
Is it easy to maintain?
Maintenance cost is one of the biggest costs of a software system. Don't write software you can't maintain. - Robert C. Martin.

Maintainable code - that's a phrase you hear a lot in the software industry. However, what does it really mean and why is it so important? Let's comment and discuss this topic!
What does it mean?
According to the Oxford Language Dictionary, maintenance is defined as:
Action or effect of maintaining or conserving.
Action to make something remain, last.
Regular or periodical conservation work.
We see that the word "maintenance", at its core, is a comprehensive concept that encompasses a variety of activities, from fixing bugs to implementing new features. In the software industry, maintenance is an ongoing process that occurs throughout the lifetime of a system. And by "ease" we are referring to reducing the complexity and effort required to perform such maintenance activities.
Now, if we take it to software engineering, we are referring to the practice of creating code that can be easily understood, tested, modified and extended. It is the principle of producing software that is not only functional, but also of quality, efficient and, above all, sustainable in the long term.
But why is code maintenance so crucial? The answer is clear. Software development is not a static process but a dynamic journey. As requirements change, new functionality is needed, or defects are discovered, the code needs to evolve. And here comes the need for efficient maintenance.
If code is difficult to maintain, every change becomes a time- and resource-consuming challenge, with the constant risk of introducing new bugs.
Why care about maintenance?
Imagine for a moment that you have just purchased a new car. However, even though it is such an impressive machine, over time it will need regular maintenance to ensure that it continues to function well. If we ignore maintenance - oil changes, wheel alignments, brake checks, and so on - chances are our beautiful car will start to malfunction.
Just like cars, any software needs regular maintenance too. As the software is used, modified and evolves, new requirements arise and old ones may change or undergo minor adaptations. Also, bugs need to be fixed, after all there is no system that does not contain bugs.
Here is where the importance of software maintenance really shines through. Maintainable code not only makes these unavoidable tasks less onerous, it can also significantly improve the overall quality of the software. Maintaining quality over time means fewer bugs, less downtime, and ultimately, more satisfied users.
Herein lies the real challenge: the software is not just about what it can do at the beginning, but how well it can reliably transform and evolve over time. Therefore, software maintenance should be a priority.
But what should be easy to maintain? When we talk about code maintainability, we are referring to several code units, from the smallest ones like functions or methods, to bigger units like classes, modules, components and even entire systems.
Think of software as a city. The functions and methods would be houses and buildings, the classes would be blocks, the components would be neighborhoods, and the complete system would be the city itself. Now, think of a city that is easy to maintain. The houses and buildings are well designed and constructed, which reduces the need for frequent repairs. The blocks have adequate infrastructure, such as access to water, electricity and sanitation, which makes life easier for the inhabitants. The neighborhoods are well planned, with easy access to services and commerce, and the city as a whole has a good transport system and efficient public services.
Now think about it for our context, functions and methods should be small and have a single responsibility (SRP principle). This makes it easier to understand what they do and, if necessary, we can change their behavior, extend or fix a bug without affecting other parts of the software.
Classes should also have clearly defined responsibilities and should be designed in such a way that they are cohesive (i.e. the methods and properties within the class are closely related) and loosely coupled (i.e. the class does not heavily depend on other classes) .
Components or modules, which are groups of classes that work together to provide certain functionality, must also be designed with maintainability in mind. This means that they must be self-contained and able to function independently of other components as much as possible. We will comment on this a little more in depth.
Four essential characteristics for any class!
Clarity: Undoubtedly one of the most important features of an easily maintained class. A clear class has a name that effectively expresses its purpose, methods that are named after the operations they perform, and comments that clarify the most intricate parts of the code. If reading a class gives us an immediate understanding of its role in the overall system, then we have a strong indication that it is a clear class. Benefits of this approach include making it easier to onboard new developers to the project and reducing the amount of time spent trying to understand what the class does.
Cohesion: An easy-to-maintain class is also highly cohesive, meaning that it has a well-defined responsibility. For programmers, cohesion refers to the extent to which the elements of a class belong together. A cohesive class does one thing and does it well, which makes it easier to understand, test, and modify. Cohesion promotes modularity and code reuse, as a class that performs a single task can be used in multiple contexts without changes.
Loose coupling: Refers to the interdependence between classes. An easy-to-maintain class is loosely coupled, that is, it is independent and does not depend heavily on other classes. This allows changes to be made to a class without affecting other parts of the system. Loose coupling is beneficial as it helps isolate parts of the system, making the code easier to understand, test, and change.
Encapsulation: It is a principle that allows hiding the internal complexity of components and exposing only necessary operations and attributes for interaction with other components. A well-encapsulated class is like a black box: we know its inputs and outputs, but we don't need to understand its inner workings in detail to use it. This favors the clarity of the code, makes it more secure and less prone to errors, as the internal implementation details are 'protected' from direct access and manipulation. Furthermore, encapsulation makes the system more flexible, because if the internal details of a class need to be changed, that change does not directly affect other parts of the code that use that class.
By combining these four traits, we've created a scenario where code maintenance becomes a less daunting and more manageable task. This increases team productivity too! These attributes are essential. But let's take a closer look at the third and fourth, loose coupling and encapsulation.
Be careful with the coupling!
When we talk about loose coupling, we are referring to a scenario where classes have few dependencies, that is, a class doesn't need to know much about other classes to work. Let's see this in practice, but instead, let's use a bad example, so everyone can understand how serious tight coupling is:
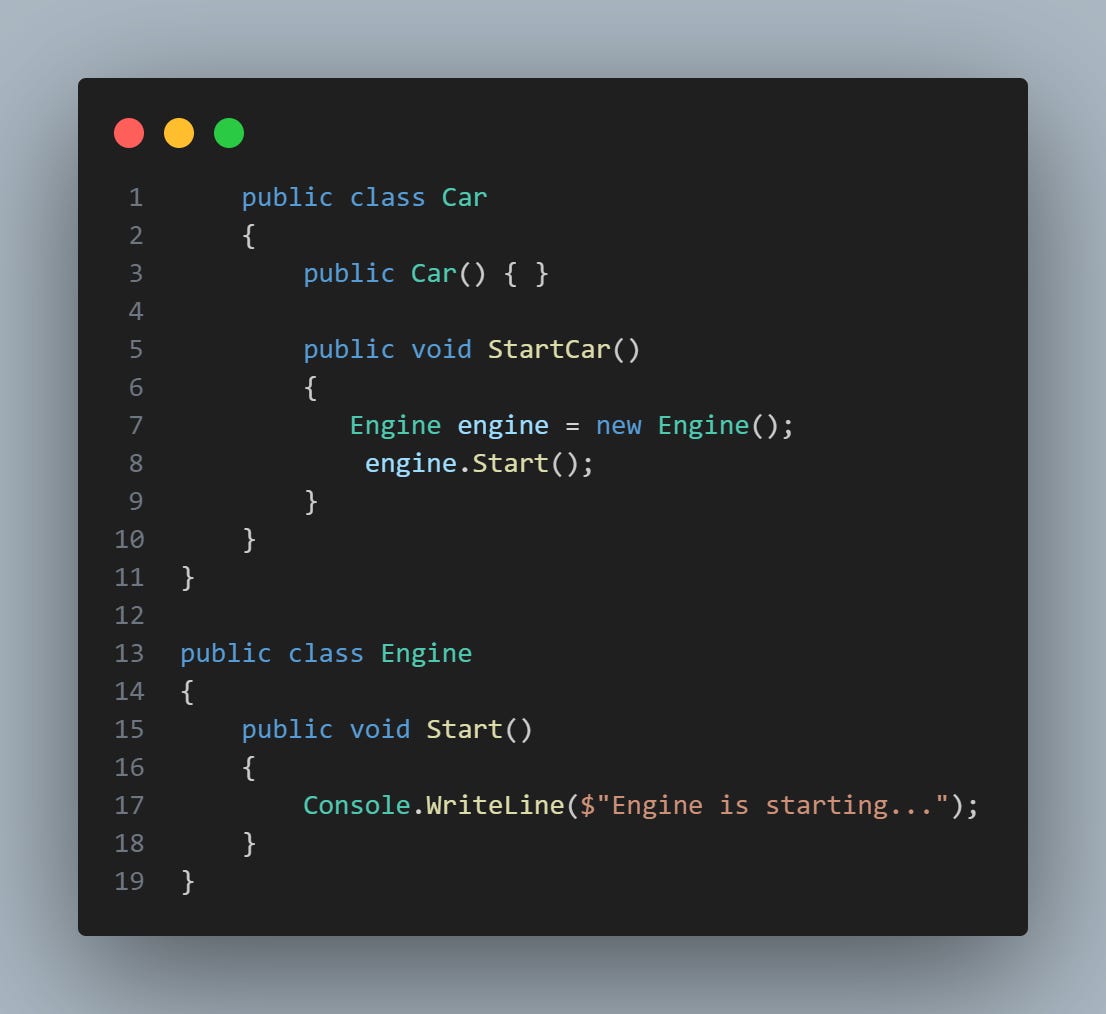
Here, the Car class is tightly coupled with the Engine class. That is, the Car class has a high level of dependence on the Engine class, because it creates an instance of Engine directly inside the StartCar method.
This presents a problem, as any change to the Engine class can affect the Car class. Also, it's difficult to test the Car class in isolation, because the StartCar method always creates a new instance of Engine, so you can't test the StartCar method with a simulated (or "mock") instance of Engine.
This can be problematic on a larger system where the Engine class can have its own dependencies and can be complex to configure for testing. It also makes the system as a whole less flexible, because you can't, for example, replace Engine with a different version or an entirely different implementation without changing the Car class.
I'd like to demonstrate how a change to the Engine class can impact the Car class in the example I've provided. Let's think that for some reason the Engine class needs to be modified to require a fuel type at startup time:

Now notice what happens in the Car class:
The error in the IDE alerts us:

⚠️ There is no argument provided that matches the required 'fuelType' parameter of 'Engine.Engine(string)'.
This error occurs when we try to create a new instance of the Engine class without providing an argument for its constructor that requires a string parameter for the fuelType. But you might be thinking:
"But that's easy to solve, just create an empty constructor... right?"
Creating an empty constructor for the Engine class would not completely solve the coupling problem. The situation in which the Car class is responsible for instantiating Engine persists, creating a direct coupling between the two classes.
This means that if the process of creating an Engine becomes more complex in the future (for example, if the Engine needs other dependencies to be instantiated), we will have to change the Car class to accommodate these changes. This goes against the principle of single responsibility and can lead to code that is more difficult to maintain and test.
Ideally, we'd like to have a situation where Car simply receives an already-built Engine that it can use, without having to worry about the details of how it's created. This is something dependency injection helps us achieve.
Let's explain this more deeply and with an analogy.
The advantages of the DI
Dependency injection is a technique used in object-oriented programming that allows a class to delegate the responsibility of creating its dependencies to an external entity. This inversion of control increases flexibility and makes the class easier to test and maintain. How does it happen? See more details in the footnote. 1
I will try to make an analogy so that the explanation is clearer in your mind. Imagine a class as being a house. If the household is responsible for managing its own outbuildings—say, producing its own electricity or purifying its own water—any problem or change in those outbuildings could affect the entire house. For example, if the generator that produces the electricity fails, the house is in darkness. Furthermore, if we decide to change the energy source, perhaps from a generator to solar energy, the house must be adapted to deal with this.
Now, let's think about a house that, instead of managing these dependencies internally, is connected to the electricity grid and the water network. The house doesn't care about how electricity is produced or water is purified. She simply "uses" these resources. If we decide to change the energy source to solar energy, we don't need to change anything in the house. The change takes place at the network level.
This is similar to DI. Instead of a class being responsible for creating and managing its own dependencies, those dependencies are "injected" into it from the outside. This means that the class doesn't have to worry about the details of how these dependencies are created or how they might change over time. For example. Rather than creating an Engine directly, the Car class would declare that it needs an Engine (usually via the constructor or a setter method), and then some external entity would be responsible for providing (or "injecting") the appropriate Engine.
Let's go back to the first example and perform the fitting and decoupling the class:

The small snippet below shows how the decoupling is visible:
Engine engine = new Engine("Gasoline");
Car car = new Car(engine);
car.Drive();Therefore, dependency injection is an essential technique that helps make your code more modular, flexible and testable.
Obviously it doesn't stop there. We can use interfaces (contracts) to do this as well. So for this case the difference is that the Engine class implements an interface for example IStarter. And we just need to call the interface in the Car class:
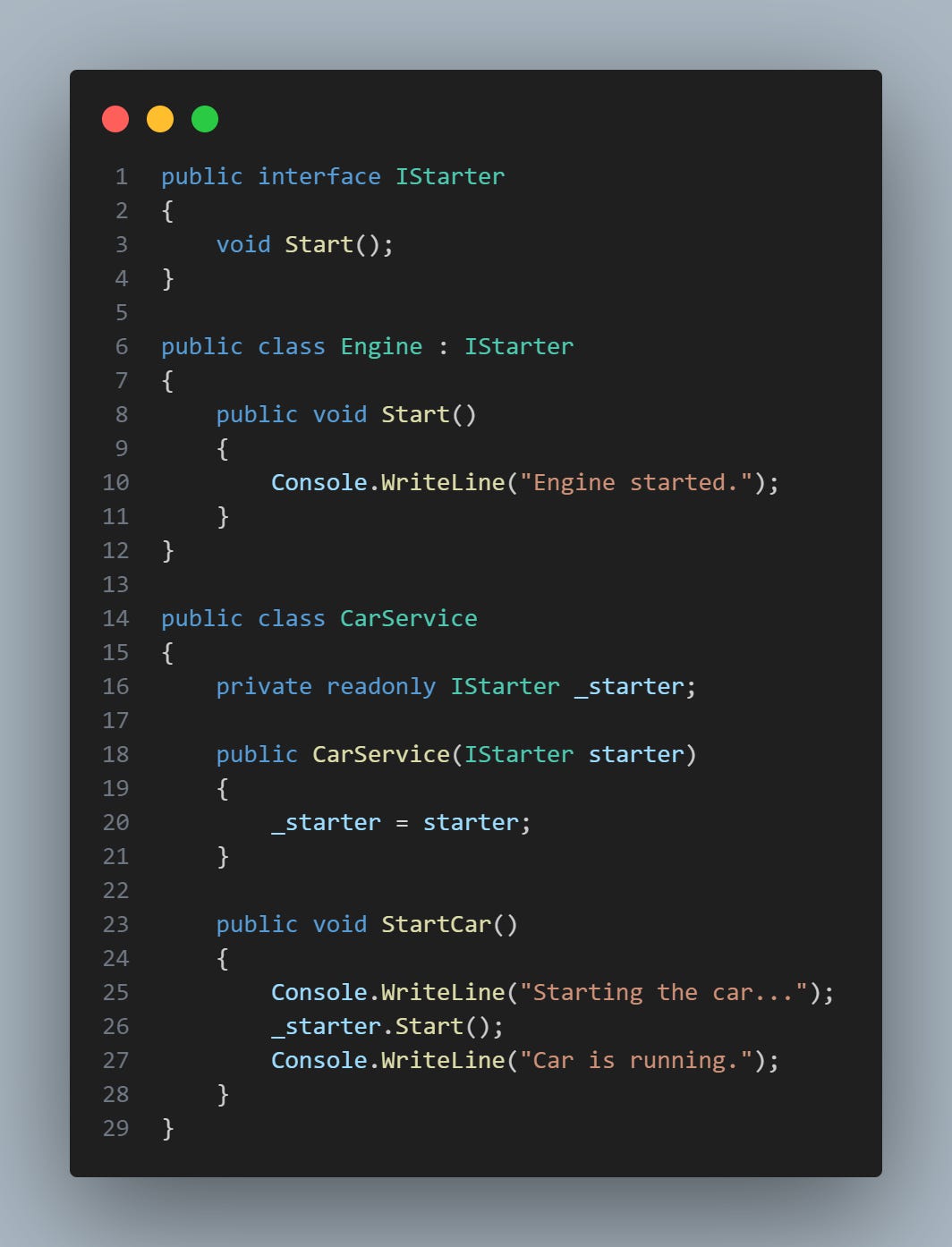
The choice between these two approaches will depend on the specific needs of your project and architecture.
For a more detailed explanation, read below about the differences between the two and how they are related. 👇
Inversion of Control (IoC)
Inversion of Control is a design principle in which control of the flow of a program is inverted. Instead of application code controlling the flow, a container or framework takes control. This allows for greater decoupling and flexibility.
Dependency Injection (DI)
Dependency Injection is a specific pattern that implements the principle of IoC. It is a technique that allows an object to receive its dependencies from outside, instead of creating them internally. It also makes decoupling easier and makes the code more testable.
Relationship between IoC and DI
DI is a way to perform Inversion of Control. Through injection, control over how and when dependencies are created and associated is taken away from dependent objects and given to a container or framework.
Example:
Let's go to the Car class that depends on an Engine object.
Without IoC and DI: The Car class would instantiate and control the Engine object directly.
With IoC: Control over how the Engine object is created and associated with Car is taken from the Car class and managed externally.
With DI: The Engine object is injected into the Car class by a container or constructor, rather than being created by the Car class itself.
It's important to remember, while IoC is a broader concept that inverts control of program flow, Dependency Injection is a specific technique that implements this principle, focusing on how objects obtain their dependencies.
So in the previous example the IStarter interface is used as an abstraction for the start action. The Engine class implements this interface, and the Car class only depends on the abstraction (interface), not the concrete implementation. This is a form of IoC in that it reverses control of how start behavior is provided to the Car class.
In addition, it is also an example of Dependency Injection, as the IStarter dependency is injected into the Car class through the constructor. This means that the Car class is decoupled from any specific implementation of IStarter.
Encapsulate… what?
Let's get straight to the point. Think of a class that, instead of correctly hiding details that shouldn't be exposed, does its job very poorly. Leaking encapsulation (or leaking implementation details) means that the internal details of a class or module are being exposed and used by other classes or modules, which leads to unnecessary coupling.
This can make the code very difficult to maintain and evolve, because any change in one module can have unwanted side effects in other modules that are coupled to it. Also, leaking implementation details can make code harder to understand and test, as dependencies between modules can be complex and not obvious.
It is important to show this in practice. Let's continue using the example of the Car and Engine class, but now changing the internal structure a little, see the code in the image below:
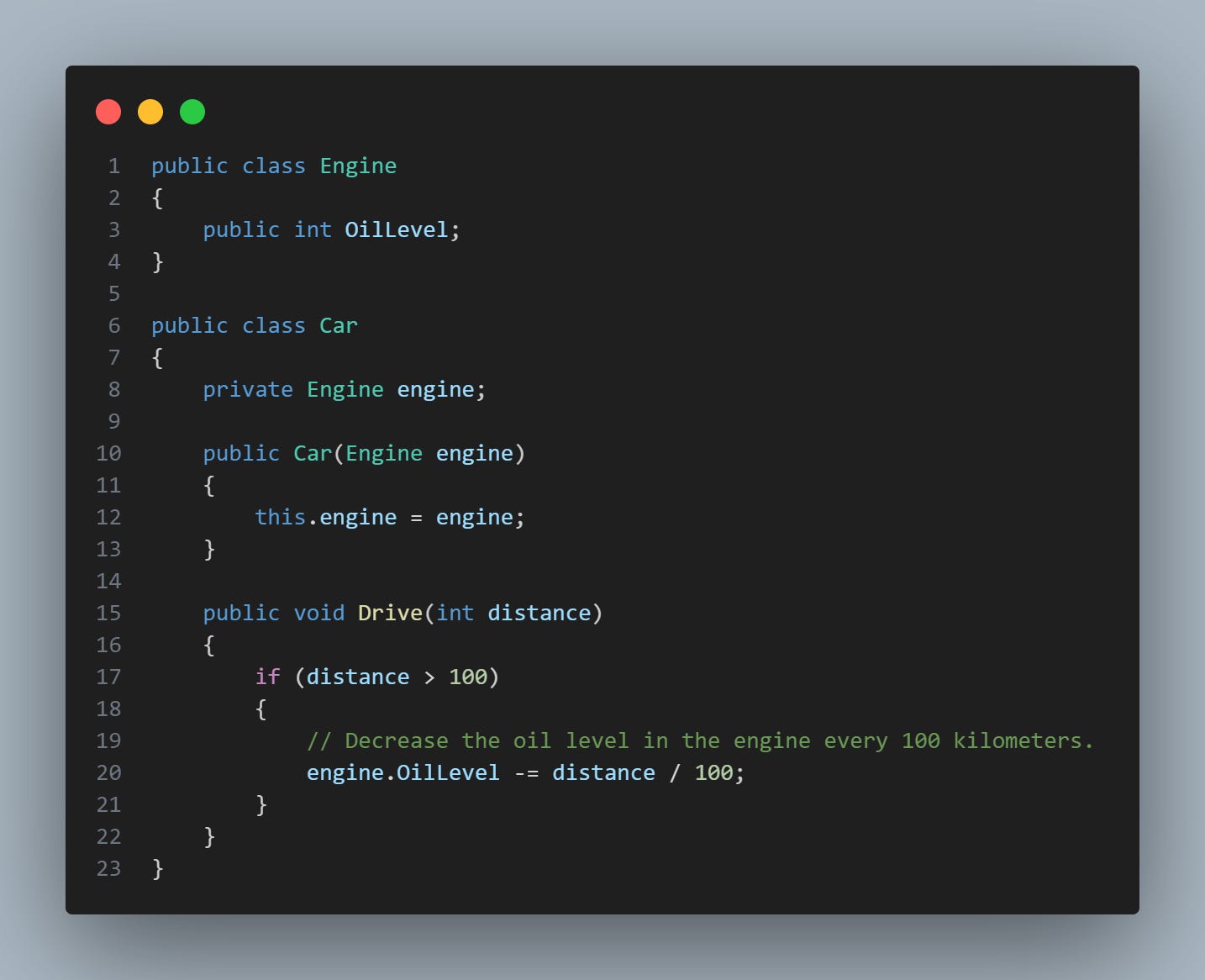
In this example, the Car class is directly accessing and modifying the OilLevel field of the Engine class. So we have an implementation detail being leaked? Why? Note that the Car class is aware of the internals of the Engine class and is directly manipulating its fields.
If, in the future, the way the Engine class handles its oil level changes (for example, we might want to measure the oil level in liters instead of an abstract value), we would have to change the code in the Car class and in any other class that directly accesses the OilLevel field.
To fix this encapsulation leak, it's much better to add a UseOil() method to the Engine class and call it from within the Car class:
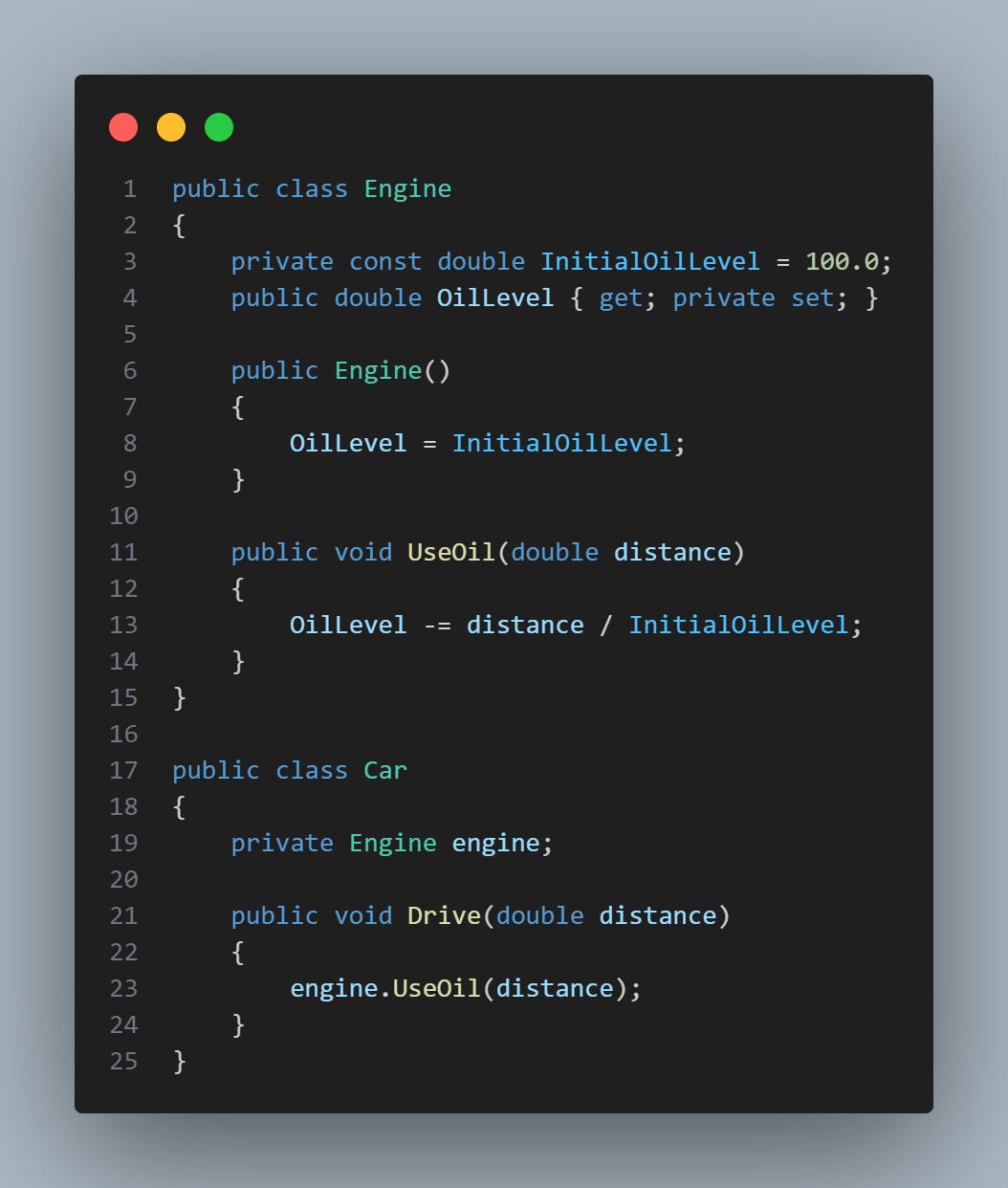
We can highlight some benefits:
Better Organization and Readability: Now, it is clear that the responsibility of managing the oil level belongs exclusively to the Engine class. This makes the code easier to read and understand.
Maintainability: If the logic of how oil is used needs to change in the future, we just need to change the UseOil() method in the Engine class. We wouldn't have to search the entire project for places where the OilLevel field is accessed directly.
Robustness: By encapsulating the oil logic inside the Engine class, we are protecting the Car class from possible bugs. If there was an error in the oil usage logic, it would be isolated to the Engine class and less likely to affect the Car class.
It was clear that maintenance just got easier!
Is it really easy to maintain?
Let's go to more practical examples of our day to day to dive deeper into the topic. I think it's interesting to start talking about a subject that many people need to pay attention to on a daily basis, magic numbers in the code.
At first glance, they might seem harmless or even a convenient way to quickly code a certain behavior. However, its presence in code has a number of negative implications, many of which are often overlooked by developers.
One of the often overlooked crux is that these magic constants make code less understandable. When you see a magic number in code, it's not immediately clear what that number means or why it matters. Let's practice!

Here, 20 and 30 are magic constants representing the regular hourly rate and the overtime hourly rate, respectively. However, these rates are not explained in the code, and if these rates need to be changed in the future, you will need to look for all occurrences of these numbers in the code.
Also, if the same value is used in multiple places, each occurrence will have to be found and changed manually, increasing the chance of errors.
This makes the code less flexible and more difficult to maintain. A programmer working with this code in the future may not know what these numbers represent and may have difficulty modifying or extending it. A clearer approach would be to give them meaningful names and keep them in one place for easy modification.
But maybe that's not a problem for you. So I would like to show you another example:
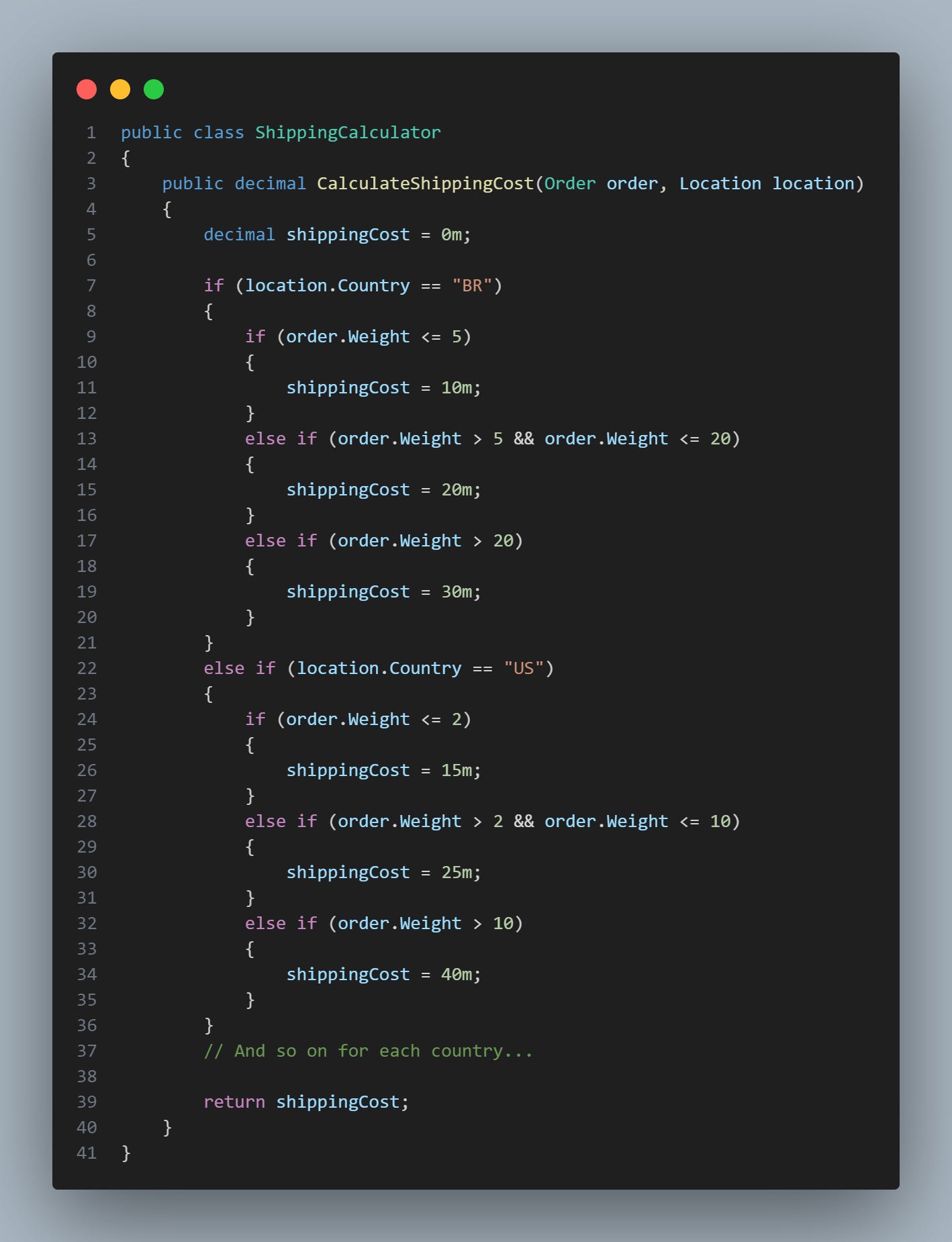
On many eCommerce platforms, there is one aspect that often appears behind the curtains: a shipping calculation system. This system essentially decides the amount a customer must pay to have their purchase delivered to their address. And do you know how he does it? It is based on several criteria. But notice how the method is doing a lot of things? At first glance, this method appears to be working correctly and serving the purpose. However, there are several issues that can make it difficult to maintain in the future:
1. Complexity and readability: Over time, as the business logic becomes more complex (eg, introducing special rates for specific regions, special offers, etc.), the amount of if-elses will increase dramatically, making the code increasingly difficult to understand and maintain.
2. Violation of the Open/Closed principle: It is clear that the class/method violates the Open/Closed principle, which states that software should be open for extension but closed for modification. Each time a new rule is added, the code needs to be changed.
3. Difficulty of testing: Each new case requires a new test, which can make testing very complex. Also, if a change is introduced, it can be difficult to isolate the effect of that change on existing tests.
4. Code Repetition: The general structure of each conditional is the same, with the only difference being the values used. This is code repetition, which could be avoided with better design.
A possible solution to these problems would be to use the Strategy design pattern, which allows you to define a family of algorithms, encapsulate them as separate classes, and make them interchangeable. But that's not the only solution, let's quickly explore others.
For every problem there are several solutions!
In addition to the Strategy pattern, as mentioned earlier, there are other approaches that can be employed to make code more manageable, extensible, and maintainable. Two of these approaches are Segregation of responsibilities and the Specification pattern.
Segregation of responsibilities is a principle that states that a class or module should have only one reason to change. This means that each class or module should only have a single responsibility. By breaking software down into components that perform a specific task, we can isolate behavior and complexity. This makes the system as a whole more understandable and easier to maintain and extend.
Let's go back to our freight calculation example. In that case, calculating the shipping cost for each country can be seen as a separate responsibility. Therefore, we can create a separate class for calculating the shipping cost for each country. This would result in classes like BrazilShippingCalculator, USShippingCalculator, etc. Each containing the specific logic for calculating the shipping cost for that country. This approach makes code flow and branches easy to follow, easier to test, maintain, and extend.
The Specification pattern, on the other hand, is a pattern that allows us to encapsulate business rules in separate classes. Each specification class contains business logic that can be combined with others to create more complex business rules. The pattern is useful when we have complex logic that needs to be represented in a reusable and modular way.
In the freight calculation example, each if-else condition can be seen as a business rule that can be encapsulated in a specification. For example, we could have specs like IsHeavyPackage, IsLightPackage, IsMediumPackage, IsDestinationBrazil, IsDestinationUS, etc. Each of these specifications can then be used to determine the appropriate shipping cost. Just to solve some doubts, see how it would look with the help of this pattern:

Note that this important rule that directly affects users is no longer within an error-prone conditional structure. Now we have a class of our own for that.
The approaches provide robust ways of dealing with complexity, making code easier to maintain and extend. Choosing between them (or a combination of them) will depend on the specific nature of the problem you are trying to solve. The important thing is to recognize that there are tools and patterns available that can help us write better and more maintainable code.
Not everything is roses 😄, there are pros and cons of these approaches and care that we must take, I will not go into too much depth, but just mention two:
Specification Management: On large systems, there can be many different specifications. Managing all these specs and ensuring they are correct can be challenging.
Abstraction Cost: Each specification is a separate class. This can result in a large number of classes, especially if you have many different rules. While organization is important, many classes can be difficult to manage.
Stay tuned, you need to know how to use each solution wisely. Quickly let's see the differences between the Strategy and the Specification:
Strategy Pattern is useful when you have multiple algorithms that can be used interchangeably.
The Specification Pattern is useful when you need to represent complex business rules in a reusable way.
Don't forget Cohesion!
Cohesion is a fundamental principle of software engineering that refers to the idea that a unit of code (for example, a class) should have a single, well-defined and focused responsibility.
When a class is cohesive, all its methods and attributes are directly related to its responsibility. Each method must contribute to fulfilling that responsibility, and the class must not do anything that is not directly related to its duties.
Let's consider an example. Let's say we have a "Car" class. A cohesive Car class could have methods like "On", "Off", "Accelerate" and "Brake". Each of these methods is directly related to the responsibility of the Car class, which is to represent and control a car.
However, if the Car class started having methods like "SaveToDatabase", "SendConfirmationEmail", or "CalculateTax", it would be becoming less cohesive. These methods are not directly related to the responsibility of representing and controlling a car, and should be in other classes.
Detecting classes that are not cohesive can be a little interpretive, but generally if you notice that a class is doing a lot of different things, or that some of its methods don't seem to be directly related to its main responsibility, then it's likely that the class don't be cohesive.
Some signs of the absence of cohesion:
Too many fields or properties: If a class has too many fields or properties, it could be a sign that it is doing too much. For example, an Order class with fields for order details, customer information, and payment details can be split into several smaller classes such as Order, Customer, and Payment.
Large methods: Long and complex methods can indicate a lack of cohesion. It is often possible to break these methods down into smaller subroutines that can be moved into their own classes.
Frequent changes: If you frequently need to change a class due to changing business requirements, it could be a sign that that class has too many responsibilities. Rather than modifying a large, complex class, it may be easier and safer to modify a smaller, more cohesive class.
Difficulty in testing: If it is difficult to write unit tests for a class, it can be a symptom of a lack of cohesion among other problems. Cohesive classes are generally easier to test because they have a single responsibility and fewer dependencies.
Too many dependencies: If a class depends on too many other classes to function correctly, it is likely doing too much.
Unrelated method names: If the methods in a class seem unrelated to each other, it could be an indication that the class is doing too many things. For example, in a User class, methods like Login(), Logout(), Register() are coherent and show a high degree of cohesion. However, if the same class also has methods like SendEmail(), CalculateTax(), CreateToken() then this could indicate a lack of cohesion.
Low cohesion between methods and attributes: In a cohesive class, each method will use one or more attributes of the class. If a class contains methods that don't use any of the class's attributes, it could suggest that the class has too many responsibilities and that such a method may belong to another class.
Large amount of conditional code: If the class/method has a lot of if, else if or switch conditional structures, it may be an indication that it is doing too many things. Refactoring the code to separate these conditions into different classes can improve cohesion.
These are just a few tips. Detecting non-cohesive classes can take practice and experience. However, by focusing on maintaining cohesion, we can significantly improve the quality and maintainability of your code.
The Intersection Between Testability and Maintainability
Programmers often find themselves in a situation where they need to modify code to fix a defect, improve performance or add a new feature. Without proper testing, this is a risky task - we can inadvertently introduce bugs into the system.
Herein lies the beauty of automated testing. Tests provide a safety net for developers. If the tests are well written and cover a large part of the system, developers can confidently make changes to the code. If they break something, the tests will fail, alerting them to the problem.
However, for tests to be useful, they must be kept in sync with the code they are testing. This means that when the code changes, the tests may also need to change. So this is where maintainability comes in. If the code is maintainable, the tests will be too.
Also, if the code was written with testability in mind, it will be easier to write tests for it. And if we have tests for the code, it will be easier to maintain. But stay alert! Tests also need to respect principles and good practices so that they can be a useful and comprehensive auxiliary tool. Write and value the tests!
Therefore, we can see that testability and maintainability are not just related, they are mutually reinforcing. Code that is easy to test is easier to maintain, and code that is easy to maintain is easier to test.
Think before write!
We can reflect and analyze whether what we are writing and creating really makes sense, and if, above all, it is easy to maintain. Some questions may help:
Purpose and Responsibilities: Does this class or function I'm about to create have a clearly defined purpose? Does she have a single responsibility or is she trying to do too many things at once?
Readability: Is the code I'm writing clear and easy to read? Could a person who has never seen this code before quickly understand what it does?
Unit Tests: How am I going to write unit tests for this code? Are the functions small and independent enough to be tested in isolation?
Dependencies: What does this code depend on to function correctly? Are dependencies clearly defined and easily replaceable for ease of testing?
Future: If I have to modify this code in the future, will it be easy to do so? Or am I creating complex tangles that will be difficult to unravel?
Refactoring: Is this code easily refactorable? Am I writing the code so that it's easy to make small, incremental improvements in the future?
Conclusion
In conclusion, software maintainability is a crucial property that often determines the longevity and success of a project. Easy-to-maintain code not only improves software quality and efficiency, but also lowers the total cost of ownership over time.
Testability, clarity, cohesion, and loose coupling are intrinsic attributes of maintainable code. Well-written unit tests improve testability and make maintenance safer by preventing regressions. Cohesion ensures that each class or module in the code has a single responsibility, making it more understandable and easier to modify. Loose coupling allows software components to be modified or replaced independently, promoting code reuse and extensibility.
However, achieving these attributes requires constant awareness and strict discipline during the development process. It requires practicing good software design principles such as dependency injection, interface segregation, and the principle of single responsibility. In addition, we constantly need to reflect and question our design and implementation choices, asking ourselves, "Does this make the code easier to test? Does it make the code easier to understand? Does it make the code easier to modify?"
Finally, it is important to remember that while maintainability is important, it is not the only factor that determines software quality. Other aspects, such as performance, security and usability, are also fundamental. Therefore, as with many aspects of software development, maintainability must be considered in balance with these other factors.
Inversion of Control (IoC) is a software design principle that refers to delegating responsibility for creating and managing dependencies to an external "container", rather than allowing classes to manage their own dependencies.
In DI, the external "container" that is responsible for creating and managing dependencies is usually an IoC frame or IoC container. Common frameworks include Spring on Java, ASP.NET Core on .NET, and others. These frameworks can analyze the code, determine which classes depend on which other classes, create instances of those classes in the correct order, and inject those instances where needed.
Inversion of Control is so called because it reverses the traditional flow of control within a program. In a non-IoC program, the main class controls the creation and management of all its dependencies. This means that the main class has firm control over the program flow. With IoC, this control is reversed: the IoC container dictates the flow of control, controlling the creation of dependencies and injecting them where needed.