
Armadilhas Arquitetônicas: Quando Microserviços Se Revelam Monólitos Distribuídos 😮
Se você decompor um sistema incorretamente, você construirá um monólito distribuído... - Chris Richardson, Padrões de microsserviços: com exemplos em Java

O conceito de microsserviços sempre está em alta. Muitas organizações implementam esperando ter mais facilidade e agilidade no dia a dia. Mas essas corporações e profissionais que apostam nessa arquitetura devem estar cientes da complexidade e dificuldades que podem encontrar. Não estou falando de um ou dois desafios, estou afirmando que a alta complexidade é um fato! Lidar com serviços que cuidam de responsabilidades diferentes tem seu preço a se pagar, especialmente quando a linha entre a eficiência da modularização e o emaranhado da interdependência começa a se borrar. Nesse contexto, surge uma questão crucial que muitos desenvolvedores e arquitetos de software enfrentam: seu microsserviço é, na verdade, um monólito distribuído?
Este dilema não é apenas semântico, mas reflete uma realidade operacional onde a promessa de agilidade e escalabilidade dos microsserviços pode ser ofuscada por uma complexidade inadvertida e problemas de gerenciamento que são característicos dos sistemas monolíticos. À medida que mergulhamos neste debate, é essencial desvendar os sinais reveladores de um monólito distribuído e explorar estratégias para manter a verdadeira essência dos microsserviços, garantindo que a arquitetura adotada promova a independência, a eficiência e a capacidade de resposta que as organizações modernas exigem.
Se gostar do conteúdo, por favor, compartilhe e deixe seu like no post! Isso me ajuda e incentiva a continuar a trazer conteúdos em forma de texto também!😄
O que é um microserviço?
Chris Richardson, autor do livro "Microservices Patterns", comenta que microserviços são uma abordagem arquitetônica que estrutura uma aplicação como uma coleção de serviços. Esses serviços são caracterizados por serem:
Organizados em torno de capacidades de negócios: Cada serviço é construído em torno de uma função de negócio específica e é projetado para ser uma parte autônoma e independente do sistema total. Isso permite que equipes diferentes se concentrem em diferentes serviços, cada uma com seu próprio ciclo de vida de desenvolvimento e implantação.
Propriedade de pequenas equipes: Geralmente, cada microserviço é mantido por uma equipe pequena que é responsável por todo o ciclo de vida do serviço, desde o desenvolvimento até a operação. Isso promove a propriedade e a responsabilidade direta, permitindo que as equipes se movam rapidamente e façam mudanças de forma independente.
A arquitetura de microserviços permite que organizações entreguem aplicações grandes e complexas de forma rápida, frequente, confiável e sustentável, o que é crucial para competir e ter sucesso no mercado atual. Essa abordagem promove a entrega de software rápida e confiável, alinhada com os princípios do DevOps, organização em equipes pequenas e desacopladas, e uma arquitetura que é desacoplada, testável e implantável. No entanto, a transição para um contexto de serviços isolados não é isenta de desafios, ao contrário, desafios são comuns e muitas vezes podemos estar indo na direção contrária! Como assim?
No livro "Microservices Patterns", o conceito de "monólitos distribuídos" é discutido no contexto dos desafios e armadilhas que as organizações podem enfrentar ao adotar uma arquitetura de microserviços. Richardson alerta que, sem uma cuidadosa consideração do design e das práticas de implementação, as organizações podem acabar construindo o que ele chama de "monólitos distribuídos" em vez de uma verdadeira arquitetura de microserviços. Vamos conversar muito sobre esse tema no tópico abaixo.
O que é um monólito distribuído?
Quem acompanha meus artigos sabe que gosto de analogias. Então vou utilizar mais uma para tentar melhorar o entendimento do que seria um monólito distribuído.
Imagine por um momento que você está tentando montar um grande quebra-cabeça. Cada peça representa um serviço diferente em sua aplicação. Na arquitetura ideal de microsserviços, cada peça se encaixa perfeitamente em seu lugar, contribuindo para o quadro geral sem depender excessivamente das peças ao redor. Você pode trabalhar em diferentes seções do quebra-cabeça simultaneamente, com diferentes grupos de amigos, sem atrapalhar uns aos outros. Isso é o que torna a abordagem de microsserviços tão atraente: a capacidade de escalar, modificar e manter partes da aplicação de forma independente.
Agora, vamos à analogia do monolito distribuído. Imagine que, em vez de peças de quebra-cabeça independentes, você tem peças que estão presas umas às outras em grupos. À primeira vista, parece que você tem várias seções menores para trabalhar – um pouco como microsserviços. Mas quando você tenta mover ou alterar uma seção, descobre que está inextricavelmente ligada a outras seções. Você e seus amigos se encontram constantemente esbarrando uns nos outros, tentando descobrir como alterar uma parte sem desmontar metade do quebra-cabeça.
Esse é o cerne de um monolito distribuído: apesar da aparência de modularidade, há uma interdependência tão forte entre os serviços que a autonomia pretendida é mais ilusória do que real. Assim como no quebra-cabeça, onde peças interligadas limitam a liberdade de trabalhar em seções independentes, um monolito distribuído restringe a agilidade e a eficiência da equipe de desenvolvimento.
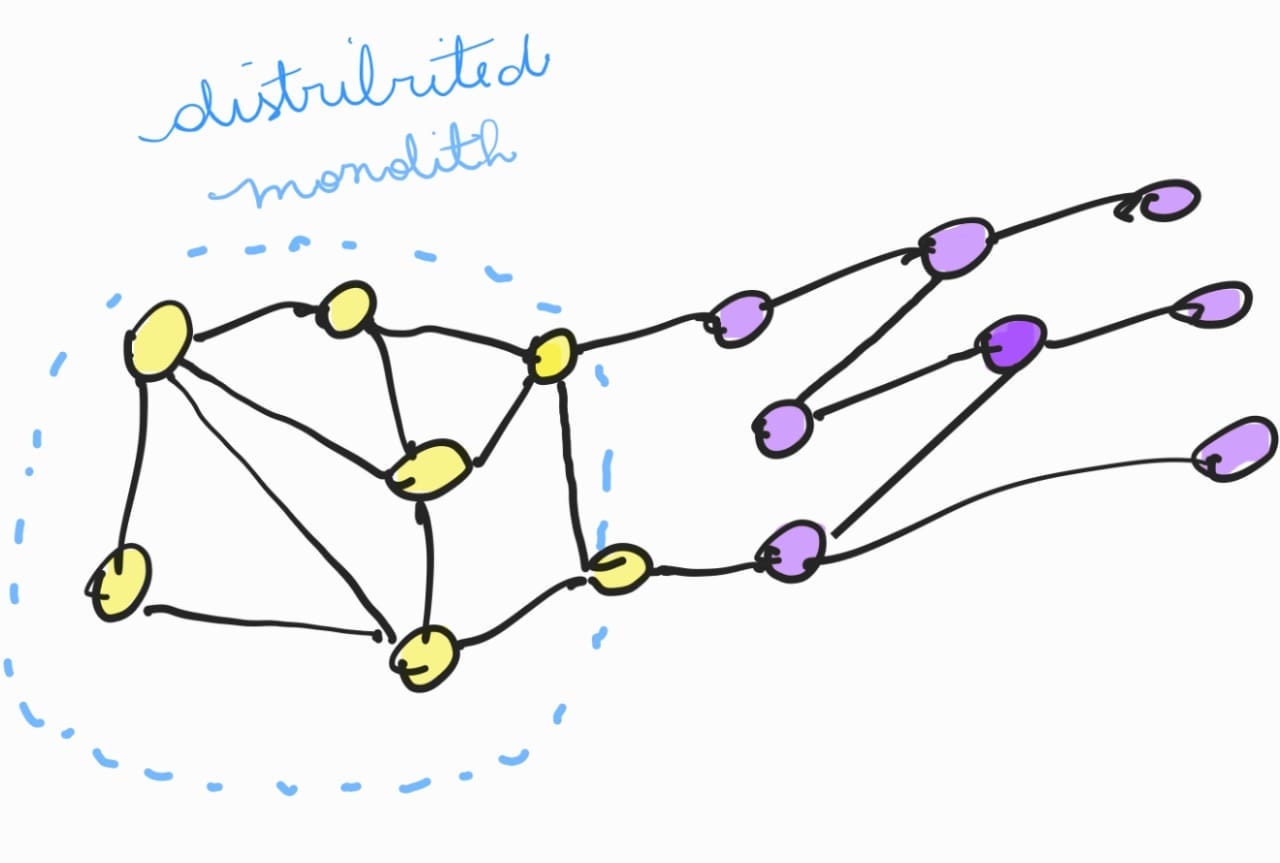
Os principais pontos a serem observados aqui são a importância da independência e do desacoplamento em microsserviços. Não basta simplesmente dividir uma aplicação em vários serviços e comunicá-los via API REST; é crucial que esses serviços sejam verdadeiramente autônomos, sem dependências ocultas que os amarrem uns aos outros. A comunicação síncrona, quando excessiva, pode ser uma armadilha, criando pontos de falha e gargalos que afetam toda a aplicação.
Mas todo o problema tem suas origens, por isso vamos entender melhor o que pode levar ao inferno distribuido monolitico.
O que leva ao caminho sombrio do monólito distribuído?
A quebra de um monolito em microserviços é uma tarefa complexa e desafiadora, repleta de armadilhas potenciais. Um dos erros mais significativos que os arquitetos e programadores de software podem cometer nesse processo é não reconhecer a diferença entre simplesmente dividir um sistema em partes menores e reestruturar verdadeiramente a arquitetura para aproveitar os benefícios dos microserviços.
Esse equívoco pode inadvertidamente levar à criação de um ecossistema de monólitos distribuídos, ao invés de uma arquitetura de microserviços coesa e eficiente. Vamos explorar os principais pontos que contribuem para esse desvio:
Falta de compreensão dos domínios de negócios: Um dos aspectos fundamentais da arquitetura de microserviços é o alinhamento com os domínios de negócios através de contextos limitados. Sem uma compreensão clara desses domínios, os arquitetos podem acabar segmentando o monolito de maneira que reflita apenas a estrutura técnica existente, em vez de reorganizar a aplicação em torno de suas funções de negócios. Isso resulta em serviços que ainda estão fortemente acoplados em termos de lógica de negócios, levando à criação de "mini-monolitos" que precisam ser constantemente sincronizados.
Compartilhamento excessivo de dados: Um erro comum durante a decomposição de um monolito é permitir que os microserviços compartilhem bancos de dados ou esquemas de dados. Isso cria uma forte dependência entre os serviços e impede que eles evoluam de forma independente, uma vez que qualquer mudança no esquema de dados pode afetar múltiplos serviços. Idealmente, cada microserviço deve possuir e gerenciar seu próprio banco de dados ou conjunto de dados.
Comunicação síncrona excessiva: Ao transformar um monolito em microserviços, pode ser tentador manter os padrões de comunicação síncrona que estavam presentes no sistema monolítico original. No entanto, isso pode levar a um alto acoplamento temporal entre os serviços e aumentar a latência do sistema como um todo. Uma arquitetura de microserviços bem projetada prefere comunicações assíncronas e event-driven, promovendo a desacoplação e a independência.
Filas Compartilhadas: A utilização indevida de filas compartilhadas entre microserviços é outro indicativo de que a arquitetura pode estar se desviando dos princípios fundamentais de microserviços e caminhando para um monólito distribuído. Em um cenário ideal, as filas devem atuar como mecanismos de desacoplamento, permitindo que os serviços se comuniquem de forma assíncrona e independente. No entanto, quando várias partes do sistema interagem com a mesma fila - seja para ler, escrever ou ambos - surge um acoplamento implícito entre esses serviços.
Subestimação da complexidade operacional: Por fim, um erro crítico é subestimar a complexidade operacional introduzida pelos microserviços. Cada serviço adiciona à superfície de ataque do sistema, requerendo gerenciamento de segurança, monitoramento, logística e resiliência. Sem as ferramentas e práticas adequadas para gerenciar essa complexidade, os desenvolvedores e operadores podem se encontrar sobrecarregados, levando a uma situação onde os microserviços são agrupados ou integrados de maneira inadequada para simplificar o gerenciamento, culminando na criação de monólitos distribuídos.
Evitar essas armadilhas requer uma abordagem cuidadosa, que considere tanto os aspectos técnicos quanto os organizacionais da arquitetura de microserviços. A chave é manter o foco na independência dos serviços, na compreensão dos domínios de negócios e na adoção de práticas que suportem uma arquitetura distribuída.
Vamos iniciar conversando sobre como essa distribuição falha na centralização de negócios!
Falha na Centralização de Responsabilidades de Negócios
Um ponto crítico na discussão sobre monólitos distribuídos é a falha em centralizar adequadamente a lógica de negócios. Vamos desdobrar esses aspectos para entender melhor como eles contribuem para a criação de um monólito distribuído, em vez de uma arquitetura de microserviços bem definida.
Atualizar uma regra de validação simples em um ambiente onde as decisões de negócios está descentralizada pode se tornar uma operação complexa e propensa a inconsistência de dados ou erros inesperados. A descentralização ocorre quando os princípios e regras de negócio não são mantidos dentro de um contexto limitado, levando à sua replicação em vários serviços. Esse fenômeno é comumente observado em arquiteturas que, apesar de serem projetadas para serem microserviços, acabam funcionando mais como monólitos distribuídos devido ao alto acoplamento e à dependência entre os serviços.
Problemas Decorrentes da Descentralização da Lógica de Negócios
Duplicação de Lógica: Sem uma centralização adequada, cada microserviço pode acabar implementando sua própria versão da lógica de validação. Por exemplo, se dois serviços diferentes precisam validar informações do usuário, como endereço de e-mail ou senha, ambos podem acabar tendo seu próprio código para essa validação. Isso não apenas duplica o esforço de desenvolvimento, mas também aumenta a probabilidade de inconsistências na validação, onde um serviço pode aceitar um valor que outro rejeita.
Inconsistências de Dados: Quando as regras de negócios não são aplicadas de forma consistente em todos os serviços, pode-se gerar inconsistências de dados. Por exemplo, se um serviço atualiza os dados do usuário sem aplicar todas as validações necessárias, esses dados podem estar em desacordo com as expectativas de outros serviços que dependem dessa informação, levando a erros e comportamentos inesperados no sistema.
Manutenção e Atualização Difíceis: Com a lógica de negócios espalhada por vários serviços, fazer mudanças se torna uma tarefa árdua. Atualizar uma regra de validação simples pode requerer alterações em múltiplos pontos do sistema, aumentando o risco de bugs e tornando o processo de atualização lento e propenso a erros.
Atualizar uma regra de validação simples em um cenário descentralizado de lógica de negócios pode se tornar uma tarefa hercúlea, especialmente quando essa lógica se espalha por múltiplos serviços de maneira descoordenada. Este problema é exacerbado em sistemas complexos, como os de microserviços, onde a modularidade e a independência são fundamentais. Um exemplo ilustrativo desse desafio pode ser observado em um sistema que envolve a validação e criação de vouchers.
Imagine um serviço de e-commerce que, além de gerenciar produtos, carrinhos de compra e pagamentos, também oferece um sistema de vouchers para descontos. O serviço de Voucher, idealmente, deveria ser o único responsável por validar e criar novos vouchers, garantindo que as regras de negócio específicas para os vouchers sejam centralizadas e consistentes. Essas regras podem incluir a validação da data de expiração do voucher, o cálculo do desconto com base no valor total da compra, a limitação do uso do voucher a certas categorias de produtos ou a verificação da elegibilidade do usuário para o desconto.
No entanto, na prática, a lógica e as regras de negócio associadas aos vouchers podem começar a se infiltrar em outros serviços de forma inadequada. Por exemplo, o serviço responsável pelo carrinho de compras pode começar a incorporar sua própria lógica para aplicar descontos de vouchers, talvez porque seja necessário apresentar ao usuário o valor total com desconto antes de finalizar a compra. Da mesma forma, o serviço de gerenciamento de usuários pode começar a implementar regras para determinar se um usuário é elegível para receber um voucher com base em seu histórico de compras.
Essa bagunça relacionada aos vouchers leva a vários problemas. Ocorre uma duplicação de esforços, pois a mesma lógica é implementada em múltiplos serviços, aumentando a carga de desenvolvimento e manutenção. Além disso, qualquer mudança nas regras de negócio dos vouchers — como alterações nas condições de elegibilidade, cálculos de desconto ou tipos de vouchers — exige atualizações em todos os serviços que incorporaram partes dessa lógica, o que é propenso a erros e inconsistências. Se um serviço falhar ao incorporar as atualizações corretamente, o sistema como um todo pode começar a se comportar de forma imprevisível, oferecendo descontos incorretos ou permitindo o uso de vouchers expirados, por exemplo.
Esse cenário contribui para a criação de um "monólito distribuído", onde, apesar da aparência de modularidade proporcionada pelos microserviços, a lógica de negócios permanece interdependente e fortemente acoplada entre os serviços. Isso vai contra os princípios fundamentais de uma arquitetura de microserviços bem definida, que visa a separação clara de responsabilidades e a independência entre os serviços.

O desenvolvimento de novas funcionalidades nesse contexto torna-se mais lento e arriscado, uma vez que a interdependência entre os serviços aumenta a complexidade do sistema. A implementação de uma nova regra de negócio pode requerer uma análise cuidadosa de todos os serviços afetados e uma coordenação precisa durante a atualização, para evitar quebras no sistema.
Como podemos evitar esse tipo de armadilha? O Domain-Driven Design (DDD) oferece uma abordagem para mitigar esses problemas, enfatizando a importância de modelar os serviços em torno das fronteiras do domínio de negócios. No contexto do nosso exemplo, o DDD sugeriria a construção de um modelo de domínio rico para o serviço de Voucher, encapsulando toda a lógica e as regras de negócio pertinentes aos vouchers dentro desse serviço. Outros serviços, como o carrinho de compras e o gerenciamento de usuários, interagiriam com o serviço de Voucher por meio de interfaces claramente definidas (APIs), sem incorporar diretamente qualquer lógica de negócio relacionada aos vouchers. Isso assegura que as regras de negócio permaneçam consistentes, centralizadas e fáceis de manter, ao mesmo tempo em que mantém a modularidade e a independência dos serviços.
Acho importante comentar brevemente isso no sub-tópico a seguir.
Definindo o Bounded Context do Voucher
O primeiro passo seria definir o Bounded Context para o serviço Voucher. Isso envolveria identificar os limites funcionais e as responsabilidades do serviço de Voucher, distinguindo-os claramente de outros domínios, como o carrinho de compras e o gerenciamento de usuários. No contexto de negócios, isso significa compreender todas as operações, políticas e regras relacionadas aos vouchers, como emissão, validação, expiração, e restrições de uso.
Do ponto de vista técnico, esse entendimento se traduz na modelagem de entidades, agregados e serviços de domínio que encapsulam a lógica e as regras de negócios dos vouchers. Isso ajuda a garantir que o serviço de Voucher seja autossuficiente, gerenciando todos os aspectos relacionados aos vouchers sem depender de lógica implementada em outros serviços.
Ubiquitous Language
A adoção de uma Linguagem Ubíqua dentro deste Bounded Context ajuda a alinhar todos os membros da equipe (desenvolvedores, especialistas de domínio, gerentes de produto, etc.) em relação ao entendimento dos conceitos e operações relacionadas aos vouchers. Isso assegura que, quando se fala em "validar um voucher" ou "emitir um novo voucher", todos compreendem exatamente o que essas operações implicam, tanto em termos de regras de negócio quanto de implementação técnica.
Modelagem de Domínio
Com um Bounded Context claramente definido e uma Linguagem Ubíqua adotada, a equipe pode então proceder à modelagem de domínio. Isso implica na criação de um modelo de domínio rico que encapsula a lógica e as regras de negócios dos vouchers de forma abstrata e expressiva. Este modelo serve como a espinha dorsal do serviço de Voucher, garantindo que todas as operações realizadas através deste serviço estejam em conformidade com as políticas e regras de negócio estabelecidas.
Contínua Colaboração e Refinamento
O DDD não vê o design do sistema como algo fixo; ao contrário, promove uma contínua colaboração entre os membros da equipe para refinar o modelo de domínio e ajustar os Bounded Contexts conforme novos insights são adquiridos. Isso assegura que o sistema permaneça alinhado às necessidades de negócios e tecnologia, adaptando-se a mudanças sem comprometer a clareza das fronteiras do domínio ou a coesão da lógica de negócios.

Ao seguir essas diretrizes, o DDD ajuda os arquitetos e especialistas a criar um sistema de microserviços no qual cada serviço, como o de Vouchers, é uma ilha de consistência e autonomia, claramente delimitada e alinhada com as necessidades específicas do domínio de negócios que atende. Isso minimiza o risco de criar um monólito distribuído, onde a lógica de negócios se torna entrelaçada e difusa entre os serviços, prejudicando a modularidade, a escalabilidade e a manutenibilidade do sistema.
Desmembrar um monólito sem uma estratégia clara é o primeiro passo para criar um monólito distribuído.
Interfaces e Integração
Para interagir com outros serviços, como o carrinho de compras e o gerenciamento de usuários, o serviço de Voucher exporia interfaces bem definidas (APIs), que permitiriam operações específicas, como a validação de um voucher durante o checkout. Essas interfaces seriam desenhadas para limitar o acesso às operações internas do serviço de Voucher, evitando que a lógica de negócios dos vouchers se espalhe ou seja duplicada em outros serviços.
No diagrama sequencial ajustado, fica claro que a comunicação dos serviços que precisam validar ou consultar Vouchers muda totalmente:

Esses diagramas C4 Diagrams e Sequence diagrams são grandes aliados quando precisamos visualizar isso claramente dentro de grandes sistemas e ao quebrar monólitos.
Compartilhamento de Bibliotecas e Acoplamento
O uso de bibliotecas compartilhadas entre serviços é outra área que merece atenção. Bibliotecas compartilhadas podem ser extremamente úteis para evitar a duplicação de código e para promover práticas consistentes de codificação em toda a organização. No entanto, quando mal gerenciadas, elas podem se tornar um ponto de acoplamento indesejado entre os serviços.
Se múltiplos serviços dependem fortemente das mesmas bibliotecas para realizar tarefas críticas, qualquer alteração nessas bibliotecas pode exigir uma onda de atualizações em todos os serviços afetados. Isso não apenas aumenta o risco de introduzir bugs, mas também cria um cenário onde a independência de cada serviço é comprometida. Eles se tornam menos capazes de evoluir, serem mantidos e escalados de forma independente, uma vez que mudanças em uma biblioteca central podem afetar vários serviços.
Caro leitor, esse assunto é importante, principalmente em corporações com alto grau de complexidade e seus sistemas críticos e fundamentais!
Além disso, o uso intensivo de bibliotecas compartilhadas pode mascarar a complexidade, fazendo com que os desenvolvedores subestimem o acoplamento real entre os serviços. Isso pode levar a decisões de design que favorecem a conveniência de curto prazo em detrimento da saúde a longo prazo da arquitetura.
Vamos explorar alguns cenários hipotéticos sobre o compartilhamento de bibliotecas criadas internamente para um ecossistema corporativo e como isso pode inadvertidamente contribuir para o desenvolvimento de um monólito distribuído, destacando os desafios e as implicações desse acoplamento.
Cenário 1: Atualização de Protocolo de Segurança
Imagine uma biblioteca interna que lida com a autenticação e a segurança, amplamente utilizada em vários serviços para validar tokens de usuário. Uma atualização crítica de segurança é necessária devido a uma nova vulnerabilidade. A mudança na biblioteca exige uma atualização em todos os serviços que a utilizam. No entanto, cada serviço tem seu próprio ciclo de lançamento e dependências, tornando a atualização sincronizada um pesadelo logístico. Isso pode resultar em uma janela de tempo em que diferentes partes do sistema estão em desacordo em termos de segurança, comprometendo a integridade do sistema como um todo.
Cenário 2: Dependência de Biblioteca para Operações de Dados
Considere uma biblioteca que fornece acesso e manipulação padronizados para um banco de dados compartilhado. Embora isso possa promover a reutilização de código, também cria um ponto único de falha. Se a biblioteca tiver um bug ou precisar de otimização para lidar com cargas de trabalho maiores, todos os serviços que dependem dela serão afetados. Isso não apenas aumenta o risco de interrupção do serviço, mas também limita a capacidade de cada serviço de otimizar seu próprio acesso aos dados de acordo com suas necessidades específicas.
Cenário 3: Mudança na Lógica de Negócios
Uma biblioteca interna comum que gerencia regras de negócios compartilhadas, como cálculos de preços ou descontos. Uma mudança nas regras de negócio exige uma atualização da biblioteca. No entanto, diferentes serviços podem ter interpretado ou implementado as regras originais de maneira ligeiramente diferente, adaptando-as às suas necessidades específicas. A atualização centralizada pode, inadvertidamente, quebrar a lógica personalizada em vários serviços, levando a inconsistências e erros na aplicação.
Acoplamento Invisível e Complexidade Subestimada
As equipes podem subestimar a complexidade de suas arquiteturas devido ao uso extensivo de bibliotecas compartilhadas, acreditando que os serviços são mais independentes do que realmente são. Quando uma biblioteca compartilhada precisa ser atualizada ou refatorada, as equipes podem se deparar com uma complexa teia de dependências que não era aparente inicialmente. Esse acoplamento "invisível" pode levar a um esforço significativo de coordenação entre as equipes para realizar mudanças que pareciam simples na superfície.

Implicações
Arquitetos e engenheiros devem abordar o compartilhamento de bibliotecas entre serviços com cautela, pois isso pode introduzir acoplamentos indesejados e comprometer a independência e a facilidade de modificação de cada serviço. Isso ocorre porque as bibliotecas compartilhadas criam uma base de código comum que, se alterada, pode afetar todos os serviços que a utilizam.
Quando o desacoplamento é superficial, o monólito distribuído emerge como uma sombra sobre a arquitetura.
Vamos relembrar algumas considerações e práticas recomendadas para gerenciar o uso de bibliotecas compartilhadas:
Avaliação Cuidadosa da Necessidade de Compartilhamento
Isolamento de Responsabilidades: É crucial que os engenheiros de software definam e preservem as responsabilidades únicas de cada serviço dentro de uma arquitetura de microserviços. Ao fazer isso, cada serviço deve operar de forma independente, com suas funções e áreas de atuação bem estabelecidas. Quando se trata do uso de bibliotecas compartilhadas, estas devem ser reservadas estritamente para funcionalidades que são transversais e não específicas a qualquer domínio de negócios particular. Exemplos claros de tais funcionalidades incluem operações de registro de atividades (logging), mecanismos de comunicação inter-serviços, exceptions personalizadas e sistemas de autenticação. Estas são consideradas práticas comuns que suportam a infraestrutura técnica subjacente dos microserviços, sem se entrelaçarem diretamente com a lógica de negócios específica de qualquer serviço individual.
Análise de Impacto: Antes de adotar uma biblioteca compartilhada, é crucial avaliar o impacto de suas alterações nos serviços consumidores. A biblioteca é estável? Quão frequentes são as atualizações? As mudanças são retrocompatíveis?
Garantia da Independência dos Serviços
Versionamento de Bibliotecas: Utilizar versionamento semântico para bibliotecas compartilhadas pode ajudar a gerenciar dependências e garantir que atualizações incompatíveis não afetem serviços existentes sem uma revisão adequada.
Contratos Claros: Definir e manter contratos claros para as interfaces expostas pelas bibliotecas compartilhadas. Isso ajuda a garantir que as expectativas entre os serviços consumidores e a biblioteca sejam bem compreendidas e mantidas.
Realização de Provas de Conceito (PoC)
Validação de Viabilidade: Realizar PoCs antes de implementar e adotar bibliotecas compartilhadas em larga escala é essencial para validar a viabilidade técnica e a adequação ao uso pretendido nos diversos serviços do ecossistema.
Identificação de Efeitos Colaterais: PoCs ajudam a identificar possíveis efeitos colaterais ou problemas de integração que podem não ser óbvios no início do desenvolvimento. Isso inclui testar a biblioteca em diferentes contextos e cargas de trabalho para garantir a escalabilidade e a performance.
Feedback Iterativo: A fase de PoC permite um ciclo de feedback iterativo entre os desenvolvedores da biblioteca e seus consumidores (outros serviços), facilitando ajustes e melhorias antes de um lançamento mais amplo.
Considerações de Negócios e Técnicas
Impacto no Time-to-Market: O uso de bibliotecas compartilhadas pode acelerar o desenvolvimento inicial, mas mudanças nessas bibliotecas podem se tornar bloqueios para atualizações ou novas funcionalidades nos serviços, afetando o tempo de lançamento de produtos ou serviços.
Custo de Manutenção: Engenheiros devem considerar o custo de manutenção associado a bibliotecas compartilhadas. A complexidade adicional vale a reutilização de código?1
Cultura de Colaboração: Fomentar uma cultura de colaboração e comunicação aberta entre as equipes de desenvolvimento para garantir que as necessidades e preocupações de todos os serviços sejam consideradas na manutenção das bibliotecas compartilhadas.
Em suma, a decisão de compartilhar bibliotecas entre serviços em um ecossistema de microserviços não deve ser tomada levianamente. Requer uma avaliação cuidadosa das necessidades técnicas e de negócios, além de uma implementação e gestão cuidadosas para evitar os riscos associados ao acoplamento e à perda de independência dos serviços. Realizar PoCs é uma etapa crítica nesse processo, fornecendo insights valiosos e ajudando a garantir que a solução seja robusta, escalável e alinhada com os objetivos de longo prazo do ecossistema.
Você pode ler mais sobre esse tema no meu artigo👇🏼:
Quando Bibliotecas Compartilhadas Complicam Microserviços?

Em arquiteturas de microserviços, conforme os sistemas crescem, um tema delicado surge: o compartilhamento de bibliotecas entre serviços. À primeira vista, pode parecer uma prática inofensiva ou até eficiente. Afinal, reutilizar código é uma boa prática. Mas, como veremos ao longo deste artigo, essa prática pode esconder armadilhas que comprometem justa…
Cuidado com o Acoplamento Excessivo!
Em arquiteturas distribuídas, como aquelas baseadas em microserviços, algum nível de acoplamento entre serviços é normal e até inevitável. Diferentes componentes precisam interagir e colaborar para que o sistema funcione como um todo coeso. Isso inclui a troca de informações e a coordenação entre serviços para realizar tarefas conjuntas, cumprir fluxos de trabalho ou manter consistência de dados.2
No entanto, é fundamental estar atento ao acoplamento excessivo, que pode se tornar uma grande preocupação. Um acoplamento muito estreito entre os serviços pode levar a uma série de problemas.
Acoplamento Excessivo: A Raiz do Problema
Em uma arquitetura ideal de microserviços, cada app é autocontido, gerenciando sua própria lógica de negócios, dados e dependências. O acoplamento excessivo acontece quando serviços distintos, mesmo separados fisicamente (em diferentes contêineres ou servidores), compartilham diretamente dados ou estados, criando uma dependência intrínseca um no outro.
Como o Acoplamento Excessivo Prejudica os Princípios de Microserviços
Violação da Independência: Microserviços devem ser independentes, permitindo atualizações, escalabilidade e manutenção sem impactar outros serviços. O acoplamento de dados compromete essa independência, pois mudanças em um serviço podem exigir mudanças correspondentes nos serviços acoplados.
Degradação da Resiliência: Um dos pilares dos microserviços é a resiliência, a capacidade de um serviço falhar sem afetar significativamente os demais. O acoplamento de dados cria pontos únicos de falha, onde problemas em um serviço podem se propagar, afetando outros serviços acoplados.
Obstáculo à Escalabilidade: A escalabilidade se torna complexa e ineficiente quando serviços são fortemente acoplados. Escalar um serviço acoplado pode exigir que todos os serviços relacionados sejam escalados simultaneamente, aumentando os custos e a complexidade.
A Importância do Isolamento Completo
O isolamento completo dos serviços é fundamental para manter a modularidade, facilitar a manutenção e promover a escalabilidade eficiente. Isolar serviços significa que cada um opera de forma independente, sem depender diretamente dos dados ou estados de outro serviço.
Riscos Operacionais do Acoplamento Excessivo
Inflexibilidade: A capacidade de adaptar e evoluir rapidamente os serviços é prejudicada, pois qualquer mudança pode requerer uma coordenação complexa entre vários serviços.
Aumento do Tempo de Downtime: A falha em um serviço pode levar à falha em cascata, aumentando o tempo de inatividade do sistema e afetando a experiência do usuário.
Complexidade de Gerenciamento: O gerenciamento e monitoramento se tornam mais desafiadores, exigindo ferramentas e processos mais complexos para garantir a integridade do sistema.
Impacto no Desenvolvimento de Novas Funcionalidades
O acoplamento excessivo entre serviços pode significativamente retardar o desenvolvimento de novas funcionalidades. Equipes de desenvolvimento podem se ver emaranhadas em uma teia de dependências, tornando difícil implementar, testar e lançar novas features de forma ágil.
Sistema de E-commerce
Quero que visualize um sistema de e-commerce com dois serviços: um serviço de Pedidos e um serviço de Inventário. Se o serviço de Pedidos acessa diretamente o banco de dados do serviço de Inventário para verificar a disponibilidade de produtos, cria-se um acoplamento direto de dados. Isso significa que qualquer mudança na estrutura de dados do Inventário pode exigir mudanças no serviço de Pedidos. Além disso, se o serviço de Inventário falhar, o serviço de Pedidos pode se tornar inoperante, mesmo que sua própria infraestrutura esteja intacta.

Explorando mais profundamente o exemplo do sistema de e-commerce, podemos ver como o acoplamento direto entre o serviço de Pedidos e o serviço de Inventário pode levar a uma série de desafios e complicações, ilustrando claramente os problemas associados ao acoplamento excessivo em uma arquitetura de microserviços.
Desafios Técnicos e Operacionais
Mudanças na Estrutura de Dados: Se o serviço de Inventário decide alterar sua estrutura de dados - por exemplo, para otimizar o armazenamento ou adicionar novos atributos aos produtos - essa mudança pode quebrar a integração com o serviço de Pedidos. O serviço de Pedidos pode esperar dados em um formato específico ou depender de campos que são modificados ou removidos, levando a falhas e a necessidade de refatoração imediata.
Falhas em Cascata: A dependência direta do serviço de Pedidos no banco de dados do serviço de Inventário significa que qualquer interrupção no Inventário - seja por sobrecarga, falhas de hardware ou manutenção - diretamente impacta a funcionalidade do serviço de Pedidos. Isso pode levar a uma experiência de usuário negativa, onde os clientes são incapazes de realizar pedidos mesmo quando outras partes do sistema estão operacionais.
Dificuldades na Escalabilidade: A escalabilidade torna-se um desafio significativo quando serviços estão fortemente acoplados. Se o sistema experimenta um pico de demanda que exige mais recursos para o serviço de Pedidos, a performance do serviço de Inventário pode ser inadvertidamente afetada devido ao acoplamento de dados, e vice-versa. Escalar um serviço sem impactar o outro requer uma coordenação cuidadosa e pode ser ineficiente.
Implicações no Desenvolvimento e Manutenção
Barreiras ao Desenvolvimento Ágil: A necessidade de sincronizar mudanças entre o serviço de Pedidos e o serviço de Inventário pode retardar significativamente o ciclo de desenvolvimento. Novas funcionalidades que exigem alterações em ambos os serviços exigem coordenação entre as equipes, revisões cruzadas e testes extensivos para garantir que as mudanças em um serviço não quebrem o outro.
Manutenção Complexa: A manutenção se torna mais complexa devido à interdependência. Atualizações de segurança, correções de bugs ou melhorias de performance em um serviço podem exigir ajustes correspondentes no outro. Isso não apenas aumenta o esforço de manutenção, mas também eleva o risco de introduzir novos bugs durante o processo de atualização.
Abordagem Alternativa para Desacoplamento
Uma abordagem mais saudável para esse cenário seria implementar uma camada de comunicação que desacople os serviços. Por exemplo, o serviço de Pedidos poderia emitir uma solicitação via API ou um sistema de mensagens assíncronas para verificar a disponibilidade do produto. O serviço de Inventário, então, responderia com a disponibilidade atualizada, sem expor diretamente sua base de dados. Isso permite que cada serviço evolua independentemente, mantendo a integridade e a resiliência do sistema.

Esse cenário, onde o Serviço de Pedidos e o Serviço de Inventário comunicam-se de forma desacoplada através de uma fila de mensagens, é válido e bastante comum na indústria, especialmente em arquiteturas orientadas a eventos e microserviços.
Fique atento com o excesso de comunicação síncrona!
Embora a comunicação síncrona possa simplificar o design inicial, facilitando a compreensão do fluxo de dados e operações, ela introduz um acoplamento temporal que pode ser problemático. Cada solicitação entre serviços exige uma resposta imediata, criando uma dependência direta na disponibilidade e no desempenho do serviço chamado. Isso não apenas aumenta a latência do sistema como um todo, mas também torna o sistema mais frágil e menos resiliente a falhas.
Comunicação síncrona em microserviços
A comunicação síncrona ocorre quando um serviço A faz uma solicitação a um serviço B e aguarda uma resposta antes de prosseguir. Esse padrão é intuitivo e direto, mimetizando chamadas de função comuns em programação, o que o torna atraente durante a decomposição de um monólito. No contexto de microserviços, ele é frequentemente implementado através de chamadas de API REST ou gRPC, por exemplo.
Aplicabilidade e Limitações
Embora a comunicação síncrona seja adequada para operações que requerem confirmação imediata e consistência, como algumas transações financeiras ou atualizações críticas de estado, ela possui limitações significativas em uma arquitetura distribuída:
Acoplamento Temporal: Serviços se tornam fortemente dependentes da disponibilidade e do desempenho um do outro, o que pode levar a pontos únicos de falha.
Latência: A necessidade de esperar por respostas pode aumentar significativamente a latência geral do sistema, especialmente se várias chamadas síncronas em cadeia forem necessárias para completar uma operação.
Escalabilidade: A escalabilidade pode ser prejudicada, pois o aumento do volume de solicitações pode sobrecarregar os serviços e exigir uma escalabilidade proporcional de todos os serviços envolvidos na cadeia de comunicação.
Caminho Sombrio para um Monólito Distribuído
O uso excessivo de comunicação síncrona em uma arquitetura de microserviços pode, em certos contextos, sinalizar um desvio rumo à criação de um monólito distribuído. Isso ocorre porque um alto grau de interdependência entre os serviços pode comprometer sua capacidade de operar, evoluir ou escalar de forma independente. Essa situação é especialmente problemática quando padrões de comunicação síncrona são adotados sem uma avaliação criteriosa de suas consequências, resultando em uma rede complexa de dependências diretas.
A independência dos serviços é crucial para o sucesso de uma arquitetura de microserviços, e o uso inadequado de comunicações síncronas pode subverter essa independência, limitando severamente a flexibilidade e a escalabilidade do sistema.
Primeiros sinais e alertas
Os primeiros sinais de que a comunicação síncrona está levando a um monólito distribuído incluem:
Degradação do Desempenho: Um aumento na latência geral do sistema, onde operações que deveriam ser rápidas começam a sofrer atrasos perceptíveis.
Falhas em Cascata: Falhas ou degradações em um serviço começam a impactar diretamente outros serviços, mesmo que não compartilhem a mesma base de código ou infraestrutura.
Dificuldades na Implantação Independente: A necessidade de coordenar atualizações e implantações entre serviços sugere um alto nível de acoplamento.
Sobre os pontos acima eu gostaria de citar com alguns exemplos para que fique bem claro.
Degradação do desempenho
Exemplo: Imagine um sistema de e-commerce onde, ao finalizar uma compra, o serviço de Pedidos precisa confirmar o estoque com o serviço de Inventário, calcular o frete com o serviço de Logística e, finalmente, processar o pagamento com o serviço de Pagamentos. Se cada uma dessas etapas é feita de forma síncrona e uma após a outra, um atraso em qualquer serviço pode aumentar significativamente o tempo total para concluir a compra.
Perguntas a Fazer:
"Existe uma maneira de paralelizar essas verificações ou de realizá-las de forma assíncrona para reduzir a latência?"
"Podemos implementar um cache ou uma política de fallback para lidar com a indisponibilidade temporária de um serviço?"
Falhas em cascata
Exemplo: Suponha que o serviço de Pagamentos, mencionado anteriormente, esteja enfrentando uma falha. Se o serviço de Pedidos não pode processar uma compra sem a confirmação do pagamento, toda a operação de checkout fica comprometida, afetando a experiência do usuário, mesmo que os serviços de Inventário e Logística estejam operando normalmente.
Perguntas a Fazer:
"Podemos introduzir um sistema de mensagens ou uma fila para desacoplar o processo de pagamento do processo de finalização da compra?"
"Existe uma estratégia de contingência, como permitir pagamentos offline ou atrasados, para manter a funcionalidade do checkout em caso de falha no serviço de Pagamentos?"
Dificuldades na implantação independente
Exemplo: Cada vez que o serviço de Inventário é atualizado para incluir novas funcionalidades, o serviço de Pedidos também precisa ser modificado para acomodar essas mudanças, mesmo que sua lógica principal não tenha sido afetada. Isso não apenas atrasa o lançamento de novas funcionalidades, mas também aumenta o risco de introduzir bugs.
Sempre questione:
"Os serviços estão compartilhando a lógica de negócios ou dados que poderiam ser encapsulados ou abstraídos?"
"Podemos definir contratos de API mais estáveis ou utilizar padrões de versionamento de API para minimizar o impacto das mudanças?"
Mas para lidar com os desafios apresentados pela comunicação síncrona excessiva e evitar a evolução indesejada de uma arquitetura de microserviços em um monólito distribuído, é importante adotar estratégias conscientes e soluções pragmáticas. Quero comentar algumas que são aplicadas na indústria e que são viáveis:
Comunicação Assíncrona Onde Possível
A transição para padrões de comunicação assíncrona, como filas de mensagens e eventos, pode reduzir significativamente o acoplamento temporal entre serviços. Isso permite que os serviços operem de forma mais independente, sem a necessidade de esperar por respostas imediatas.
Solução para Degradação do Desempenho:
Implemente filas de mensagens para desacoplar os processos de negócios, permitindo que as operações críticas, como o processamento de pedidos, continuem mesmo se um serviço dependente estiver lento ou indisponível temporariamente.
Utilizar Padrões de Resiliência
Padrões como Circuit Breaker, Bulkhead e Timeout podem ajudar a prevenir falhas em cascata e garantir que o sistema permaneça responsivo mesmo diante de falhas em serviços individuais.
Solução para Falhas em Cascata:
Implemente o padrão Circuit Breaker no serviço de Pedidos para evitar chamadas a um serviço de Pagamentos que esteja apresentando falhas consistentes, recorrendo a uma lógica de fallback adequada.
Estratégias de Versionamento e Contratos de API
Definir e manter contratos de API claros e estáveis, juntamente com estratégias de versionamento, pode minimizar os impactos das mudanças, permitindo que os serviços evoluam de forma mais independente.
Solução para Dificuldades na Implantação Independente:
Utilize versionamento de API para permitir que o serviço de Inventário introduza novas funcionalidades sem forçar alterações imediatas no serviço de Pedidos, facilitando a implantação independente dos serviços.
Implementar Monitoramento e Alertas
Um sistema robusto de monitoramento e alertas pode ajudar a identificar rapidamente problemas de desempenho e falhas, permitindo uma resposta ágil antes que os usuários finais sejam significativamente impactados.
Solução Proativa:
Configure dashboards de monitoramento e alertas baseados em métricas críticas, como latência e taxas de erro, para cada serviço, permitindo a detecção e a resolução proativas de problemas.
Embora a comunicação síncrona não seja a norma em arquiteturas de microserviços, ela tem seu lugar e pode ser necessária para determinadas operações que exigem consistência e resposta imediata. No entanto, é crucial estar vigilante quanto ao seu uso à medida que a complexidade da rede de serviços aumenta.
Em arquiteturas de microserviços, o ideal é favorecer a comunicação assíncrona, que promove a desacoplagem entre os serviços. Isso permite que cada serviço opere de maneira mais independente, facilitando a escalabilidade e a manutenção do sistema. A comunicação assíncrona também reduz os pontos de falha, pois os serviços não ficam bloqueados aguardando respostas uns dos outros, o que aumenta a resiliência do sistema.
Espero que esse tema tenha ficado claro, vamos agora falar de outro cenário que leva a microserviços mascarados de monólitos.
Entendendo o Problema com Filas Compartilhadas
Filas são componentes essenciais para a comunicação assíncrona em sistemas distribuídos, permitindo que serviços enviem e recebam mensagens de maneira desacoplada. No entanto, o compartilhamento de uma única fila por múltiplos serviços introduz um acoplamento indesejado, semelhante aos problemas encontrados com o compartilhamento de bancos de dados em monólitos. Esse acoplamento manifesta-se de várias formas:
Acoplamento de Formato de Mensagem: Todos os serviços que produzem ou consomem mensagens de uma fila compartilhada devem concordar com um formato de mensagem comum. Isso limita a flexibilidade para que serviços evoluam independentemente, pois qualquer alteração no formato da mensagem pode afetar todos os serviços conectados à fila.
Gestão de Consumo de Mensagens: Em uma fila compartilhada, há o risco de um serviço consumir mensagens destinadas a outro, a menos que haja uma forma de filtragem ou roteamento de mensagens muito bem definida, o que adiciona complexidade ao sistema.
Escalabilidade e Resiliência: A dependência mútua em uma fila compartilhada pode criar um ponto único de falha e tornar desafiador escalar serviços de forma independente, visto que a carga na fila é compartilhada entre todos os serviços.
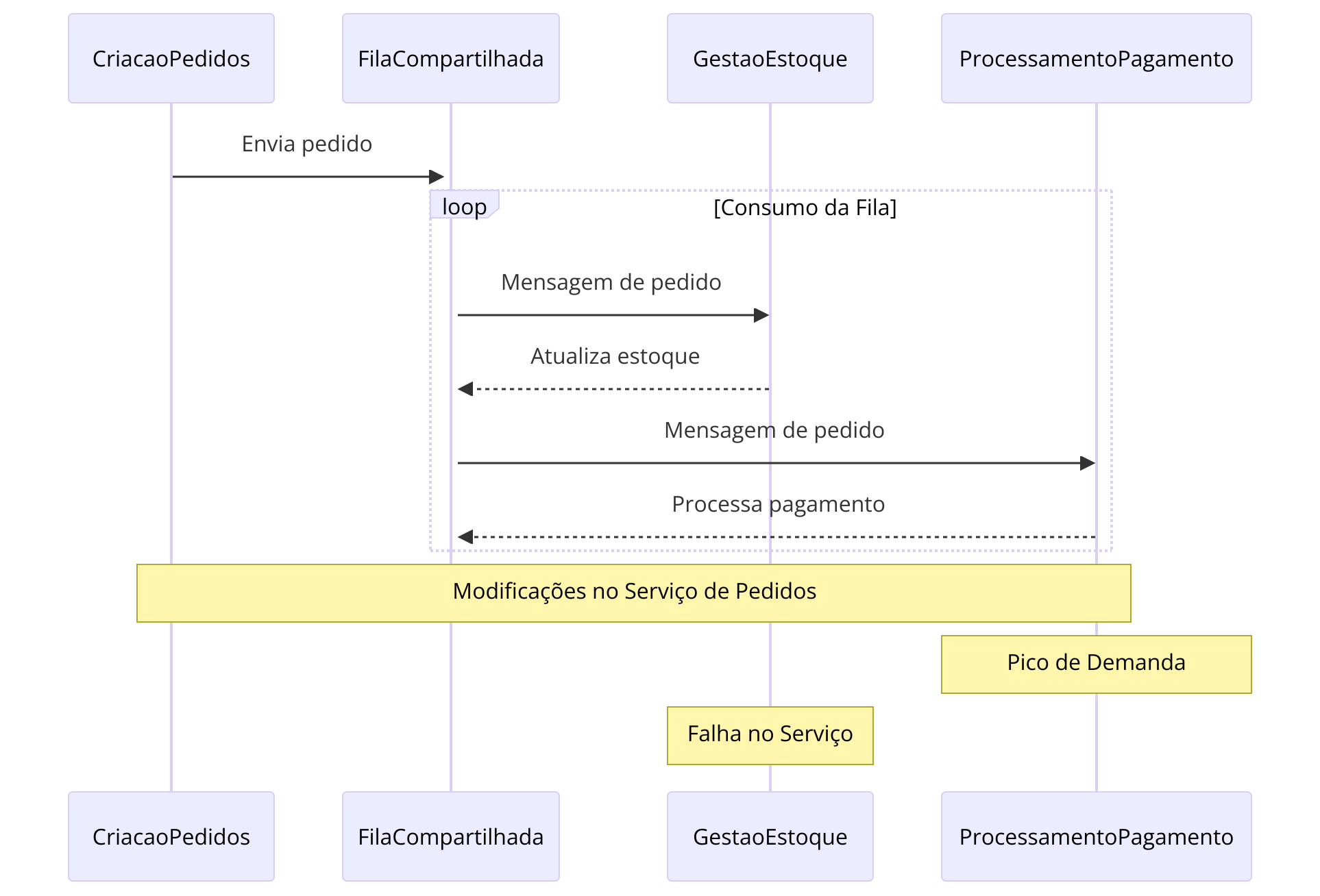
Um sistema de processamento de pedidos
Imagine um sistema de processamento de pedidos onde um serviço de "Criação de Pedidos" envia informações de novos pedidos para uma fila compartilhada, da qual um serviço de "Gestão de Estoque" e um serviço de "Processamento de Pagamento" consomem mensagens. Inicialmente, essa configuração pode parecer eficiente, mas os problemas emergem rapidamente:
Modificações no Serviço de Pedidos: Se o serviço de "Criação de Pedidos" precisa modificar a estrutura de suas mensagens para incluir novos dados, como códigos promocionais, ambos os serviços consumidores precisam ser atualizados para lidar com o novo formato, mesmo que esses dados não sejam relevantes para suas operações. Isso retarda a entrega de novos recursos e aumenta o risco de erros.
Pico de Demanda no Processamento de Pagamentos: Durante uma promoção, o volume de pedidos aumenta significativamente, sobrecarregando o serviço de "Processamento de Pagamento". Como resultado, o serviço de "Gestão de Estoque" também é afetado, pois as mensagens se acumulam na fila compartilhada, atrasando a atualização do estoque.
Falha no Serviço de Gestão de Estoque: Uma falha no serviço de "Gestão de Estoque", que o impede de consumir mensagens, pode interromper todo o fluxo de processamento de pedidos, pois as mensagens não consumidas se acumulam, potencialmente afetando até o recebimento de novos pedidos.
Algumas perguntas essenciais que devemos nos fazer para analisar o contexto:
Qual é o objetivo de compartilhar a fila?
Avalie a motivação por trás da decisão. É por conveniência, redução de custos, ou existe uma necessidade de negócios claramente definida?
Como o compartilhamento da fila afeta a autonomia dos serviços?
Considere se os serviços podem evoluir, escalar e ser mantidos independentemente um do outro, mesmo compartilhando a mesma fila.
Existem alternativas para o compartilhamento de filas que ainda atendem aos requisitos?
Explore outras opções, como a utilização de tópicos com múltiplas inscrições ou a implementação de filas dedicadas para cada serviço.
Como o formato das mensagens será gerenciado e versionado?
Determine se há um contrato de mensagens claramente definido e como as mudanças no formato das mensagens serão gerenciadas para evitar interrupções nos serviços consumidores.
Como o processamento de mensagens será isolado entre os serviços?
Avalie mecanismos para garantir que um serviço não consuma ou interfira nas mensagens destinadas a outro serviço.
Quais são as implicações de escalabilidade e resiliência?
Considere como o sistema responderá a picos de carga e falhas. O compartilhamento de filas introduz pontos únicos de falha ou gargalos?
Responder a essas perguntas ajudará os arquitetos e todos os envolvidos a tomar decisões mais informadas sobre o uso de filas compartilhadas, assegurando que a arquitetura de microserviços permaneça robusta, flexível e alinhada com os objetivos de longo prazo da organização.
A comunicação entre unidades de negócios também é prejudicada!
Quero abordar a questão dos sinais de um monólito distribuído do ponto de vista da comunicação entre as equipes de desenvolvimento e de negócios e como isso pode divergir dos princípios essenciais dos microserviços. Isso eu presenciei em alguns contextos corporativos, principalmente quando trabalhavam em instituições bancárias!
Sinais de um monólito distribuído em comunicação e negócios
Integrações Tightly Coupled (fortemente acopladas): Um indicativo claro da presença de um monólito distribuído dentro de uma arquitetura que, idealmente, deveria favorecer a independência e a modularidade entre os serviços. Em uma arquitetura de microserviços bem concebida, espera-se que cada serviço tenha a capacidade de evoluir e se adaptar de maneira autônoma, sem a necessidade de coordenação extensiva ou renegociações constantes com outros serviços dentro do mesmo ecossistema de negócios. Essa independência é crucial para aproveitar os benefícios da arquitetura de microserviços, como a agilidade no desenvolvimento, a escalabilidade e a resiliência. No entanto, quando observamos que alterações em um serviço específico desencadeiam uma cadeia de ajustes e modificações em outros serviços correlatos, isso denota um nível problemático de interdependência. Tal cenário revela esse acoplamento. Vou deixar mais informações e alguns pontos de atenção na nota de rodapé.3
Geração de Contratos Centralizada: Em um ambiente saudável de microserviços, cada equipe é responsável por definir e manter os contratos de seus próprios serviços. Se uma única equipe ou um pequeno grupo central está constantemente envolvido na geração e na revisão de contratos para a maioria dos serviços, isso pode indicar que os serviços não são tão autônomos quanto deveriam, apontando para a presença de um monólito distribuído.
Comunicação Ineficiente entre Equipes: A comunicação frequente e eficiente é crucial em um ambiente de microserviços, especialmente entre equipes de desenvolvimento e negócios. Se as equipes de negócios se encontram frequentemente surpresas por mudanças ou por não entenderem o impacto das decisões técnicas, isso pode indicar uma falha na comunicação e na autonomia dos serviços, o que é comum em estruturas de monólito distribuído.
Impactos nos prazos e na eficiência
Atrasos nos Lançamentos: A necessidade de coordenação extensiva entre as equipes para realizar mudanças pode levar a atrasos significativos nos lançamentos de novas funcionalidades ou na resolução de problemas. Isso é exacerbado em um monólito distribuído, onde as dependências entre serviços são complexas e mal gerenciadas.
Ineficiências Operacionais: O esforço redundante na manutenção de integrações e contratos entre serviços acoplados pode levar a um desperdício significativo de recursos, tanto humanos quanto computacionais. Isso afeta negativamente a eficiência operacional e pode desviar o foco das equipes das iniciativas de inovação.
Imagine uma corporação financeira com múltiplas equipes de desenvolvimento trabalhando em um sistema de gestão de ativos. A equipe de "Gestão de Portfólio" precisa atualizar seu serviço para acomodar novos tipos de ativos. No entanto, isso requer mudanças sincronizadas na "Análise de Risco" e nos serviços de "Relatórios", devido a uma fila de mensagens compartilhada e a um banco de dados comum. As negociações entre as equipes atrasam o lançamento, criando frustração entre as partes interessadas de negócios que esperavam um lançamento ágil de novos produtos financeiros.
A questão mencionada reflete um cenário onde os serviços e contextos ultrapassam suas fronteiras naturais, invadindo domínios que não lhes pertencem. Isso nos reconduz à essência do Domain-Driven Design (DDD) que foi comentada anteriormente, que enfatiza a importância de definir claramente as responsabilidades e limites de cada serviço, assegurando que cada um se concentre em sua especialidade inerente. Ao aderir aos princípios do DDD, podemos evitar a proliferação de monólitos distribuídos, promovendo uma arquitetura de serviços mais coesa, modular e alinhada com os objetivos de negócios.
Possíveis soluções para melhoria da comunicação
Contratos: Garantir que cada serviço tenha sua próprio contrato, definidos e mantidos pela equipe responsável pelo serviço. Isso promove a independência e facilita a comunicação entre as equipes. Os contextos e limites devem ser claros de cada serviço, pois um serviço reflete a unidade de negócio e suas especialidades!
Práticas de Domain-Driven Design (DDD): Adotar DDD para alinhar as estruturas dos serviços com os domínios de negócios, melhorando a comunicação entre as equipes de desenvolvimento e negócios e garantindo que os serviços reflitam as necessidades do negócio.
Cultura de Feedback e Iteração Contínua: Promover uma cultura onde o feedback entre as equipes de desenvolvimento e negócios é constante e valorizado, permitindo ajustes rápidos e iterativos nos serviços.
Perguntas para Reflexão
"Como podemos alinhar nossos serviços com os domínios de negócios para facilitar a comunicação entre as equipes?"
"Quais ferramentas e práticas podem promover a autonomia dos serviços e reduzir o acoplamento indesejado?"
"Como podemos melhorar nosso processo de definição e gestão de contratos para garantir a independência dos serviços?"
Evitar a formação de um monólito distribuído requer um compromisso contínuo com a independência dos serviços, uma comunicação eficaz entre as equipes e a adoção de práticas e ferramentas que suportem uma arquitetura de microserviços verdadeiramente descentralizada e ágil.
E os testes podem ser afetados?
Será que tudo isso que comentamos ao longo do artigo pode afetar os testes? Essa pergunta é dificil de responder pois cada sistema e seus serviços disponiveis tem um contexto único e particular! Mas vou deixar minha opinião. Para isso vamos voltar para o exemplo de gestão de pedidos em uma loja online.
Nesse sistema, temos serviços distintos para gerenciar usuários, pedidos, pagamentos e envios. A princípio, esses serviços parecem bem definidos e independentes. No entanto, à medida que o sistema evolui, as linhas entre esses serviços começam a se borrar. As atualizações em um serviço requerem mudanças coordenadas em outros, e o banco de dados, em vez de ser segregado por serviço, torna-se um emaranhado compartilhado de tabelas inter-relacionadas.
Neste ponto, a complexidade dos testes começa a se revelar. Os testes de contrato, projetados para garantir que as interações entre os serviços permaneçam consistentes e previsíveis, tornam-se um desafio. O que deveria ser uma simples verificação de interface agora requer um entendimento profundo das mudanças em cascata através do sistema. Uma alteração no serviço de pedidos, por exemplo, pode afetar inesperadamente o serviço de envios, exigindo uma bateria de testes de integração não apenas dentro do serviço modificado, mas também em todos os serviços que, de alguma forma, dependem dele.
Essa interdependência complica não apenas a execução dos testes, mas também sua manutenção. Testes que antes eram isolados dentro de um contexto de serviço agora precisam ser atualizados em resposta a mudanças em outros serviços, aumentando o esforço de manutenção e o risco de erros. Os testes de integração, em particular, tornam-se exercícios laboriosos, tentando simular o ambiente de produção completo, com todos os seus serviços interconectados, para garantir que o sistema como um todo funcione como esperado.
Além disso, a falta de clareza nas fronteiras dos serviços pode levar a testes que não cobrem adequadamente os cenários de uso. Campos e colunas em bancos de dados compartilhados podem ser modificados ou interpretados de maneira diferente por diferentes serviços, levando a inconsistências que só são descobertas durante os testes de integração - ou pior, na produção. Isso não apenas atrasa o desenvolvimento, como também compromete a confiança na qualidade do sistema.
Os bugs inesperados tornam-se visitantes frequentes, manifestando-se de formas que desafiam a lógica inicial. Pode ser que um teste passe quando executado isoladamente dentro de um serviço, mas falhe quando o sistema é testado como um todo. Esses bugs são sintomas de um design que, embora possa ter começado com a intenção de criar microserviços independentes, deslizou para a complexidade de um monólito distribuído.
Mas então como mitigar esses riscos? Podemos começar a detectar os sinais e agir antes de entrar no inferno distribuído monólitico. Existem estratégias focadas em reforçar a independência e a clareza nas interações entre os serviços. Aqui estão cinco estratégias diretas para manter a integridade dos testes:
Isolamento de Testes com Mocks e Stubs: Utilize mocks e stubs para simular as interações entre os serviços nos testes. Isso permite que cada serviço seja testado de forma isolada, sem depender diretamente dos outros serviços. Ao mockar as dependências externas, você pode verificar o comportamento do serviço em questão de maneira controlada e previsível, reduzindo o risco de falhas inesperadas devido a complexidades externas.
Contratos de Serviço Claros e Testados: Implemente testes de contrato que validam as interações entre os serviços. Ferramentas como Pact ou Spring Cloud Contract podem automatizar a verificação de que as interações entre os consumidores e os provedores de serviços estão em conformidade com os contratos definidos. Isso ajuda a garantir que as mudanças em um serviço não quebrem as expectativas dos serviços dependentes.
Estratégias de Teste de Integração Segmentadas: Em vez de tentar testar toda a integração do sistema de uma só vez, quebre os testes de integração em segmentos menores e mais gerenciáveis, focando em interações específicas entre os serviços. Isso não só torna os testes mais claros e fáceis de manter, mas também ajuda a identificar rapidamente a origem de um problema.
Ambientes de Teste Independentes: Mantenha ambientes de teste independentes para cada serviço, permitindo que as equipes testem suas mudanças em isolamento antes de integrar com o sistema maior. Isso facilita a detecção precoce de problemas e minimiza o impacto das mudanças em desenvolvimento nos outros serviços.
Conclusão
À medida que navegamos pelo intricado labirinto da arquitetura de sistemas, a distinção entre microserviços autênticos e monólitos distribuídos disfarçados torna-se crucial, não apenas para a saúde técnica de nossas plataformas, mas também para a agilidade e a resiliência de nossas organizações. Chris Richardson nos lembra eloquentemente que a decomposição inadequada de sistemas não nos afasta do monolitismo; ao contrário, nos arrasta para uma versão mais insidiosa dele - o monólito distribuído.
A verdadeira essência de uma arquitetura baseada em microserviços reside na sua capacidade de fragmentar a complexidade em unidades gerenciáveis e autônomas, cada uma encapsulando uma faceta distinta da lógica de negócios. Quando essa autonomia é comprometida por integrações excessivamente acopladas, perdemos não apenas a agilidade técnica, mas também a capacidade de inovar e responder rapidamente às necessidades em constante mudança do mercado.
Portanto, enquanto aspiramos a desenhar sistemas que são verdadeiramente modulares e descentralizados, devemos estar constantemente vigilantes aos sinais de acoplamento e dependências ocultas que ameaçam essa modularidade. O objetivo não é apenas evitar a construção de um monólito distribuído, mas assegurar que cada microserviço possa florescer em seu próprio ecossistema, contribuindo para a robustez e a adaptabilidade geral do sistema.
Para finalizar, o caminho para uma arquitetura eficaz de microserviços é contínua e repleta de aprendizados. É uma jornada que exige não apenas a compreensão profunda dos princípios de design e arquitetura, mas também a disposição para adaptar e evoluir esses princípios à medida que novos desafios e compreensões emergem. Ao permanecermos comprometidos com a clareza, a modularidade, a autonomia e limites, podemos desvendar o verdadeiro potencial dos microserviços e liderar nossas organizações para um futuro mais ágil e resiliente.
Existem situações em que realmente é necessário ou viável.
Sam Newman até comenta sobre esse ponto em seu livro Criando Microsserviços - 2ª Edição.
É importante distinguir, contudo, as integrações entre unidades de negócios distintas ou entre a empresa e seus clientes externos. Nesses casos, ajustes decorrentes de mudanças em um serviço são naturais e fazem parte do processo de integração entre sistemas que, por natureza, operam de forma independente. Tais ajustes são geralmente gerenciados por meio de contratos de interface bem definidos, que estabelecem claramente as expectativas e os requisitos para a interação entre os sistemas envolvidos.
Por outro lado, dentro de uma mesma unidade de negócios, a necessidade de sincronização constante e ajustes recíprocos entre serviços que deveriam funcionar de forma independente sinaliza uma falha na concepção da arquitetura. Esse cenário sugere que, apesar da distribuição física dos serviços, há uma fusão indesejada de responsabilidades e dependências, característica de um monólito em que os componentes são inseparáveis e interdependentes. Tal configuração dificulta significativamente a manutenção, a escalabilidade e a evolução do sistema, contrariando os objetivos fundamentais da arquitetura de microserviços.