
Antes de Implementar o Outbox Pattern, Leia Isso!
"Em um sistema assíncrono, você nunca sabe quando (ou se) algo aconteceu." - Gregor Hohpe & Bobby Woolf — Enterprise Integration Patterns

Você já teve aquele frio na barriga ao pensar: “E se o sistema salvar os dados no banco, mas falhar bem na hora de enviar a notificação?”
Pois é. Parece um detalhe pequeno, mas esse tipo de situação pode causar uma dor de cabeça enorme tanto pra quem usa seu sistema quanto pra quem cuida dele.
Imagina o seguinte: um cliente faz uma compra na sua loja online. O pagamento é aprovado, tudo certo com o estoque… mas o e-mail de confirmação nunca chega.
Pra ele, parece que a compra não foi finalizada. Ele tenta de novo. Ou abre um chamado no suporte. Ou começa a reclamar nas redes sociais. E aí? O time de atendimento corre pra entender o que aconteceu. O time de desenvolvimento tenta rastrear logs, verificar se foi problema de rede ou se o sistema de e-mail caiu. No fim, ninguém dorme tranquilo.
Tudo isso por causa de uma falha no que deveria ser uma operação simples: salvar os dados e avisar outro sistema sobre isso.
Esse tipo de falha acontece porque salvar no banco de dados e enviar uma mensagem (pra uma fila, serviço de e-mail, ou outro sistema) são duas operações separadas — e se uma falhar depois da outra, temos um problema.
É aqui que entra o Outbox Pattern.
Mas será que a sua arquitetura realmente precisa disso? Vamos conversar sobre isso ao longo do artigo — sem complicar demais, mas indo fundo o suficiente pra você entender quando (e por que) esse padrão pode salvar seu sistema.
Neste artigo, eu repito algumas informações para fixar o conhecimento. Se isso se tornar irritante, me avise! O objetivo é sempre deixar a leitura agradável e interessante para todos.
O que é o Padrão Outbox?
Beleza, agora que já entendemos o tipo de dor de cabeça que pode acontecer quando uma mensagem se perde no meio do caminho, vamos entender o que exatamente é esse tal de Outbox Pattern e por que ele tem esse nome curioso.
A palavra Outbox vem do inglês e significa literalmente “caixa de saída”. Você provavelmente já viu isso no seu e-mail: toda vez que você escreve uma mensagem e clica em enviar, ela passa por essa tal Outbox antes de ir efetivamente para o destinatário.
E por que isso é importante? Porque a Outbox funciona como um “estacionamento temporário” para garantir que a mensagem será enviada mesmo se algo der errado no caminho. Se a conexão com a internet cair, por exemplo, o e-mail continua lá, esperando a hora certa de ser enviado.
No contexto de sistemas, é a mesma ideia: a Outbox Pattern é um mecanismo que armazena as mensagens de saída dentro do próprio banco de dados, junto com os dados da operação principal, antes que essas mensagens sejam enviadas pra fora — seja pra outro sistema, uma fila (tipo Kafka, SQS…), ou até uma notificação por e-mail ou SMS.
Tá, mas o que exatamente é esse padrão?
De forma simples e direta:
O Outbox Pattern é uma forma de garantir que uma operação no banco de dados e o envio de uma mensagem aconteçam juntas, na mesma transação.
Assim, você evita o risco de salvar os dados mas não enviar a mensagem, ou vice-versa. Funciona assim:
1. Você faz a operação principal (por exemplo, criar um pedido no banco de dados).
2. Ao mesmo tempo, você salva a mensagem que deve ser enviada (por exemplo, “NovoPedidoCriado”) numa tabela especial de outbox (vamos falar mais pra frente dessa tabela), que está no mesmo banco de dados.
3. Depois, um processo separado (que pode ser um job, um worker ou um listener) pega essas mensagens da tabela outbox e as envia de verdade, seja pra um broker de mensagens, outro serviço ou e-mail.
Uma analogia para esclarecer 🙃
Vou tentar ilustrar isso, imagine seu restaurante favorito. O cliente faz um pedido. O garçom escuta, entende, mas… não anota nada. Ele vai até a cozinha tentar lembrar de cabeça o que foi pedido. Às vezes dá certo. Mas às vezes ele esquece um detalhe — ou até o pedido inteiro. Resultado: o cliente fica esperando e nada chega.
Agora, imagina outro cenário. O garçom sempre anota tudo no caderninho antes de levar o pedido pra cozinha. Esse caderninho é a garantia de que nada vai ser esquecido. Mesmo se a cozinha estiver cheia, o pedido tá ali registrado. E se tiver algum problema, o garçom consegue ver o que já foi anotado e retomar de onde parou.

Esse caderninho é a Outbox. Ele garante que, mesmo que alguma parte do processo falhe temporariamente, a informação essencial foi salva com segurança e pode ser enviada assim que for possível.
Mas o que isso resolve na prática?
O problema de sistemas distribuídos é que a gente não consegue garantir que tudo vai acontecer ao mesmo tempo, de forma confiável. Quando você salva uma informação no banco e quer enviar um evento (ou mensagem) com base nessa informação, essas duas ações não são, por padrão, sincronizadas ou garantidas como um único pacote.
Ou seja: você pode acabar com um sistema onde os dados foram salvos, mas ninguém foi avisado sobre isso e isso pode quebrar totalmente a lógica de negócios em arquiteturas orientadas a eventos, como microservices. Esse é um tema tão importante que vamos mergulhar mais a fundo nessa realidade de sistemas distribuídos e como o Outbox virou uma resposta pra esses desafios modernos.
Por que o Outbox Pattern Existe?
Você pode estar se perguntando:
“Mas esse problema sempre existiu? Como os sistemas funcionavam antes do Outbox? A galera só aceitava que as coisas falhassem?”
Pois é… durante muito tempo, as coisas funcionavam de um jeito meio “na confiança” e em muitos sistemas simples, isso até era suficiente. Só que o mundo mudou. E com ele, a complexidade dos sistemas também.
Como era antes?
Vamos voltar um pouco no tempo.
Em sistemas mais tradicionais, monolíticos, tudo acontecia dentro do mesmo lugar: o banco de dados, a lógica de negócio, o envio de e-mails, as atualizações de estoque, tudo dentro da mesma aplicação. Era mais fácil garantir que tudo ocorresse numa ordem certinha, e se desse erro, era possível reverter tudo com um simples rollback.
Mas aí chegaram os sistemas distribuídos e os microservices. Cada pedaço da aplicação virou um serviço separado, com seu próprio banco de dados, sua própria linguagem, e sua própria responsabilidade. E aí surgiu o dilema:
“Como garantir que algo que acontece em um serviço reflita corretamente em outros serviços, sem inconsistência e sem perder mensagens pelo caminho?”
A resposta comum era essa: grava no banco e depois envia a mensagem. Simples, né? Só que não.
O problema do “dual write” (ou: o famoso “escreve aqui e depois lá”)
Vamos imaginar um exemplo bem simples:
1. O sistema salva um pedido no banco de dados.
2. Em seguida, ele envia um evento chamado PedidoCriado pra outro serviço pra atualizar o estoque ou notificar o usuário.
Essas duas operações parecem ligadas, mas acontecem separadamente. E isso tem nome: dual write (escrita dupla). O problema é que qualquer uma das duas pode falhar.
Cenário 1:
✅ Pedido salvo no banco
❌ Evento não enviado (ex: problema de rede, fila indisponível, código bugado)
Cenário 2:
❌ Pedido não salvo no banco
✅ Evento enviado (opa! notifiquei algo que nem existe direito)
Resultado: caos. Um sistema acha que o pedido existe, o outro não acha nada. E aí o que era pra ser um processo simples vira um festival de inconsistências. LEIA O RODAPE1
E por que isso importa de verdade?
Se o seu sistema é todo sincronizado e fechado, talvez isso nunca seja um problema.
Mas quando você começa a trabalhar com:
• Serviços assíncronos
• Arquitetura orientada a eventos
• Filas como Kafka, RabbitMQ, SQS
• Integrações com terceiros (pagamento, e-mail, SMS, etc.)
… você entra num território onde dual write pode ser um problema silencioso.
O sistema pode parecer que tá funcionando, até a primeira falha. E quando ela acontece, ela quebra a confiança: o pedido some, a notificação não chega, os dados ficam incoerentes. E aí começam os chamados no suporte, os logs malucos e os “não sei o que aconteceu” da equipe técnica.
E é aí que o Outbox Pattern entra
Ao invés de fazer duas operações separadas (salvar + enviar), o Outbox agrupa tudo numa única transação:
• A informação principal é salva no banco
• E junto com ela, uma “mensagem” é registrada numa tabela de Outbox
Aí sim, depois, um processo separado (mas seguro) vai ler essas mensagens e enviá-las com calma, sem risco de “perder” a notificação.
Ou seja, o Outbox Pattern quebra o dual write, centraliza a garantia da entrega, e tenta trazer um pouco de paz pro coração dos desenvolvedores.
Como o Outbox Pattern Funciona (Sem Dor de Cabeça)
Agora que a gente já entendeu por que o Outbox Pattern existe, vamos ver como ele funciona na prática. Não se preocupe se você não for expert em arquitetura de sistemas a ideia aqui é tornar isso o mais visual e lógico possível.
A tabela de outbox 📦
Tudo começa com uma tabela especial no banco de dados chamada… outbox.
Ela é como um caderninho de anotações que seu sistema usa para garantir que nada importante seja esquecido especialmente mensagens e eventos que precisam ser enviados para outros sistemas ou serviços.
Sempre que algo relevante acontece (como um pedido sendo criado, um pagamento sendo aprovado ou um produto sendo atualizado), o sistema anota esse fato na tabela de outbox. Isso acontece dentro da mesma transação do banco que salva os dados principais. Ou seja, ou tudo é salvo junto, ou nada é salvo. Isso evita inconsistências do tipo “salvei o pedido, mas esqueci de avisar o sistema de entregas”.
Essa tabela costuma conter alguns campos essenciais:
• id: um identificador único da mensagem (gerado automaticamente). É o que garante que cada evento na outbox tenha sua própria identidade.
• aggregateType: o tipo da entidade que gerou o evento, como "Order", "User" ou "Invoice". Isso ajuda a saber de onde o evento veio.
• aggregateId: o ID específico daquela entidade. Por exemplo, se for um pedido, aqui entra o ID do pedido. É útil para rastrear ou correlacionar eventos com os dados originais.
• type: o tipo do evento em si. Por exemplo, "OrderCreated", "PaymentFailed", "UserRegistered". Isso permite que os consumidores da mensagem saibam como reagir.
• payload: o conteúdo da mensagem, geralmente em JSON. Aqui você coloca os dados que outro sistema vai precisar para processar esse evento corretamente.
• createdAt: o momento exato em que o evento foi registrado. Esse timestamp é importante tanto para fins de auditoria quanto para ordenação ou expiração futura.
Você pode (e provavelmente vai querer) adicionar outros campos com o tempo, dependendo das suas necessidades:
• Um campo status (como "pending", "sent", "failed") para controlar se o evento já foi processado.
• Uma processedAt para indicar quando a mensagem foi de fato enviada.
• Um retryCount caso você queira tentar reenviar mensagens que falharam.
Então primeiro, o sistema registra o evento na outbox. Depois, um outro processo — geralmente assíncrono — lê essa tabela e faz o trabalho de envio, seja para um broker de mensagens, webhook, fila, etc.
Essa separação entre “registrar” e “enviar” é o que torna o padrão Outbox tão confiável. Ele garante que o dado e a mensagem sempre caminham juntos, sem riscos de inconsistência.
Ou seja, essa tabela é o seu caderninho de pedidos (lembra da analogia do restaurante?). Nada sai antes de ser anotado aqui.
Tudo em uma única transação
Aqui tá o pulo do gato. Quando o seu sistema realiza uma operação principal como criar um pedido, registrar um pagamento ou atualizar um cadastro salva esses dados normalmente no banco de dados.
Mas, junto com isso, ele também salva a mensagem na tabela de outbox, na mesma transação.
Isso significa que ou as duas operações acontecem juntas, ou nenhuma delas acontece.
💡 Esse é o segredo do Outbox Pattern: salvar o dado principal e a mensagem de forma atômica, em uma única transação.
Dessa forma, você garante que não vai existir dado sem mensagem, nem mensagem sem dado.
O papel do publicador (message dispatcher)
Depois que a operação foi concluída com sucesso, temos um pedido criado e uma mensagem registrada na outbox.
Agora entra em cena um processo separado, chamado de publicador (ou dispatcher, ou worker, depende da arquitetura).
Esse cara tem uma função bem clara:
Ler mensagens da tabela de outbox e enviá-las para fora.
Ele pode rodar de tempos em tempos (a cada segundo, por exemplo), ou ficar sempre escutando se algo novo chegou.
Ao encontrar uma nova mensagem, ele:
1. Lê o conteúdo da mensagem
2. Envia para o destino correto (como Kafka, RabbitMQ, SQS, um webhook, etc.)
3. Marca a mensagem como “processada” (ex: atualizando o campo processado_em)
Assim, ele garante que tudo que foi salvo será enviado, mesmo que com um pequeno delay mas com segurança.

E se o envio falhar?
Boa pergunta. Se o sistema de envio (por exemplo, Kafka ou o servidor de e-mail) estiver fora do ar no momento em que o publicador tentar entregar a mensagem, nada será perdido. A mensagem ainda está segura na tabela de outbox, e o publicador ou consumidor pode tentar de novo mais tarde.
Isso abre espaço pra técnicas como:
• Retries automáticos
• Dead letter queues (caso a mensagem falhe muitas vezes)
• Idempotência no lado consumidor (pra garantir que processar duas vezes não causa erro)
Tente visualizar o fluxo
Pra deixar tudo mais claro:
1. 📝 O sistema salva um novo pedido no banco
2. 📨 No mesmo momento, ele insere uma mensagem na tabela outbox
3. 🔄 Um publicador separado lê essa mensagem
4. 🚀 A mensagem é enviada pra outro sistema (ex: fila de eventos)
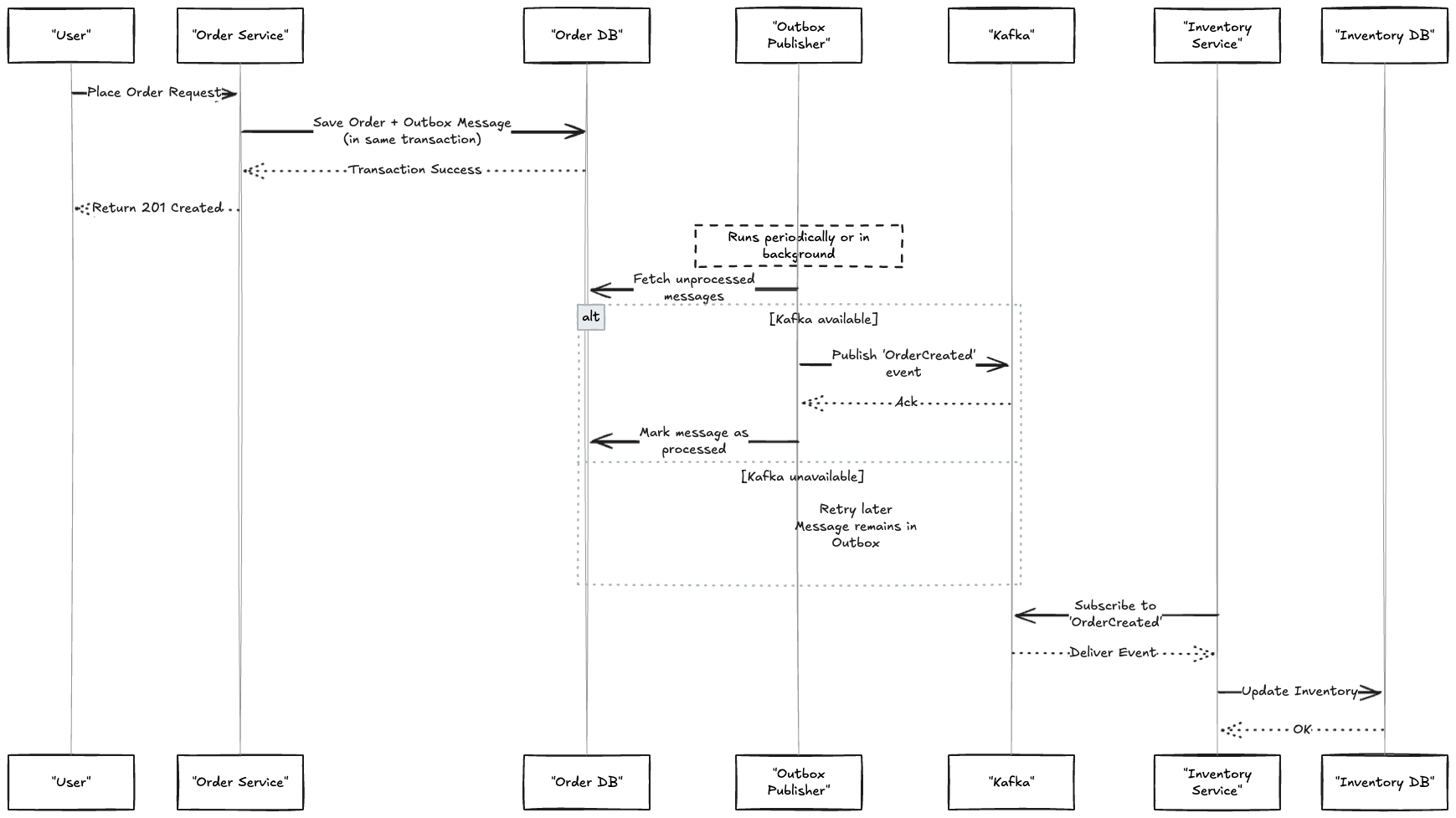
E por que tudo isso importa?
Porque essa separação entre gravação e envio, feita de forma organizada e transacional, traz segurança, previsibilidade e controle.
Você não precisa mais torcer pra que tudo aconteça em perfeita sincronia. O sistema passa a ser mais resiliente, menos frágil, e mais preparado pra lidar com falhas no mundo real.
Como Salvar Dados e Mensagem Juntos com Outbox
Agora que você entendeu o conceito e visualizou como ele funciona com o diagrama sequencial, bate aquela dúvida comum:
“Tá, mas como eu salvo os dados do sistema e a mensagem na tabela de outbox ao mesmo tempo, sem correr o risco de um dar certo e o outro falhar?”
A resposta está em uma palavrinha mágica: transação.
Tudo acontece dentro de uma única transação e é o @Transactional que garante isso
Quando você anota um método com @Transactional no Spring, está dizendo pro sistema o seguinte:
“Execute tudo isso como uma coisa só. Se qualquer parte falhar, desfaz tudo automaticamente.”
Ou seja, quando você salva o objeto principal (por exemplo, um Pedido) e, na sequência, cria um registro na tabela outbox_messages, o Spring vai garantir que ambas as operações sejam feitas com sucesso ou nenhuma seja feita.
Isso é fundamental pro Outbox Pattern funcionar corretamente.
Se algo der errado no meio por exemplo, falha na serialização do JSON da mensagem, nada será persistido no banco, e seu sistema não vai ficar com os dados pela metade.
O que exatamente vai pra tabela outbox_messages?
Já falamos disso anteriormente mas vale reforçar! Não é necessário (nem indicado) salvar o objeto inteiro da sua entidade principal!
Geralmente podemos salvar:
• Um tipo de evento (ex: PedidoCriado)
• Um payload com os dados necessários para o consumidor (normalmente em JSON)
• Metadados (ID, timestamps, status, etc.)
Ou seja, você envia só o que precisa ser comunicado para fora do sistema. Isso mantém a mensagem leve e desacoplada do seu modelo interno.
Vou deixar nos próximos tópicos, um exemplo simples e explicativo. Não é um baita código ou implementação… mas é apenas para deixar algo mais visual:
Entidade principal: Pedido
@Entity
public class Pedido {
@Id
@GeneratedValue
private Long id;
private String cliente;
private BigDecimal valor;
// Getters, setters e construtores
}Entidade da Outbox
@Entity
public class OutboxMessage {
@Id
@GeneratedValue
private UUID id;
private String eventType;
@Lob
private String payload;
private LocalDateTime createdAt = LocalDateTime.now();
private boolean processed = false;
// Getters, setters e construtores
}Repositórios (Spring Data JPA)
public interface PedidoRepository extends JpaRepository<Pedido, Long> {}
public interface OutboxRepository extends JpaRepository<OutboxMessage, UUID> {
List<OutboxMessage> findByProcessedFalse();
}Serviço com transação única
@Service
public class PedidoService {
private final PedidoRepository pedidoRepository;
private final OutboxRepository outboxRepository;
private final ObjectMapper objectMapper;
public PedidoService(PedidoRepository pedidoRepository,
OutboxRepository outboxRepository,
ObjectMapper objectMapper) {
this.pedidoRepository = pedidoRepository;
this.outboxRepository = outboxRepository;
this.objectMapper = objectMapper;
}
@Transactional
public void criarPedido(String cliente, BigDecimal valor) {
Pedido pedido = new Pedido();
pedido.setCliente(cliente);
pedido.setValor(valor);
pedidoRepository.save(pedido);
// Cria o payload da mensagem
Map<String, Object> payload = Map.of(
"pedidoId", pedido.getId(),
"cliente", cliente,
"valor", valor
);
try {
String payloadJson = objectMapper.writeValueAsString(payload);
OutboxMessage message = new OutboxMessage();
message.setEventType("PedidoCriado");
message.setPayload(payloadJson);
outboxRepository.save(message);
} catch (JsonProcessingException e) {
throw new RuntimeException("Erro ao serializar payload da mensagem", e);
}
// Tudo salvo numa única transação
}
}E o Dispatcher?
Agora você precisa de um componente separado que leia a tabela outbox_messages e envie as mensagens.
Pode ser um @Scheduled, um listener Kafka, ou um worker rodando de tempos em tempos.
Exemplo de dispatcher com @Scheduled
@Component
public class OutboxDispatcher {
private final OutboxRepository outboxRepository;
public OutboxDispatcher(OutboxRepository outboxRepository) {
this.outboxRepository = outboxRepository;
}
@Scheduled(fixedDelay = 5000)
public void processarMensagens() {
List<OutboxMessage> mensagens = outboxRepository.findByProcessedFalse();
for (OutboxMessage msg : mensagens) {
try {
// Aqui você enviaria para Kafka, RabbitMQ, e-mail, etc.
System.out.println("Enviando mensagem: " + msg.getPayload());
msg.setProcessed(true);
outboxRepository.save(msg);
} catch (Exception e) {
System.err.println("Falha ao enviar mensagem: " + e.getMessage());
// Mensagem continua na tabela e será reprocessada depois
}
}
}
}Reprocessamento? Sem problemas.
Repare no detalhe importante: se o envio falhar, a mensagem não é marcada como processada.
Isso significa que ela permanece na tabela e será tentada novamente no próximo ciclo do dispatcher.
É assim que o Outbox Pattern garante resiliência e confiabilidade, mesmo com falhas temporárias nos sistemas externos.
• Você salva o dado principal e a mensagem juntos, numa única transação.
• A mensagem é armazenada de forma simples e independente do modelo interno.
• Um componente separado (dispatcher) lê essas mensagens e as envia para onde for necessário.
• Se o envio falhar, nada é perdido. A mensagem continua lá até ser enviada com sucesso.
Mas… e pro negócio? O que o Outbox Pattern resolve de verdade?
Talvez você esteja pensando:
“Ok, entendi que isso evita falhas técnicas… mas por que isso importa no dia a dia do meu produto? Que diferença faz pro meu cliente final ou pro resultado da empresa?”
A verdade é que o Outbox Pattern não é só uma boa prática ele é uma forma de proteger a experiência do usuário, a reputação do produto e até evitar prejuízo financeiro.
Vamos ver alguns exemplos reais de impacto:
1. Evita confusão e retrabalho no suporte
Imagina o cliente final esperando um e-mail de confirmação, um status atualizado no app, ou um código de rastreio, mas a mensagem nunca chegou.
Ele pensa que o processo falhou e abre um chamado.
O suporte vai investigar, acionar o time técnico, e talvez precise forçar algum reenvio manual. Isso custa tempo, energia, e confiança.
Com o Outbox Pattern, essa mensagem não teria se perdido. Ela teria sido reentregue automaticamente, sem ninguém precisar intervir.
2. Garante consistência entre sistemas (e entre times)
Negócios modernos geralmente envolvem vários sistemas se comunicando entre si:
vendas, estoque, logística, atendimento, financeiro… todos precisam ter uma visão sincronizada do que está acontecendo.
Se uma operação foi feita mas os outros sistemas não ficaram sabendo (porque a mensagem falhou no envio), as decisões podem ser baseadas em dados errados.
Isso pode gerar:
• Estoque travado ou duplicado
• Pagamentos em duplicidade
• Desentendimentos entre áreas
• Relatórios com informações inconsistentes
Com Outbox, você reduz esse risco drasticamente.
3. Ajuda na auditoria e rastreabilidade
Por armazenar as mensagens enviadas e seus status, a tabela de outbox também funciona como um registro histórico de tudo que foi comunicado pra fora do sistema.
Se alguém questionar:
“Esse evento foi mesmo enviado pro parceiro logístico?”
Você tem como provar, rastrear e até reprocessar se for necessário.
4. Reduz o impacto de falhas temporárias
Sistemas externos falham. Fila fica indisponível. API de terceiros responde 500.
Mas quando o envio é desacoplado e reprocessável, como no Outbox, essas falhas não viram crise.
Você ganha resiliência de verdade, com menos urgência, menos incidentes fora do horário, menos estresse pra todos.
Resumindo:
Implementar o Outbox Pattern:
Evita perda de eventos e inconsistência de dados
Melhora a confiabilidade da aplicação (sem fantasmas intermitentes)
Protege a experiência do cliente final
Reduz o volume de chamados e suporte técnico
Dá visibilidade e controle sobre o que sai do sistema
Diminui o risco de falhas virarem prejuízo ou desgaste com parceiros
Legal… mas agora vamos falar da parte chata… custos… dinheiro… money…
Outbox Pattern: Nem sempre é barato. Nem sempre é simples. Mas às vezes…
Vamos lá: o Outbox Pattern não é gratuito, nem em termos de recursos computacionais, nem em termos de complexidade. E, como toda escolha arquitetural séria, ele deve ser analisado com critério, à luz do seu contexto — técnico e de negócio.
Então vamos conversar com calma sobre os custos envolvidos e como balancear tudo isso de forma consciente.
1. Custo computacional: sim, tem uma escrita a mais (e isso pesa)
Em sistemas de alto volume, cada milissegundo conta.
Com Outbox, toda vez que você salva um dado no banco, você também faz uma segunda escrita na tabela outbox_messages.
Essa escrita extra:
• ocupa espaço em disco,
• aumenta o tempo de commit da transação,
• e pode causar contenção no banco (especialmente se a tabela de outbox for muito acessada).
Além disso, você precisa de um componente a mais (o dispatcher/worker) que roda periodicamente ou continuamente lendo essa tabela, o que também consome CPU, memória e IO.
Em arquiteturas com alta taxa de eventos, isso pode se tornar um gargalo se não for bem dimensionado.
2. Latência: a resposta pro cliente pode demorar (um pouquinho) mais
Se você salvar o dado + a mensagem na mesma transação, o tempo de resposta da API vai incluir as duas operações.
Mesmo que essa diferença seja pequena, em ambientes com requisitos de baixa latência, isso pode se tornar um ponto de atenção.
E mesmo que o envio da mensagem aconteça depois (assincronamente, via dispatcher), o processo inteiro agora tem mais peças, mais camadas e mais dependências.
Então, sim: há impacto no tempo de resposta. Mas com um porém: você está trocando alguns milissegundos por consistência, resiliência e previsibilidade.
3. Complexidade a mais: mais código, mais testes, mais cuidado
Vamos ser realistas: implementar um Outbox Pattern direito não é copiar um repositório do GitHub.
Você vai precisar:
• Criar uma tabela especial no banco
• Serializar dados com cuidado (evitar acoplamento entre modelos)
• Configurar o dispatcher com tratamento de falhas, retries, e idempotência
• Monitorar a fila da tabela outbox
• Garantir que mensagens duplicadas não causem efeitos colaterais
Tudo isso aumenta a complexidade do sistema e também o trabalho do time.
Pra uma equipe pequena ou com prazos curtos, isso pode ser inviável, ou até arriscado, se for mal feito.
Até aqui, vimos que o Outbox Pattern tem custos reais. Mas também precisa ficar claro que ele não é um luxo. Ele é uma resposta a um problema que pode custar muito mais lá na frente. Vamos pesar os dois lados agora:
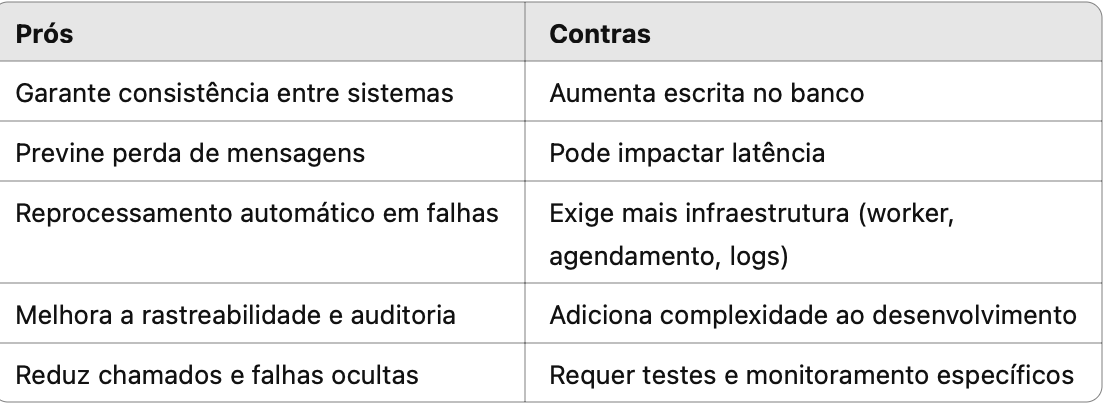
Como tomar uma boa decisão?
A melhor pergunta que você pode fazer não é “Devo usar o Outbox Pattern?” É:
“Meu sistema precisa mesmo dessa garantia extra de entrega e consistência?”
E pra isso, você precisa estudar o seu contexto. Pergunte:
• O que acontece se uma mensagem não for enviada?
• O cliente vai perceber? Vai abrir um chamado?
• O erro será silencioso e difícil de rastrear?
• Quantas integrações assíncronas tenho hoje (e terei no futuro)?
• Tenho capacidade técnica no time pra manter essa solução?
• Tenho budget pra monitorar isso direito?
Se o seu sistema é crítico, orientado a eventos, altamente distribuído, e precisa de confiabilidade na troca de informações, o Outbox Pattern pode valer cada linha de código.
Por outro lado, se seu sistema é mais simples, com integrações tolerantes a falhas, e onde eventuais perdas podem ser recuperadas manualmente, talvez o custo não se justifique.
E se eu quiser um meio-termo?
Existem alternativas intermediárias, como:
• Usar eventos transacionais com integração nativa do banco e broker (ex: Postgres + Kafka com Debezium)
• Aplicar retry com persistência temporária na aplicação
• Adiar a implementação completa do Outbox e focar primeiro em rastreabilidade + logs
O Outbox Pattern é uma das formas mais eficazes de garantir entrega confiável de eventos em sistemas distribuídos.
Mas como toda ferramenta poderosa, ele tem um custo e precisa ser bem avaliado antes de ser adotado.
O segredo está em pesar o impacto de perder uma mensagem… com o impacto de manter a solução que evita essa perda. E aí, a decisão fica menos sobre técnica, e mais sobre estratégia.
E é aí que a arquitetura deixa de ser só código e passa a ser uma ponte entre tecnologia e negócio.
Dual write é quando o sistema precisa realizar duas escritas distintas, geralmente uma no banco de dados e outra em um sistema externo, como uma fila de eventos, e-mail ou outro serviço. O problema é que essas escritas não acontecem de forma atômica, ou seja, uma pode dar certo e a outra falhar, criando inconsistência. Não há uma transação única envolvendo os dois lados, então se algo dá errado no meio do caminho, não tem como voltar atrás automaticamente.