
Um breve mergulho no DynamoDB
Por que sua mentalidade Relacional está matando a performance da sua aplicação (e como resolver).

Hoje o papo é sobre um gigante que, muito provavelmente, você já cruzou ou vai cruzar na sua jornada de desenvolvimento na nuvem: o Amazon DynamoDB.
Sendo bem sincero com vocês: a primeira vez que a gente mexe com DynamoDB, a sensação pode ser um pouco... desconfortável. A maioria de nós vem daquela escola clássica dos bancos relacionais (o bom e velho SQL), onde tudo é tabelinha normalizada e os JOINs resolvem magicamente qualquer problema.
Aí você chega no Dynamo e descobre que JOIN não existe, que modelar dados parece um quebra-cabeça e que você precisa saber exatamente como vai consultar o dado antes mesmo de criá-lo. Dá um nó na cabeça de qualquer um no começo, né?
Eu sei, a AWS tem uma documentação oficial extremamente robusta. Tem de tudo lá, é uma bíblia técnica. Mas, justamente por ser tão completa, às vezes a gente se sente tentando beber água de um hidrante: é tanta informação, limite e configuração que fica difícil filtrar o que é teoria do que é “vida real”.
O meu objetivo com este artigo é facilitar o seu caminho.
Não quero apenas replicar o manual. Quero ter uma conversa franca sobre como usar essa ferramenta no dia a dia, focando no que realmente importa, nas “cicatrizes” de batalha e nas lições que a gente costuma aprender da maneira mais difícil.
Vamos percorrer juntos tópicos essenciais para dominar esse banco, passando por:
A arte de escolher Partition Keys (PK) e Sort Keys (SK);
O famoso (e às vezes polêmico) Single Table Design;
A matemática real dos custos de leitura e escrita;
O lado obscuro dos GSIs e as armadilhas perigosas do comando Scan;
E, claro, como lidar com transações e dados gigantes;
Então, pega um café, ajusta a cadeira e bora conhecer o DynamoDB.
A Anatomia da Chave Primária: Onde tudo começa (e onde tudo pode terminar mal)
Se você vem do mundo dos bancos relacionais, a “Chave Primária” (Primary Key) geralmente é algo trivial: um campo ID autoincremental (1, 2, 3...) ou um UUID que você cria apenas para garantir unicidade e fazer alguns JOINs depois.
No DynamoDB, a Chave Primária é muito mais do que um identificador único. Ela é o destino, o mapa e o motor de performance do seu dado.
Para começar, precisamos entender que existem dois tipos de Chaves no DynamoDB:
Chave Simples: Composta apenas pela Partition Key (PK).
Chave Composta: Composta pela Partition Key (PK) + Sort Key (SK).
Vamos dissecar cada uma delas e entender por que essa escolha tira o sono de muito arquiteto de software.
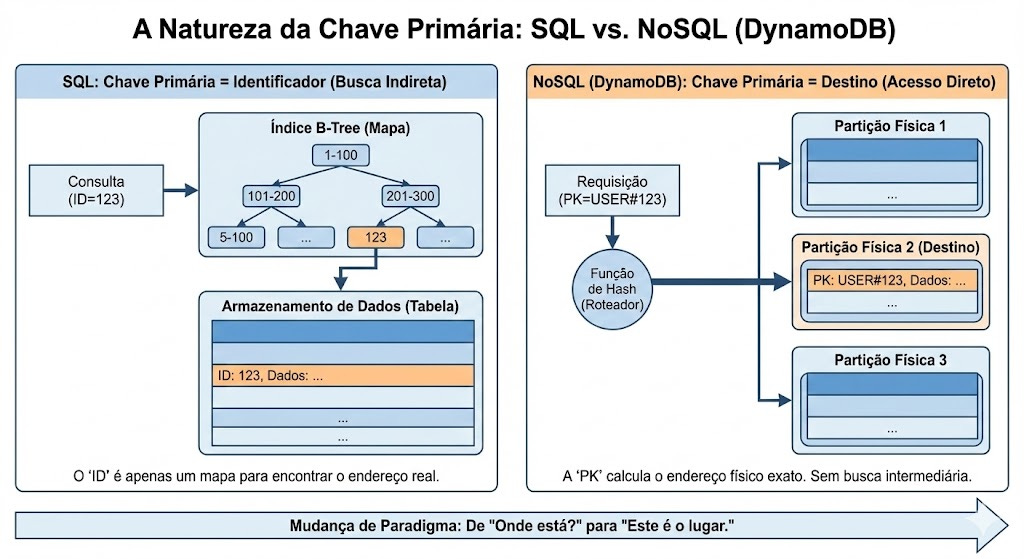
A Anatomia da Chave Primária: O “GPS” Matemático do DynamoDB
Para dominar o DynamoDB, você precisa esquecer como um banco SQL funciona.
No SQL, quando você busca um ID=50, o banco vai até um índice (geralmente uma árvore B-Tree), percorre os galhos da árvore procurando onde está o 50, pega o ponteiro e vai até o disco. É uma busca.
No DynamoDB, a Partition Key (PK) não serve para “buscar”. Ela serve para calcular.
O que é a Partition Key (PK) realmente?
O nome técnico dela é Hash Key. E esse nome não é à toa. A PK é a entrada de uma Função de Hash.
O processo interno é o seguinte:
Você envia o dado:
PK = “USER#123”.O DynamoDB pega essa string e passa por uma função criptográfica interna.
O resultado é um número hexadecimal gigante (o hash).
O DynamoDB olha para esse número e diz: “O hash resultante cai no intervalo que pertence à Partição 3“.
Por que isso muda tudo?
Isso elimina a necessidade de percorrer índices.
No SQL (B-Tree): O banco precisa navegar pelos galhos da árvore de índice. Quanto mais dados (1 milhão vs 1 bilhão), mais profunda é a árvore e mais “saltos” o banco precisa dar para achar o endereço do dado. A latência aumenta ligeiramente com o tamanho.
No DynamoDB (Hash Table): O cálculo do Hash tem complexidade constante O(1). Mas o segredo é o que acontece depois: esse hash funciona como uma coordenada direta. O Request Router da AWS usa esse hash para ir diretamente ao nó de armazenamento correto. Ele não “procura” o dado; ele sabe onde está.
É por isso que a latência do DynamoDB é previsível. Não importa se sua tabela tem 1 GB ou 100 TB, o número de etapas para chegar ao dado é o mesmo. A PK não é apenas um ID, é o endereço físico matemático do item.
A Escalabilidade Horizontal
Imagine que o DynamoDB não é um “supercomputador gigante”, mas sim um exército de milhares de computadores pequenos (nós).
A Partition Key é a ferramenta de Sharding (Fragmentação) automática.
Se todos os seus usuários tiverem a PK
BRASIL, todos os dados cairão no mesmo computador. Esse computador vai lotar e travar.Se cada usuário tiver uma PK única (
USER#A,USER#B...), o algoritmo de hash vai espalhar matematicamente esses dados entre os milhares de computadores disponíveis.
Resumo: A PK não é apenas um ID. Ela é a instrução de roteamento que garante que seu dado seja distribuído uniformemente pelo cluster da AWS, evitando que um único servidor sofra sobrecarga.
Como escolher bem sua Primary Key (PK)?
A regra de ouro aqui é: Alta Cardinalidade.1
Você quer uma PK que tenha muitos valores únicos diferentes.
Escolha Ruim:
Status(Valores: “Pendente”, “Aprovado”, “Cancelado”).Por que é ruim? Você só terá 3 partições lógicas. Se você tiver 1 milhão de pedidos e todos estiverem como “Aprovado”, todo o tráfego de leitura e escrita vai martelar um único nó do banco. Isso cria uma Hot Partition (vamos ter um tópico para falar sobre isso). O DynamoDB vai engasgar e limitar suas requisições (Throttling).
Escolha Boa:
UserIDouDeviceID(Valores: Milhões de UUIDs diferentes).Por que é boa? Os dados e o tráfego são distribuídos uniformemente por todo o cluster da AWS.
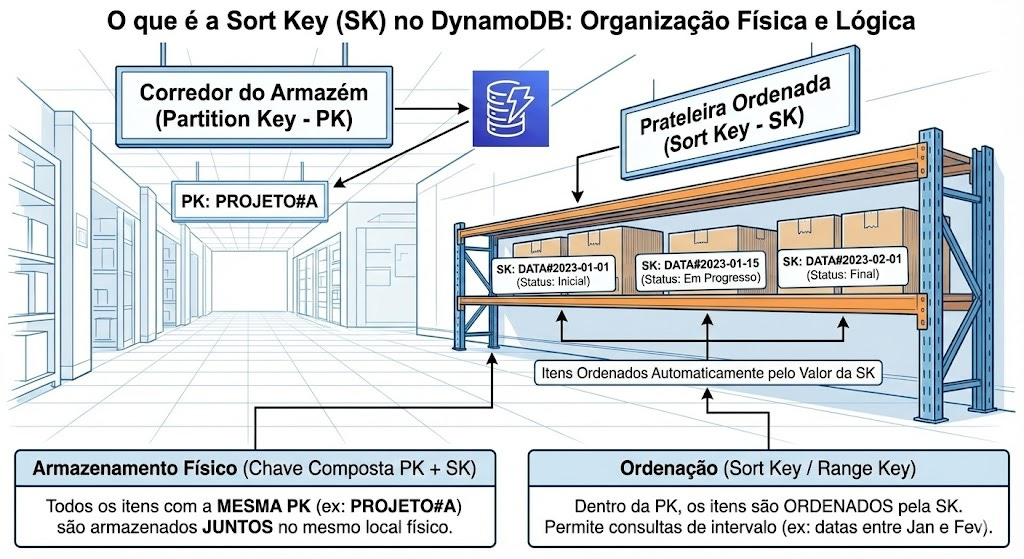
O que é a Sort Key (SK)?
Também conhecida como: Range Key.
Se a PK é o “Corredor” do armazém, a Sort Key é a organização da prateleira dentro desse corredor.
Quando você usa uma Chave Composta (PK + SK), o DynamoDB faz algo mágico: ele garante que todos os itens que compartilham a mesma PK serão armazenados fisicamente juntos e ordenados pelo valor da SK.
Por que precisamos dela?
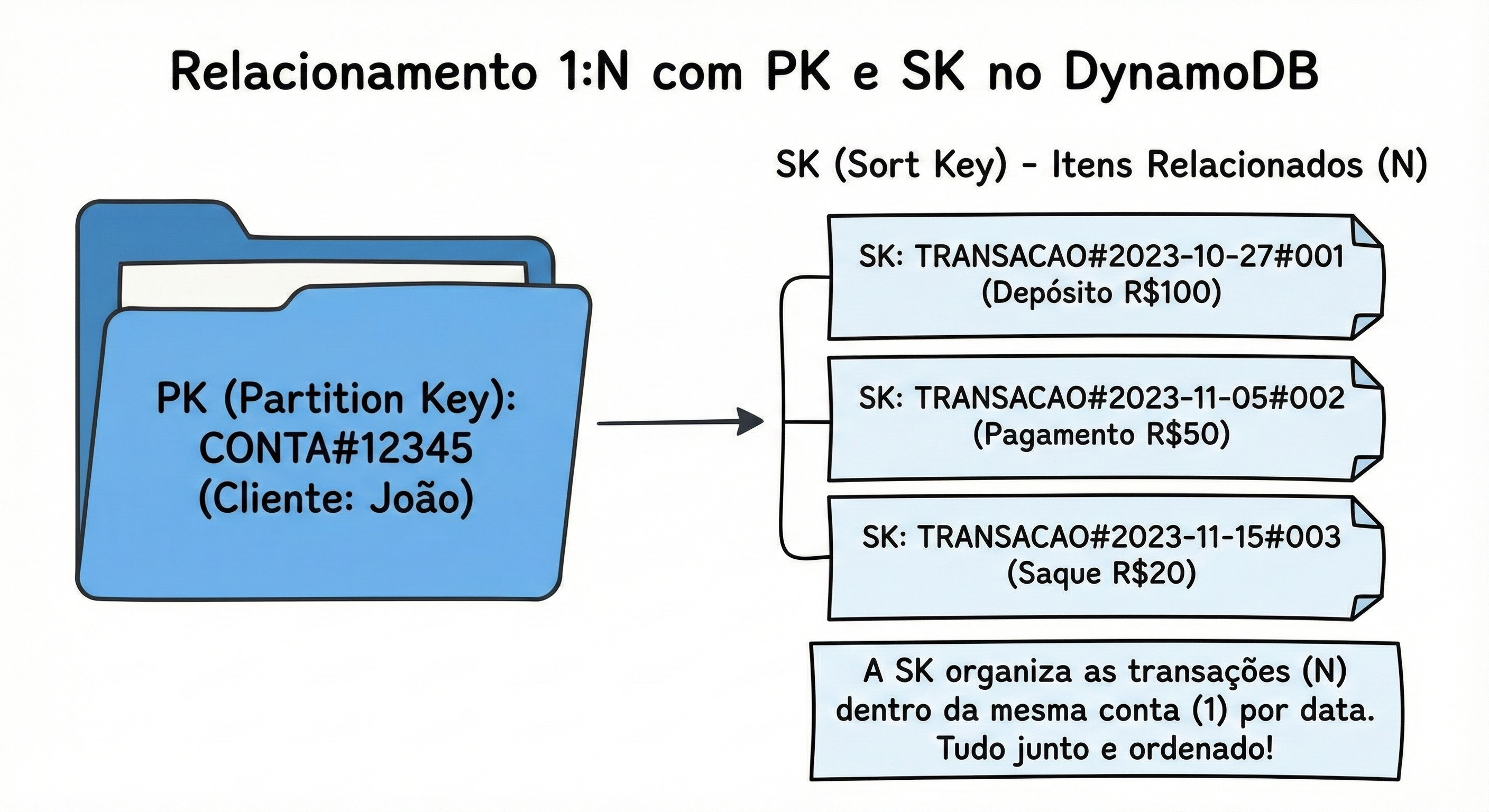
Precisamos dela para Modelar Relacionamentos 1:N e para Queries Complexas.
Sem a SK, você só conseguiria buscar um item pelo ID exato (GetItem). Com a SK, você ganha superpoderes de pesquisa dentro de uma partição.
Como a SK está relacionada à PK?
A relação é de hierarquia e agrupamento.
PK: Agrupa os dados (Ex: “Tudo sobre o usuário João”).
SK: Identifica o dado específico dentro do grupo (Ex: “Perfil”, “Pedido #1”, “Pedido #2”).
Melhores práticas para usar Sort Keys (SK)
Aqui é onde a arte da modelagem acontece. Uma SK bem escolhida permite que você recupere exatamente o que precisa com uma única requisição, gastando o mínimo de dinheiro.
1. Use Sort Keys para criar Hierarquias
Imagine que você está armazenando dados geográficos.
PK:
Country#BRASILSK:
State#SP#City#CAMPINAS
Isso permite que você use a função begins_with na sua query.
Quero todas as cidades de SP? Query onde PK é
Country#BRASILe SK começa comState#SP. O DynamoDB lê apenas esse bloco sequencial de dados. É extremamente rápido.
2. Use Sort Keys para Versionamento
Em sistemas de auditoria ou controle de documentos.
PK:
DOC#123SK:
v1,v2,v3...
Você pode fazer uma Query pedindo para listar em ordem decrescente (ScanIndexForward = false) e limitar a 1 item (Limit = 1) para pegar sempre a versão mais atual do documento instantaneamente.
3. Datas ISO 8601 são suas melhores amigas
Se o seu acesso é temporal (ex: extrato bancário, logs, histórico de pedidos), use datas no formato ISO (YYYY-MM-DDThh:mm:ss).
PK:
CONTA#12345SK:
2023-10-27T14:30:00
Como a SK ordena o dado fisicamente, strings ISO ordenam cronologicamente de forma perfeita. Isso permite queries do tipo: “Me dê todas as transações da conta 12345 que aconteceram entre dia 01 e dia 15”.
4. O “Pulo do Gato”: Nomes Genéricos (Generic Names)
Se você pretende usar Single Table Design (que falaremos adiante), pare de batizar suas colunas de chave como UserId ou OrderId. No DynamoDB, a prática de mercado é chamar as colunas simplesmente de PK e SK.
Por que fazer isso? Porque isso desacopla o esquema físico do significado lógico, permitindo armazenar tipos de dados completamente diferentes na mesma tabela.
Na linha 1, a coluna
PKpode guardar um Usuário.Na linha 2, a mesma coluna
PKpode guardar um Pedido.
“Mas eu quero usar o CPF como chave, posso?” Com certeza! O segredo está nos prefixos. Você não cria uma coluna chamada CPF, você usa a coluna PK e preenche o valor com CLIENTE#11122233344.
Ao fazer isso, você organiza a casa: o prefixo (CLIENTE# ou PEDIDO#) diz o que é aquele dado, e o sufixo (o CPF ou UUID) diz quem é aquele dado. Tudo isso morando harmoniosamente na mesma coluna genérica.

A regra de ouro da modelagem:
“Projete sua PK para espalhar os dados uniformemente (evitar hot spots). Projete sua SK para agrupar os dados que você precisa ler juntos (query eficiente).”
No próximo tópico, vamos pegar esses conceitos e aplicar no Single Table Design, onde vamos aprender a colocar Usuários, Pedidos e Produtos tudo nessa estrutura de PK e SK que acabamos de conversar.
O Dilema do Single Table Design: Uma tabela para todos governar
Se você mostrasse um diagrama de Single Table Design (STD) para um DBA de banco relacional nos anos 90, ele provavelmente teria um ataque cardíaco.
A ideia de colocar Usuários, Pedidos, Produtos e Notas Fiscais tudo misturado dentro de uma única tabela (MinhaApp) parece violar todas as leis de organização que aprendemos na faculdade. Parece caótico. Parece errado.
Mas, no DynamoDB, isso não só é “certo”, como é o estado da arte da performance. Para entender o porquê, precisamos entender de onde essa loucura nasceu.
De onde nasceu esse conceito?
No mundo SQL, a normalização de dados (criar várias tabelas separadas) existe para economizar espaço em disco. Antigamente, armazenamento era caro. Então, você salvava o nome “João” na tabela Usuarios e apenas referenciava o ID dele na tabela Pedidos. Para ver o nome do João junto com o pedido, o banco de dados fazia um JOIN — uma operação de CPU pesada que “cola” as tabelas na hora da leitura.
O Problema: Quando você tem milhões de usuários e bilhões de pedidos, os JOINs começam a ficar lentos. O banco precisa pular de um lugar para outro no disco para montar a resposta.
O DynamoDB foi criado para rodar na escala da Amazon.com (o e-commerce). Eles perceberam que espaço em disco é barato, mas tempo de CPU é caro.
O Single Table Design nasceu de uma premissa simples: E se a gente já deixasse os dados “pré-juntados” no disco?
Em vez de gastar CPU para fazer JOIN na hora que o cliente pede (Leitura), nós organizamos os dados fisicamente juntos na hora de salvar (Escrita). O STD resolve o problema da latência de rede e processamento: ele elimina a necessidade de fazer múltiplas requisições para buscar dados relacionados.
Como funciona na prática: A Arte da “Sobrecarga” (Key Overloading)
Lembra que falamos sobre nomes genéricos (PK e SK)? É aqui que eles brilham. No STD, nós usamos uma técnica chamada Key Overloading (Sobrecarga de Chave). Isso significa que a coluna SK vai ter significados diferentes dependendo da linha.
Vamos visualizar o cenário clássico de E-commerce: “Quero buscar um Cliente e ver todos os pedidos dele de uma vez só”.
No SQL, seriam duas tabelas e um JOIN. No DynamoDB Single Table, modelamos assim:
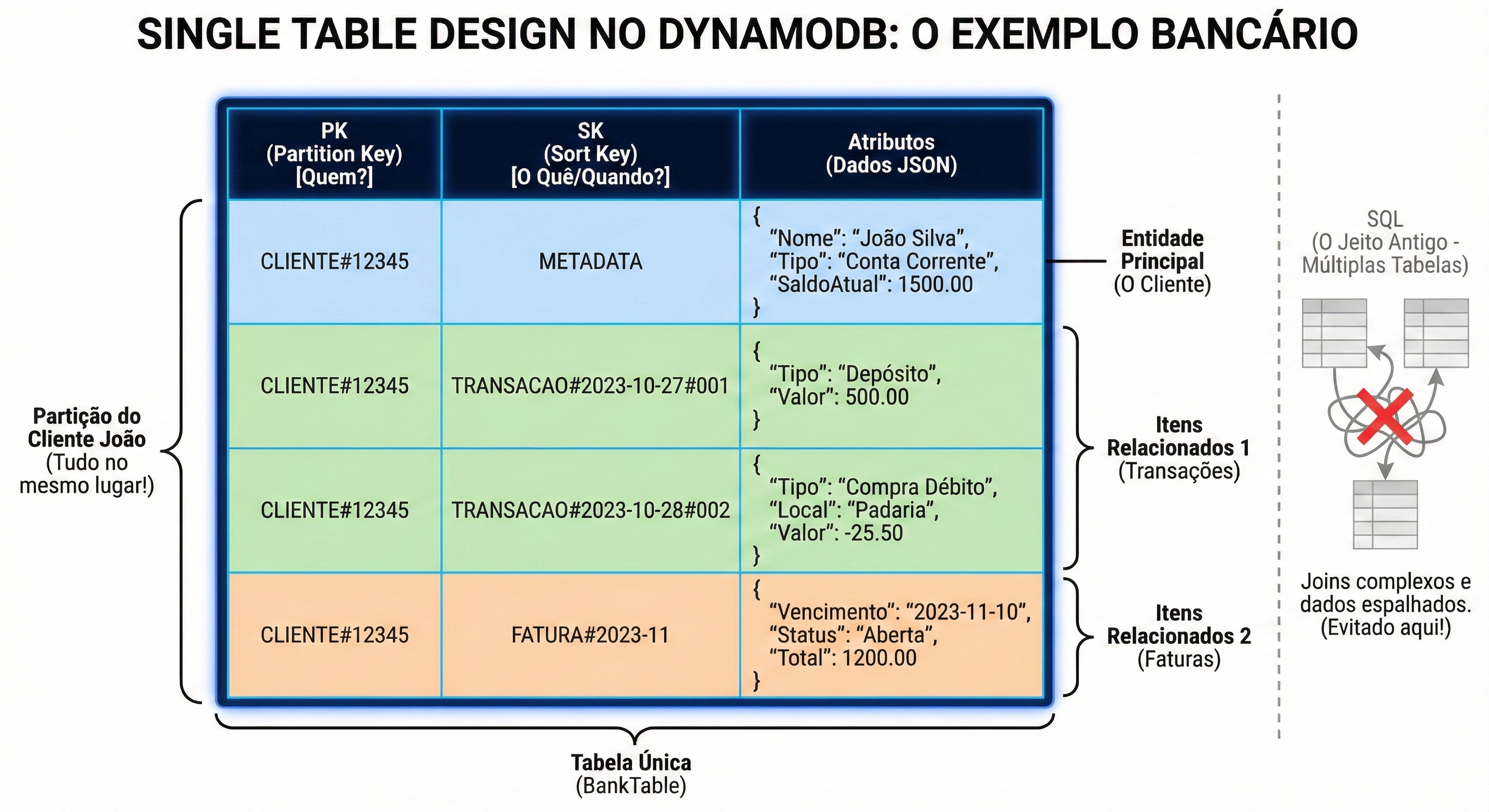
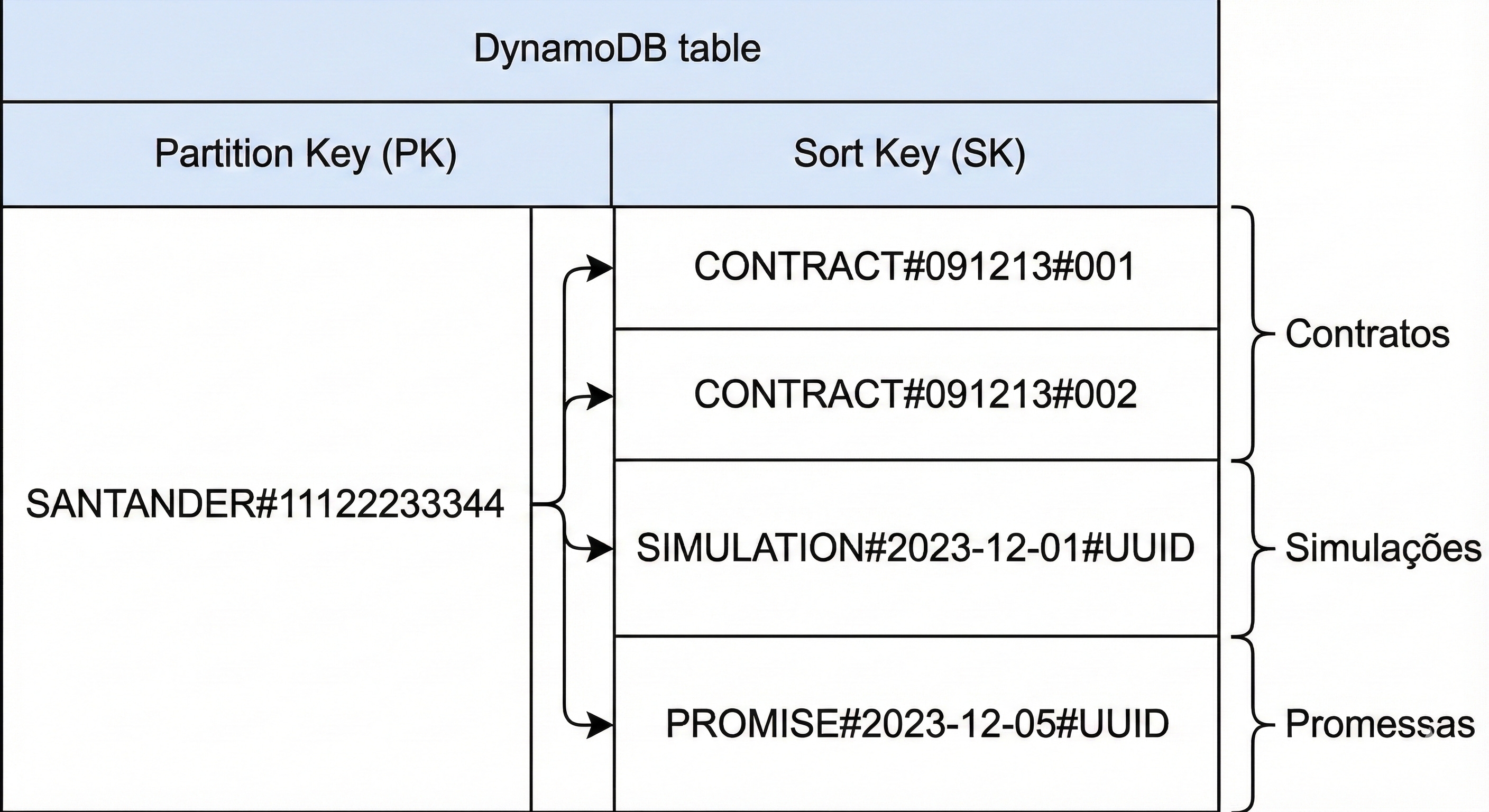
Observe a mágica acontecendo na primeira coluna da imagem. Veja que o Perfil (METADATA), as Transações (TRANSACAO#...) e até a Fatura (FATURA#...) compartilham rigorosamente a mesma Partition Key: CLIENTE#12345.
Isso cria o que a chave lateral da imagem destaca como "Partição do Cliente João" — tecnicamente chamado de Item Collection (Coleção de Itens). O DynamoDB garante que todos esses dados, embora sejam entidades diferentes (JSONs com atributos distintos), sejam armazenados fisicamente vizinhos, "colados" uns nos outros no mesmo servidor.
Agora, olhe para o diagrama SQL riscado à direita da imagem. Para obter esses dados no modelo antigo, você precisaria de múltiplos JOINs entre tabelas espalhadas. Aqui, para buscar o perfil do João, seu extrato e suas faturas, você faz apenas uma Query:
Condição: PK = "CLIENTE#12345"
Custo: 1 única viagem de rede (ida e volta).
O banco lê esse "bloco azul" sequencialmente e te devolve tudo de uma vez. É uma performance imbatível. Você acabou de "emular" os JOINs complexos de Clientes, Transações e Faturas com custo computacional quase zero.
O Lado Amargo: STD não é bala de prata
Depois de ler isso, a vontade é sair convertendo tudo para Single Table. Calma.
O Single Table Design tem um “custo cognitivo” alto. Ele é rígido.
A curva de aprendizado é alta: É difícil explicar para novos desenvolvedores do time por que a tabela está “misturada”.
Rigidez nas Consultas: Você precisa desenhar a tabela baseado nas perguntas (Access Patterns)2 que você tem hoje. Se daqui a 6 meses o chefe chegar e disser: “Agora quero filtrar pedidos pelo tipo de cartão de crédito”, e você não previu isso na sua SK, você terá um problema sério. Adicionar novos padrões de acesso em uma Single Table já populada é doloroso.
Analytics e BI: Ferramentas de BI (como Tableau, PowerBI) odeiam Single Table Design. Elas esperam tabelas normalizadas. Tentar rodar queries analíticas (”Qual a média de vendas por estado?”) em uma STD é ineficiente e caro.
Use Multi-Table (uma tabela por entidade) se você está prototipando, se seu produto muda toda semana, ou se você precisa de flexibilidade para queries ad-hoc que você ainda nem sabe quais serão. Não há vergonha nenhuma em usar múltiplas tabelas no DynamoDB se isso simplificar sua vida e a performance for aceitável.
Lidando com Itens Gigantes e a Arte do Particionamento Vertical (Case Real)
O DynamoDB impõe um limite rígido: um único item não pode exceder 400KB.3
Pode parecer muito. Afinal, 400KB de texto puro é quase um livro. Mas no dia a dia, especialmente quando trazemos vícios de outros bancos (Relacional ou Documentais como MongoDB), esse limite chega mais rápido do que imaginamos.
Vou ser transparente com vocês: eu bati de frente com essa parede.
No início, minha mentalidade ainda estava presa ao modelo relacional. Eu olhava para um “Cliente” e queria guardar tudo sobre ele num único registro gigante. Histórico de simulações, contratos, logs de auditoria... eu ia anexando tudo num JSON aninhado que só crescia. O resultado? Itens obesos, lentidão na rede e o risco iminente de estourar o limite do banco.
Eu precisei dar um passo atrás. Parei de codar, respirei fundo e voltei para a prancheta de Access Patterns. Entendi que o segredo não é guardar tudo junto, mas guardar de forma que eu consiga ler apenas o necessário.
Foi aí que apliquei o Particionamento Vertical em um case real de sistema financeiro no qual trabalhei, e é essa modelagem que quero compartilhar com vocês.
Segregação e Temporalidade na SK
O desafio era gerenciar dados de crédito onde um cliente (identificado por CPF) poderia ter contratos, fazer dezenas de simulações e registrar promessas de pagamento.
Em vez de criar um item gigante do tipo “Dossiê do Cliente”, quebrei esse cliente em várias linhas pequenas na mesma tabela, usando a Sort Key (SK) para organizar a bagunça.
A estrutura ficou assim:
Partition Key (PK):
BANCO#CPF(Ex:SANTANDER#11122233344)Por que? Garante o isolamento entre instituições (Multi-tenant) e usa o CPF para dar a alta cardinalidade que o DynamoDB precisa.
Sort Key (SK): Aqui está a mágica da segregação.
Contratos: CONTRACT
#091213#001, CONTRACT#091213#002...Simulações:
SIMULATION#2023-12-01#UUIDPromessas:
PROMISE#2023-12-05#UUID
Veja como isso fica no banco:
O que conseguimos alcançar?
Fim dos Itens Gigantes: Cada simulação é uma nova linha de apenas 1KB ou 2KB. Eu posso ter 1 milhão de simulações para esse cliente e nunca vou estourar o limite de 400KB do item, porque são itens diferentes (Item Collection).
Ordenação Temporal Automática: Ao colocar a DATA ISO 8601 na SK (
SIMULATION#2023...), como falamos no tópico anterior o DynamoDB ordena cronologicamente.Query Poderosa: “Quero as últimas 5 simulações”. Basta fazer uma Query com
ScanIndexForward=FalseeLimit=5. O banco nem lê o resto.
Idempotência com UUID: Perceba que finalizei a SK com
#UUID. Isso evita colisão se o cliente gerar duas simulações no mesmo milissegundo. Cada evento é único.Query Híbrida: Se eu quiser saber “Tudo sobre o cliente”, faço uma Query apenas pela PK. O DynamoDB traz contratos, simulações e promessas num pacote só, mas estruturado.
E quando o item é realmente um binário pesado? (O Padrão Claim Check)
Mesmo com essa modelagem, as vezes precisamos guardar um PDF do contrato ou uma imagem de comprovante. Nesses casos, não tente forçar a barra guardando Base64 no DynamoDB.
Siga a recomendação oficial da AWS e use o padrão Claim Check:
Salve o arquivo pesado no Amazon S3 (que é feito para isso e custa muito menos).
Salve no DynamoDB apenas o link (a URL do S3) e os metadados.
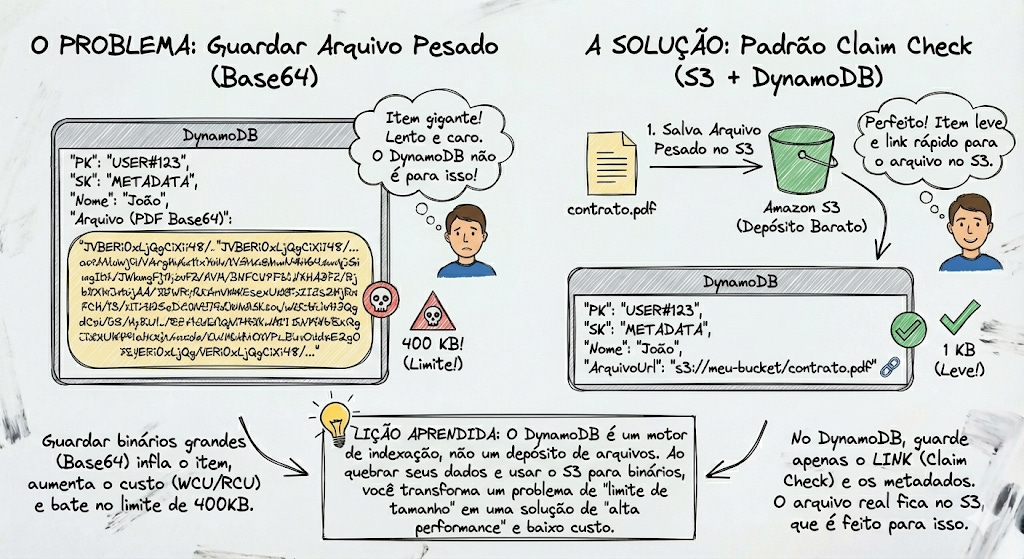
Lição Aprendida: O DynamoDB não é um depósito de arquivos, nem um JSON infinito. Ele é um motor de indexação e recuperação rápida. Ao quebrar seus dados verticalmente, você transforma um problema de “limite de tamanho” em uma solução de “alta performance”.
Agora vamos mudar um pouco o foco e entrar em um outro lado… Chegamos na parte onde os engenheiros viram contadores.
Ao contrário de um banco de dados tradicional (RDS/SQL) onde você paga pelo “tamanho da máquina” (CPU e RAM) e pode usar o quanto aguentar, no DynamoDB você paga pelo tráfego. Você paga por cada leitura e cada escrita.
Vamos colocar isso na ponta do lápis, porque a matemática do DynamoDB é implacável e cheia de “pegadinhas”.
Custo Real: O que são WCU e RCU?
Para a AWS, não importa se sua query demorou 1ms ou 100ms. O que importa é o tamanho do dado que você mexeu. Para medir isso, eles criaram duas “moedas”:
WCU (Write Capacity Unit): Unidade de Capacidade de Escrita.
RCU (Read Capacity Unit): Unidade de Capacidade de Leitura.
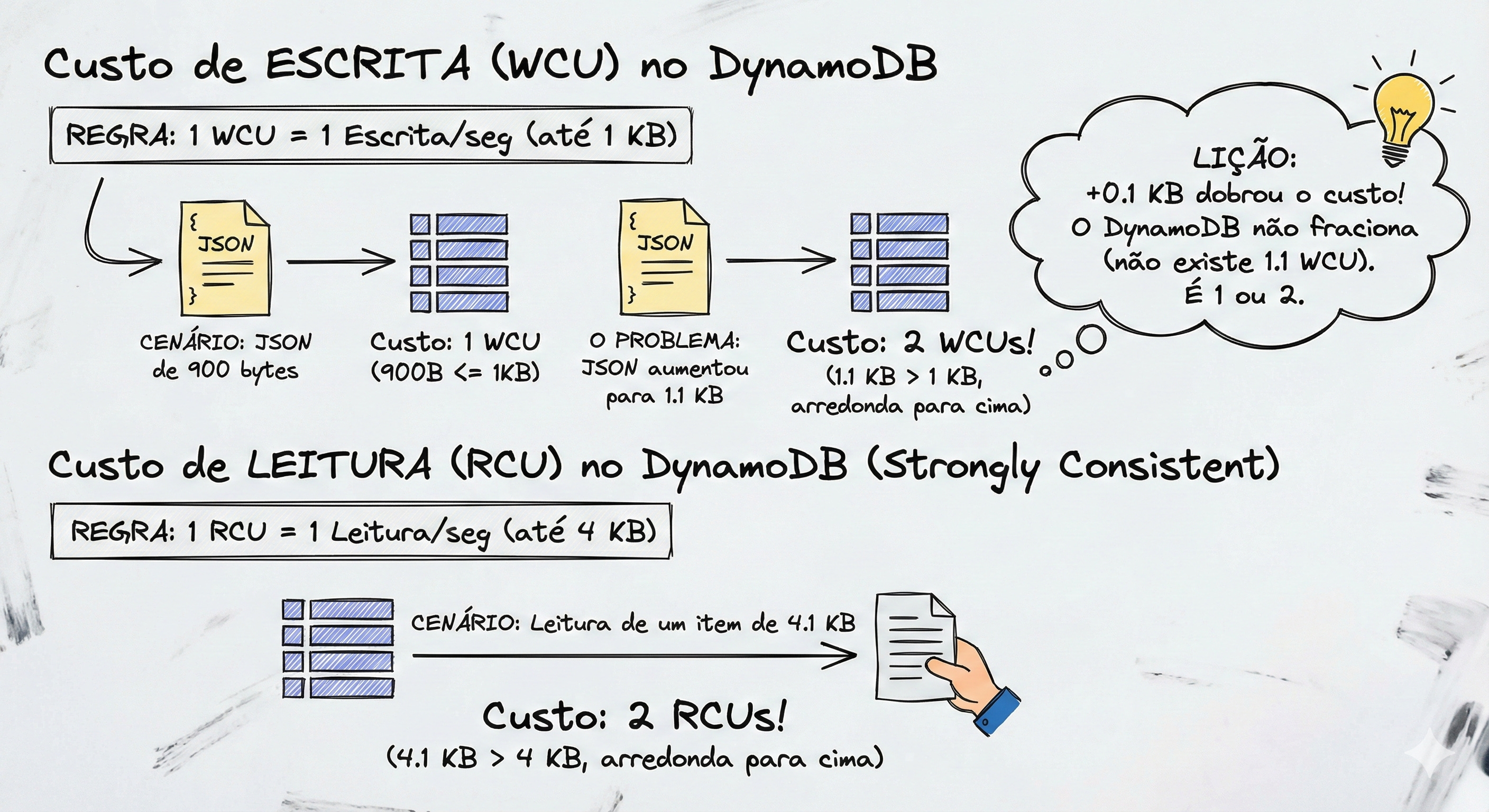
A Matemática “Cruel” do Arredondamento
Aqui mora o perigo. A AWS cobra por blocos, e o arredondamento é sempre para cima.
Para Escrita (WCU):
Regra: 1 WCU permite escrever um item de até 1 KB por segundo.
O Cenário: Você tem um JSON de usuário super otimizado com
900 bytes.Custo: 1 WCU.
O Problema: Você adicionou uma descrição nova e o JSON foi para
1.1 KB.Custo: 2 WCUs.
Lição: Por causa de 0.1 KB (100 bytes), sua conta dobrou. O DynamoDB não cobra “1.1 WCU”. É 1 ou 2.
Para Leitura (RCU):
Regra: 1 RCU permite ler um item de até 4 KB por segundo (no modo Strongly Consistent).
Se você ler um item de
4.1 KB, você pagará 2 RCUs.
Provisioned vs On-Demand: Onde está o risco?
A AWS te dá duas formas de comprar essas moedas. A escolha errada aqui pode derrubar sua aplicação ou falir seu orçamento.
1. Mode: On-Demand (Sob Demanda)
É o modelo “Uber”. Você não combina nada antes. Se tiver tráfego, o DynamoDB escala instantaneamente para atender.
Vantagem: Zero dor de cabeça com planejamento. É perfeito para startups ou cargas de trabalho imprevisíveis (ex: um pico de acesso repentino).
Desvantagem: É o preço “Premium”. O custo por requisição chega a ser 5 a 7 vezes mais caro do que o modo provisionado otimizado.
Preço (Estimativa base US-East-1):
Escrita: 1.25 por milhão de unidades.
Leitura: 0.25 por milhão de unidades.
Pode parecer centavos, mas em sistemas com alto throughput, isso vira milhares de dólares rápido.
2. Mode: Provisioned (Provisionado)
É o modelo “Aluguel”. Você diz para a AWS: “Eu prometo que vou precisar de 100 Writes por segundo e 50 Reads por segundo”, e ela deixa essa capacidade reservada para você, 24 horas por dia.
Vantagem: É muito mais barato se você tiver fluxo constante.
Desvantagem: Você paga pela capacidade reservada, usando ou não. Se você reservar 100 WCUs e seu site ficar vazio na madrugada, você paga pelas 100 WCUs do mesmo jeito (a menos que configure Auto-Scaling, que tem um delay para reagir).
O Custo na Ponta do Lápis (Baseado US East N. Virginia): Olhando a tabela oficial, o custo é cobrado por hora para cada unidade que você provisiona:
WCU (Write): 0.00065 por hora.
RCU (Read): 0.00013 por hora.
“Isso é barato ou caro?” Vamos fazer uma conta de padaria para comparar com o On-Demand. Imagine uma aplicação que precisa sustentar 10 escritas por segundo constantes durante um mês inteiro (720 horas).
No Provisioned:
10 WCUs x 0.00065 x 720 horas = $4.68 dólares/mês.
No On-Demand (estimado):
10 escritas/seg x 60 seg x 60 min x 720 horas = 25.9 milhões de escritas.
25.9 milhões x $1.25 (preço médio por milhão) = 32.37 dólares/mês.
O Provisioned custou quase 7x menos nesse cenário de carga constante. Por isso, grandes empresas fogem do On-Demand assim que o tráfego estabiliza. O On-Demand é excelente para picos, mas o Provisioned é quem paga as contas do dia a dia.
O Perigo do Provisioned: “Podemos acabar não persistindo dados?”
A resposta técnica é: O banco não perde, mas sua aplicação pode desistir.
Imagine que você configurou (provisionou) 10 WCUs (10 escritas por segundo). De repente, sua aplicação recebe um lote de 50 requisições simultâneas.
O DynamoDB aceita as primeiras 10.
Para as outras 40, o DynamoDB devolve um erro HTTP 400:
ProvisionedThroughputExceededException. Isso é o famoso Throttling (em breve explico mais).O que acontece agora?
O SDK da AWS (que você usa no código) é inteligente. Ele captura esse erro e tenta de novo automaticamente (Retries) usando Exponential Backoff (espera um pouco e tenta, espera mais um pouco e tenta...).
Se o tráfego continuar alto por muito tempo, o SDK vai cansar de tentar e vai estourar o erro na cara da sua aplicação.
O Resultado: Se você não tiver um tratamento de erro (
try/catch) para salvar esse dado em uma fila morta (DLQ) ou tentar mais tarde, sim, o dado será perdido pela aplicação, porque o banco bateu a porta na sua cara.
Auto-Scaling no Provisioned: A AWS tem um “Auto-Scaling” para o modo provisionado, mas ele não é instantâneo. Ele demora alguns minutos para reagir. Se o pico for muito rápido (ex: 1 minuto de loucura), o Auto-Scaling não chega a tempo de evitar os erros.
Boas Práticas
Como trabalhar de forma inteligente com essas regras?
1. Nomes de Atributos contam no Custo!
Essa é chocante para muitos. No DynamoDB, o nome da coluna é salvo junto com o valor em cada linha.
Ruim:
{ “CustomerIdentificationNumberOfTheSystem”: 123 }Você está gastando WCU para salvar essa string gigante de chave milhões de vezes.
Bom:
{ “id”: 123 }ou{ “cin”: 123 }Em milhões de registros, encurtar nomes de atributos economiza gigabytes e muitas WCUs.
2. Eventual Consistency (O desconto de 50%)
Por padrão, leituras podem ser “Eventualmente Consistentes”. Isso significa que se você gravar um dado agora e ler 1 milissegundo depois, pode ser que pegue o dado antigo.
Se sua aplicação aceita isso (ex: listar comentários de um blog, histórico antigo), use Eventual Consistency.
Leituras eventuais custam metade do preço (0.5 RCU por 4KB). É um desconto de 50% na fatura apenas mudando um parâmetro na query.
3. Cuidado com Índices (GSIs)
Cada GSI que você cria é, na prática, uma nova tabela oculta. Se você insere um item na tabela principal e esse item precisa ser replicado para 3 índices, você paga a escrita na tabela principal + a escrita no Índice 1 + a escrita no Índice 2 + a escrita no Índice 3. Um insert pode custar 4x mais caro se você tiver muitos índices. Pode ficar confuso agora, mas vamos ter um tópico dedicado para conversar mais.
4. O Mito do “Capacity Planning” Perfeito
Se você tem tráfego previsível (ex: processamento em lote toda madrugada), use Provisioned. Se seu tráfego é errático e você tem medo de Throttling, comece com On-Demand. Você pode alternar entre os modos uma vez a cada 24 horas.
Estratégia: Muitos times começam em On-Demand para aprender o padrão de uso e, depois de um mês, mudam para Provisioned ajustado para economizar.
Query vs. Scan: O Herói e o Vilão
A diferença entre Query e Scan não é apenas técnica; é a diferença entre uma aplicação que responde em milissegundos custando centavos e uma aplicação que trava o banco e estoura o cartão de crédito da empresa.
Muitos desenvolvedores que vêm do SQL (onde um SELECT * FROM tabela é comum) tendem a usar o Scan inadvertidamente. Vamos entender por que isso é um erro grave em produção.
Se o DynamoDB fosse um filme de ação, a Query seria o atirador de elite: silencioso, preciso e letal. O Scan seria o Rambo com uma metralhadora: atira para todo lado, faz muito barulho, gasta toda a munição, mas eventualmente acerta o alvo (depois de destruir o cenário inteiro 😂).

Para dominar o DynamoDB, você precisa entender profundamente a mecânica dessas duas operações.
O Herói: Query (A Operação Cirúrgica)
A operação de Query é a forma “correta” de buscar dados em escala. Ela é projetada para encontrar itens com base na Chave Primária (PK).
Como funciona: Quando você executa uma Query, você obrigatoriamente fornece a PK. O DynamoDB usa sua função de hash interna e vai direto para a partição física onde aquele dado reside. Se você usar também a Sort Key (SK), ele vai direto para o ponto exato da lista ordenada.
Por que é eficiente: O DynamoDB lê apenas os itens que satisfazem sua chave. Se sua partição tem 100 itens e você pediu 5, ele lê e cobra apenas por esses 5 (arredondando para blocos de 4KB).
O Limite: Uma única requisição de Query pode retornar no máximo 1 MB de dados. Se houver mais dados, o DynamoDB devolve uma
LastEvaluatedKey(paginação) para você fazer a próxima requisição e continuar de onde parou.
Imagine um livro gigantesco (a tabela). A
Queryé ir direto ao Índice Remissivo, ver que o tópico “Dinossauros” está na página 42, abrir a página 42 e ler. Tempo gasto: segundos.
O Vilão: Scan (A Arrastão de Dados)
O Scan é a operação mais simples de escrever, mas a mais perigosa de rodar.
Como funciona: O Scan ignora completamente as chaves e índices. Ele abre a tabela na primeira página e começa a ler item por item, linha por linha, até chegar no final da tabela (ou atingir o limite de 1MB).
O Desastre da Escalabilidade: Se sua tabela tem 100 itens, o Scan é rápido. Se ela tem 100 milhões de itens, o Scan vai tentar ler os 100 milhões.
O Custo: Você paga por cada item lido, mesmo que você jogue o item fora depois.
Imagine o mesmo livro gigantesco. O
Scané você ignorar o índice e começar a ler o livro da página 1 até a última página procurando a palavra “Dinossauros”. Você vai demorar dias (latência alta) e vai cansar muito (gasto de RCU).
O Grande Perigo: A Ilusão do FilterExpression
Aqui está a “Lição Aprendida” mais valiosa deste tópico. É onde 90% dos iniciantes caem.
Você pode pensar: “Ah, mas o Scan tem um parâmetro chamado FilterExpression. Se eu usar isso para filtrar apenas os usuários ativos, eu vou economizar dinheiro, certo?”
ERRADO. E perigosamente errado.
É crucial entender a ordem de execução do DynamoDB:
Leitura do Disco: O DynamoDB vai ao disco e lê o dado (Scan).
Cobrança (O Taxímetro): A AWS cobra as RCUs baseadas no dado que foi lido do disco.
Filtragem: Só agora o DynamoDB aplica o seu
FilterExpressione descarta o que não serve.Retorno: Ele te devolve apenas o que sobrou.
Cenário Real de Pesadelo:
Sua Tabela: 1 milhão de usuários.
Seu Objetivo: Achar os 10 usuários que moram no “Acre”.
Sua Ação: Fazer um Scan com
FilterExpression = “Estado = :acre”.
O Resultado:
O DynamoDB lê 1 milhão de itens.
Você paga o consumo de RCU para ler 1 milhão de itens (centenas de dólares se for frequente).
O DynamoDB joga fora 999.990 itens.
Ele te entrega os 10 itens do Acre.
Para a sua aplicação (backend), pareceu que vieram só 10 itens. Mas a fatura da AWS vai cobrar a leitura da tabela inteira. O filtro economiza apenas banda de rede (transferência de dados), mas não economiza processamento nem dinheiro.4
Quando usar Scan então?
O Scan não é inútil. Ele tem seu lugar, mas geralmente é em processos de background, nunca no fluxo síncrono do usuário (aquela tela de loading girando).
Use Scan para:
Backups e Exportações: “Preciso jogar tudo para o S3 (Data Lake) para rodar Analytics”.
Migrações: “Preciso ler tudo para mudar um formato de dado”.
Tabelas de Configuração Pequenas: Tabelas com menos de 100 itens que raramente mudam.
Dica de Ouro: Se você precisa fazer um Scan frequente porque não sabe a PK, você modelou errado. A solução não é otimizar o Scan, é criar um Global Secondary Index (GSI) para transformar esse padrão de acesso em uma Query.
O Segredo dos Índices Esparsos (Sparse Indexes): Menos é Mais
Muitos desenvolvedores acham que um Índice (GSI) é apenas uma cópia completa da tabela principal, reordenada por outra coluna. E, na maioria das vezes, é assim que usamos.
Mas o DynamoDB tem uma regra peculiar e poderosa sobre índices:
“Se um item não possui o atributo definido como Chave do Índice, ele NÃO é copiado para o Índice.”
Em bancos SQL, se você cria um índice numa coluna que está nula (NULL), o banco indexa o nulo. No DynamoDB, o item é simplesmente ignorado. Ele não existe no mundo do índice.
É aqui que nasce o Sparse Index.
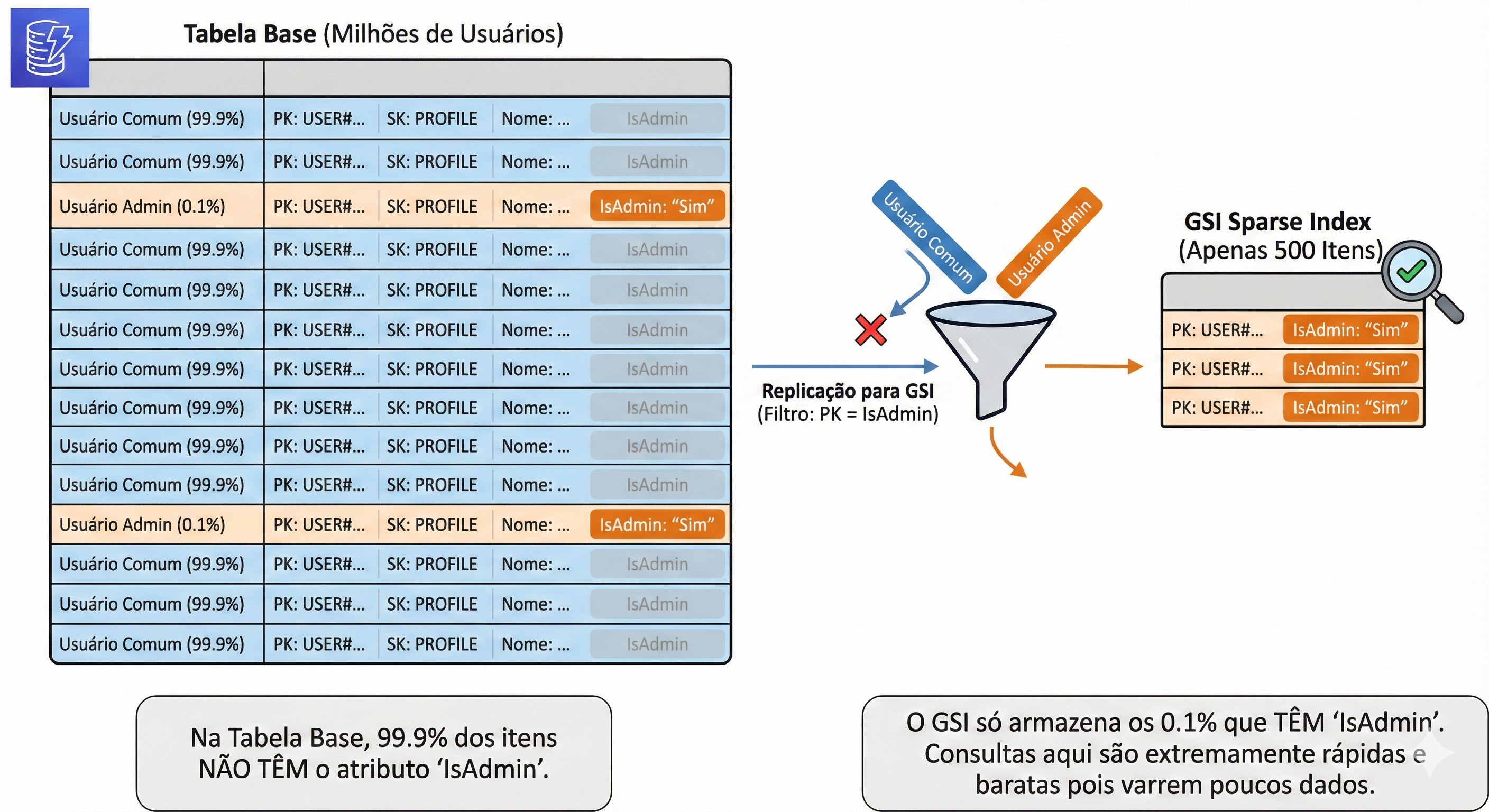
O que é um Índice Esparso?
É um GSI intencionalmente “incompleto”. É um índice que contém apenas uma pequena fração dos itens da sua tabela principal.
Em vez de indexar todos os 1 milhão de usuários, você cria um índice que contém apenas os usuários que atendem a um critério específico.
O Cenário Real: “Ache os Admins”
Imagine que você tem uma tabela de Usuários com 10 milhões de registros. Desses, apenas 500 são Administradores.
Seu chefe pede: “Crie uma tela que lista todos os Admins do sistema.”
Abordagem Ingênua (Scan):
Você faz um
Scanna tabela de 10 milhões de itens comFilterExpression = “Role = ‘ADMIN’”.Custo: Você paga para ler 10 milhões de itens. Caro e lento.
Abordagem Padrão (GSI Comum):
Você cria um GSI na coluna
Role.O índice terá 10 milhões de itens (9.999.500 “USER” e 500 “ADMIN”).
Melhor que o Scan, mas você paga armazenamento por 10 milhões de réplicas e paga WCU (escrita) toda vez que qualquer usuário comum for atualizado.
Sparse Index:
Você cria um atributo novo chamado
IsAdmin.Para os usuários comuns, você não cria esse atributo (deixa ele inexistente).
Para os administradores, você grava:
“IsAdmin”: “Sim”.Você cria um GSI onde a PK é
IsAdmin.
A Mágica: Como 99.9% dos usuários não têm o atributo IsAdmin, o DynamoDB não copia esses usuários para o índice. O seu GSI terá apenas 500 itens.
Resultado da Query: Você faz um
Scannesse índice esparso.Custo: Você paga para ler apenas 500 itens. É quase de graça.
Performance: Instantânea.
Outros Casos de Uso
Pedidos em Aberto:
Tabela de Pedidos tem milhões de históricos. Pedidos abertos são poucos.
Crie um atributo
StatusAberto. Remova esse atributo quando o pedido for entregue. O índice se “limpa” sozinho.
Soft Delete (Lixeira):
Em vez de apagar o dado, você marca com
DeletedAt: “2023-10-27”.Crie um índice na chave
DeletedAt.Seu índice funciona como uma “Lixeira” isolada. Itens ativos (sem essa data) não ocupam espaço lá.
Mensagens Não Lidas:
App de chat. A maioria das mensagens já foi lida. Crie um índice apenas nas que têm flag
Unread.
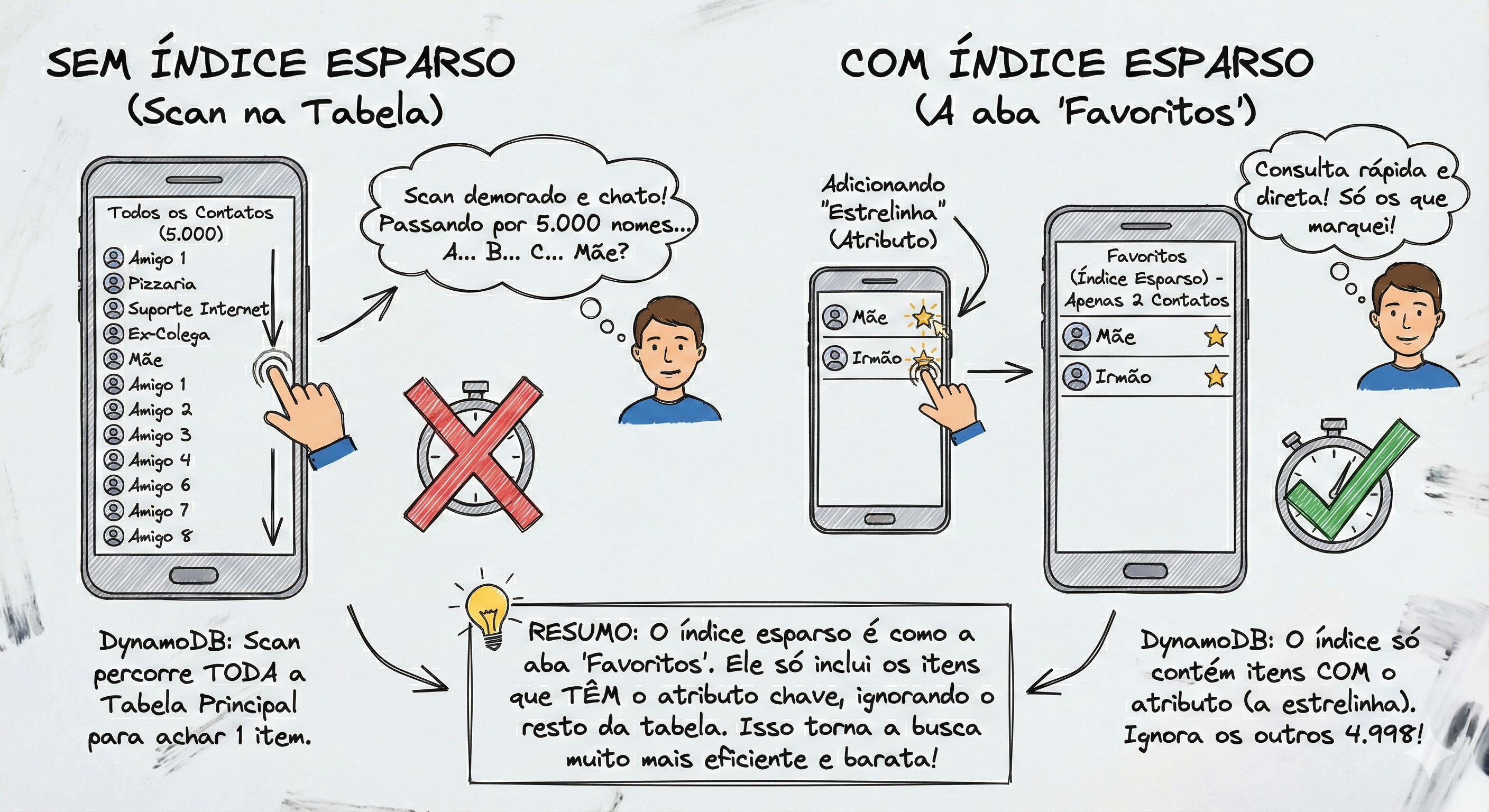
Imagine que você tem 5.000 contatos na sua agenda telefônica (Tabela Principal). Tem todo mundo lá: amigos, ex-colegas, a pizzaria do bairro, o suporte da internet, etc.
Você quer ligar para sua Mãe.
Sem Índice Esparso (Scan na Tabela): Você abre a lista completa (A-Z) e rola a tela para baixo passando por todos os 5.000 nomes até achar “Mãe”. É demorado e chato.
Com Índice Esparso (A aba “Favoritos”): Você clica na estrelinha “Favorito” apenas no contato da sua mãe e do seu irmão. Quando você clica na aba Favoritos (que é o nosso Índice Es
parso), o celular ignora os outros 4.998 contatos. Ele só te mostra os 2 que você marcou.
No DynamoDB, o “clicar na estrelinha” é adicionar o atributo. Se o contato não tem estrelinha, ele nem aparece na lista de Favoritos. Na imagem abaixo tem um breve resumo.

O “Lado Obscuro” dos Global Secondary Indexes (GSIs)
Até agora, falamos dos GSIs como se fossem a salvação da lavoura: “Quer buscar por e-mail? Cria um GSI! Quer buscar por status? Cria um GSI!”.
Eles são incríveis, sim. Mas eles têm um preço. E se você não configurar direito, esse preço vem em duas faturas: na financeira (AWS Cost Explorer) e na técnica (bugs de sincronia).
Talvez eu soe repetitivo em alguns pontos aqui, mas acredite: é melhor ler isso duas vezes agora do que descobrir na sexta-feira à noite com a produção parada.
1. A Verdade Nua: Um GSI é outra Tabela “Clonada”
Quando você clica no botão “Criar Índice”, a AWS não faz mágica. Ela cria, nos bastidores, uma tabela inteiramente nova e separada, gerenciada automaticamente por ela.
Isso significa que:
Cada vez que você grava (
PutItem) na sua tabela principal, o DynamoDB precisa replicar esse dado para a tabela do GSI.Consequência: Você paga a escrita duas vezes. Uma na tabela principal e outra no índice. Se tiver 5 índices, você paga 6 escritas.
2. Attribute Projection
Aqui está a configuração mais perigosa da AWS. Quando você cria um GSI, ele pergunta: “Quais atributos você quer copiar para este índice?”
Opções:
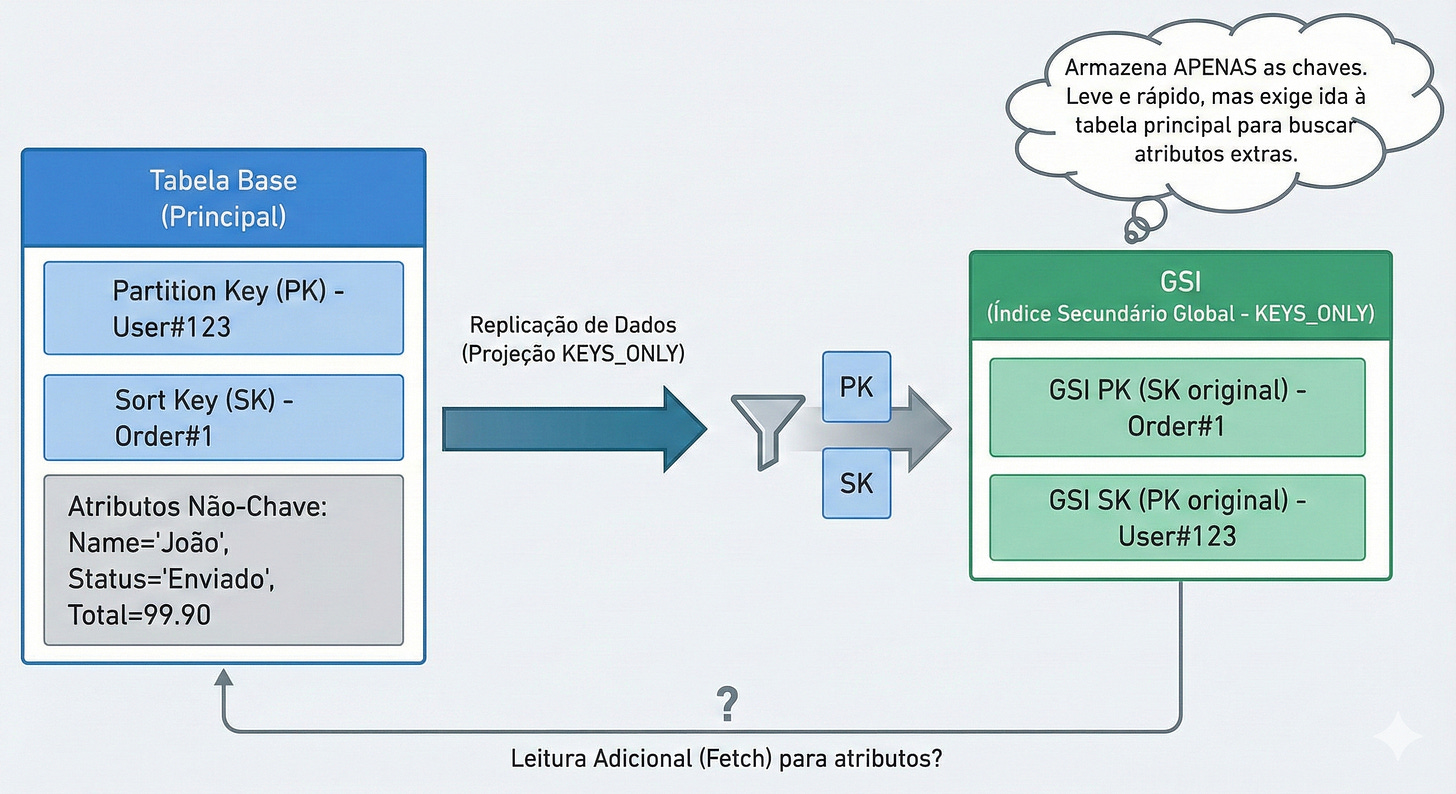
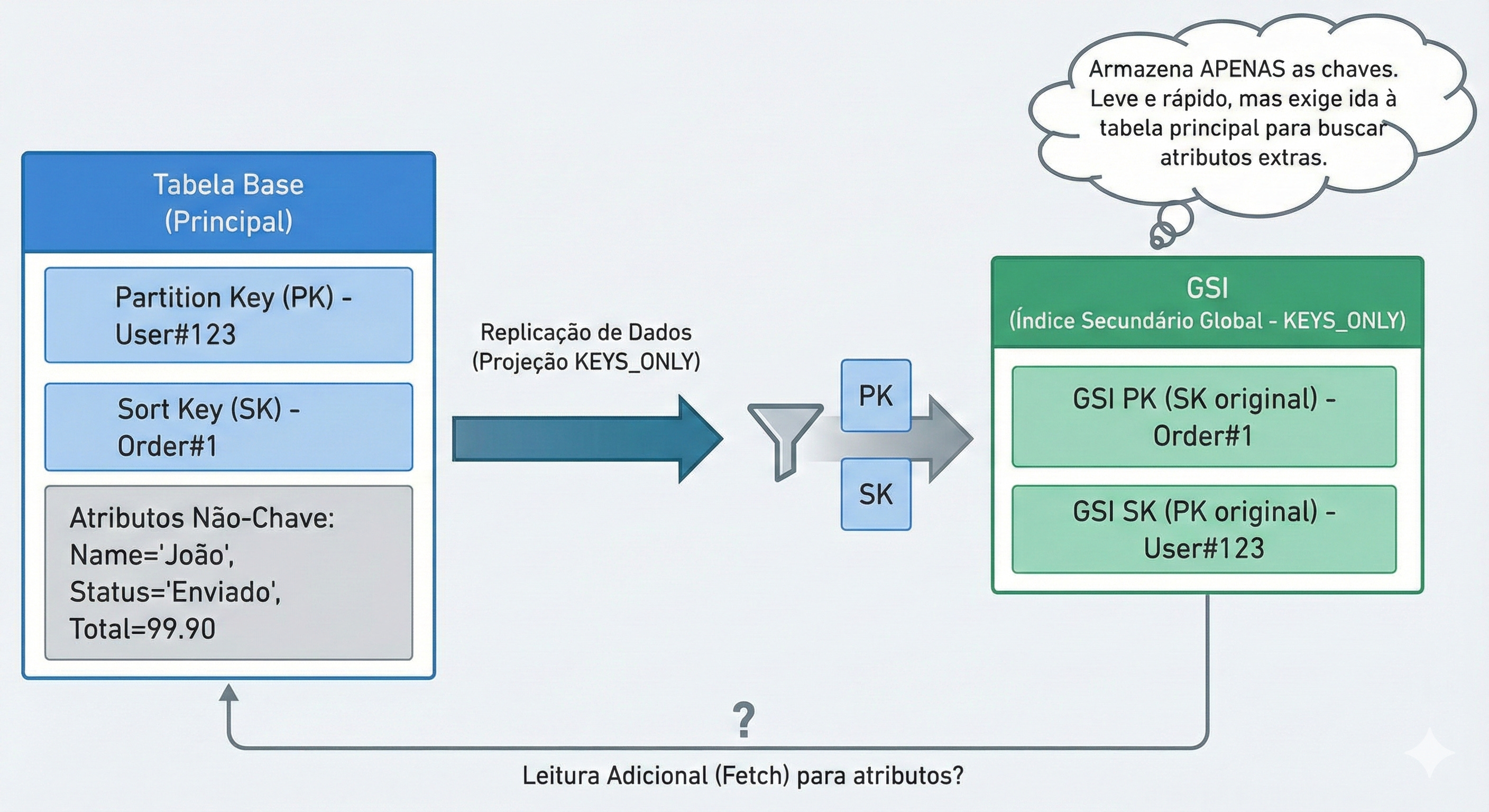
KEYS_ONLY (Apenas Chaves): Copia apenas a PK e a SK.
Custo: Mínimo. O item fica minúsculo.
Uso: Perfeito para verificar existência ou buscar IDs.
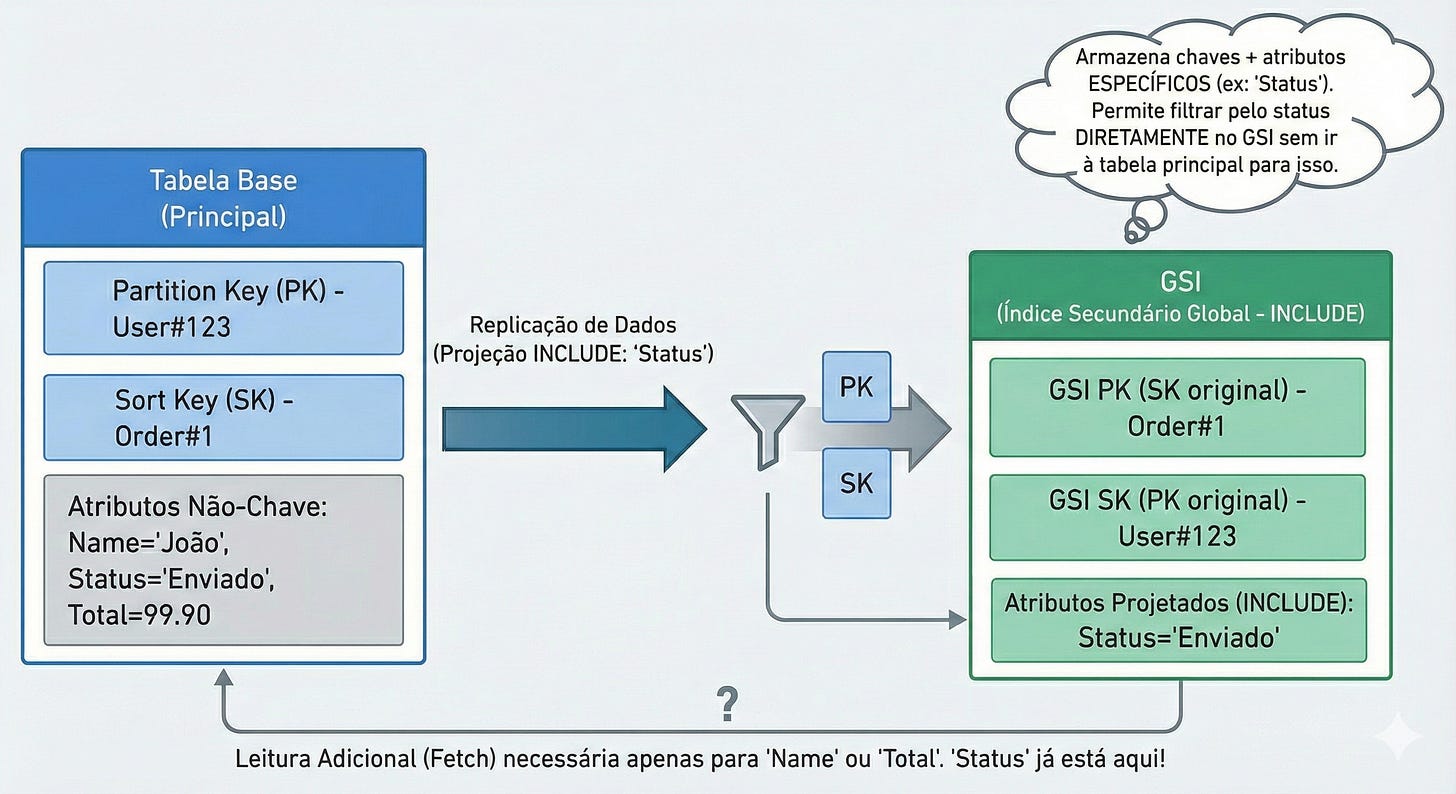
INCLUDE (Incluir Específicos): Copia as chaves + alguns campos que você escolher (ex:
Nome,Data).Custo: Médio.
Uso: O ideal. Você leva apenas o que precisa para exibir na tela de listagem.
ALL (Todos - O Perigo): Copia o item inteiro.
Custo: Dobro.
O Erro Comum: Na pressa, o desenvolvedor marca
ALL“só para garantir” que não vai faltar dado.Resultado: Se seu item tem 4KB, você grava 4KB na tabela principal e 4KB no índice. Você acabou de duplicar sua conta de armazenamento e de WCU sem necessidade.
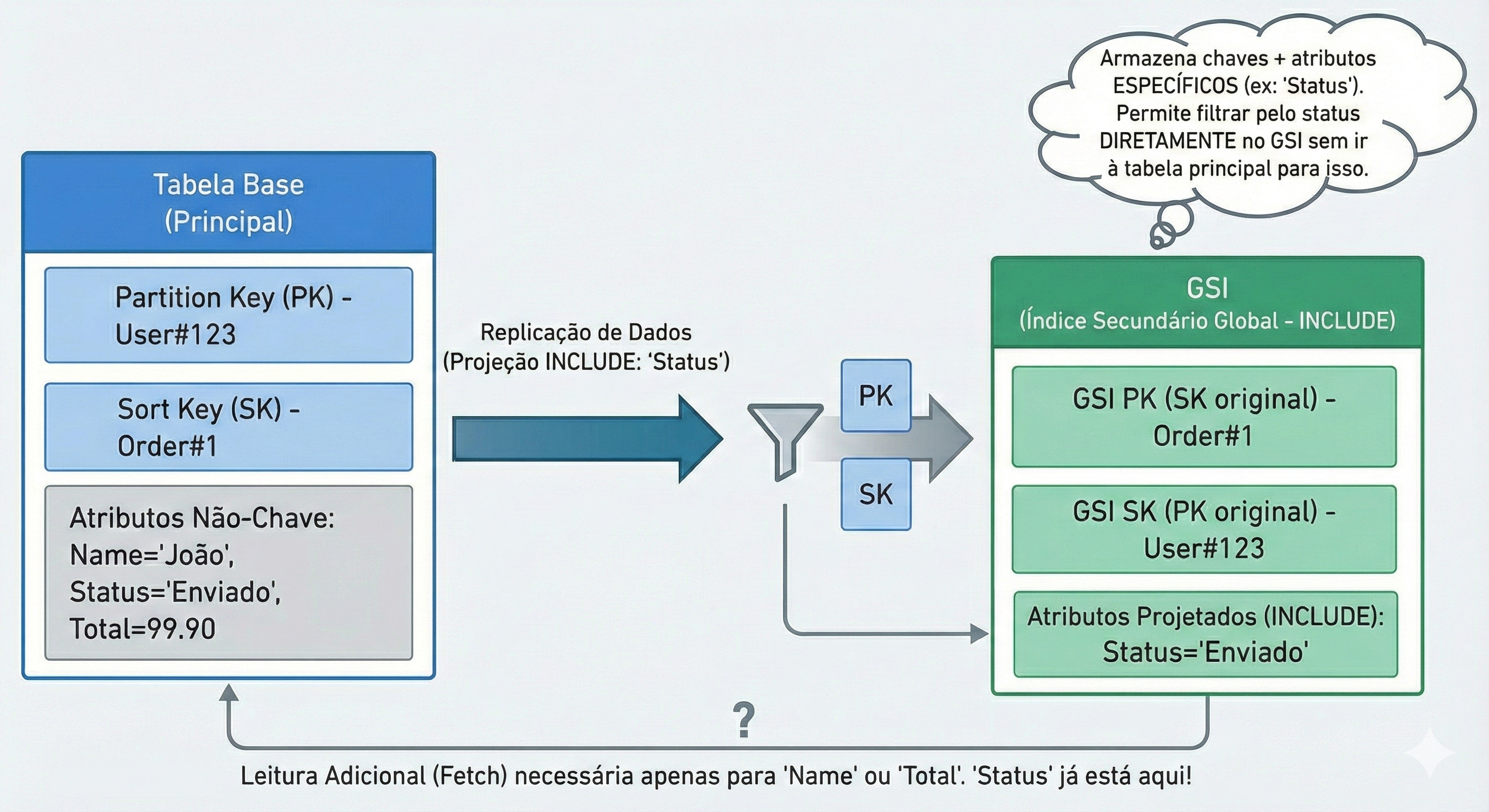
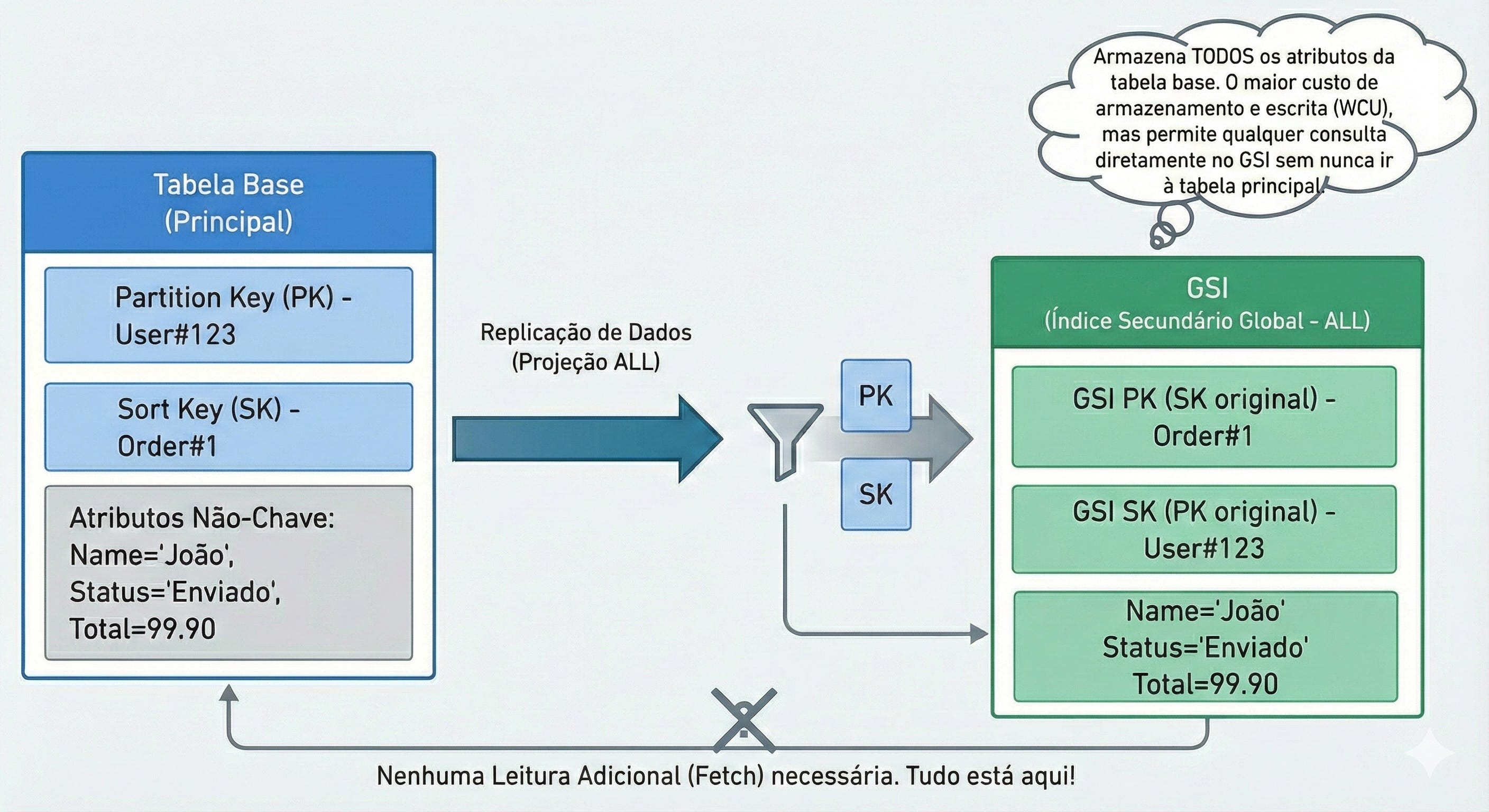
Alerta: Se você escolher
KEYS_ONLYe depois sua aplicação tentar ler um atributo que não está no índice (ex: o endereço do usuário), o DynamoDB vai cobrar extra para buscar esse dado na tabela principal (isso se chama Fetch). Portanto, projete com sabedoria: nem de menos (que exige fetch), nem de mais (que custa caro).5
3. O “Delay” Fantasma: Consistência Eventual
Diferente da tabela principal, onde você pode pedir consistência forte (”quero o dado mais recente agora!”), GSIs são sempre eventualmente consistentes.
A replicação da tabela principal para o GSI é assíncrona. Geralmente leva milissegundos, mas pode levar segundos em momentos de falha ou carga alta.
O Cenário do Bug “Impossível”:
Usuário edita o perfil e muda o nome de “João” para “José”.
Aplicação salva na Tabela Principal (Sucesso).
A aplicação imediatamente redireciona o usuário para a lista de perfis.
A lista de perfis consulta o GSI.
O Bug: O GSI ainda não recebeu a atualização. A tela mostra “João”. O usuário acha que o sistema quebrou e clica em salvar de novo.
Como mitigar? Nunca use GSIs para fluxos que exigem leitura imediata após a escrita (Read-after-Write). Se o usuário acabou de salvar, leia da Tabela Principal usando a PK, nunca do índice.
Chegamos a um momento decisivo. Se você trabalha em uma Fintech, E-commerce ou qualquer sistema onde o dado representa dinheiro ou estoque finito, este capítulo é o mais importante da sua leitura.
Durante muito tempo, o maior argumento dos críticos de NoSQL era: “Bancos não relacionais não têm transações ACID. Você não pode confiar neles para operações financeiras.”
Bom, essa afirmação envelheceu mal. O DynamoDB suporta, sim, transações ACID (Atomicidade, Consistência, Isolamento e Durabilidade) completas entre múltiplos itens e tabelas. Mas, como tudo na AWS, isso não acontece “automaticamente” e tem um preço específico que você precisa calcular.
Transações ACID: O Protocolo do “Tudo ou Nada”
Imagine o cenário clássico de transferência bancária:
Debitar R$ 100,00 da conta da Maria.
Creditar R$ 100,00 na conta do João.
Num banco SQL tradicional, você abriria uma BEGIN TRANSACTION, rodaria os dois updates e daria COMMIT. Se a luz acabasse no meio, o ROLLBACK garantiria que o dinheiro não sumiria.
No DynamoDB, nós usamos a API TransactWriteItems. Ela permite agrupar até 100 operações (Put, Update, Delete ou ConditionCheck) em um único pacote atômico.
A regra é binária: Ou todas as operações do pacote têm sucesso, ou nenhuma acontece. Se a conta da Maria tiver saldo, mas a conta do João tiver sido bloqueada no mesmo milissegundo, a transação falha e o dinheiro da Maria permanece intacto.
O Custo da Segurança: Por que custa o dobro?
Aqui está a matemática que você precisa explicar para o seu gerente financeiro.
Uma operação de escrita normal (PutItem) custa 1 WCU (para itens até 1KB). Uma operação transacional (TransactWriteItems) custa 2 WCUs.
Por que o dobro? Porque o DynamoDB precisa realizar um protocolo de Two-Phase Commit (Commit em Duas Fases) para garantir a integridade.
Fase 1: Preparação (Prepare Phase): O DynamoDB vai até todos os nós onde os itens da transação vivem e pergunta: “Vocês podem realizar essa escrita? As condições (ConditionCheck) são válidas? Alguém está bloqueando esse item?”. O banco reserva o item.
Fase 2: Confirmação (Commit Phase): Se todos os nós responderam “SIM”, o DynamoDB escreve os dados de fato e libera o bloqueio.
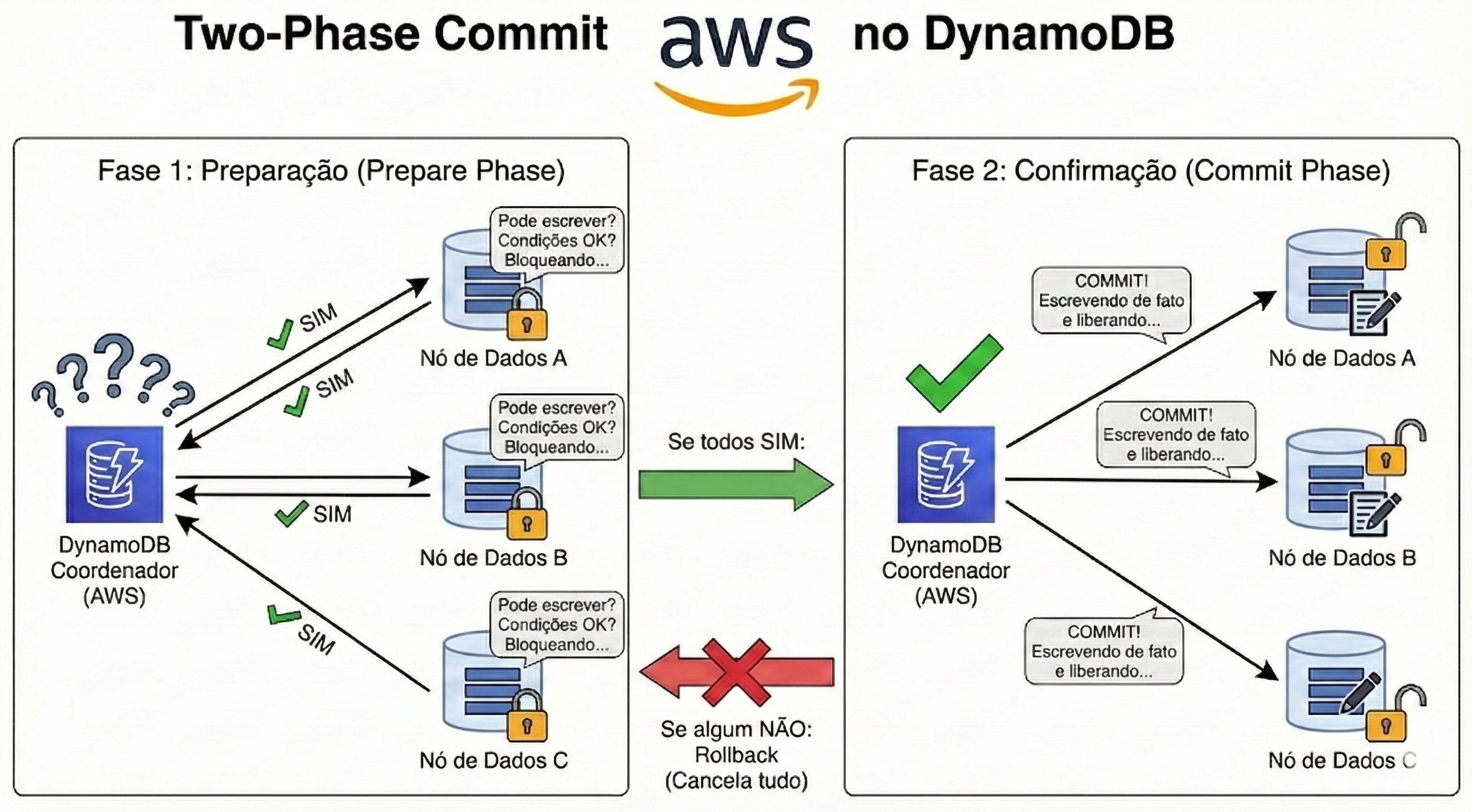
Você paga 1 WCU pela preparação e 1 WCU pela escrita. Total: 2 WCUs. O mesmo vale para leituras transacionais (TransactGetItems): custam o dobro de RCUs para garantir que você está lendo o dado isolado e perfeitamente consistente naquele instante.
ConditionCheck
Muitas vezes, você não quer escrever um dado, você só quer garantir que uma condição é verdadeira antes de mexer em outro dado.
Imagine um sistema de estoque:
Ação: O cliente comprou o último iPhone.
Operação Transacional:
UpdateItem: TabelaPedidos(Criar pedido do Cliente).UpdateItem: TabelaEstoque(Diminuir quantidade em -1).ConditionCheck: TabelaProdutos(Verificar seStatus== ‘ATIVO’).
Se o produto estiver inativo, o ConditionCheck falha. Como ele faz parte do pacote transacional, o pedido não é criado e o estoque não é baixado. O ConditionCheck é o guardião da sua regra de negócio.
O Pesadelo da Rede e a Solução: Idempotência (ClientRequestToken)
Aqui entra um problema que tira o sono de quem desenvolve APIs financeiras. Imagine que seu backend manda a transação para a AWS: “Transfere 50 reais”. A AWS processa, transfere o dinheiro, e manda a resposta: “Sucesso! 200 OK”. Mas... a sua internet piscou. O cabo de rede soltou. O pacote de resposta se perdeu no caminho.
Para o seu backend, deu Timeout. Você não sabe se o dinheiro foi transferido ou não. O que sua aplicação faz? Tenta de novo (Retry). Se você não se proteger, o DynamoDB vai receber o segundo pedido e transferir mais 50 reais. O cliente pagou duas vezes.
Como resolver? Use o ClientRequestToken.
O ClientRequestToken é uma string única (geralmente um UUID) que você gera no seu código antes de chamar o DynamoDB.
Você envia a transação com Token:
abc-123.O DynamoDB processa e salva internamente que o Token
abc-123já foi executado.A resposta falha na rede.
Você envia a transação de novo com o mesmo Token:
abc-123.O DynamoDB olha e diz: “Opa, eu já fiz isso 1 segundo atrás. Não vou debitar de novo. Toma aqui a resposta de Sucesso que você perdeu.”
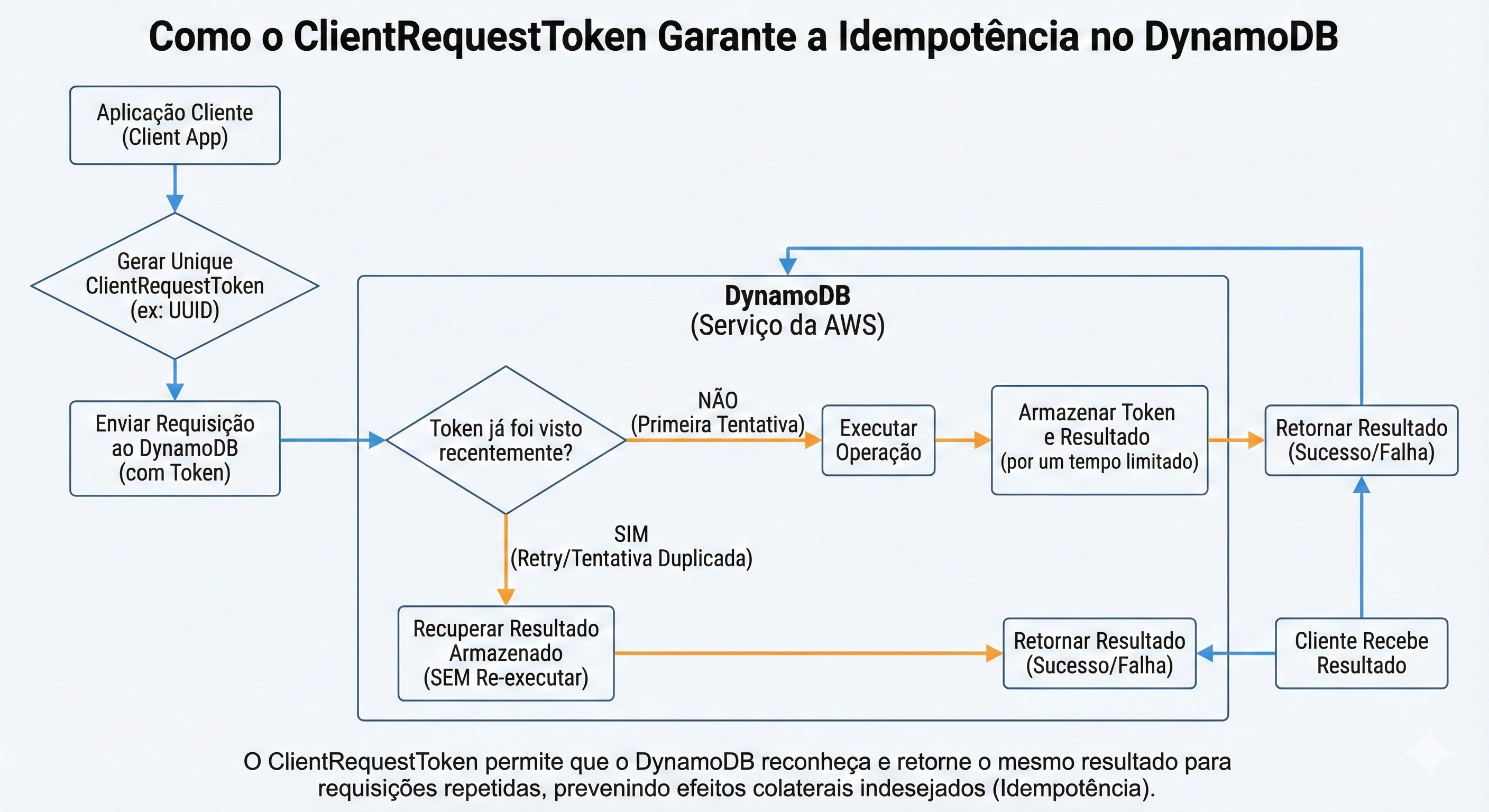
Dica de Implementação: Garanta que esse Token seja gerado o mais “alto” possível na sua arquitetura (de preferência no frontend ou no início da controller da API) e passado adiante até o banco. Isso garante idempotência ponta a ponta.
Cuidados na API e Tratamento de Erros
Quando uma transação falha, o DynamoDB lança uma exceção específica: TransactionCanceledException.
Dentro dessa exceção, existe um campo chamado CancellationReasons (Razões do Cancelamento). Isso é uma lista que corresponde à ordem dos itens que você tentou gravar.
Se você enviou 3 itens na transação e a lista de razões voltar assim: [None, “ConditionalCheckFailed”, None]
Isso significa que:
O Item 1 estava OK.
O Item 2 falhou na checagem de condição.
O Item 3 estava OK.
Mas, lembre-se: como é uma transação, nada foi salvo. Seu código precisa ser inteligente o suficiente para ler esse erro, entender qual condição falhou (ex: “Sem saldo” ou “Sem estoque”) e devolver uma mensagem amigável para o usuário, em vez de um simples “Erro 500”.
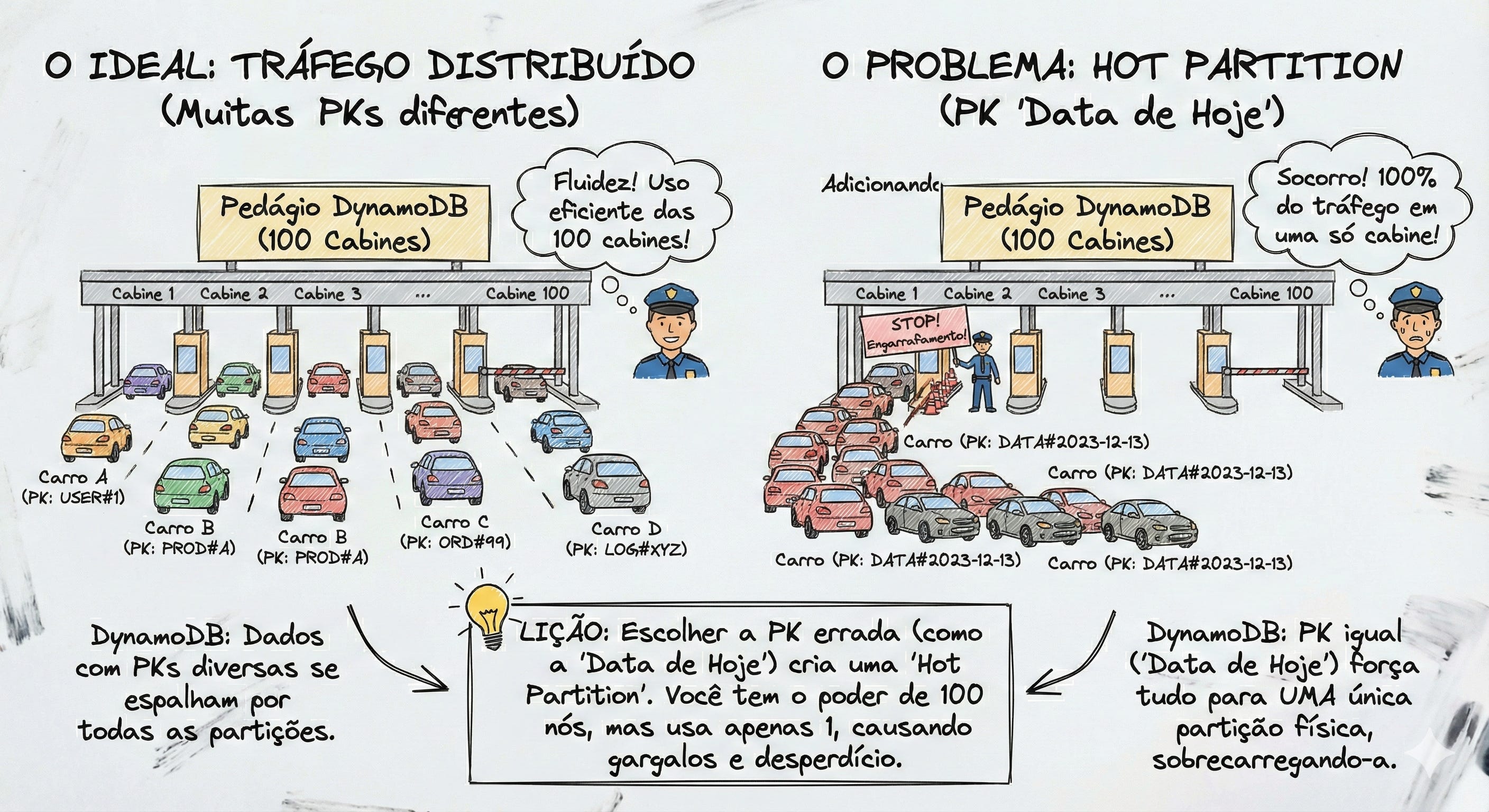
Evitando “Hot Partitions”: Quando todo mundo tenta passar na mesma porta
Lembra daquela nossa analogia do Pedágio com 100 cabines? Vamos resgatá-la porque ela explica perfeitamente o fenômeno da “Partição Quente” (Hot Partition).
Você contratou o DynamoDB e ele te deu 100 cabines (partições) para distribuir seus carros (dados). O ideal é que os carros se espalhem e usem as 100 cabines ao mesmo tempo.
Mas, se você escolher a Partition Key errada, você pode acabar forçando todos os carros a tentarem passar apenas pela Cabine Número 1, enquanto as outras 99 ficam vazias.
O resultado? Engarrafamento monstro na Cabine 1. O guarda de trânsito (DynamoDB) começa a barrar os carros. Isso é o que chamamos de Hot Partition.
O Erro Clássico: Datas ou Sequenciais na PK
Aqui entra a confusão comum:
“No início, dissemos que Data na Sort Key (SK) é ótimo. Agora estou dizendo que Data na Partition Key (PK) pode ser um desastre.”
A Diferença Vital:
Data na SK (Sort Key): Ótimo! Porque você já escolheu a cabine (pelo CPF do cliente, por exemplo) e agora está apenas organizando a fila dentro daquela cabine.
Data na PK (Partition Key): Perigoso! Porque a PK define qual cabine usar.
O Exemplo no Sistema Financeiro: Imagine que você tem uma tabela de “Logs de Transações do Dia” para auditoria. Muitos desenvolvedores pensam: “Vou agrupar tudo pela data de hoje.”
PK Escolhida:
DATA#2023-12-13(A data de hoje).O Cenário: Você tem 50 microsserviços bombardeando essa tabela com logs de Pix, TED, Boletos e Pagamentos.
O Problema: Como hoje é dia 13, 100% das escritas terão a mesma PK (
DATA#2023-12-13).Isso significa que 100% do tráfego vai para uma única partição física.
Você tem o poder de processamento de todo o cluster da AWS à sua disposição, mas está usando a capacidade de apenas um nó.
O mesmo vale para IDs Sequenciais Simples. Se sua PK for ORDEM#1000, ORDEM#1001, ORDEM#1002... e essas ordens são criadas muito rápido, o DynamoDB pode alocar esses números sequenciais vizinhos na mesma partição física, criando um ponto de calor.
O Fantasma do “Throttling”
Quando você cria esse “ponto de calor”, o DynamoDB levanta uma placa de “Pare”. Isso é o Throttling.
Tecnicamente, você recebe um erro ProvisionedThroughputExceededException.
Traduzindo: “Você excedeu a velocidade permitida nesta cabine específica”.
Consequência: Sua API começa a tomar erro 400/500, transações financeiras falham e o sistema fica instável, mesmo que você esteja pagando por uma capacidade total gigantesca (que está ociosa nas outras partições).
A Solução: Write Sharding (Dividir para Conquistar)
Se você realmente precisa agrupar dados por dia (ou qualquer chave com alta concentração de escrita), você precisa usar a técnica de Write Sharding.
A ideia é adicionar um “sufixo aleatório” ao final da sua PK para espalhar os dados.
Como funciona: Em vez de gravar tudo em DATA#2023-12-13, sua aplicação sorteia um número de 1 a 10 (ou 1 a N) e adiciona na chave.
DATA#2023-12-13_1(Vai para a partição A)DATA#2023-12-13_2(Vai para a partição B)...
DATA#2023-12-13_10(Vai para a partição J)
O Resultado: Agora você tem 10 cabines do pedágio trabalhando simultaneamente para processar o dia 13. Você multiplicou sua capacidade de escrita por 10.
Trade-off: Na hora de ler, você não pode buscar apenas por DATA#2023-12-13. Você terá que fazer 10 queries em paralelo (uma para cada sufixo _1 a _10) e juntar os resultados na sua aplicação. Dá mais trabalho para ler? Sim. Mas é o único jeito de escalar escritas massivas sem gerar Hot Partitions.
Resumo:
Use datas para ordenar (Sort Key), não para agrupar (Partition Key) volumes massivos. Se precisar agrupar por data, quebre o dia em pedacinhos (Sharding) para não engarrafar o pedágio.
Conclusão
Ufa! Quanta coisa, né?
Se você chegou até aqui, respire fundo. Nós acabamos de percorrer o caminho que separa quem apenas “usa” o DynamoDB de quem realmente domina a ferramenta.
Eu sei que, em alguns momentos, a vontade é voltar correndo para o conforto do SQL, onde um JOIN resolve tudo e o SELECT * não custa os olhos da cara. Mas a verdade é que o desconforto que você sentiu lendo sobre Single Table Design, Inversão de Índices e Cálculo de WCU é apenas o som da sua “mentalidade relacional” quebrando para dar lugar a algo novo.
O que vimos aqui não foi apenas um manual de “como apertar botões na AWS”. Foi um guia de sobrevivência baseado em cicatrizes reais de produção:
Aprendemos que Access Patterns não são opcionais: eles são o projeto da sua casa. Sem eles, você constrói uma mansão sem portas.
Vimos que Single Table Design pode parecer caótico, mas é a orquestração perfeita para performance quando bem executado (lembra do nosso case financeiro com Contratos e Simulações?).
Entendemos que o Bolso (custos de WCU/RCU) é o melhor arquiteto: técnicas como Sparse Indexes e o padrão Claim Check com S3 salvam orçamentos.
E, principalmente, descobrimos que o DynamoDB é implacável com erros de modelagem, mas incrivelmente generoso em escala e velocidade quando você joga pelas regras dele.
O meu conselho final para você é: Não tente aplicar as 10 técnicas amanhã cedo no sistema crítico da empresa. Comece pequeno. Pegue aquele microsserviço novo, aquela tabela de logs, aquele sistema de notificações. Abra o Excel, desenhe seus Access Patterns, discuta com seu time se o CPF deve ir na PK ou se é melhor usar um UUID.
O DynamoDB é como uma Ferrari: se você tentar dirigir como se fosse um carro popular você vai bater no primeiro poste. Mas, se você aprender a pilotar... não existe limite de velocidade para o que você pode construir.
Espero que este artigo tenha facilitado o seu caminho e evitado algumas das pedras nas quais eu tropecei. 😅
Não se assuste com a palavra. Cardinalidade é apenas uma medida de “variedade”.
Imagine que você está chegando em um pedágio gigante com 100 cabines (partições do banco de dados).
Baixa Cardinalidade (O Pesadelo): É como se você tivesse uma chave chamada
Statuscom apenas 2 valores: “Aprovado” ou “Pendente”.Resultado: Mesmo tendo 100 cabines disponíveis, todos os seus carros (dados) vão tentar passar apenas pelas cabines 1 e 2. O resto fica vazio. Gera engarrafamento, lentidão e o banco rejeita seus dados.
Alta Cardinalidade (O Sonho): É quando você usa chaves com milhões de valores únicos, como
UserID,CPFouUUID.Resultado: Os carros se espalham perfeitamente. Tem carro passando na cabine 1, na 50, na 99... O trânsito flui, ninguém pega fila e seu banco voa baixo.
Resumo: No DynamoDB, queremos que os dados sejam “anti-sociais”. Quanto mais espalhados eles estiverem, melhor. Por isso, amamos alta cardinalidade.
Em tradução livre, são os Padrões de Acesso.
Basicamente, um Access Pattern é uma lista detalhada de todas as perguntas que sua aplicação fará ao banco de dados.
No modelo relacional (SQL), você pode se dar ao luxo de criar as tabelas primeiro e depois “descobrir” como vai consultá-las usando JOINs e WHEREs complexos. O banco se vira para te responder.
No DynamoDB, essa flexibilidade não existe (ou custa muito caro via Scan). Você precisa saber a pergunta antes de construir a tabela.
Como mapear um Access Pattern na prática? Antes de escrever uma linha de código, você deve abrir uma planilha (o Excel é o melhor amigo do arquiteto NoSQL) e listar cada funcionalidade do sistema:
Access Pattern 1: “Buscar usuário pelo Email.”
Access Pattern 2: “Listar todos os pedidos de um usuário ordenados por data.”
Access Pattern 3: “Buscar detalhes de um produto pelo SKU.”
Por que isso define a estrutura? Cada pergunta dita a regra da sua Chave Primária:
Para atender o Padrão 1, sua PK precisa ser o Email.
Para atender o Padrão 2, sua PK precisa ser o UserID e sua SK precisa ser a Data do Pedido.
A Regra:
“Se não estiver no seu documento de Access Patterns, sua aplicação não vai conseguir buscar com performance. No DynamoDB, você modela as queries, não os dados.”
O que são 400KB na ponta do lápis?
Tecnicamente, 1 KB = 1024 bytes.
Portanto, o limite do DynamoDB é 409.600 bytes.
Em uma codificação de texto padrão da web (UTF-8), onde cada caractere comum (letras e números) ocupa 1 byte, isso equivale a 400.000 caracteres.
Se considerarmos que uma página média de um livro impresso tem cerca de 2.500 caracteres (com espaços), um único item do DynamoDB pode armazenar:
160 páginas de texto puro.
Ou seja, guardar um item de 400KB é o equivalente a tentar enfiar metade do livro "Harry Potter e a Pedra Filosofal". É muita coisa para processar em tempo real.
Muitos leitores podem estar questionando: “Então o FilterExpression é inútil?” Não! Ele é útil para limpar o payload de retorno (economizar banda de rede), mas ele é financeiramente inútil para economizar leitura no banco.
A Regra de Ouro:
“O DynamoDB cobra pelo que ele lê do disco, não pelo que ele entrega para você.”
Se o seu filtro descarta dados, você está pagando para ler lixo. Aqui estão as 3 alternativas arquiteturais para substituir um FilterExpression pesado:
1. Mova o dado para a Sort Key (SK)
Se você vive filtrando por Data ou Status, esses dados devem fazer parte da sua Chave de Ordenação.
Antes (Errado):
Queryna PK “USUARIO#123” eFilterExpression“Data > 2023-01-01”. (O banco lê todo o histórico do usuário e filtra depois).Depois (Correto): Coloque a data na SK (
PEDIDO#2023-01-01). Use a condiçãoKeyConditionExpressioncom o operadorbegins_withoubetween. (O banco vai direto no bloco de dados de 2023 e ignora o resto. Você paga apenas pelo que pediu).
2. Use Índices Esparsos (Sparse Indexes)
Imagine que você quer buscar apenas os pedidos com Status = “CANCELADO”, mas eles representam só 1% da sua tabela.
A Técnica: Crie um GSI (Global Secondary Index) onde a PK é o
PedidoIDe a SK éStatusCancelado.O Truque: No DynamoDB, se um item não tem o atributo usado na chave do índice, ele não é copiado para o índice.
O Resultado: Seu índice terá apenas os 1% de pedidos cancelados. Fazer um
Scannesse índice minúsculo é extremamente rápido e barato. Você transformou um “filtro” em uma “tabela VIP” só com os dados que te interessam.
3. Filtre no lado da Aplicação (Se o volume for pequeno)
Se você já fez uma Query eficiente pela PK+SK e retornou 50 itens, e agora quer filtrar apenas os que são “cor azul”, faça isso no código da sua aplicação (Node.js, Python, C#).
Por que? A CPU do seu servidor de aplicação (Lambda/EC2) geralmente é mais barata e escalável que a RCU do DynamoDB. Não gaste a inteligência do banco para fazer filtros triviais em conjuntos de dados pequenos.
Resumo: Use KeyConditionExpression (Chaves) para cortar o grosso dos dados. Use FilterExpression (Atributos) apenas para aparar as arestas finais.
Antes de demonizar completamente a projeção ALL, precisamos entender o custo de não ter o dado no índice.
Imagine que você projetou apenas as chaves (KEYS_ONLY) para economizar na escrita. Sua query no GSI retorna a lista de pedidos, mas agora seu frontend precisa mostrar o Valor Total do pedido, e esse dado não está no índice.
O que acontece?
O DynamoDB lê o índice (Gasto de RCU).
O DynamoDB percebe que falta o “Valor Total”.
Ele é obrigado a ir na Tabela Principal buscar o resto do item. Isso se chama Fetch.
O Custo: Você paga 2 Leituras (uma no índice, uma na tabela) e a latência dobra.
Quando usar ALL (e pagar o preço sorrindo): Se o seu Access Pattern é intensivo em leitura (Read-Heavy) e o dado raramente muda (pouca escrita), projetar ALL é vantajoso. Você paga mais caro uma única vez na escrita, mas economiza metade do custo e do tempo em todas as milhões de leituras subsequentes, pois o índice já entrega o “pacote completo” sem precisar bater na tabela principal.
Resumo do Cálculo:
Muita Escrita / Pouca Leitura: Fuja do
ALL. UseKEYS_ONLYouINCLUDE.Muita Leitura / Pouca Escrita: O
ALLpode ser seu melhor amigo para performance.