
Refactoring as a Technique for Bug Detection
Refactoring allows us to notice details that were previously overlooked.

Amid the complex tangle of functions, classes and components of code, software engineers face constant challenges when trying to maintain the quality and efficiency of their projects. Bugs are inevitable in software development, often popping up in unexpected areas and causing unwanted effects that can degrade functionality and user experience. Consequently, detecting and fixing bugs is a vital part of the software development lifecycle.
In this scenario, refactoring emerges as a crucial technique. It is the process of modifying code to improve its internal structure without changing its external behavior. It's a very important concept, being much more than a mere "cleanup" task - refactoring is an opportunity to improve the design, performance, testability and maintainability of code.
And more than that, refactoring can be a powerful ally in detecting bugs. During the code review and restructuring process, programmers can discover hidden problems and subtleties that went unnoticed during coding.
Therefore, the purpose of this text is to explore how code refactoring can be used as an effective technique for bug detection, demonstrating through practical examples and discussing the implications and benefits of this process for software engineering teams. Let's go!
Why talk about code refactoring?
Well we can answer this question with the sentence below:
Code is a liability, not an asset.
What does that mean?
This sentence can be a little confusing, but if we think of the code as a house, maybe we can understand it better.
Imagine you bought a house. At first, it may seem like an asset, a good that has value. However, any homeowner knows that a home requires ongoing maintenance. The roof may need to be replaced, the paint may start to peel. If you ignore these problems, they will only get worse over time, and can even lead to structural damage that drastically reduces the value of your home. In a sense, your house is a "liability" - it constantly requires your time, effort and money to keep it in good condition.
Similarly, the code we write for software projects is very similar to this house. It may seem like an asset at first - after all, it's what allows our programs to function, and the solutions produced with this code often generate profit. But like a house, the code requires ongoing maintenance.
Bugs need to be fixed, logic may need to be updated as requirements change, as the system grows, code that was perfectly fine in the past can become a roadblock to adding new features. If we ignore crucial quality aspects and just introduce new features into the code without planning and good practices, we will sabotage the software over time, making the code increasingly difficult to understand, modify and especially test!
And this is where refactoring comes in. Like refactoring a house to keep it in good shape, refactoring is the process of organizing (practically improving) code to keep it cohesive. It allows us to fix code design, coupling, and other issues before they become critical, makes code easier to understand and modify, and ensures that our code liability doesn't cost us more than it should in effort and productivity.
So while we may initially think of our code as an asset, it's helpful to think of it as a liability - something that requires ongoing maintenance to maintain its value.1
That's why we always need to talk about refactoring. Have you been using this technique in your favor? No? How then can we do this? Let's understand!
How to use this technique in our favor?
One of the main benefits of refactoring is that it can help with catching bugs in code. How is that possible? To understand this, we first need to look at the nature of software bugs. Bugs are essentially defects in code that cause undesirable behavior. Often, these defects are the result of incorrect assumptions, misunderstandings, or programming errors. Let's clarify this:
Incorrect Assumptions: Occurs when a developer has made an assumption about how something should work, but that assumption was wrong. A classic example is assuming that a list of items will always have at least one item. This can lead to a bug if the list is empty, because the code might try to access the first item in the list and instead throw an error because there are no items to access.
Misunderstandings: Sometimes, a programmer may simply not fully understand how a specific piece of code is supposed to work, or how a particular function or class is supposed to be used. For example, maybe a method returns a null value under certain circumstances, but the developer thought it would always return a valid value. When the method returns null, this can cause a "null object" error when code attempts to use the returned value.
Programming errors: These are "errors" in the most classic sense. Maybe the developer typed something wrong, forgot to initialize a variable, used the wrong operator in an expression, or made some other simple mistake. These types of errors can be difficult to detect, because the code may look correct at first glance, but it doesn't behave as expected.
Now let's go to a simple example, which has happened to everyone.
// Initial code in C#
public class Calculator
{
public int Divide(int numerator, int denominator)
{
return numerator / denominator;
}
}Here's a simple example of a function that divides two numbers. However, there is a hidden bug here, which went unnoticed by the programmer: the function doesn't take into account the possibility of the denominator being zero. During refactoring, an attentive programmer might notice this and fix the bug.
// Refactored code in C#
public class Calculator
{
public int Divide(int numerator, int denominator)
{
if(denominator == 0)
throw new DivideByZeroException("Denominator cannot be zero.");
return numerator / denominator;
}
}Some developers believe that refactoring is only effective for making code cleaner and more readable. But experienced programmers who apply good programming practices know that refactoring goes further!
During refactoring, we have the opportunity to understand the code deeply. We can review and tweak the code to make it more efficient, organized, and readable. It is in this process that bugs are usually found. When you're really digging into the code, you have a chance to notice something that isn't working as it should. As bugs are often the result of subtle mistakes or mistakes in logic, this careful review is a valuable opportunity to catch them.
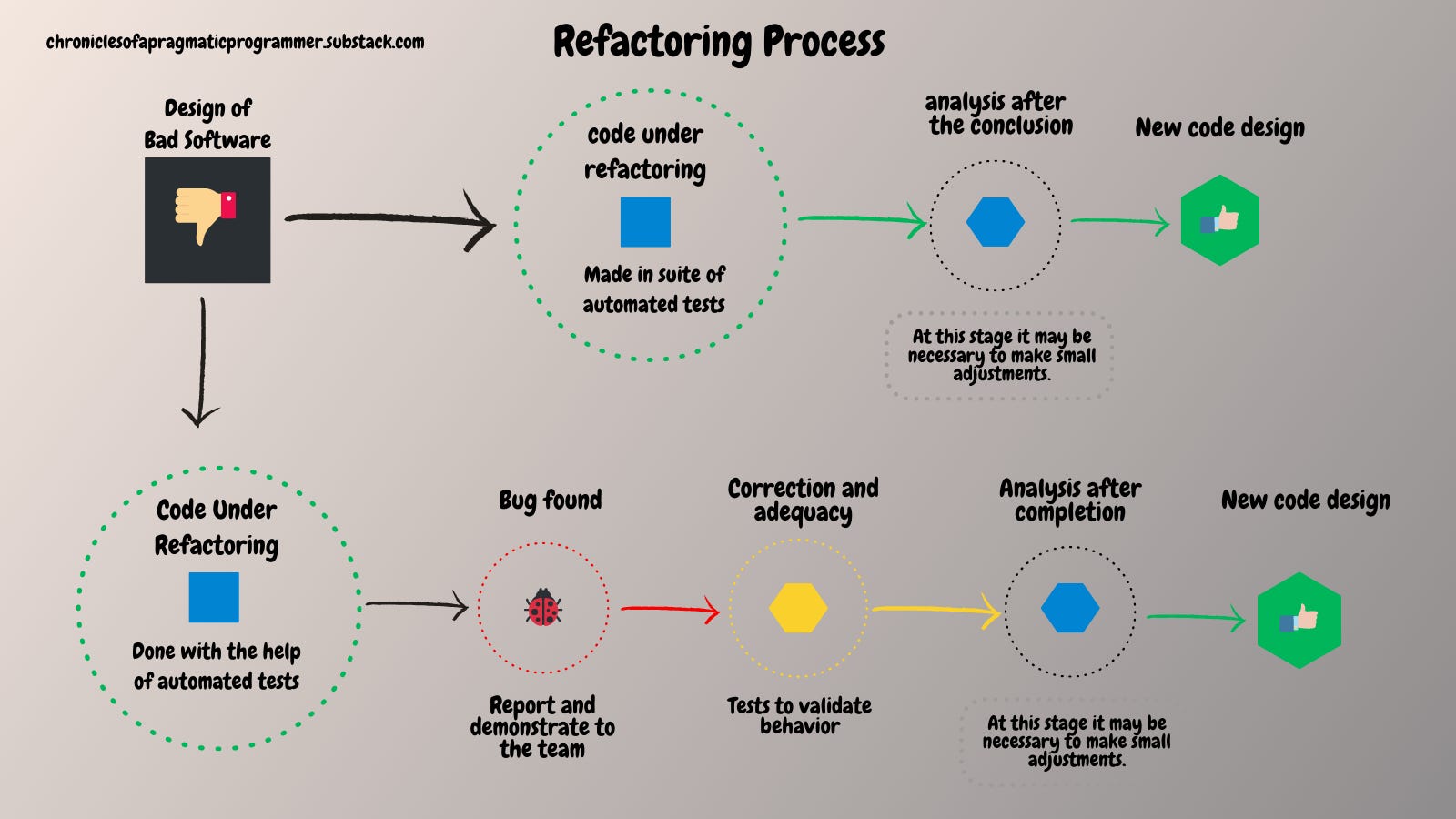
But it's always important to remember, to refactor safely we also need to understand the business rules and have a clear perspective of the original behavior of the code that we are going to refactor. But that topic can be left for another article.
Refactoring is crucial!
Code refactoring is a crucial component of the software development process. It's such an important practice that Martin Fowler once described it as "a controlled technique for improving the design of existing code." And, in essence, it is exactly that.
Let's imagine you're reviewing an old photo album. The more you look, the more you start to notice details that previously went unnoticed. A person hidden in the background, an object that wasn't there before, a facial expression you didn't notice. These are details that are only noticed with a close eye, and the same idea applies to code refactoring.
As with reviewing the photo album, refactoring allows us to notice previously overlooked details. You may encounter an uninitialized variable, an infinite loop if a certain situation or return occurs, a method that doesn't do what it's supposed to. It's these small, often overlooked details that often manifest as bugs.
Also, clean and well-organized code is less prone to bugs. Messy and confusing code can lead to equally confusing thinking. Mistakes are easily made when the structure of the code is complex and hard to follow. By refactoring, you're simplifying this structure, making it easier for everyone to understand what's going on.
Let's go to the example of a Voucher class in Csharp, where the IsVoucherValid method checks if the voucher is still valid, the example is very simple, but it serves very well to propose a line of reasoning and highlight the importance of practicing refactoring after the write completion of any class or method:
public class Voucher
{
public string Code { get; set; }
public DateTime ExpiryDate { get; set; }
public bool IsVoucherValid()
{
if (DateTime.Now > ExpiryDate)
{
return false;
}
else
{
return true;
}
}
}In this case, the code appears to be correct. The IsVoucherValid method checks whether the current date is greater than the ExpiryDate of the voucher and, if so, returns false, indicating that the voucher is no longer valid.
However, there is a problem with this code that might not be immediately obvious, but could be discovered during the refactoring process. The datetime comparison is taking into account the current time and the time the voucher expires. This means that if the voucher expiration date is today, but the expiration date time is before the current time, the voucher will be considered invalid. What do you mean?
The problem encountered is that DateTime.Now returns both the current date and time down to the millisecond. If the ExpiryDate only contains a date (without a time component) or the time is set to midnight (the default for a date with no time specified in C#), then the voucher will be considered expired at the turn of the day, even though technically still be the expiry day.
For example, if the ExpiryDate of the voucher is set to "2023-07-06" and the customer tries to use the voucher at 12:01 am on "2023-07-06", the condition (DateTime.Now > ExpiryDate) will be true, because "2023-07-06 12:01:00" is greater than "2023-07-06 00:00:00", and the voucher will be considered expired.
If the intent is to allow the voucher to be used until the end of the expiration day, you need to consider this in your validation logic. One way to do this is to ensure that the comparison is only done on the date part, ignoring the time. This can be achieved using the DateTime.Date method to remove the time part of the current date:
public bool IsVoucherValid()
{
DateTime currentDateWithoutTime = DateTime.Now.Date;
DateTime expiryDateWithoutTime = ExpiryDate.Date;
if (currentDateWithoutTime > expiryDateWithoutTime)
{
return false;
}
else
{
return true;
}
}Now the IsVoucherValid method is only comparing the date parts, ignoring the time. This ensures that the voucher will be valid for the entire day of the expiration date, regardless of the time.
The case above is a real situation reported by a co-worker a few years ago. Guess how he found the behavior incorrect? When he was refactoring! The funniest thing is that he didn't realize that it was thanks to refactoring that it was possible to detect this problem. And if the programmer didn't do a refactoring, would he have caught this problem on verification? Very hardly. Maybe when testing? In the code review? It all depends on other factors, but the point is the refactoring, the care in looking again at the code looking for points of improvement helped to avoid a problem that would affect the end user!
When refactoring, inquire!
While immersed in the refactoring process, we often ask ourselves:
Does this code make sense?
Is it readable and understandable?
If I were to go back to this code in a few months, or even years, would I still be able to understand what's going on here?
If a new team member were to see this code, would they be able to quickly pick up the logic and structure?
These aren't trivial questions - they're vital to the refactoring process and the long-term health of the software.
This kind of questioning, this critical thinking, is what allows us to identify the weak and problematic points of our code. This is where we spot bugs, inefficiencies, duplicate code, and unnecessary complexities.
Let's say you're reading a block of code and you notice that the logic is jumbled and tangled. If you come across this code and feel confused, chances are other developers feel the same way. And confusion is the gateway to mistakes. If the code is not properly understood, the chances of bugs being introduced during code changes or extensions increase exponentially.
So, by questioning the code during refactoring, you not only improve the quality of the code, but also create an opportunity to identify and fix bugs that may have crept into this mess.
Furthermore, when you question yourself about the readability and understandability of the code, you are indirectly thinking of all the other team members. You're trying to make their lives easier. This type of empathy leads to better teamwork, less frustration and greater productivity.
So now I think it's appropriate to list some questions that we should ask before and after refactoring:
Before Refactoring:
What is the purpose of refactoring? Before starting, you must have a clear objective in mind. This could be improving code readability, reducing complexity, improving performance, or fixing poor design.
Does the code contain tests? Before starting the refactoring, it's essential that you have solid tests in place. This will allow you to verify that the functionality remains the same after refactoring.
How will this refactoring impact other parts of the system? You need to understand the dependencies of the code you plan to refactor to avoid unwanted side effects.
Are enough resources (time, skills, tools) available for refactoring? Refactoring can take some time and effort, so it's important to consider whether you have the resources to do it.
After Refactoring:
Were the goals of the refactoring achieved? After the refactoring, make sure you achieved the goals you initially set.
Did the refactored code pass all tests? This is essential to ensure that the refactoring hasn't changed any functionality.
Is the refactored code easier to understand and maintain? Refactoring should result in code that is easier to understand and maintain for anyone working on it.
Are there lessons learned that can be applied to future refactorings? Refactoring is a learning opportunity. After each refactoring, it's helpful to reflect on what worked well, what could have been done differently, and what might apply in the future.
Finally, it's important to remember that code refactoring is not a once-and-forget process. It's an ongoing process, a practice that should be built into your daily workflow. When handled this way, refactoring becomes a powerful tool for detecting and fixing bugs, improving code readability, and promoting a culture of teamwork.
But how does this benefit everyone on the team?
The answer is simple: it improves comprehension, communication and collaboration. Each team member, by adopting refactoring as part of their daily routine, becomes more aware of their own coding and that of their peers. They learn to question, to deeply understand the logic behind the code, and become more capable of detecting and correcting bugs.
Refactoring, ultimately, is a form of care for the code, care for the work of teammates and the quality of the final product. This creates a culture of accountability and collaboration that goes beyond catching bugs. It creates an environment where everyone is aware of the importance of code quality and strives to achieve it.
Conclusion
We can conclude with Fowler's words in his talk at [XConf Brasil 2019] - Introduction to Refactoring, the presentation is available on Youtube:
But the reason you want to refactor regularly is that you produce new features quickly. Refactoring lets you do things faster over time. So it's important whenever you discuss refactoring with someone and try to justify it, focus on the economics. Focus on the fact that it allows you to release more features faster. So it's not a case of refactoring or more features. It's refactoring to produce more features. - Martin Fowler.
Refactoring is fundamental in the software development lifecycle and, as Fowler emphasizes, its usefulness goes beyond mere improvement of code quality: it is a technique that accelerates the delivery of new functionality. While often seen as a task that takes the team away from their new feature development goals, it is actually the key to maintaining a long-term sustainable development velocity.
In this context, refactoring also stands out as an efficient bug detection technique. At first glance, it might seem like we're diverting valuable resources that could be used to develop new features. However, if we consider the amount of time a development team spends dealing with bugs, we can see that refactoring can indeed save time and effort.
By reorganizing the code to make it clearer and less coupled, we're making bugs easier to catch and fix. Clean and well-structured code not only facilitates the identification of bugs, but also makes the insertion of new features a process less likely to generate new errors.
So, when we make refactoring a regular practice, we are not only increasing the speed with which we can add new functionality, but we are also decreasing the incidence of bugs and, consequently, the time spent on fixing them. It's like Martin Fowler mentioned: "It's not a case of refactoring or more features. It's refactoring to produce more features."
Therefore, refactoring should not be seen as a waste of time, but rather as an investment. An investment that will enable more effective bug detection and, consequently, a faster and more efficient software development process.
Thank you so much for reading until the end and I'm glad if you share this post with other programmers. If you have any questions, leave them in the comments. Until the next post! 😄
When we talk about code as an "asset" or a "liability", we're using a metaphor from the financial world. In the business world, an asset is something that creates value for the company, while a liability is something that costs the company money. When we apply this metaphor to software code, it takes on an interesting interpretation.
If we consider the code as an asset, it implies that the code itself brings value. We might think so because, after all, the code is the concrete manifestation of the software product which, in turn, generates revenue for the company. In this sense, the more code, the more functionality and, consequently, the more value.
On the other hand, if we think of code as a liability, it suggests that each line of code represents a future obligation, a potential cost. Code needs to be maintained, tested, fixed and updated. Coding errors can lead to failures that cost a company time, money and even reputation. Furthermore, each new line of code makes the software as a whole more complex, potentially introducing new bugs and making the software harder to understand and modify.