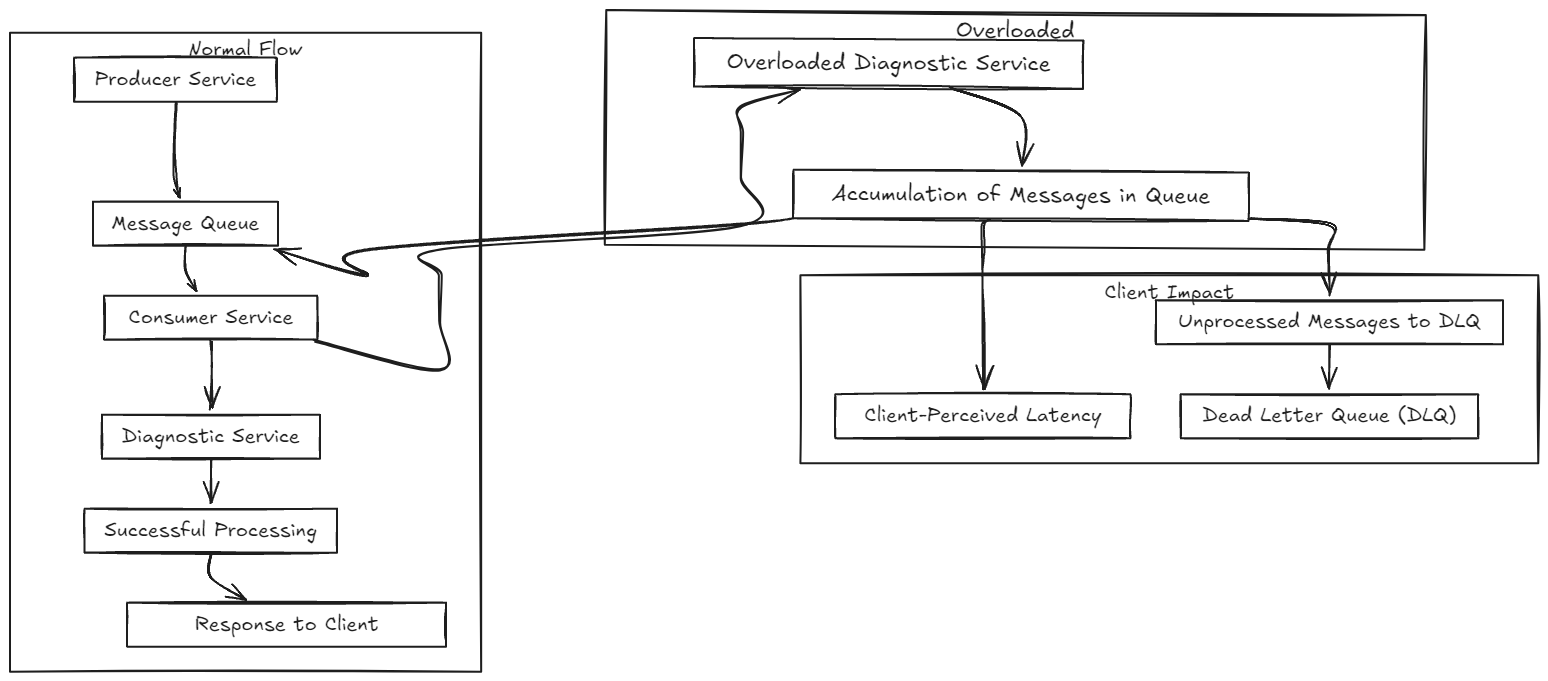
Let’s imagine a customer service system in a large telecommunications company. When a customer requests technical support, the system needs to perform several steps: identify the problem, check the customer’s service history, and, if necessary, schedule a technician visit. In an asynchronous communication architecture, the service that receives the customer’s request places a message in a queue for the diagnostic service, which analyzes the reported issue. Then, another message is sent to the service responsible for checking technician availability, and so on.
Initially, this approach seems efficient. Each service operates independently, and asynchronous communication allows the system to continue processing other requests without having to wait for each step to be completed sequentially. However, the situation can become complicated when the message queue starts to grow.
When a message is placed in a queue, the time it takes to be processed depends on how many other messages are already in the queue and how quickly the consumer services can handle them. If, for some reason, processing slows down—perhaps due to an overload in the diagnostic service or an unexpected increase in support requests—messages start to pile up. This creates a cascading effect: the more messages in the queue, the longer it takes for each new message to be processed.
This additional latency can become noticeable to the customer. For example, if the service checking technician availability is overloaded and cannot process messages quickly, the total time to schedule a technician visit increases. Even if the system continues to function technically, the customer may have to wait longer to receive a solution to their problem.
Why Scaling More Pods Doesn’t Always Solve the Problem
The idea of scaling horizontally by adding more instances of the service (or pods, if you’re using Kubernetes) seems like a logical and straightforward solution to latency and capacity issues. However, this has its limitations and can, in some cases, even exacerbate the problems you’re trying to solve. Why?
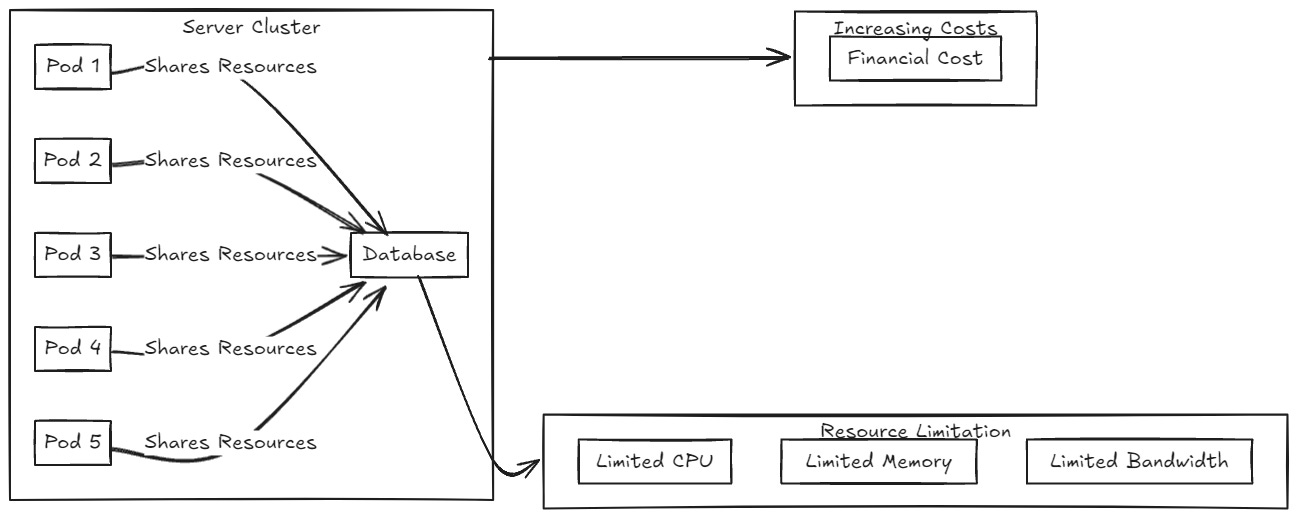
When you add more pods, each of these pods requires resources to function—CPU, memory, and network bandwidth. However, these resources are finite. Imagine that all these pods are running in a cluster of servers. If the cluster is running at the hardware capacity limit, adding more pods won’t bring the expected benefit.
For example, if your application is limited by database processing, adding more pods won’t solve the problem because the database, which is a shared resource, remains the bottleneck. In other words, you’re just creating more instances that compete for the same set of scarce resources, and the impact will be minimal.
Moreover, in cloud environments, scaling horizontally can also significantly increase costs. Even if you have resources available, there is a financial cost for each additional instance that may not be justified if the performance gain is marginal.
Resource Contention
Resource contention is another critical issue. When you scale horizontally, all the pods or instances need to access shared resources, such as a central database, a cache service, or even the network. As the number of pods increases, they all compete for these resources.
Let’s consider the example of a centralized database. If you add more pods that frequently query the database, it’s likely that the database will become the bottleneck. That’s because, despite having more pods trying to process messages, the wait time to access the database increases, leading to higher latency for all services that depend on that database.
This resource contention can create a domino effect, where increasing the number of pods not only fails to improve performance but also degrades the performance of the entire system. The result is a system that, despite having more instances, operates less efficiently.
Synchronization Complexity
As you add more service instances, the synchronization complexity between these instances also increases. In asynchronous systems, there may be a need to coordinate state between different service instances to ensure data consistency.
For example, if multiple pods are processing different parts of a financial transaction, all of them need to be in sync to ensure that the transaction is complete and consistent. If synchronization is not well managed, you might introduce additional latency while the pods try to coordinate, or worse, there could be data inconsistencies that could lead to processing errors.
In distributed systems, this synchronization complexity can be exacerbated by the need for coordination between pods in different geographic regions or different clusters. Each new instance added to the system increases this complexity, which can lead to a reduction in the overall efficiency of the system.
Cascading Latency Increase
When a message queue is already growing rapidly, adding more instances to process these messages might seem like a good solution. However, this can have a paradoxical effect. As more instances try to consume messages from the queue, you might end up increasing the number of messages being added to the queue if the instances are generating new messages as part of their processing.
For example, if each instance that processes a message also generates other messages for different services, you end up adding more load to the queue. This can create a vicious cycle where the attempt to improve performance ends up creating more work for the system, leading to even higher latency.
This cascading effect means that instead of alleviating the pressure on the system, you’re merely redistributing the problem so that it spreads across more parts of the system. The message queue continues to grow, and the total time to process all the messages may increase instead of decrease.
Horizontal scalability is not a magic solution to latency problems in asynchronous systems. As we’ve seen, limited resources, resource contention, synchronization complexity, and the risk of increasing cascading latency are factors that can make this approach ineffective or even counterproductive.
Let’s discuss some strategies that can help mitigate latency issues in asynchronous systems. We know that in distributed systems, latency can arise in unexpected ways, even in asynchronous architectures, where we might expect everything to flow smoothly and without waits. However, the reality is a bit more complicated, and this is where some approaches can make a difference. Let’s talk about them in more detail and also the possible challenges you may face when implementing them.
Strategies for Optimizing Performance in Asynchronous Communication
When we talk about optimizing asynchronous communication, we’re really looking for ways to make our systems more efficient and resilient. There’s no silver bullet; each approach has its advantages and challenges. Let’s take a look at some strategies that can help improve your system’s performance, always keeping in mind that context is everything.
Rate Limiting: Controlling Access
Imagine a road with a speed limit. Rate limiting works just like that: it sets how many requests the system or an API can handle within a certain period of time. This prevents the system from being overwhelmed during a surge in demand.
Here’s how it works: when the limit is reached, the system can either reject additional requests and ask the user to try again later or place those requests in a waiting queue. Depending on the case, the system might even dynamically adjust the limit based on the current load.
This technique is particularly useful in scenarios where stability is more important than immediate speed. But, like everything, it has its downside: if not well-calibrated, it can leave users waiting or even worsen the experience during peak access times.
Message Prioritization
Not all messages are created equal, right? In a customer support system, for example, resolving a critical issue is much more urgent than a request to change a setting. That’s why it makes sense to prioritize the most important messages.
However, there’s a catch: if you always prioritize certain messages, lower-priority ones might end up neglected, piling up in the queue. Imagine a restaurant that only prepares the most complex dishes and leaves the simple orders for later—the customers who ordered something simple end up waiting longer than necessary.
Prioritizing messages is a good strategy, but it requires careful balance to ensure that less urgent tasks are also handled in a timely manner.
Circuit Breakers: A Smart Filter
Circuit breakers are like the fuses in your house. When a service is overloaded or failing, the circuit breaker stops the flow of new messages, giving the service time to recover.
This prevents the problem from getting worse, but it can also create a side effect: the messages that were blocked start piling up, and when the circuit breaker disengages, they all arrive at once, potentially overloading the service again. That’s why it’s essential to manage this situation carefully, perhaps processing the messages in smaller batches or with adjusted priority.
Resource Tuning: Giving the Best to What Needs It
You’ve probably experienced this: in a critical system, like a real-time monitoring service, resources never seem sufficient. Resource tuning is about ensuring that the most important services have what they need to function smoothly, even during peak demand.
This requires a good understanding of what each service really needs. If you over-allocate resources to one service, you might end up leaving others without the necessary resources, creating new bottlenecks. It’s a matter of balancing needs, constantly adjusting as the system’s usage evolves.
Distributed Queues: Spreading the Workload
Now, imagine a major sporting event happening in multiple cities at the same time. Instead of having a single ticket sales center, you spread ticket points across each city. This reduces wait time for fans who buy tickets locally, but it also adds complexity when it comes to syncing everything.
Distributing queues among different services or regions can reduce latency, but it can also introduce new challenges, such as keeping data synchronized and ensuring that all queues are consistent. If not well-managed, this can end up creating more latency and issues than it resolves.
Batch Processing: Processing in Bulk
Batch processing is like tackling multiple tasks at once instead of one by one. If you need to send a thousand emails, for example, it’s much more efficient to group them and send a hundred at a time.
The downside? This approach can introduce a slight delay, especially in systems that require quick responses. In contexts where timing is critical, this latency can be an issue, so it’s essential to weigh whether the benefits outweigh the risks.
Questions That Need to Be Asked!
Implementing asynchronous communication strategies can seem complicated, but it’s crucial to ensure your system runs efficiently, is resilient, and can scale as needed. To help you choose the right strategies, here are some questions worth considering:
What Are My Services’ Priorities?
Think: Which services or features are absolutely essential for the system’s operation and the user experience?
Why It Matters: Knowing which services are critical will help you decide where to focus more resources, where to apply circuit breakers, and which messages should be handled with more urgency.
What’s My System’s Traffic Profile?
Ask yourself: How does traffic vary throughout the day, the week, or during specific events? Are there predictable spikes?
Why It Matters: Understanding traffic patterns allows you to implement rate limiting and allocate resources more efficiently, avoiding overloads during peak times.
How Do I Handle Latency?
Reflect: What is my system’s tolerance for latency? Can I accept small delays, or do I need real-time responses?
Why It Matters: Assessing the importance of latency will help you decide whether techniques like batch processing or distributed queues are most suitable for your scenario.
Am I Prepared to Handle Failures?
Consider: How does my system react when a service fails? Do I have mechanisms to prevent a failure from propagating?
Why It Matters: Circuit breakers are great for isolating failures, but it’s essential to have a recovery plan and be prepared to manage the buildup of messages when the service returns to normal.
How Do I Monitor and Adjust My System?
Ask yourself: What tools am I using to monitor the performance and status of my services? Am I ready to make adjustments as needed?
Why It Matters: Continuous monitoring and the ability to make dynamic adjustments are essential for keeping the system running efficiently and resiliently as conditions change.
Is Synchronization Creating Problems?
Think: Are my distributed queues introducing more problems than they’re solving? Is synchronization between regions or services causing inconsistencies?
Why It Matters: Evaluating whether the additional complexity of keeping distributed queues synchronized is truly offsetting latency reduction or is creating new bottlenecks can be crucial for system performance.
Conclusion
In this article, we explored pitfalls associated with asynchronous communication in microservices architectures. From the temptation to consider queues as a magic solution to all problems to the dangers of silent failures and how they occur.
Asynchronous communication offers significant benefits in terms of scalability and temporal decoupling, but these benefits come with their own risks.
Ultimately, the key to success in distributed architectures is balance. In part two of this article, we will continue to discuss and explore more topics that deserve attention.
Here I will briefly mention some of the options you can study and implement:
Events and Pub/Sub (Publish/Subscribe):
Description: The Pub/Sub pattern is a form of asynchronous communication where system components publish events that other components can subscribe to. This creates a high level of decoupling, as there is no direct link between the publisher and the consumer of the event.
Common Use: Ideal for systems where multiple services need to react to the same event in different ways. For example, when a new transaction is processed, one service may update the balance, another may send a notification, and another may log the event for auditing.
Tools: Kafka, Redis Pub/Sub, Amazon SNS.
Callbacks:
Description: In callbacks, an asynchronous function or service is invoked, and when the operation is complete, a callback function is called to process the result. This is common in APIs, where the response or result of an initial call is handled later.
Common Use: Widely used in API integrations, especially in asynchronous HTTP calls and JavaScript frameworks.
Tools: Callbacks are more of a programming pattern than a specific tool but are widely supported by various frameworks and libraries.
Polling:
Description: In polling, a system regularly checks a resource or service to see if a task is complete or if new data is available. Although not the most efficient method, it is useful when it is not possible to implement push communication.
Common Use: Suitable for systems where real-time response is not critical or when there are technical limitations to real-time communication.
Tools: It can be implemented directly in scripts with waiting loops or using cron jobs.
Webhooks:
Description: Webhooks allow a service to send an HTTP POST request to a specific URL when an event occurs. Instead of a system constantly checking for new data, the service that detects the change directly notifies the interested system.
Common Use: Widely used in system integrations where an external service needs to notify the local system of an event, such as when a transaction is completed in a payment service.
Tools: Webhooks are widely adopted by modern APIs, such as Stripe, GitHub, and other SaaS services.
To implement robust monitoring, it is essential to use tools that offer not only real-time visibility but also the ability to identify patterns and anomalies. Prometheus is an excellent choice for metric collection, especially when combined with Grafana for visualizing these metrics in dashboards. With these tools, you can set up custom alerts that trigger when certain conditions are met, such as an increase in the number of messages diverted to the DLQ. These alerts can be integrated with notification systems like PagerDuty or Slack, ensuring that the team is immediately informed of any anomalies.
Additionally, using AWS CloudWatch or Azure Monitor can be particularly useful in environments that utilize cloud services, as these tools offer native integrations with various services, allowing for deep monitoring of system operations, including DLQs. Both tools provide the ability to set alarms based on custom metrics, such as the growth rate of messages in a DLQ.
Distributed Tracing for Traceability
Distributed tracing is essential for following the path of a message through different microservices. Tools like Jaeger and Zipkin are widely used to implement distributed tracing. These tools capture detailed information about each step a message or request takes within a distributed system. Integrating them with microservices frameworks like Spring Cloud (in the Java ecosystem) simplifies the implementation of tracing in each service, allowing engineers to visualize the complete trajectory of messages and quickly identify where a failure occurred.
OpenTelemetry is another powerful tool as it provides a unified solution for metrics, logs, and tracing. With it, you can monitor the performance of each component in a distributed system and detect silent failures by analyzing the complete journey of messages in one place.
Rigorous Message Validation
To ensure that messages are rigorously validated before being sent to the destination services, it is essential to implement validation mechanisms at the application level. Frameworks like JSON Schema can be used to define and validate the structure of JSON messages before they are placed in a queue. This ensures that all messages contain the required fields and are in the correct format.
In the Java world, libraries like Hibernate Validator can be used in conjunction with Spring Boot to validate objects before they are serialized and sent to queues. Additionally, implementing contract testing using tools like Pact can help ensure that the messages exchanged between services strictly adhere to the defined contracts, minimizing the chance of errors in production.
Automated Replay Processes
Automating the replay of messages from the DLQ can be done using scripts or specific tools that reprocess the messages once the issues have been resolved. AWS Lambda, for example, can be configured to monitor a DLQ and, as soon as an error is fixed, automatically reprocess the messages, sending them back to the main queue.
In Kubernetes, you can implement a Job or CronJob that periodically checks the DLQs and reprocesses the messages. It’s important that these replay processes are configured with safeguards, such as retry limits and additional validations, to prevent faulty messages from being reprocessed indefinitely.