
Entenda o Optimistic Locking: O Que Acontece Quando Todo Mundo Clica em Salvar?
A única forma de ir rápido é fazendo bem feito.

Então, você está construindo um aplicativo. Você testou tudo. Funciona perfeitamente. Fez o deploy. Sucesso! Agora, várias pessoas começam a usá-lo ao mesmo tempo e… BUM 💥 — estamos encrencados. Nada funciona.
Você se pergunta: “Mas tava tudo certo… o que aconteceu?”
A verdade é que, quando estamos desenvolvendo um app, é natural pensar nele como algo usado por uma única pessoa. Afinal, você é uma só pessoa testando tudo. E nesse contexto, tudo parece sob controle. Mas o mundo real é paralelo. Usuários simultâneos, ações concorrentes. E aí, meu amigo(a), o bicho pega.
Projetar sistemas que aguentam esse tipo de uso não é trivial. Requer técnicas específicas. Requer atenção. Mas também oferece a oportunidade de dar aquele salto de qualidade como dev.
Neste artigo, vamos mostrar que até aquele seu CRUD aparentemente simples pode esconder armadilhas. Vamos entender o que acontece quando vários usuários interagem com os mesmos dados ao mesmo tempo, por que isso gera problemas — e como você pode resolver isso de forma elegante com uma técnica chamada Optimistic Locking. Além disso, as notas ao rodapé podem ajudar a explicar algumas coisas de maneira objetiva!
Já passou por isso?
Se você já lidou com aplicações multiusuário, provavelmente já viveu — ou pelo menos ouviu falar — daquele bug misterioso em que duas pessoas atualizam o mesmo dado ao mesmo tempo… e uma delas perde tudo que fez.
Não é um bug difícil de entender, mas ele quebra uma coisa essencial: a confiança no sistema.
Se o que eu acabei de editar pode simplesmente desaparecer porque outra pessoa salvou por cima, como confiar que o sistema está me ouvindo de verdade? Pois é. Esse tipo de situação tem nome: concorrência de dados.
E se a gente quiser construir sistemas mais confiáveis, precisamos entender como lidar com ela.
O que é concorrência de dados?
Pra entender isso com clareza, deixa eu te contar uma cena que talvez já tenha acontecido com você.
Imagina que você e um familiar estão atualizando uma lista de compras compartilhada no celular.
Você abre a lista e vê que tem:
• Leite
• Pão
• Arroz
Você decide adicionar “Café”.
Seu irmão, no mesmo momento, abre a mesma lista e resolve apagar “Arroz”, porque ele lembra que ainda tem um pacote fechado em casa.
Ambos fazem suas alterações ao mesmo tempo, sem saber que o outro também está mexendo. E ambos clicam em salvar.
Agora, depende de quem salvou por último:
• Se você salvou depois, a lista final terá o “Café”, mas ainda terá “Arroz”, porque a exclusão feita pelo seu irmão foi sobrescrita.
• Se ele salvou depois, a lista final estará sem “Arroz”, mas também sem o seu “Café”.
Resultado? Um sobrescreveu o outro. E nenhum dos dois ficou feliz.
Agora pense nisso ocorrendo em um software…
Pensa num sistema de vendas com 50 vendedores atualizando preços e estoques ao mesmo tempo. Ou num CRM com um time inteiro de atendimento alterando dados de clientes. Ou até num sistema de gestão escolar onde professores, alunos e secretaria interagem com os mesmos registros. Esse tipo de concorrência é inevitável.
A questão é: o que seu sistema faz quando ela acontece?
Mas pera aí… isso não é papel do banco de dados?
Se você pensou isso, parabéns — faz sentido. Durante muito tempo, a gente confiou (e com razão) que os bancos de dados davam conta de manter a consistência das informações. Transações, locks, rollback… tudo isso funciona muito bem em ambientes controlados.
Mas aí vem a realidade dos sistemas modernos:
• APIs distribuídas
• Microsserviços
• Replicações
• Banco em nuvem
• Escalabilidade horizontal
E, de repente, nem tudo acontece em um único banco de dados. Nem sempre dá pra garantir que todo mundo tá vendo o mesmo dado ao mesmo tempo. E nem sempre o que você leu ainda está válido no momento em que tenta salvar.
Concorrência de dados acontece no nível da aplicação também.
Ou seja: não basta depender do banco. A aplicação precisa saber lidar com conflitos que acontecem entre o tempo que o dado é lido e o momento em que ele é salvo.
Esse intervalo de tempo — que pode ser de milissegundos ou minutos — é a janela onde os problemas surgem. E quanto maior a escala do seu sistema, maior a chance de alguém mudar aquele dado bem ali, enquanto você estava editando.
E em sistemas distribuídos?
Aqui a coisa fica ainda mais séria. Em sistemas distribuídos, nem sempre existe uma transação única entre bancos de dados. Muitas vezes, cada serviço trabalha com seu próprio banco, seu próprio contexto. Não existe mais uma “transação mágica” abraçando tudo.
Você pode ter uma operação aparentemente simples, como atualizar um pedido, que envolve:
• o serviço de estoque
• o serviço de pagamentos
• o serviço de entrega
• e o banco de pedidos
Tudo separado. Cada um com seu próprio banco. E todos eles podem concorrer pelo mesmo dado ou depender de versões sincronizadas que não chegam ao mesmo tempo.
Nesse cenário, controlar a concorrência vira responsabilidade sua — do desenvolvedor, da aplicação. E é aí que entram as estratégias como Optimistic Locking, que vamos explorar mais adiante.1
Antes do Optimistic Locking… como a gente lidava com isso?
Antes da popularização do Optimistic Locking, a abordagem mais comum pra lidar com concorrência era a mais direta possível: tranca tudo e só um usuário mexe por vez.
Sim, estou falando do Pessimistic Locking — o “jeito cauteloso” de lidar com dados.
Pessimistic Locking (ou: “trava na entrada”)
A ideia é simples:
“Se alguém está mexendo nesse dado agora, ninguém mais pode mexer até que ele termine.”
É como se o sistema colocasse uma plaquinha virtual:
🛑 “Em manutenção — aguarde sua vez!”
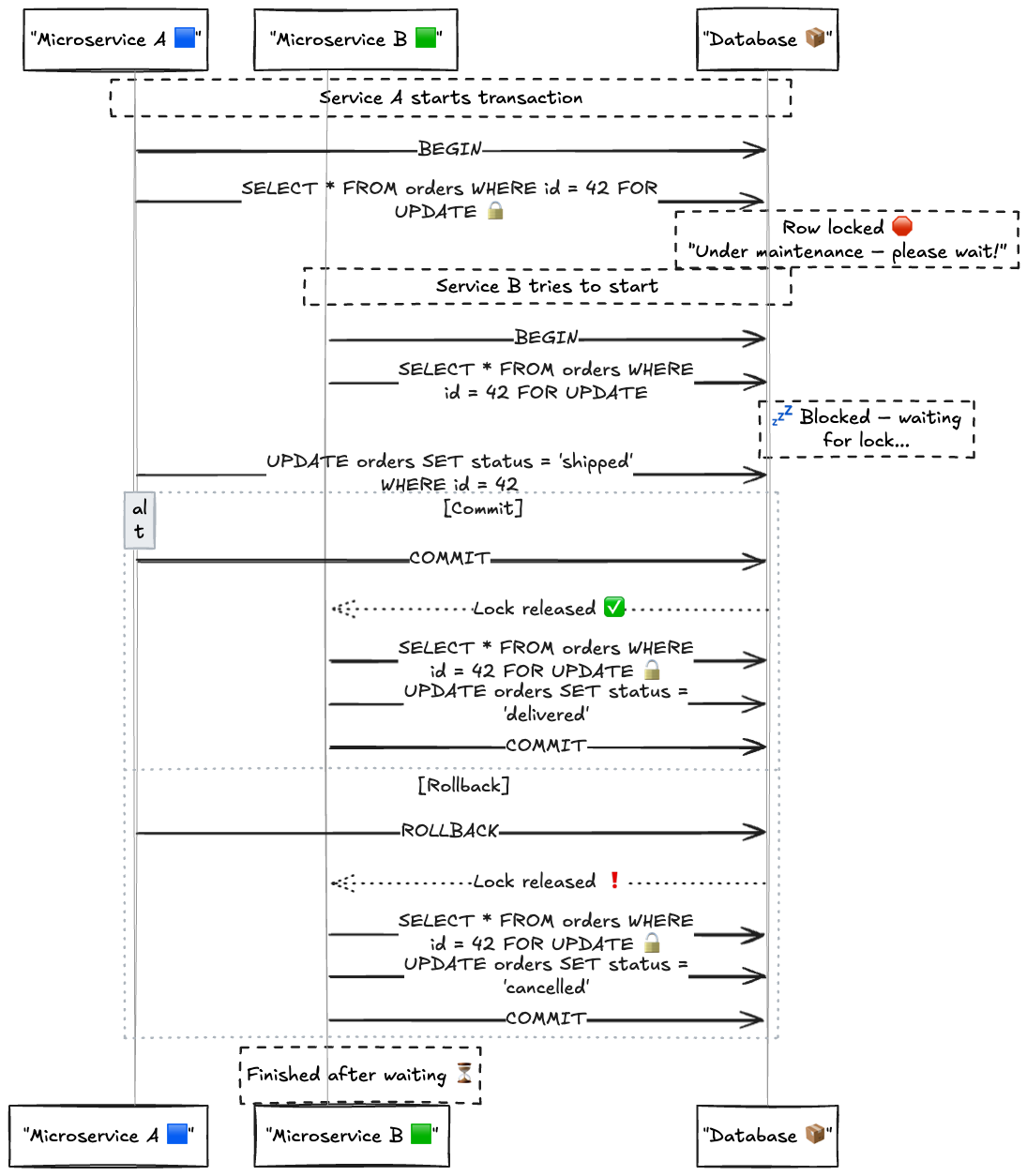
Esse bloqueio acontece no banco de dados. E o jeito mais comum de fazer isso é através de comandos como:
🔒 SELECT ... FOR UPDATE
Esse comando é usado dentro de uma transação para travar a linha que foi lida.
Ou seja, se você fizer:
BEGIN;
SELECT * FROM pedidos WHERE id = 42 FOR UPDATE;
-- faz alguma lógica aqui
UPDATE pedidos SET status = 'enviado' WHERE id = 42;
COMMIT;Enquanto essa transação estiver aberta, ninguém mais consegue atualizar o mesmo pedido (id = 42).
Outros usuários que tentarem acessar essa linha pra atualizar vão ficar esperando até que a transação seja finalizada (commit ou rollback).
🔒 Tipos de bloqueios
Dependendo do banco e do que está sendo feito, esse lock pode ocorrer em diferentes níveis:
• Bloqueio de linha: trava apenas o registro exato que você está mexendo. Ideal.
• Bloqueio de página: trava um grupo de linhas (em alguns bancos, por baixo dos panos).
• Bloqueio de tabela: trava todos os registros da tabela. Ninguém mais lê nem escreve.
• Bloqueio global (banco inteiro): extremo e raríssimo — mas sim, existe.
Quanto mais amplo o lock, maior o risco de travar o sistema e criar gargalos.
⚠️ Os riscos do Pessimistic Locking
Parece seguro? Sim.
Mas isso tem um preço:
• Usuários podem ficar esperando sem saber o motivo.
• Deadlocks: dois processos esperando um ao outro liberar uma linha.
• Escalabilidade comprometida: quanto mais gente usando o sistema, mais os locks se acumulam.
• Menor paralelismo: o banco trabalha menos porque passa mais tempo “esperando”.
É por isso que, apesar de ser muito útil em alguns contextos críticos (tipo controle financeiro ou transações bancárias), o Pessimistic Locking não é a melhor escolha para todo sistema.
Além disso, em sistemas distribuídos (como APIs modernas ou microsserviços), manter esse tipo de lock entre serviços separados é quase impossível. Os bancos não conversam entre si de forma nativa, e você perde a consistência global.
E antes de qualquer tipo de locking?
Muitos sistemas antigos simplesmente não tratavam isso.
Confiavam que “ninguém ia mexer no mesmo dado ao mesmo tempo” ou aceitavam sobrescrever dados silenciosamente.
Resultado?
• Alterações perdidas
• Dados inconsistentes
• E aquele clássico: o usuário dizendo “Ué, eu tinha preenchido isso aqui!”
A chegada do Optimistic Locking
Com o tempo (e com a evolução das arquiteturas e da carga dos sistemas), surgiu a necessidade de uma abordagem mais leve, escalável e segura: o Optimistic Locking.
Ele não trava nada por padrão. Ele confia. Mas verifica se ainda pode confiar na hora de salvar.
E isso mudou o jogo — principalmente pra aplicações com alta leitura, baixa taxa de conflito e arquiteturas distribuídas.
Perfeito! Vamos fazer uma nova versão, mais visual, mais detalhada, com exemplos claros e mantendo a conversa leve com o leitor. A ideia aqui é deixar o leitor não apenas entender, mas visualizar mentalmente o funcionamento do Optimistic Locking, sem dúvida nenhuma sobre o que acontece em cada passo.
Como funciona o Optimistic Locking na prática?
Tá, agora que a gente já entendeu os problemas com múltiplos usuários mexendo nos mesmos dados ao mesmo tempo, vamos falar sobre como o Optimistic Locking resolve isso — e de um jeito elegante.
Lembra que ele não trava ninguém?
O sistema deixa todo mundo mexer nos dados ao mesmo tempo, como se dissesse:
“Vai lá, pode editar tranquilo… só vou conferir se tá tudo certo na hora de salvar.”
Ou seja, ele confia que não vai ter conflito. Mas… confia desconfiando. 😅
Como ele faz essa verificação?
Com um pequeno truque: ele guarda uma versão do dado. Toda vez que um registro é alterado, essa versão é incrementada.
Assim, na hora de salvar, o sistema consegue saber se alguém mexeu nesse dado depois de você ter lido.
Vamos ver isso acontecendo? Situação inicial no banco:

Você, usuário 1, abre a tela de edição e o sistema mostra:
• Nome: Caneca A
• Estoque: 15
• Versão: 3
Ao mesmo tempo, o usuário 2 também abre a mesma tela e vê as mesmas informações.
Agora, cada um vai fazer uma modificação diferente:
• Você quer mudar o estoque para 12
• O outro usuário quer mudar o nome para “Caneca Azul”
O que acontece na hora de salvar?
Você envia sua alteração pro sistema. E ele tenta rodar essa query no banco:
UPDATE produtos
SET estoque = 12, version = 4
WHERE id = 42 AND version = 3;Olha esse WHERE:
“Só atualize se o registro ainda estiver na versão 3.”
Nesse momento, o banco olha:
• O produto ainda tá na versão 3?
• Sim? Beleza, atualiza!
• E atualiza também o campo version, subindo ele pra 4.
Agora, o banco ficou assim:

Agora é a vez do segundo usuário salvar…
Ele tenta rodar a seguinte query2:
UPDATE produtos
SET nome = 'Caneca Azul', version = 4
WHERE id = 42 AND version = 3;Mas pera… O WHERE version = 3 não bate mais, porque a versão atual do banco é 4 (graças à sua alteração anterior). Resultado?
Nenhuma linha é atualizada.
O banco entende que o dado foi alterado por outra pessoa nesse meio tempo. Ou seja: conflito detectado.
E o sistema (ou a aplicação) agora pode te avisar com clareza:
“Opa! Alguém alterou esse registro enquanto você editava. Quer revisar as mudanças antes de continuar?”
Resumindo a mágica
O Optimistic Locking funciona como uma conferência rápida:
“Esse dado ainda está do jeitinho que eu li lá atrás?”
Se sim, salva. Se não, o sistema recusa a operação e te dá a chance de revisar.
Sem travar ninguém. Sem filas. Sem bloqueios no banco. Só uma checagem de integridade no momento certo.

Esse comportamento é excelente pra sistemas onde:
• Os conflitos são raros, mas precisam ser tratados com cuidado.
• Há muitos acessos de leitura e poucas alterações simultâneas.
• A escalabilidade e performance são críticas.3
Mas e se eu usar a data da última atualização? Não é a mesma coisa?
Muita gente pensa:
“Se eu gravar a data e hora da última modificação (updated_at), posso usar isso pra saber se o dado mudou, né?”
Na teoria, parece funcionar. Na prática? Tem umas armadilhas escondidas nessa abordagem.
Por que usar updated_at como controle de versão é arriscado ⚠️
Aqui vão os principais problemas:
1. Precisão de tempo pode variar
Relógio de servidor não é infalível.
Em sistemas distribuídos, cada serviço pode estar rodando em máquinas diferentes, fusos diferentes, até com alguns milissegundos (ou segundos) de diferença.
Esses “desvios sutis” podem gerar conflitos invisíveis ou rejeições desnecessárias.
“Mas é só sincronizar os relógios!”
Sim, em teoria. Na prática, garantir isso em todos os ambientes (dev, staging, produção, clusters…) é mais difícil do que parece.
2. Comparação de timestamps é mais sensível
Datas podem vir com precisão diferente dependendo do banco, linguagem, driver ou até formato da requisição (ISO, UTC, timestamp, etc).
Às vezes a diferença é de milissegundos e já basta pro WHERE falhar ou, pior, passar batido. Um updated_at “quase igual” pode não ser exatamente igual, e o seu UPDATE pode:
• não rodar (conflito falso positivo)
• ou sobrescrever sem perceber (conflito falso negativo)
3. Não deixa explícito que você está controlando versão
Quando você usa um campo chamado version, o objetivo fica evidente:
“Esse campo existe só pra controle de concorrência.”
Isso traz clareza pro código, facilita o entendimento de quem lê depois e evita confusões com lógicas que também usam a data pra outras coisas (ex.: ordenação, histórico, relatórios…).
4. Timestamps podem ser alterados por outras lógicas
Imagine um sistema que atualiza o campo updated_at em outras situações — como um log de acesso, atualização de status, ou até um job automático.
Você nem tocou no conteúdo real, mas o timestamp mudou.
E pronto: o sistema acha que houve conflito, mesmo sem alteração real. Resultado? Usuário frustrado sem motivo.
Por que version é melhor?
Um campo version é simples, confiável e direto:
• Começa em 1.
• A cada modificação real, ele sobe pra 2, 3, 4…
• A comparação é numérica: version = 3.
• Sem depender de relógios, formatações ou precisão de data.
Ele é um contador puro, só sobe quando alguém muda algo. E isso é tudo que a gente precisa pra saber se o dado foi alterado por outra pessoa.
Optimistic locking exception, mas os dados foram salvos… O que está acontecendo?
Você está lá, acompanhando os logs da sua aplicação Spring Boot, e se depara com isso:
org.springframework.orm.ObjectOptimisticLockingFailureException:
Object of class [br.com.exemplo.Produto] with identifier [42]:
optimistic locking failed; nested exception is javax.persistence.OptimisticLockExceptionE junto disso, uma resposta 500 sendo enviada pro cliente.
Aparentemente, tudo falhou, né?
Mas aí você vai conferir o banco de dados e… os dados foram atualizados normalmente. 😳
Ou pelo menos uma das versões da atualização está lá.
O que pode estar acontecendo?
O erro OptimisticLockingFailureException indica que o Hibernate tentou atualizar um registro cuja versão já havia sido modificada por outra transação.
Ou seja:
• Você leu o registro na versão 3.
• Tentou salvar dizendo: “só atualize se a versão ainda for 3”.
• Mas nesse meio tempo, alguém já subiu pra versão 4.
• Resultado: conflito.
Isso é esperado! ✅
O erro significa que o Hibernate (ou qualquer ORM) não conseguiu realizar o UPDATE, justamente porque o controle de concorrência funcionou.
O dado não foi sobrescrito. O sistema bloqueou a perda de dados, como deve ser.
Isso é o Optimistic Locking funcionando corretamente.
O erro parece feio — mas é um sinal de que seu sistema não deixou um usuário sobrescrever o trabalho do outro sem saber.
Mas… por que está estourando como erro 500? 🚨
Por padrão, o Spring Data JPA e o Hibernate lançam essa exceção (ObjectOptimisticLockingFailureException) como uma unchecked exception, o que faz o Spring retornar um erro 500 — como se fosse uma falha interna do servidor.
Mas isso não é exatamente um bug.
É um conflito de concorrência esperado e que deve ser tratado com calma.
Como tratar isso corretamente?
1. Capture a exceção e trate como um conflito (HTTP 409)
Você pode usar um @ControllerAdvice para capturar a exceção e retornar uma resposta amigável:
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(ObjectOptimisticLockingFailureException.class)
public ResponseEntity<String> handleOptimisticLockingFailure(ObjectOptimisticLockingFailureException ex) {
return ResponseEntity.status(HttpStatus.CONFLICT)
.body("Conflict: The resource was updated by someone else. Please reload and try again.");
}
}Assim, em vez de um 500, o cliente recebe um 409 Conflict, que é muito mais adequado.

2. Retry automático? Com cuidado!
Dependendo do caso, você pode sim implementar uma estratégia de retry, principalmente para operações idempotentes.
Por exemplo:
@Retryable(
value = { ObjectOptimisticLockingFailureException.class },
maxAttempts = 3,
backoff = @Backoff(delay = 200)
)
public void updateProduct(ProductDTO dto) {
// lógica de atualização do produto
}Isso é útil quando os conflitos são ocasionais e as alterações podem ser reaplicadas sem prejuízo.
Mas atenção:
• Retentativas cegas podem causar mais conflitos.
• Se o dado tiver sido alterado com informações diferentes, talvez seja necessário reconciliar com o usuário.
O que você pode orientar no seu time (ou projeto)?
• Nunca deixe essa exceção estourar sem tratamento.
• Transforme em 409 Conflict para representar corretamente o problema.
• Analise se é seguro implementar retry em operações específicas.
• Em sistemas com muita concorrência, considere um mecanismo de merge ou aviso ao usuário para evitar frustrações.
Tem certeza que não estamos perdendo dados?
Essa dúvida é super válida. Afinal, se a aplicação está estourando um erro 500 com uma exceção de Optimistic Locking, o instinto natural é pensar:
“Algo deu muito errado. Será que os dados foram perdidos? Será que a persistência falhou?”
Mas aqui vai o ponto-chave:
❗ O erro não significa que o sistema perdeu os dados.
Ele significa que o sistema se recusou a sobrescrever algo que já tinha sido alterado.
Esse tipo de erro acontece antes de qualquer alteração no banco ser realizada com sucesso.
É o mecanismo de segurança do Optimistic Locking dizendo:
“Não vou seguir com essa operação porque os dados mudaram desde a última vez que você os viu.”
Como os ORMs de mercado tratam isso?
A maioria dos ORMs maduros (como Hibernate no Spring Boot, Entity Framework, Doctrine, TypeORM, etc.) implementam Optimistic Locking com bastante segurança, seguindo este fluxo:
1. A aplicação lê um dado (ex: versão 3).
2. Ao tentar salvar, ela executa um UPDATE ... WHERE version = 3.
3. Se nenhuma linha for afetada, significa que o dado foi alterado antes do update.
4. Nesse caso, o ORM lança uma exceção específica (ex: OptimisticLockException).
5. A transação é abortada automaticamente. Nenhuma alteração é persistida.
Ou seja, o banco se mantém intacto — e o erro 500 não é sobre perda de dados.
É sobre proteção contra sobrescrita acidental.4
Podemos ficar seguros ao tratar isso como 409?
Sim, e aqui está o porquê:
• O erro representa um conflito lógico, não uma falha interna ou inesperada no servidor.
• Os dados não foram salvos — mas também não foram perdidos.
• O mecanismo está justamente alertando que outra pessoa alterou o recurso antes de você.
O 409 é a resposta semântica correta pra isso:
“O servidor entendeu a requisição, mas não pode completá-la porque há um conflito com o estado atual do recurso.”
E claro, se sua aplicação trata isso com um @ControllerAdvice e retorna um JSON explicando o que aconteceu, você transforma um erro confuso num aviso útil pro consumidor da API.
Minha visão sobre tratamento e Retryable
Pessoalmente, eu gosto de entender o problema primeiro e só depois decidir qual abordagem realmente faz sentido. Nem tudo precisa de retry. Nem tudo merece virar erro 500. Tudo depende do contexto — e da intenção por trás do que estamos construindo.
No caso do Optimistic Locking, converter o erro 500 padrão para um HTTP 409 (Conflict) faz sentido por alguns motivos:
1. É um conflito esperado, não um erro inesperado no servidor. O sistema funcionou como deveria ao proteger o dado.
2. Ajuda a comunicação com o cliente da API, que agora pode entender que precisa agir (por exemplo, recarregar ou revisar os dados).
3. Evita poluir os logs com falsos positivos, já que conflitos controlados não são falhas reais — são parte do fluxo.
Agora… implementar retry automático já é outra história. Pode funcionar muito bem em alguns cenários, mas é preciso ter cuidado com:
1. Idempotência — Se a operação pode ser repetida sem efeitos colaterais, ok. Mas se ela gera cobrança, notificação ou qualquer efeito “real”, repetir pode causar estrago.
2. Repetição cega pode piorar a concorrência, gerando uma avalanche de novos conflitos ou sobrecarga.
3. Você precisa saber se o retry faz sentido para o seu caso de uso. Se o usuário digitou algo e já mudou de ideia, talvez seja melhor mostrar o conflito do que forçar um salvamento.
Em resumo: Converter o erro para 409? Com certeza. Retry automático? Só quando tiver certeza que é seguro.
Como o frontend pode colaborar com o Optimistic Locking?
Tá bom… já entendemos como o Optimistic Locking funciona no back-end.
Sabemos que ele protege os dados de atualizações simultâneas, e que o @Version (ou campo equivalente) é a chave dessa proteção.
Mas e o front nessa história? Ele só assiste de camarote?
Nada disso.
O frontend tem um papel essencial no bom funcionamento do Optimistic Locking — mesmo sem controlar diretamente o campo version.
Vamos conversar sobre isso.
O front não deve controlar a versão
Vamos tirar isso do caminho logo:
❌ O frontend nunca deve gerar, incrementar ou “adivinhar” o valor da versão do documento.
Esse controle é exclusivo do back-end, e normalmente gerenciado automaticamente pelo ORM (como o Hibernate com @Version).
O papel do frontend é simples:
• Ele recebe a versão junto com os dados no GET.
• Ele envia essa mesma versão de volta no PUT/PATCH, sem alterar o valor do campo version — mesmo que o resto do conteúdo tenha sido modificado.
Como o frontend ajuda, na prática?
1. Preservando o valor da versão
Mesmo que o campo version não seja exibido ao usuário, ele deve ser mantido no estado interno do front:
{
"id": 42,
"name": "Caneca Azul",
"price": 39.90,
"version": 3
}Quando o usuário edita e envia, o version vai junto. Isso permite que o back-end valide se o dado ainda está no mesmo estado.
2. Tratando o erro de conflito com empatia
Se houver uma tentativa de update e o back-end retornar um 409 Conflict, o frontend não deve simplesmente mostrar um “Erro genérico”.
Esse erro não é uma falha do sistema — é uma disputa legítima de edição entre dois usuários.
E o front pode ajudar muito na experiência de resolução.
Por exemplo:
• Mostrar uma mensagem amigável:
“Alguém atualizou esse item enquanto você fazia alterações. Quer revisar as mudanças antes de tentar novamente?”
• Trazer os dados mais recentes do servidor e permitir:
• Revisar manualmente
• Tentar re-aplicar as mudanças
• Ou cancelar a operação
• Oferecer um botão de “Recarregar e tentar de novo” que faz o GET, atualiza o version e reenvia com os novos dados
3. Exibindo feedback claro sobre quem alterou o dado (se possível)
Alguns sistemas incluem no payload:
{
"version": 4,
"lastModifiedBy": "joana.silva",
"lastModifiedAt": "2024-03-22T18:15:00Z"
}O frontend pode usar isso para mostrar algo como:
“Este registro foi alterado há 2 minutos.”5
Humaniza o conflito e evita que o usuário ache que o sistema “bugou”.
Na prática, a indústria caminha para esse equilíbrio:
• O back-end protege os dados com versionamento.
• O front-end coopera com:
• Transparência
• Respeito ao valor do version
• Boas mensagens de erro
• E UX pensada para conflitos ocasionais
Sistemas colaborativos como Google Docs, Notion, Trello, Figma e até plataformas de e-commerce com múltiplos atendentes lidam com isso diariamente — e todos eles contam com algum nível de lógica no front para suavizar conflitos.
O Frontend participa da jogada, envia a informação certa, trata o erro de forma clara e ajuda o usuário a tomar a melhor decisão.
No fim das contas, concorrer é inevitável. Perder dados não.
Construir sistemas seguros, escaláveis e amigáveis num mundo com múltiplos usuários ativos ao mesmo tempo é um desafio real. E como você viu ao longo deste artigo, até aquele CRUD inocente pode se transformar num campo minado quando a concorrência entra em cena.
O Optimistic Locking não é uma solução mágica, mas é uma ferramenta poderosa pra quando você precisa:
• Permitir paralelismo sem travas,
• Proteger dados sem comprometer performance,
• E lidar com conflitos de forma clara, controlada e previsível.
Você entendeu:
• Por que confiar só no banco de dados nem sempre é suficiente,
• Como o versionamento ajuda a detectar mudanças entre leitura e escrita,
• E como o frontend também tem um papel importante nesse processo.
Mais do que evitar erro 500, o que queremos é oferecer transparência, previsibilidade e segurança para quem usa o sistema. E quando isso acontece, seu software deixa de ser só funcional — ele se torna confiável. E isso é um baita diferencial.
Agora é com você: Já implementou Optimistic Locking em produção? Te salvou de alguma dor de cabeça? Ou causou uma nova? Me conta — gosto de trocar ideias com quem já viveu isso na prática.
Mas pera aí… isso tudo acontece por causa do paralelismo?
Sim, a concorrência de dados acontece porque operações paralelas estão acessando e tentando modificar os mesmos dados ao mesmo tempo.
Esse paralelismo pode vir de:
• Vários usuários usando o sistema ao mesmo tempo,
• Múltiplas instâncias da sua aplicação processando requisições,
• Serviços diferentes atuando sobre os mesmos recursos,
• Ou processos assíncronos, como filas e agendadores.
Mas olha só: o paralelismo em si não é o vilão. Ele é esperado — e até desejado — em sistemas modernos.
O problema surge quando essas operações acessam dados compartilhados sem coordenação. É aí que entra a concorrência.
Técnicas como Optimistic Locking existem justamente pra deixar o paralelismo rolar, sem que isso comprometa a integridade dos dados.
Usamos uma query como essa pra exemplificar o funcionamento do Optimistic Locking:
UPDATE produtos
SET nome = 'Caneca Azul', version = 4
WHERE id = 42 AND version = 3;Ela funciona — mas tem um pequeno detalhe que vale reforçar:
Estamos atribuindo manualmente o próximo valor da versão (4). Isso funciona em exemplos simples, mas não é a abordagem mais segura em sistemas reais.
Em vez disso, a prática mais comum e recomendada na indústria é deixar o próprio banco calcular a nova versão, incrementando o valor atual:
UPDATE produtos
SET nome = 'Caneca Azul', version = version + 1
WHERE id = 42 AND version = 3
RETURNING *;
Embora o exemplo clássico envolva dois usuários editando o mesmo recurso manualmente, o Optimistic Locking também é extremamente útil para proteger contra eventos sistêmicos, como:
• Serviços diferentes tentando atualizar o mesmo dado ao mesmo tempo
• Processos assíncronos (como consumidores de filas) que atuam sobre o mesmo documento
• Jobs agendados que executam ações concorrentes em paralelo
Ou seja, ele não protege apenas a interface do usuário — ele também é uma camada de segurança contra interações concorrentes entre sistemas. Em ambientes distribuídos, essa proteção se torna ainda mais essencial.
ORMS modernos e controle de versão (@Version)
A maioria dos ORMs maduros oferece suporte nativo ao Optimistic Locking — o que significa que você não precisa implementar a lógica de controle de versão manualmente.
Basta anotar o campo de versão, e o ORM faz o trabalho de:
• Verificar a versão atual antes de atualizar.
• Lançar uma exceção se houver conflito.
• Atualizar automaticamente o valor da versão em cada commit bem-sucedido.
Hibernate (Java)
@Version
private Integer version;• Com essa anotação, o Hibernate insere automaticamente a cláusula WHERE version = ? no UPDATE.
• Se nenhuma linha for afetada, ele lança OptimisticLockException.
JPA (Java padrão)
• Usa a mesma anotação @Version, compatível com múltiplas implementações (Hibernate, EclipseLink…).
Entity Framework (C# / .NET)
[Timestamp]
public byte[] RowVersion { get; set; }• Usa um campo de timestamp binário (rowversion) que o EF verifica automaticamente.
• Conflitos disparam DbUpdateConcurrencyException.
TypeORM (Node.js / TypeScript)
@VersionColumn()
version: number;• Adiciona um campo de versão e controla conflitos ao salvar.
• Lança erro se a versão não bater.
Doctrine (PHP)
/**
* @Version
* @Column(type="integer")
*/
private $version;• Controla a versão automaticamente e lança OptimisticLockException quando necessário.
Pode mostrar/exibir o nome… mas isso depende do contexto de negócios e do nível de privacidade que precisamos no software…
Sensacional!