


Idempotência: O Que Realmente Importa e Por Que Você Deve Se Preocupar
Falhas Acontecem. Idempotência Garante Que Elas Não Sejam Piores!

Já ouviu falar em idempotência? É uma daquelas palavras que podem surgir em conversas técnicas, seja no meio de uma reunião ou enquanto estamos revisando um código. Talvez um arquiteto do seu time tenha mencionado que “precisamos garantir a idempotência dessa operação”, ou quem sabe o gerente do projeto já tenha comentado algo como “tivemos problemas com duplicação”. Mas o que exatamente isso significa? Vamos conversar bastante sobre esse tema!
O que é?
A palavra idempotência tem uma origem interessante. Ela vem do latim: “idem”, que significa “o mesmo”, e “potens”, que quer dizer “poder”. Literalmente, é algo como “o mesmo poder”. Em matemática, o termo começou a ser usado no século XIX para descrever funções que, quando aplicadas várias vezes, não mudam o resultado além da primeira aplicação.
Em inglês, segundo o Oxford English Dictionary, idempotent é definido como: “(of an element of a set) unchanged in value when multiplied by itself” — ou seja, algo que permanece igual ao ser aplicado a si mesmo. Já o Merriam-Webster descreve idempotent como:
“producing the same result no matter how many times the operation is performed”
(produzindo o mesmo resultado, não importa quantas vezes a operação seja realizada).
Produzir o mesmo resultado, não importa quantas vezes… A idempotência é exatamente isso: realizar uma ação repetidamente, sem mudar o estado final.
Agora, trazendo isso para o nosso cotidiano: imagine um interruptor de luz. Se a luz já está apagada e você aperta o interruptor novamente para tentar apagá-la, nada acontece. O estado permanece o mesmo — a luz continua apagada. O efeito é o mesmo, seja você acionando o interruptor uma vez ou várias, desde que a luz já esteja apagada.

Esse é um exemplo clássico da idempotência, ações repetidas não causam efeitos adicionais.1
Como isso afeta nosso cotidiano?
Idempotência facilita nossa vida ao garantir que sistemas e ações sejam confiáveis, simples e eficientes. Isso ajuda em três pontos principais:
1. Estabilidade
Imagine um botão de semáforo para pedestres. Se apertar várias vezes causasse erros, seria um caos! Por ser idempotente, o botão só precisa ser pressionado uma vez para funcionar corretamente, sem criar problemas.
2. Previsibilidade
Quando você tranca uma porta, girar a chave novamente não muda nada — ela continua trancada. Isso nos dá segurança para agir sem medo de bagunçar tudo.
3. Economia de esforço
Apertar o botão de desligar um ventilador que já está desligado não gasta energia extra.
Idempotência é sobre simplicidade funcional
A idempotência no cotidiano é essencial porque remove complicações, criando interações simples e confiáveis com o mundo à nossa volta. Ela é o motivo pelo qual não precisamos “ficar pensando duas vezes” antes de executar uma ação: se já fizemos, tudo está em ordem; se não fizemos, podemos ir sem medo. 💪
Esse princípio, tão técnico em sua origem, é na verdade um pilar invisível do dia a dia, que nos ajuda a evitar frustrações 😌 e a viver com mais fluidez. Fascinante, não acha?
Idempotência na Engenharia de Software!
Tá, mas e no contexto de software? Idempotência, no contexto de engenharia de software, está relacionada à garantia de consistência ao executar uma operação repetidamente. Isso é fundamental, especialmente em sistemas distribuídos, onde falhas de comunicação podem acontecer. Imagine que você envia uma solicitação para uma API e, por algum motivo, não recebe uma resposta — seu cliente (ou o sistema intermediário) pode tentar enviar a mesma requisição de novo. E agora? O sistema está preparado para lidar com essa repetição sem gerar efeitos colaterais indesejados?
E o que isso significa na prática?
Nos serviços web, temos os famosos verbos HTTP (como GET, POST, PUT, DELETE etc.), e a idempotência desempenha um papel importante aqui. Esses verbos indicam as ações que estamos realizando no servidor, mas nem todos são idempotentes:
• GET: É idempotente porque, ao buscar o mesmo recurso várias vezes, o resultado não muda o estado do servidor. Você pode pensar como consultar um relatório — você pode pedir a mesma informação dez vezes que nada muda no servidor.
• PUT: Também é idempotente porque substitui um recurso. Se você mandar a mesma solicitação várias vezes, o resultado será sempre o mesmo: o recurso será atualizado para aquele estado específico.
• DELETE: Apesar de parecer estranho, DELETE também é idempotente! Se você pedir para deletar um recurso, e ele já foi apagado na primeira vez, as chamadas seguintes não terão efeito — o estado do servidor não muda.
• POST: Aqui está a exceção! POST não é idempotente, porque cada solicitação geralmente cria um novo recurso. Se você enviar duas requisições POST para criar uma conta, vai acabar com duas contas duplicadas.
Se você quiser saber mais detalhe se esses verbos HTTP são seguros, basta ver a nota ao rodapé.2
E o estado do servidor, o que tem a ver com isso?
A idempotência está profundamente ligada ao estado do servidor e aos dados que ele armazena. Pense assim: cada operação que você realiza em um sistema pode alterar ou manter o estado dos dados. Um sistema idempotente garante que, não importa quantas vezes você realize uma mesma operação, o estado final do servidor será o mesmo de quando você a executou pela primeira vez.
Por exemplo, ao enviar uma requisição PUT para alterar o preço de um produto para R$ 100, você pode enviá-la mil vezes, mas o preço continuará sendo R$ 100 no final — essa é a idempotência agindo. Agora, se você usar POST para criar um pedido, cada requisição vai adicionar um novo pedido, alterando o estado do servidor a cada tentativa.
A idempotência é crucial para a robustez de sistemas distribuídos e no próximo tópico vamos entender o porque.
O Caos da Falta de Idempotência: Da Máquina de Café ao Sistema Bancário
Já aconteceu de você apertar o botão de uma máquina de café e nada acontecer? Depois de alguns segundos de espera, você pensa: Será que não funcionou? Então, sem pensar muito, aperta o botão de novo… e pronto! Dois cafés saem de uma vez. Parece uma situação engraçada e inofensiva, né? Afinal, é só café — talvez até dê para aproveitar o segundo.

Essa pequena analogia da máquina de café ajuda a ilustrar como a falta de idempotência pode causar problemas no nosso cotidiano. Mas, e se não fosse café? E se estivéssemos falando de dinheiro saindo de uma conta bancária?

Se uma ação que deveria ser feita uma vez acaba sendo executada várias vezes por falha do sistema ou por ações do usuário, os resultados podem ser inesperados e, muitas vezes, indesejados. O mesmo conceito se aplica no mundo digital, mas os impactos são muito maiores.
Quando o sistema bancário “trava” e o caos começa
Agora, vamos imaginar um cenário em uma API REST que lida com operações bancárias, como transferências ou saques. Suponha que você está no aplicativo do banco para transferir 100 reais para um amigo. Você preenche os dados, clica em Confirmar e, no momento em que o sistema deveria processar a transação, algo dá errado — a internet oscila ou o servidor demora para responder. Você espera alguns segundos, mas a tela não atualiza. Sem saber se a operação foi concluída, você tenta novamente. Dessa vez, a transferência parece ter funcionado. Ufa!

Mas o que aconteceu nos bastidores? Sem idempotência, o sistema pode interpretar as duas tentativas como solicitações separadas.
Resultado: seu amigo recebe R$ 200 em vez de R$ 100, e você fica assustado! 😬
Por que isso é tão crítico?
No mundo financeiro, cada transação é como um bloco de confiança. Quando algo dá errado, os impactos vão muito além de um simples erro técnico. Pense nos possíveis desdobramentos:
1. Impacto para o cliente: Imagine o susto de perceber que seu saldo foi reduzido além do esperado ou, pior ainda, que sua conta entrou no vermelho. Isso gera frustração imediata e pode levar o cliente a desconfiar do banco.
2. Impacto para o banco: Para a instituição financeira, a duplicação de uma operação não é só um erro; é um potencial prejuízo financeiro. Seja para corrigir manualmente cada caso ou para lidar com disputas judiciais de clientes insatisfeitos, o custo é enorme.
3. Impacto na reputação: Bancos dependem de confiança. Problemas frequentes causados por falhas na idempotência podem destruir a imagem da instituição e levar clientes a migrarem para concorrentes.
Onde tudo começa?
O problema está no fato de que certas operações, como um saque ou transferência, não são naturalmente idempotentes. Diferente de atualizar o número de telefone em uma conta (que sempre leva ao mesmo resultado final, não importa quantas vezes seja feito), ações que alteram o saldo de uma conta dependem do histórico e da sequência de eventos. Repetir essas ações sem controle é como apertar o botão da máquina de café várias vezes: o sistema pode não saber que já processou a solicitação inicial e repetir a ação desnecessariamente.
Essa é a essência do problema que queremos discutir: a falta de idempotência pode transformar sistemas bancários em verdadeiras armadilhas para os clientes e dores de cabeça para as empresas.
Soluções Ingênuas para a Falta de Idempotência: Por que Nem Sempre Funcionam?
Lembra da nossa analogia da máquina de café? Vamos retomar esse cenário para falar de soluções que, à primeira vista, podem parecer resolver o problema, mas que, no fundo, acabam gerando mais confusão do que respostas claras.
Imagine que alguém teve a brilhante ideia de colocar um temporizador na máquina de café para evitar a duplicação de pedidos. A lógica seria algo como: “Se dois pedidos forem feitos com menos de 10 segundos de diferença, descartamos o segundo.” Parece uma solução interessante, certo? Afinal, quem precisa de dois cafés tão rápido assim? Mas aqui está o problema: e se você REALMENTE quisesse dois cafés? Ou pior, e se o primeiro pedido falhou, mas o temporizador descartou o segundo pensando que era duplicado? Resultado: nem café, nem solução eficiente.
Agora, vamos levar essa ideia para o mundo das APIs REST e sistemas bancários. Como você pode imaginar, soluções “rápidas” para lidar com a falta de idempotência em transações financeiras podem ser desastrosas. Vamos falar de algumas abordagens ingênuas e entender por que elas não funcionam.
1. Verificar Timestamps: A Armadilha do Relógio
Uma solução ingênua é comparar o timestamp (marcação de tempo) das transações. A ideia é que, se duas transações tiverem exatamente o mesmo horário, elas são consideradas duplicadas, e o sistema descarta a segunda. Parece simples, mas vamos aos problemas:
• Falta de unicidade por timestamp: Embora timestamps possam identificar transações únicas em sistemas simples, eles não são suficientes em sistemas complexos. Operações realizadas por diferentes usuários ao mesmo tempo podem ter o mesmo timestamp, e, sem mais contexto, o sistema pode interpretar erroneamente como duplicadas ou legítimas.
• Problemas de precisão e sincronia: Mesmo se o timestamp for atrelado ao ID do usuário, relógios desincronizados entre servidores podem causar inconsistências. Sistemas distribuídos frequentemente dependem de servidores em diferentes fusos horários, aumentando o risco de decisões incorretas.
• Impacto negativo na confiabilidade: Se o sistema descartar transações legítimas por uma falha de interpretação do timestamp, o cliente pode acabar frustrado e perder a confiança no serviço.
2. O Problema de Confiar no Saldo Bancário
Imagine que você realiza um pagamento via cartão ou transferência bancária. Após confirmar a transação, algo inesperado acontece: a resposta demora ou não chega. Você não sabe se o pagamento foi concluído. O que fazer?
Agora, suponha que o sistema bancário tente resolver isso de uma forma simples: em vez de verificar se a transação foi registrada corretamente, ele apenas olha para o saldo da conta:
• Se o saldo diminuiu, significa que o pagamento foi processado.
• Se o saldo ainda está igual, a transação é reenviada.
Embora essa abordagem pareça lógica, ela cria problemas graves:
1️⃣ O saldo pode ainda não ter sido atualizado, mas a transação já foi enviada ao banco. Isso pode levar ao reenvio da cobrança e resultar em um pagamento duplicado.
2️⃣ A transação pode estar pendente e ainda não refletida no saldo. Nesse caso, o sistema pode interpretar erroneamente que o pagamento não ocorreu e tentar processá-lo novamente.
Por Que Isso Causa Problemas em Sistemas Financeiros?
🔹 Race Conditions (Condições de Corrida):
• Se múltiplas transações forem processadas simultaneamente e o sistema depender apenas do saldo para validar pagamentos, ele pode permitir cobranças duplicadas antes da atualização do saldo.
• Exemplo: Um Pix e um pagamento automático são processados ao mesmo tempo. Se o saldo ainda não refletiu a primeira operação, o sistema pode aprovar ambos, mesmo sem fundos suficientes.
🔹 Transações Pendentes:
• Algumas operações levam tempo para serem processadas, como pagamentos internacionais ou transferências entre bancos diferentes.
• Se o sistema só verificar o saldo antes de registrar a transação, ele pode permitir que o usuário gaste o mesmo dinheiro duas vezes enquanto a primeira operação ainda está sendo processada.
🔹 Conversões de Moeda:
• Em contas multimoeda, um usuário pode fazer uma compra em dólares, mas a conversão para a moeda local ainda não foi finalizada.
• Se o sistema basear a decisão no saldo momentâneo, pode aprovar uma nova transação antes de concluir a conversão, levando a uma possível inconsistência.
O Saldo é um Reflexo, Não um Indicador Confiável
O saldo bancário reflete transações já finalizadas, mas não prevê operações em andamento. Depender apenas dele para validar pagamentos pode resultar em erros, pagamentos duplicados e inconsistências financeiras.
A solução correta é garantir que cada transação seja registrada no momento em que ocorre e que qualquer tentativa de reprocessamento seja verificada antes de ser executada. Isso impede cobranças indevidas e garante que uma transação seja realizada uma única vez, independentemente de falhas de comunicação.
3. Usar Hashes das Solicitações: Uma Boa Ideia Mal Implementada
Outra solução que, à primeira vista, parece promissora é usar o hash (uma sequência gerada a partir do conteúdo de uma requisição) para identificar transações duplicadas. A lógica seria algo como: “Se duas requisições têm o mesmo hash, apenas uma será processada.”
Embora tenha um certo apelo técnico, ela pode falhar de várias maneiras:
• Falhas por pequenas alterações: Pequenas diferenças no conteúdo (como um espaço extra em um campo ou um formato diferente de data) podem gerar hashes completamente diferentes, fazendo com que o sistema não identifique duplicatas reais.
• Limitações em sistemas distribuídos: Em sistemas distribuídos, partes diferentes do sistema podem calcular hashes de forma inconsistente devido a diferenças na implementação, fuso horário ou formato de dados.
• Problemas de concorrência: Se o sistema calcular o hash e processar a transação em momentos separados, pode não garantir que apenas uma operação seja concluída. Isso é especialmente perigoso em transações críticas, como pagamentos.
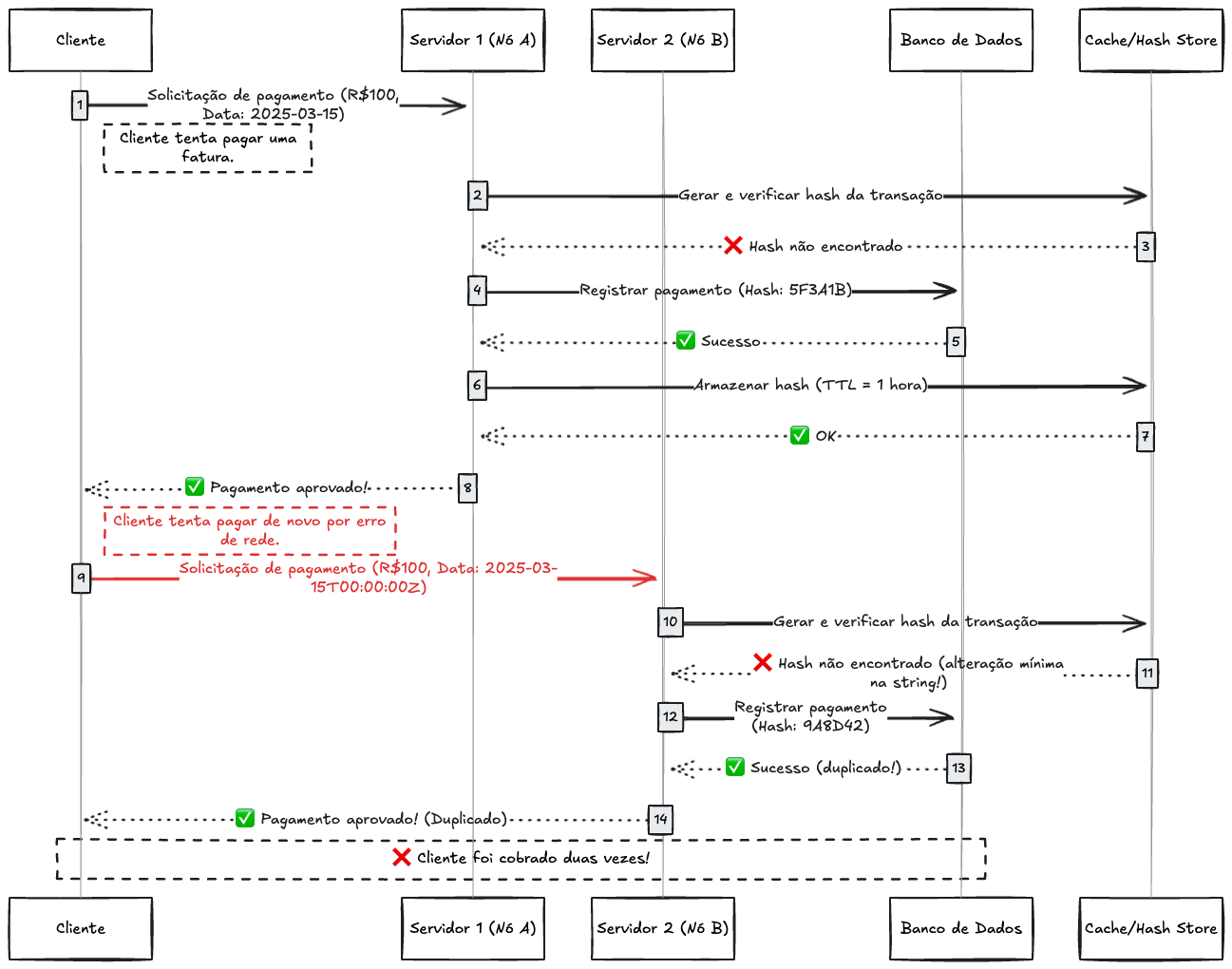
Então parece que não é uma solução segura para levar para frente… vamos continuar a conversar sobre isso.
Essas soluções parecem funcionar bem em cenários pequenos ou controlados, mas, quando aplicadas a sistemas financeiros robustos, podem criar um verdadeiro caos. Imagine tentar pagar uma conta e ser bloqueado porque o sistema achou que sua transação era duplicada. Ou, pior, perceber que seu saldo foi debitado duas vezes porque a lógica de validação era insuficiente.
No mundo financeiro, a confiança do cliente está diretamente ligada à confiabilidade do sistema. Soluções ingênuas podem parecer atraentes no início, mas, como vimos, elas falham porque não consideram a complexidade e as nuances de sistemas distribuídos e altamente concorridos.
Desafios em Sistemas de Pagamento Distribuídos
Sistemas de pagamento distribuídos operam em ambientes complexos, lidando com múltiplos nós, redes instáveis e grandes volumes de dados financeiros. Para garantir transações seguras e consistentes, esses sistemas precisam superar diversos desafios operacionais.
1️⃣ Falhas de Rede e Novas Tentativas
Interrupções de rede, atrasos e perda de pacotes são comuns em sistemas distribuídos, onde servidores podem estar em diferentes locais. Esses problemas podem gerar anomalias como pagamentos em duplicidade.
🔹 Exemplo: Um usuário inicia um pagamento, mas um atraso na rede impede que o servidor receba a solicitação a tempo. O usuário, sem saber o que aconteceu, clica novamente no botão de pagamento. Sem um controle adequado, o sistema pode processar a transação duas vezes, resultando em cobrança duplicada.
2️⃣ Confiabilidade de Armazenamento
Os sistemas de pagamento lidam com grandes quantidades de dados financeiros, tornando a segurança e a integridade dos dados essenciais. Falhas de hardware, corrupção de dados e erros humanos podem levar à perda de informações, comprometendo o funcionamento normal da plataforma.
⚠️ Fatores de risco incluem:
• Falhas de hardware (ex: discos rígidos defeituosos, perda de energia inesperada)
• Bugs de software (ex: vazamento de memória, deadlocks, falhas de concorrência)
• Configurações incorretas e ataques maliciosos que afetam a integridade dos registros
3️⃣ Falhas Ambientais
Além dos desafios técnicos, fatores externos como quedas de energia, variações de temperatura e desastres naturais podem impactar a infraestrutura dos sistemas de pagamento, reduzindo a disponibilidade e afetando a confiabilidade das operações.
Dado que falhas de rede e armazenamento podem causar transações duplicadas ou inconsistências, a idempotência se torna um conceito essencial para garantir que pagamentos não sejam processados mais de uma vez. No próximo tópico, exploramos estratégias para implementar idempotência em sistemas de pagamento distribuídos, garantindo que mesmo diante de falhas, uma transação ocorra apenas uma vez, independentemente de quantas tentativas sejam feitas.
Métodos para Atingir Idempotência em Sistemas de Pagamento Distribuídos
Em sistemas de pagamento distribuídos, garantir que uma mesma transação não seja processada mais de uma vez é essencial para evitar problemas como cobranças duplicadas e inconsistências financeiras. Mas como podemos atingir essa confiabilidade em um ambiente onde falhas de rede, tentativas repetidas e concorrência entre múltiplos servidores são comuns?
Aqui, exploramos as principais estratégias para implementar idempotência, garantindo que um pagamento ocorra uma única vez, independentemente de quantas tentativas sejam feitas.
Uso de um ID de Transação Único (Unique Transaction ID)
Uma das formas mais eficazes de garantir idempotência é incluir um ID de transação exclusivo em cada solicitação de pagamento. Esse ID permite que o sistema verifique se a transação já foi processada antes de tentar executá-la novamente.
🔹 Como funciona?
• Quando um usuário inicia um pagamento, um ID exclusivo (ex: TX123456) é gerado e anexado à solicitação.
• O sistema consulta sua base de dados para verificar se esse ID já foi registrado.
• Se já foi processado, ele simplesmente retorna a resposta anterior sem executar a operação novamente.
• Se não foi encontrado, a transação prossegue normalmente.
💡 Exemplo prático:
Imagine que um cliente realiza um pagamento online e, devido a uma falha na rede, não recebe uma confirmação. Se ele tentar pagar novamente, o sistema verificará o ID da transação original. Se já tiver sido registrado, a operação não será duplicada, e o sistema retornará o status da transação anterior.

Gerenciamento de Estado da Transação
Além de utilizar um ID único, é fundamental rastrear o estado das transações em um banco de dados ou cache distribuído. Isso permite que o sistema sempre saiba se uma transação já foi concluída ou se ainda está em andamento.
🔹 Estados comuns:
• Pendente: A transação foi iniciada, mas ainda não concluída.
• Sucesso: A transação foi processada com êxito.
• Falha: Algo deu errado, e a transação não foi concluída.
🔹 Como isso ajuda na idempotência?
• Antes de executar um pagamento, o sistema consulta o estado da transação.
• Se a transação já estiver marcada como “Sucesso”, ela não será processada novamente.
• Se estiver “Pendente”, o sistema pode evitar concorrência e garantir que apenas uma instância continue a execução.
💡 Exemplo prático:
Um usuário tenta pagar uma conta de energia e a transação fica pendente por alguns segundos. Se ele pressionar o botão de pagamento novamente, o sistema verificará o status e impedirá uma cobrança duplicada.

Abordagens Técnicas para Implementar Idempotência
Além de estratégias de design, há abordagens técnicas que ajudam a garantir idempotência na prática.
a) Transações de Banco de Dados
Ao encapsular operações em transações de banco de dados, garantimos atomicidade e consistência, evitando que pagamentos sejam processados parcialmente.
🔹 Como funciona?
• A operação de pagamento e a atualização do status da transação são realizadas dentro de uma única transação.
• Se a operação falhar em qualquer ponto, um rollback automático ocorre, garantindo que o estado do sistema não fique inconsistente.
💡 Exemplo prático:
Se um pagamento é iniciado, mas o sistema trava antes de concluir a atualização do saldo, um rollback reverte a operação, garantindo que o usuário não seja cobrado parcialmente.

b) Bloqueios Distribuídos
Em sistemas distribuídos, onde múltiplos servidores podem tentar processar a mesma transação simultaneamente, bloqueios distribuídos impedem que isso aconteça.
🔹 Como funciona?
• O sistema adquire um bloqueio baseado no ID da transação antes de processá-la.
• Enquanto um nó detém o bloqueio, outros servidores sabem que a transação já está em andamento e podem aguardar ou simplesmente retornar a resposta do processamento atual.
💡 Exemplo prático:
Se dois servidores tentam processar a mesma solicitação ao mesmo tempo, apenas um conseguirá adquirir o bloqueio, evitando duplicação de pagamento.

c) APIs Idempotentes
Vamos direto ao ponto aqui:
1️⃣ A API recebe uma solicitação de pagamento e gera um ID de transação único.
2️⃣ Antes de processar a solicitação, a API consulta o banco de dados ou um cache para verificar se esse ID já existe.
3️⃣ Se o ID já foi processado anteriormente, a API retorna a mesma resposta, garantindo que a operação não seja repetida.
4️⃣ Se um novo ID for gerado, a API trata como uma nova transação legítima e segue com o processamento normalmente.
💡 Exemplo prático - Como a API diferencia requisições duplicadas de uma nova intenção de pagamento?
Imagine que um usuário deseja transferir R$100 para outra conta e submete a requisição pela primeira vez.
🔹 Caso 1 - Requisição duplicada (idempotência ativa)
• O usuário não recebe uma resposta da API devido a uma falha na rede e tenta reenviar a mesma solicitação.
• Como a requisição original já contém um ID único (ex: TX123456), a API verifica seu banco de dados (ou em cache) e percebe que a transação já foi processada.
• A API retorna a mesma resposta original, evitando que o dinheiro seja enviado duas vezes.
🔹 Caso 2 - O usuário quer realmente enviar outro pagamento
• Se o usuário decidir transferir mais R$100 adicionais, o sistema deve gerar um novo ID de transação (ex: TX7891011).
• Como esse ID ainda não existe no banco de dados, a API processa a nova solicitação normalmente.
✅ Dessa forma, a API garante que uma transação seja realizada apenas uma vez, mas permite novas operações legítimas sempre que necessário.

Ao implementar IDs de transação únicos, gerenciamento de estado, transações atômicas, bloqueios distribuídos e APIs idempotentes, podemos construir sistemas de pagamento distribuídos confiáveis e resilientes.
Agora que implementamos a idempotência… bora falar do custo disso?
Já vimos como idempotência pode salvar nossos sistemas de pagamentos duplicados e inconsistências. Agora, vem a parte que poucos falam logo de cara: quanto custa armazenar todas essas chaves de idempotência?
Se você está pensando em guardar tudo no banco de dados tradicional, pode estar prestes a criar um problema de escalabilidade. Afinal, a cada requisição POST ou PATCH que precisa ser idempotente, você gera um UUID e armazena para garantir que, caso a mesma requisição seja feita de novo, o sistema retorne a resposta correta sem reprocessar.
Mas já parou para pensar no impacto disso? Vamos destrinchar os desafios de armazenamento, custo de consulta e a melhor estratégia para lidar com essas chaves de idempotência.
UUIDs são pesados para armazenar em banco de dados
Os UUIDs são strings longas e aleatórias (geralmente com 36 caracteres), o que significa que armazená-los ocupa muito mais espaço do que chaves inteiras autoincrementadas. Agora, pense nisso em grande escala:
🔹 Se seu sistema processa 1 milhão de transações idempotentes por dia, são 1 milhão de UUIDs armazenados apenas para evitar duplicação.
🔹 Como essas chaves precisam ser verificadas sempre que uma nova requisição chega, o índice da tabela cresce rapidamente, tornando as consultas mais lentas.
🔹 Diferente de um ID incremental, que fica ordenado no banco, UUIDs são aleatórios, o que pode gerar fragmentação nos índices e piorar a performance das buscas.
Em resumo? Se você insistir em guardar todas as chaves no banco sem expiração, seu sistema pode começar a engasgar.
Consultar um UUID no banco pode ser mais caro do que parece
Além do custo de armazenamento, tem o custo das consultas. Como os UUIDs são valores dispersos no índice, cada busca pode resultar em varreduras mais caras.
Se você está rodando uma aplicação de alta escala, um simples:
SELECT * FROM idempotency_keys WHERE key = 'TX123456-UUID';Pode se tornar uma consulta cara quando a tabela cresce. E não queremos que cada verificação de idempotência consuma mais recursos do que deveria, né?
Por isso, evitar consultas constantes ao banco de dados é essencial para manter a escalabilidade do sistema.
Cache é o nosso melhor amigo (com um TTL bem definido!)
Ao invés de encher o banco de dados com milhões de chaves de idempotência que não precisam durar para sempre, a solução ideal é usar um cache distribuído, como Redis ou Memcached, com um tempo de expiração (TTL – Time To Live).
🔹 Por que usar cache?
• O cache é muito mais rápido do que um banco SQL tradicional para buscar uma chave.
• Ele evita consultas desnecessárias no banco, reduzindo o custo operacional.
• Como as chaves de idempotência só são relevantes por um período curto de tempo, elas podem ser descartadas automaticamente após um tempo definido.
🔹 Como configurar o TTL?
O ideal é que a chave de idempotência dure tempo suficiente para cobrir as tentativas de reenvio do usuário. Alguns exemplos:
• Se o usuário pode reenviar a requisição dentro de 1 minuto, configure o TTL para um tempo maior que seja coerente e seguro para seu contexto de negócio.
• Se a idempotência precisa durar por uma sessão de usuário, pode ser entre 5 minutos e 1 hora.
• Em cenários mais críticos, pode durar até 24 horas.
💡 Exemplo de implementação no Redis:
SET idempotency:TX123456 "processed" EX 3600 # Chave expira em 1 hora✔ Assim, o backend pode verificar rapidamente se uma chave já foi usada sem precisar consultar o banco de dados.
🔹 E se o cache for reiniciado ou perder as chaves?
• Se o cache perder as chaves, o backend ainda pode consultar o banco como fallback, mas com um TTL muito mais longo.
• Para evitar isso, replicar o cache entre nós distribuídos pode ser uma solução eficiente.
Mas e se alguém tentar burlar o sistema e reutilizar um UUID expirado?
Se o TTL expirar, a chave some do cache e o backend pode aceitar uma nova requisição. Isso pode ser um problema se um usuário malicioso tentar reutilizar um UUID depois que ele expirou.
✅ Solução: O backend pode manter um histórico mínimo de UUIDs utilizados em um banco de dados de longo prazo, mas sem impactar a performance. Isso pode ser feito armazenando apenas as chaves mais críticas, enquanto as outras expiram normalmente.
Grandes players já fazem isso
Aplicações como Twitter e Instagram usam idempotência para evitar duplicação de postagens e interações. E, claro, eles não armazenam UUIDs para sempre.
Eles adotam cache com TTL e um banco de dados otimizado para armazenar apenas as transações realmente necessárias. Dessa forma:
✔ Evitam a sobrecarga no banco de dados principal.
✔ Mantêm a idempotência sem precisar guardar milhões de UUIDs indefinidamente.
✔ Conseguem lidar com milhões de requisições por segundo de forma eficiente.
O Segredo Está no Equilíbrio
Se você está lidando com idempotência e precisa armazenar chaves de forma escalável, NÃO jogue tudo no banco de dados sem um plano.
✅ Evite armazenar UUIDs no banco por tempo indefinido – isso gera um custo alto de armazenamento e consultas lentas.
✅ Use cache (Redis, Memcached) para guardar chaves temporariamente e acelerar as verificações.
✅ Configure um TTL adequado para liberar espaço automaticamente quando a chave não for mais necessária.
✅ Use o banco de dados apenas para registros críticos, e não para cada tentativa de requisição idempotente.
No final do dia, o equilíbrio entre banco, cache e TTL garante um sistema eficiente, rápido e escalável. 🚀
Atomicidade e Idempotência: O Casamento Perfeito nos Sistemas Distribuídos
Já falamos anteriormente sobre idempotência, mas agora vamos reforçar um conceito que anda de mãos dadas com ela: atomicidade. Se você quer construir sistemas distribuídos robustos, entender como essas duas ideias se complementam pode salvar seu backend de inconsistências e dores de cabeça.
Relembrando o Que É Atomicidade
A atomicidade vem do conceito de ACID (Atomicidade, Consistência, Isolamento e Durabilidade) usado em bancos de dados. Em termos simples, significa que uma operação deve ser totalmente concluída ou completamente descartada – não pode ficar pela metade.
💡 Exemplo simples: Imagine que você está transferindo R$100 de uma conta para outra.
1️⃣ O sistema deve debitar R$100 da Conta A.
2️⃣ O sistema deve creditar R$100 na Conta B.
3️⃣ Se algo falhar entre esses passos, a transação deve ser revertida, para que nenhuma conta fique com saldo incorreto.
Se o sistema permitir que apenas um desses passos aconteça, teremos um problema: dinheiro pode simplesmente “sumir” ou ser duplicado.
Como a Atomicidade Se Relaciona com Idempotência?
A idempotência evita que uma mesma operação seja executada mais de uma vez.
Mas a atomicidade garante que, se ela for executada, será feita de forma completa e consistente.3
Vamos conectar esses dois conceitos com um cenário prático.
💡 Exemplo 1: Pagamentos Online
1️⃣ Um cliente realiza um pagamento de R$100.
2️⃣ A API de pagamento verifica a chave de idempotência para evitar duplicatas.
3️⃣ O sistema inicia a transação no banco de dados.
4️⃣ O dinheiro deve ser debitado da conta do cliente e creditado na conta do vendedor.
5️⃣ Se qualquer parte falhar (ex: erro ao creditar na conta do vendedor), o sistema faz um rollback, cancelando tudo.
Aqui, a idempotência evita cobranças duplicadas caso o cliente envie a requisição várias vezes, enquanto a atomicidade impede que um pagamento fique em um estado inconsistente.
💡 Exemplo 2: Criando uma Ordem de Compra
1️⃣ O cliente adiciona um produto ao carrinho e confirma a compra.
2️⃣ O sistema gera um ID único para garantir idempotência.
3️⃣ O backend cria um registro da compra e reserva o estoque.
4️⃣ Se houver qualquer erro no meio do caminho (ex: falha ao reservar o estoque), o sistema desfaz a criação da compra.
Sem atomicidade, poderíamos ter um pedido registrado sem estoque reservado – um erro que geraria cancelamentos e frustração para o cliente.
Atomicidade e Sistemas Distribuídos: Como Garantir Que Tudo Funcione Certo?
Em sistemas distribuídos, garantir atomicidade é um grande desafio. Diferente de um sistema monolítico, onde um único banco de dados cuida de todas as operações, em um ambiente distribuído temos múltiplos serviços, filas de mensagens, caches e APIs externas trabalhando juntos.
Agora, imagine que você está tentando garantir que todas essas peças do quebra-cabeça funcionem de forma sincronizada. Como garantir que se algo der errado, não fiquemos com um sistema quebrado, com dados inconsistentes e operações pela metade?
Aqui estão três estratégias que podem nos ajudar a manter atomicidade em sistemas distribuídos.
Two-Phase Commit (2PC): O “Confirma ou Cancela” das Transações Distribuídas
Pensa em um grupo de amigos tentando decidir onde jantar. Você manda uma mensagem:
“Bora no restaurante X?”
Se todos responderem “Sim”, a reserva é feita. Se alguém disser “Não”, nada acontece.
O Two-Phase Commit (2PC) segue a mesma ideia. Ele garante que todas as partes envolvidas em uma transação concordem antes de qualquer alteração ser feita.
🔹 Como funciona?
Fase 1 - “Preparação” (Prepare Phase):
• Um coordenador (que pode ser um banco de dados distribuído, um gerenciador de transações ou um serviço de negócios) pergunta para todos os serviços envolvidos:
“Vocês estão prontos para processar essa transação?”
• Cada serviço (bancos de dados, APIs externas, sistemas distribuídos) verifica se pode executar a operação e responde:
✅ “Sim” (se puder processar)
❌ “Não” (se houver um problema)
Quem Pode Ser o Coordenador?
O coordenador pode variar dependendo da arquitetura do sistema:
✅ Banco de Dados Distribuído → Se a transação envolver apenas múltiplos nós de um banco distribuído, o próprio banco pode atuar como coordenador.
• Exemplos: Google Spanner, CockroachDB, MySQL Cluster.
✅ Gerenciador de Transações → Em sistemas mais complexos, um middleware gerencia a transação distribuída.
• Exemplos: Postgres Two-Phase Commit, Oracle XA.
✅ Serviço de Negócios (Orquestrador de Transações) → Se diferentes serviços estiverem envolvidos, um sistema de pagamento ou ERP pode atuar como coordenador.
• Exemplos: Apache Camel, Temporal.io, NestJS com Sagas ou até API's preparadas para esse tipo de função:

📌 O importante é que o coordenador seja responsável por garantir que todos os participantes concordem antes de confirmar ou cancelar a transação.
Fase 2 - “Confirmação ou Cancelamento” (Commit or Rollback Phase):
• Se todos responderam “Sim”, a transação é confirmada e processada em todos os serviços.
• Se qualquer um responder “Não”, a transação é cancelada em todos os serviços para evitar inconsistências.

🧐 Onde isso é útil?
• Bancos de dados distribuídos que precisam garantir que múltiplos nós atualizem os dados de forma consistente.
• Sistemas financeiros, onde um pagamento só pode ser concluído se o débito e o crédito forem bem-sucedidos.
❌ Limitação: O 2PC pode ser lento, pois cada serviço precisa aguardar a resposta de todos os outros antes de continuar. Se um serviço trava no meio do caminho, pode bloquear o sistema por um tempo.
Mensageria com Garantia de Processamento: Cada Passo no Seu Tempo
Às vezes, não podemos esperar que tudo aconteça ao mesmo tempo. Em vez disso, podemos quebrar uma operação complexa em várias partes e garantir que cada etapa seja concluída na sequência certa.
Aqui entram os eventos assíncronos e filas de mensagens (como Kafka, RabbitMQ ou SQS), que garantem que cada passo só acontece depois que o anterior for concluído.
🔹 Como funciona?
• O sistema não executa tudo de uma vez. Em vez disso, cada serviço escuta eventos e age quando for sua vez.
• Se uma etapa falhar, a mensagem pode ser reenviada até ser processada corretamente.
Exemplo prático:
Imagine um e-commerce processando um pedido:
1️⃣ O cliente finaliza a compra.
2️⃣ Um evento “Criar Pedido” é enviado para uma fila de mensagens.
3️⃣ O serviço de pagamento escuta esse evento, processa o pagamento e emite um novo evento “Pagamento Confirmado”.
4️⃣ O serviço de estoque escuta esse evento e reduz a quantidade disponível do produto.
5️⃣ O serviço de logística então recebe um evento para preparar o envio.
Se qualquer passo falhar, a mensagem pode ser processada novamente até dar certo.
✔ Vantagem: O sistema fica mais resiliente, pois não precisa depender de tudo acontecer ao mesmo tempo.
❌ Desafio: Precisamos garantir que não haja processamento duplicado, caso uma mensagem seja reenviada. (Aí entra a idempotência!)
Compensação em Caso de Falha: O “Desfaz Tudo” das Transações Distribuídas
Agora, imagine que você faz um pedido num aplicativo de delivery. O pagamento foi processado, o restaurante começou a preparar a comida… e de repente o sistema falha! O que fazer?
🔹 Aqui entra o conceito de “compensação”: se um processo não pode ser concluído, precisamos desfazer tudo que já foi feito.
Analogia rápida:
Pensa em um dominó caindo. Se você percebe que derrubou a peça errada, precisa levantar as peças anteriores para voltar ao estado inicial.
🔹 Como funciona?
• Em vez de tentar garantir que nada falhe, assumimos que falhas vão acontecer e criamos um processo para reverter operações caso necessário.
• Cada ação importante tem uma ação reversa correspondente.
Exemplo prático:
No caso do pedido no app de delivery, o sistema pode funcionar assim:
1️⃣ O pagamento foi feito ✅
2️⃣ O restaurante começou a preparar a comida ✅
3️⃣ O sistema falha antes do pedido ser enviado ❌
O que fazer?
• O serviço de pagamentos pode reembolsar o cliente automaticamente.
• O restaurante pode ser notificado para descartar o pedido e evitar desperdício.
Esse modelo de compensação é chamado de SAGA – um padrão arquitetural muito usado em sistemas distribuídos para garantir que ações possam ser desfeitas se algo der errado.
✔ Vantagem: Mesmo que uma falha aconteça, o sistema pode se recuperar sem deixar rastros quebrados.
❌ Desafio: Precisamos definir claramente como desfazer cada tipo de operação.
Como Escolher a Melhor Estratégia?
✅ Se você precisa garantir que tudo aconteça ao mesmo tempo (ou nada aconteça) → Use Two-Phase Commit (2PC).
✅ Se o sistema pode processar partes separadamente e garantir a ordem dos eventos → Use Mensageria e Fila de Mensagens.
✅ Se você quer um sistema flexível que possa desfazer operações quando algo falha → Use Compensação (Sagas).
Cada estratégia tem seu lugar e sua aplicação ideal. O mais importante é entender quando faz sentido usar cada uma e garantir que seu sistema seja resiliente, confiável e escalável. 🚀
Bora pra um breve resumo?
✅ Idempotência impede operações duplicadas.
✅ Atomicidade garante que as operações sejam concluídas por inteiro ou não aconteçam.
✅ Em sistemas distribuídos, combinar esses dois conceitos evita inconsistências e falhas de integridade.
Se você quer que seu sistema seja resiliente, confiável e seguro, idempotência + atomicidade são dois princípios que não podem faltar.
Ufa, quanta coisa interessante conversamos!
Aqui vai a grande sacada: idempotência não é só sobre código, é sobre confiabilidade.
Quando falamos de sistemas distribuídos, APIs e transações críticas, estamos lidando com expectativas reais de usuários e dinheiro de verdade fluindo entre serviços. Uma falha simples pode duplicar um pagamento, corromper dados ou gerar frustração, minando a confiança no sistema. E é por isso que idempotência é um conceito essencial para qualquer desenvolvedor que quer construir sistemas escaláveis e resilientes.
A Profundidade do Conceito Vai Muito Além
Se tem algo que este artigo deixou claro, é que não basta saber a definição de idempotência. É preciso entender quando e como aplicá-la corretamente.
🔹 Nem toda operação precisa ser idempotente, mas quando precisa, precisa mesmo!
🔹 Ferramentas como caches, bloqueios distribuídos e controle de estado fazem parte do jogo.
🔹 A forma como armazenamos e verificamos chaves de idempotência pode impactar diretamente a performance do sistema.
E como vimos, não existe uma única abordagem correta – há desafios e compensações em cada estratégia, e o segredo está em escolher a que faz mais sentido para o seu cenário.
O Próximo Passo
Agora que você tem essa bagagem, que tal aplicar?
✅ Revise seus sistemas atuais e veja onde a idempotência pode (ou deveria) ser implementada.
✅ Experimente diferentes abordagens – cache com TTL, storage no banco, UUIDs ou hash das requisições.
✅ Teste cenários extremos, como falhas de rede e reenvio de requisições, e veja se sua implementação realmente evita duplicação.
No fim das contas, entender idempotência te ajuda a escrever sistemas mais seguros, escaláveis e confiáveis. E acredite: essa é uma habilidade que faz toda diferença na carreira de um desenvolvedor.
Eu agradeço DE CORAÇÃO você ter lido até o final! Grande abraço! ❤️
Outros artigos sobre o tema:
https://martinfowler.com/articles/patterns-of-distributed-systems/two-phase-commit.html
https://medium.com/geekculture/distributed-transactions-two-phase-commit-c82752d69324
https://www.baeldung.com/cs/two-phase-commit-vs-saga-pattern
Uma analogia que funciona muito bem é a de usar um carimbo com tinta para selar um envelope já marcado. Uma vez que o carimbo foi aplicado e deixou sua marca, continuar carimbando no mesmo local não muda o resultado — o selo está lá, do mesmo jeito.
O que são métodos seguros?
Métodos seguros são aqueles que não alteram o estado do servidor. Eles garantem que uma requisição ao servidor não causará nenhuma modificação nos dados armazenados. Pense nesses métodos como “ações de consulta” ou “operações de leitura”. Por isso, eles são frequentemente usados em cenários onde você só precisa buscar ou verificar informações.
No HTTP, o principal exemplo de método seguro é o GET.
• GET: É usado para recuperar recursos (dados) sem alterar nada no servidor. Imagine buscar informações sobre um produto em um site de e-commerce. Você pode fazer isso quantas vezes quiser, e o estado do servidor continuará o mesmo. Por isso, o GET é seguro e também idempotente, porque múltiplas requisições não alteram o estado do sistema.
Outro método que pode ser considerado seguro em algumas implementações é o HEAD. Ele é como um GET, mas retorna apenas os metadados do recurso, sem o corpo da resposta.
E quanto aos outros verbos HTTP?
Agora que entendemos os métodos seguros, vamos falar de idempotência nos verbos HTTP. Aqui, a idempotência não tem a ver com segurança, mas sim com a garantia de que múltiplas requisições idênticas produzirão o mesmo efeito no estado do servidor. Vamos explorar isso com exemplos claros:
GET: Seguro e idempotente
• Por que é seguro? Não altera nada no servidor, apenas consulta informações.
• Por que é idempotente? Você pode chamar o mesmo GET várias vezes, e o servidor sempre retorna o mesmo resultado (supondo que os dados no servidor não mudaram por outro motivo).
Exemplo prático: Consultar o saldo de uma conta bancária. A consulta não altera o saldo e sempre retorna o mesmo valor enquanto não houver outra operação.
PUT: Não é seguro, mas é idempotente
• Por que não é seguro? Ele modifica o estado do servidor, porque geralmente é usado para substituir ou atualizar um recurso.
• Por que é idempotente? Se você enviar a mesma requisição PUT várias vezes, o resultado no servidor será sempre o mesmo: o recurso será atualizado para o estado fornecido na requisição.
Exemplo prático: Atualizar o endereço de um cliente. Mesmo que a requisição seja enviada duas vezes, o endereço final será o mesmo.
DELETE: Não é seguro, mas é idempotente
• Por que não é seguro? Ele altera o estado do servidor, porque apaga um recurso.
• Por que é idempotente? Se o recurso já foi deletado na primeira requisição, as chamadas subsequentes não têm efeito. O recurso continua ausente, e o estado do servidor não muda.
Exemplo prático: Apagar um arquivo no sistema. Depois que ele é excluído, novas tentativas de DELETE para o mesmo arquivo não farão diferença.
POST: Não é seguro, nem idempotente
• Por que não é seguro? Ele modifica o estado do servidor, geralmente criando um novo recurso.
• Por que não é idempotente? Cada requisição POST normalmente resulta em uma nova criação no servidor. Enviar duas requisições POST idênticas pode criar dois recursos diferentes (ou duplicados).
Exemplo prático: Criar um novo pedido em um e-commerce. Se o usuário clicar duas vezes no botão “Comprar”, dois pedidos podem ser criados.
PATCH: Não é seguro e geralmente não é idempotente
• Por que não é seguro? Ele altera o estado do servidor, porque é usado para modificar partes de um recurso.
• Por que não é idempotente? Depende da implementação. Em geral, múltiplas requisições PATCH podem produzir resultados diferentes, já que ele modifica apenas campos específicos, e os valores podem ser incrementais ou dependentes do estado atual.
Exemplo prático: Atualizar apenas o número de telefone de um cliente. Se o PATCH for enviado duas vezes, com valores diferentes, o recurso pode acabar em um estado imprevisível.
Como diferenciar segurança e idempotência?
1. Métodos seguros (como GET e HEAD) não alteram o estado do servidor e são ideais para operações de consulta.
2. Métodos idempotentes (como PUT, DELETE e, em alguns casos, PATCH) podem alterar o estado do servidor, mas garantem que múltiplas requisições idênticas produzirão o mesmo resultado.
3. Métodos não seguros e não idempotentes (como POST) devem ser usados com cuidado, pois podem causar duplicatas ou modificações indesejadas.
Por que isso é importante?
Entender esses conceitos ajuda no design e na integração de APIs:
• GET: Seguro para consultas, sem efeitos colaterais.
• PUT e DELETE: Idempotentes, garantindo consistência mesmo em situações de repetição.
• POST: Requer cuidado adicional, como o uso de chaves de idempotência, para evitar duplicações.
• PATCH: Precisa ser usado com atenção para não criar estados inconsistentes.
Essas definições afetam diretamente a confiabilidade e a experiência de uso dos sistemas que projetamos.
Pense em quando as pessoas depositavam cheques no banco.
• Idempotência: Se você fosse ao banco e, por engano, tentasse depositar o mesmo cheque duas vezes, o sistema do banco deveria garantir que o valor fosse creditado apenas uma vez na sua conta, evitando duplicação do depósito.
• Atomicidade: Agora, imagine que o cheque foi aceito, mas, no meio do processamento, o banco teve um problema e caiu o sistema. A atomicidade garante que ou o valor inteiro entra na sua conta, ou nada acontece—evitando que só metade do dinheiro seja registrada ou que o cheque fique numa situação inconsistente.